







前言
硬件层面:使用固态硬盘、扩大内存、加大带宽等等
架构层面:主从复制实现读写分离【一主一从 或 双主双从】
表结构层面:对含有大字段的表结构进行垂直拆分、对大数据量的表进行水平分表、分库分表
索引层面:索引是帮助MySQL高效获取数据的数据结构,优化索引的本质就是通过减少IO量和IO次数来提高查询效率
MySQL数据类型
在业务允许范围内,数据类型所占用的存储空间越少越好
数值类型
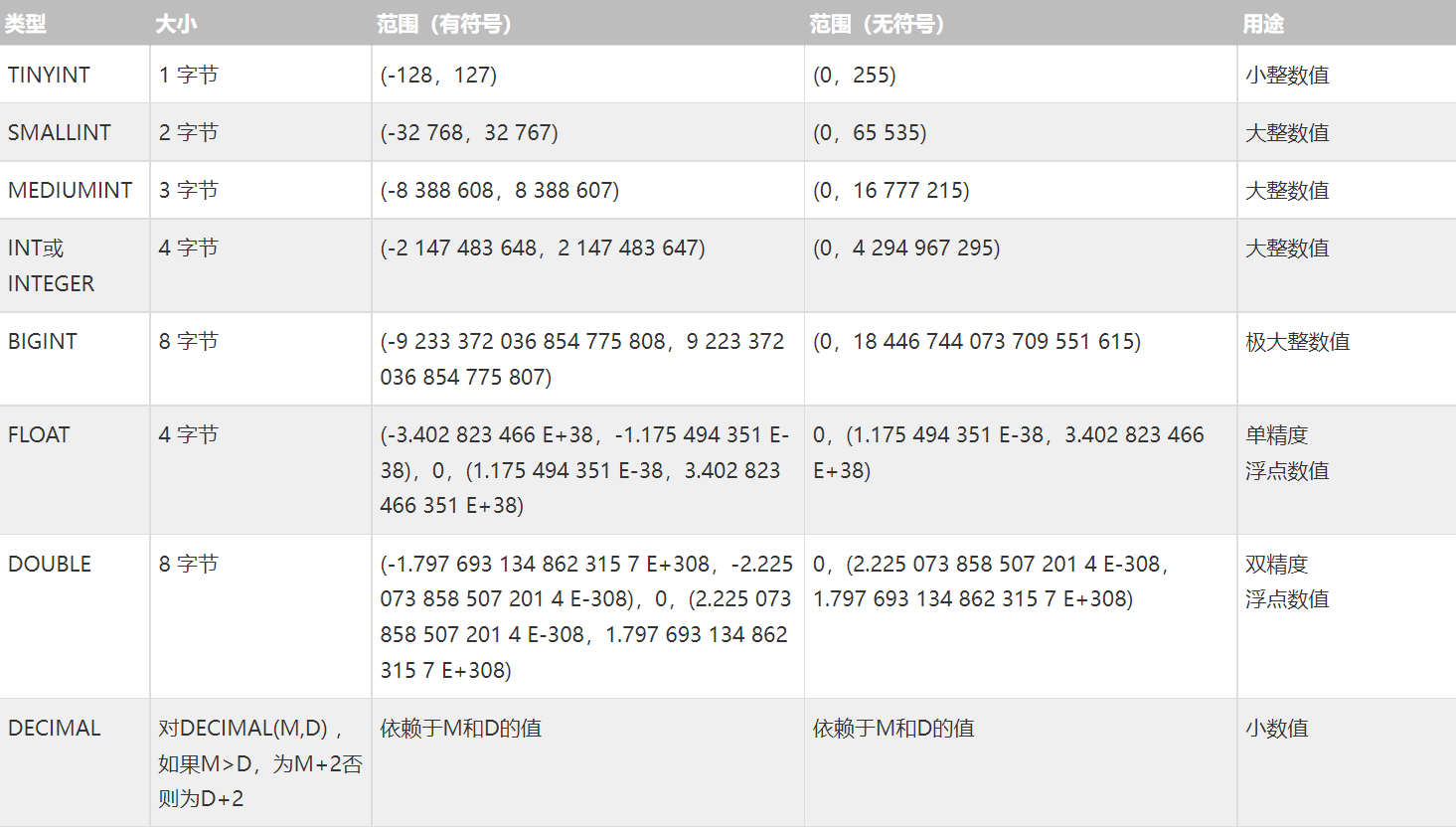
例如:decimal(m,d)
m是数字的最大位数,范围是1-65
d是小数点后的位数,范围是0-30,并且不能大于m
如果m被省略了,m的值默认为10
如果d被省略了,d的值默认为0
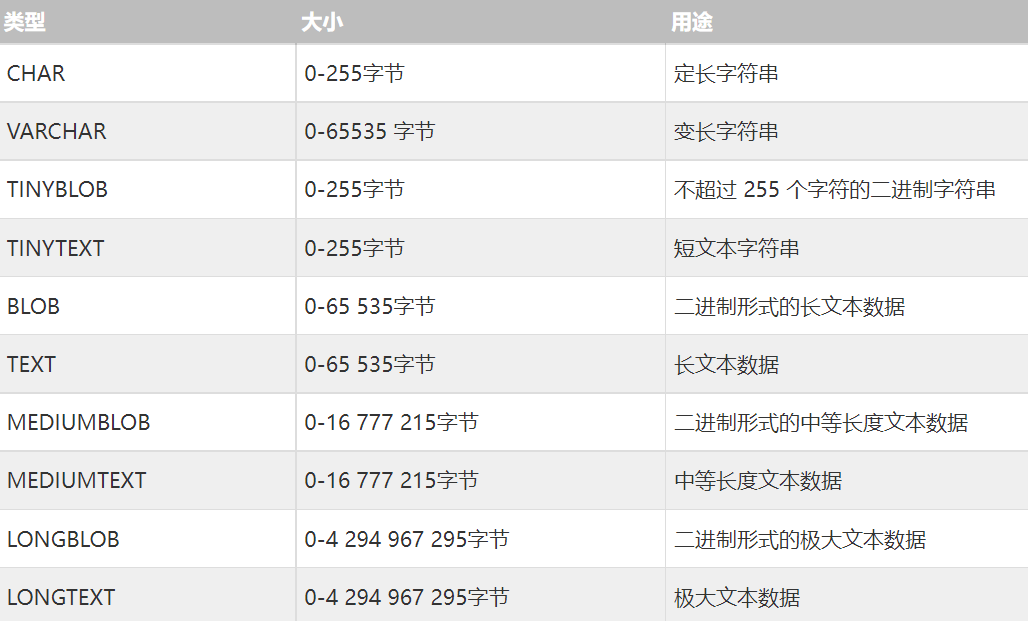
字符和字符串类型
建议对含有大文本类型的字段进行垂直拆分,把大文本字段拆分到子表
日期类型
MySQL索引的数据结构
Hash
hash表本质是一个数组,每一个下标下挂载一个数据桶,以链表的方式实现数据的存储
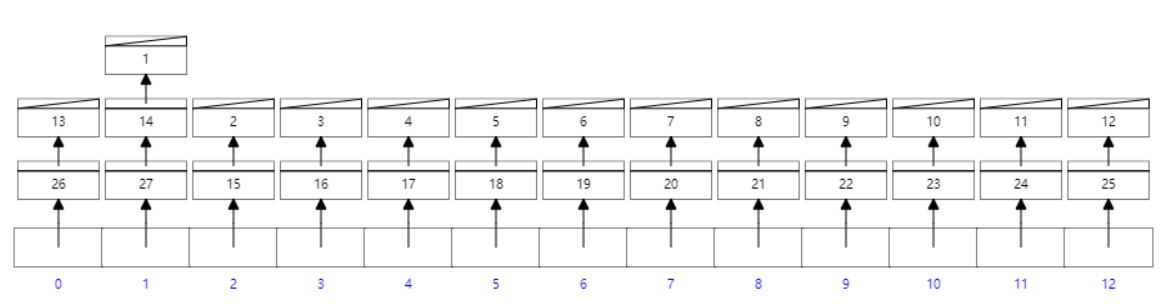
对hash的算法要求比较高,否则会导致数据散列不均,浪费存储空间
查询数据的时候,需要将全量的数据加载到内存,数据量大的情况下非常耗内存
适合做等值查询,如果按照范围查询则非常慢
二叉树
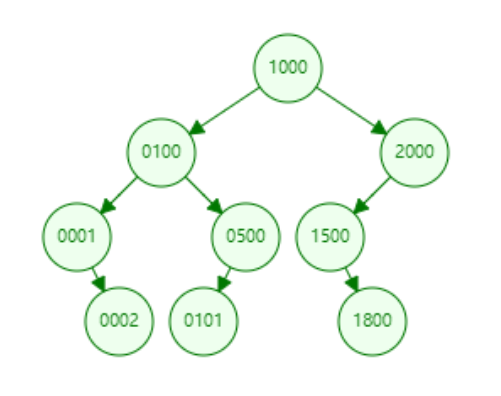

- 特点
左子节点值小于自身
右子节点值大于自身
中序遍历是递增有序
二叉树添加、删除、查询数据的时间复杂度为O ( log2N )
如果添加的数据是递减或递增时,则会出现左倾和右倾,最终退化成链表,添加、删除、查询数据的时间复杂度为O(N)
AVL - 平衡二叉树
为了解决二叉树左倾和右倾的问题,平衡二叉树中要求左子树和右子树的高度差不能超过1,如果超过1则会触发左旋或右旋来保持树的平衡。查找数据的最坏时间复杂度也为O(log2N),频繁插入/删除时会触发旋转使得AVL的性能大打折扣
下面以连续添加1、2、3、4、5的数据为例:
- 添加数据1

- 添加数据2
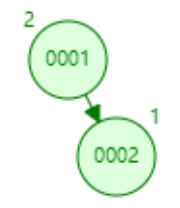
- 添加数据3(触发左旋)
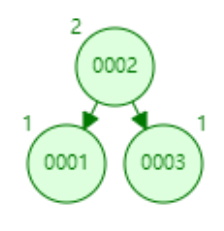
- 添加数据4
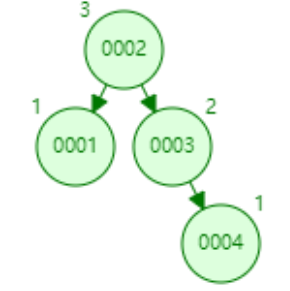
- 添加数据5(触发左旋)

红黑树
- 红黑树的5个特性
性质1. 根节点是黑色
性质2. 节点是红色或黑色
性质3. 叶节点(NIL节点,空节点)是黑色
性质4. 每个红色节点的两个子节点都是黑色。(从每个叶子到根的所有路径上不能有两个连续的红色节点)
性质5. 从任一节点到其每个叶子的所有路径都包含相同数目的黑色节点
性质4和5保证了:从根到叶子的最长路径不能超过最短路径的2倍长,保证了这个树大致上是平衡的
红黑树和AVL树类似,都是在进行插入和删除操作时通过特定操作保持二叉查找树的平衡,从而获得较高的查找性能
红黑树是每个节点都带有颜色(红色或黑色)属性的平衡二叉树,通过牺牲平衡性(相对平衡),换取插入/删除时少量的旋转操作,整体性能优于AVL
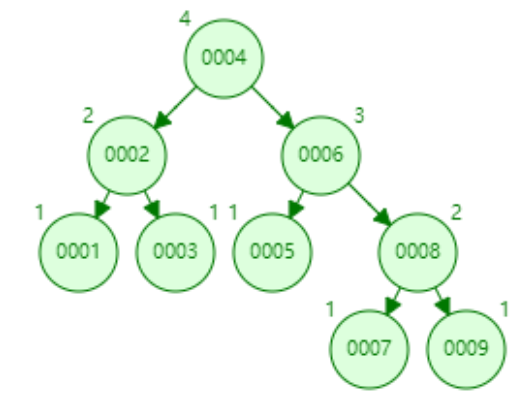
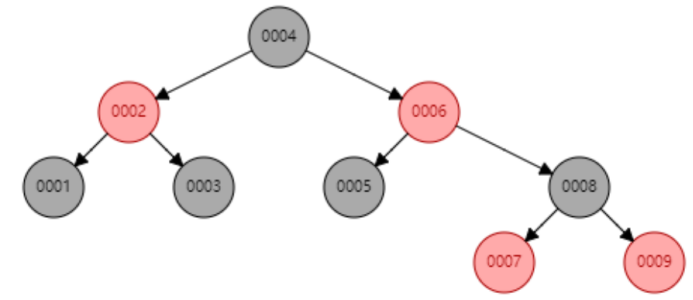
下面以连续添加 1、2、3、4、5、6、7、8、9 为例:
- 添加数据1【左边是平衡二叉树、右边是红黑树】

- 添加数据2
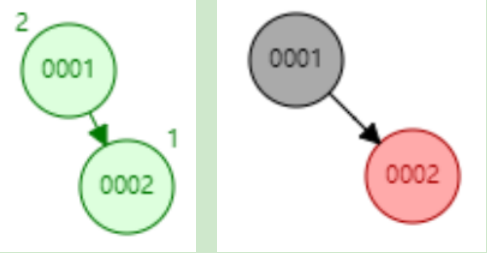
- 添加数据3
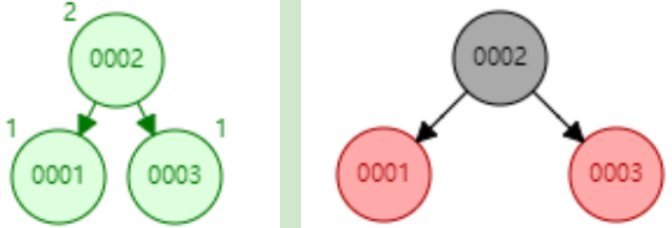
- 添加数据4
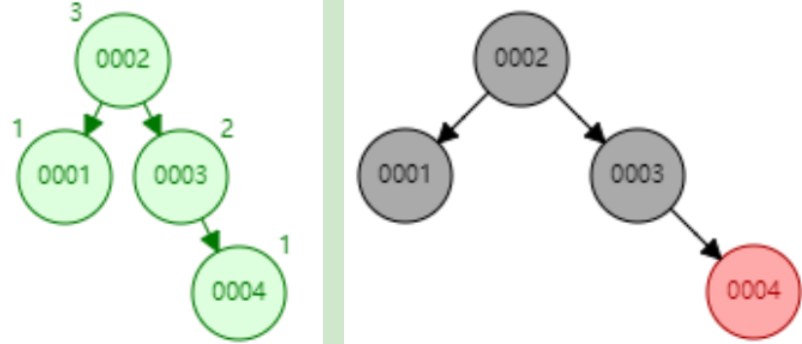
- 添加数据5
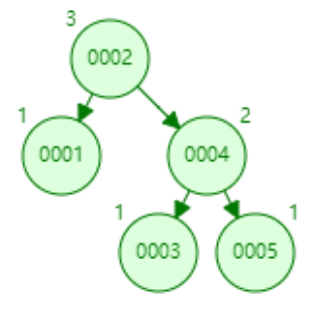

- 添加数据6
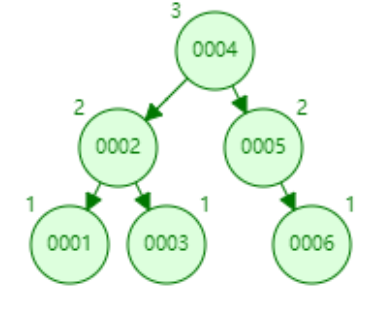
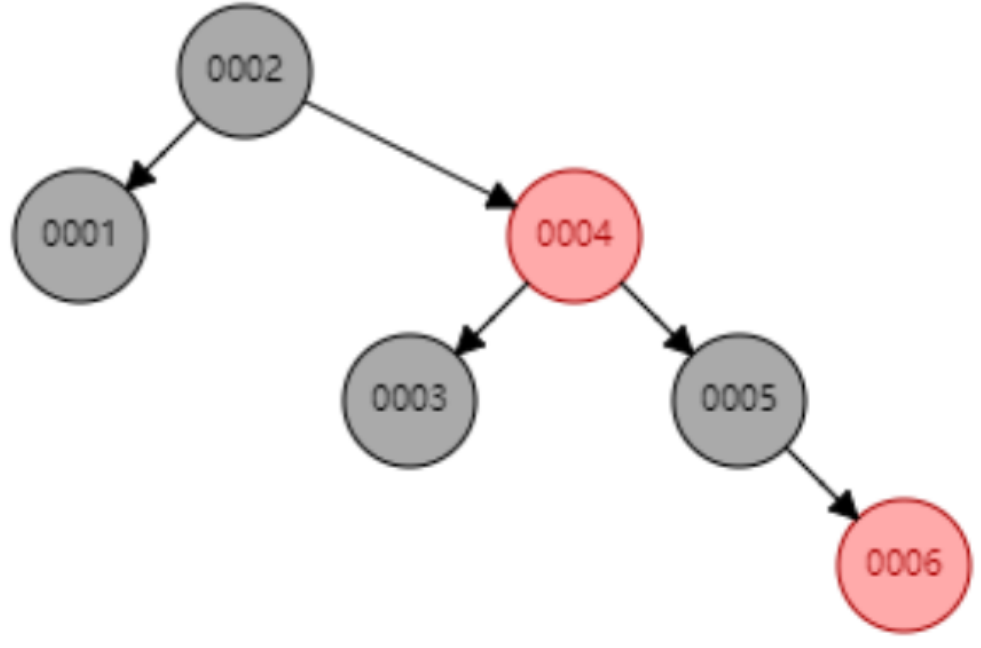
- 添加数据7
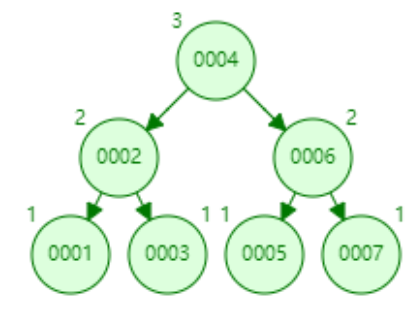
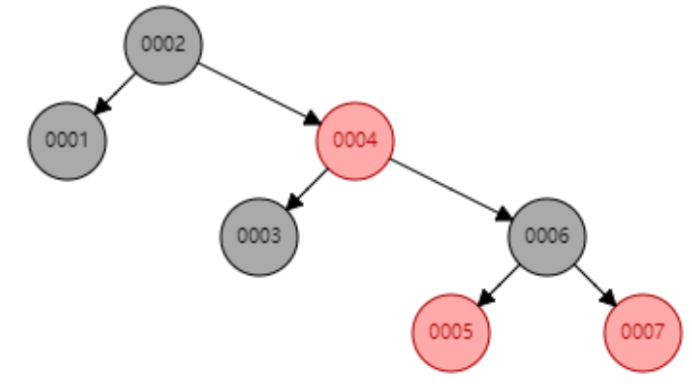
- 添加数据8
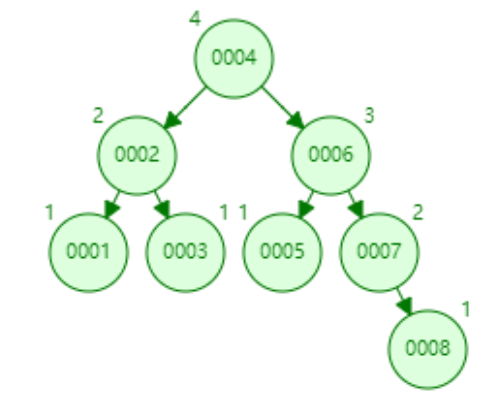
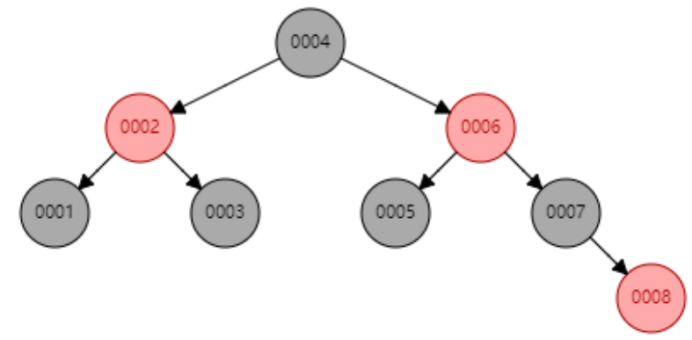
- 添加数据9
BTree 数据结构
不论什么类型的二叉树,随着数据的增加,树的深度会增加,那么IO的查询次数也会随之增加
B树中有一个叫做度的概念,默认度为3,表示该节点做多可以存储2个key(每个key对应一个data数据区)和3个节点的应用,当节点存储的key超过2时就会触发自动分裂
B树查找的时间复杂度为O(h * lgn),h为树高,n为每个节点存储key的数量,在数据量相同的情况下,B数据的高度要低于平衡二叉树,减少了IO查询次数
InnoDB存储引擎默认读取单位为页(16kb),而B树的key都会挂载一个data数据区,就会导致每页读取的key数量变少,当存储的数据量很大时,树的高度会更深,查询的IO次数会变多
下面以连续添加 1、2、3、4、5、6、7、8、9 为例:
- 添加数据1(左平衡二叉树,右B树)

- 添加数据2
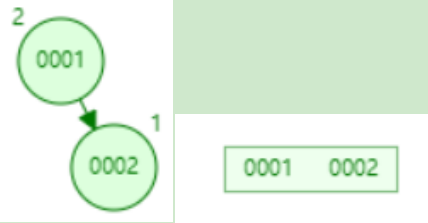
- 添加数据3
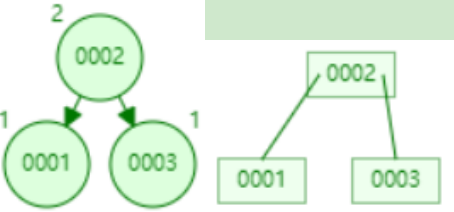
- 添加数据4
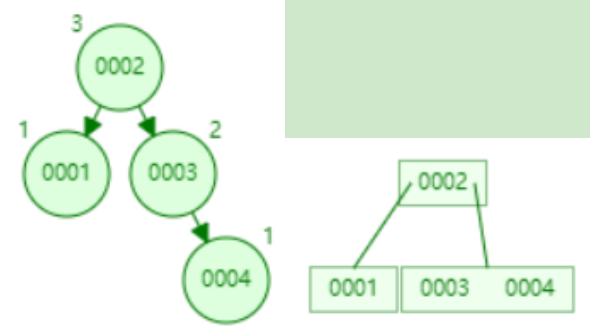
- 添加数据5
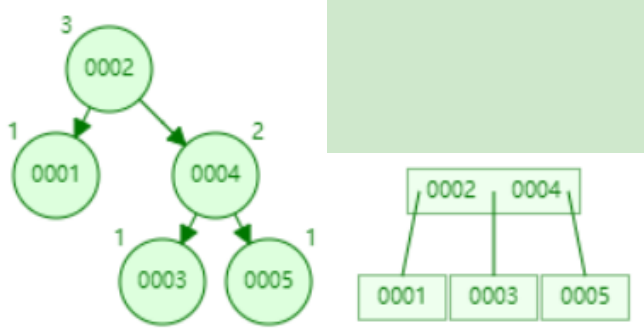
- 添加数据6
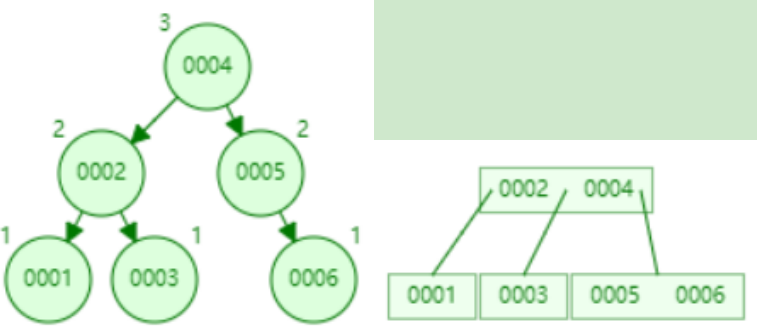
- 添加数据7
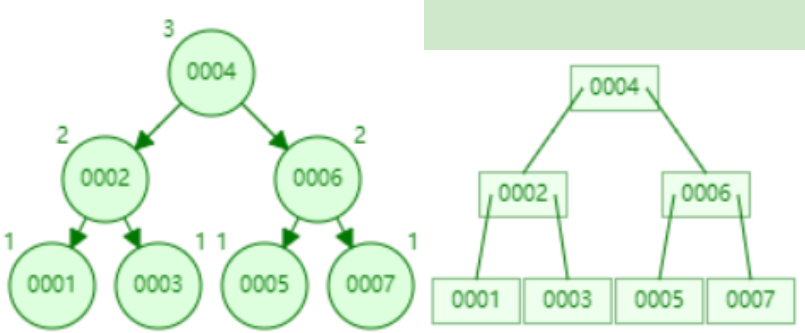
- 添加数据8

- 添加数据9
B+Tree 数据结构
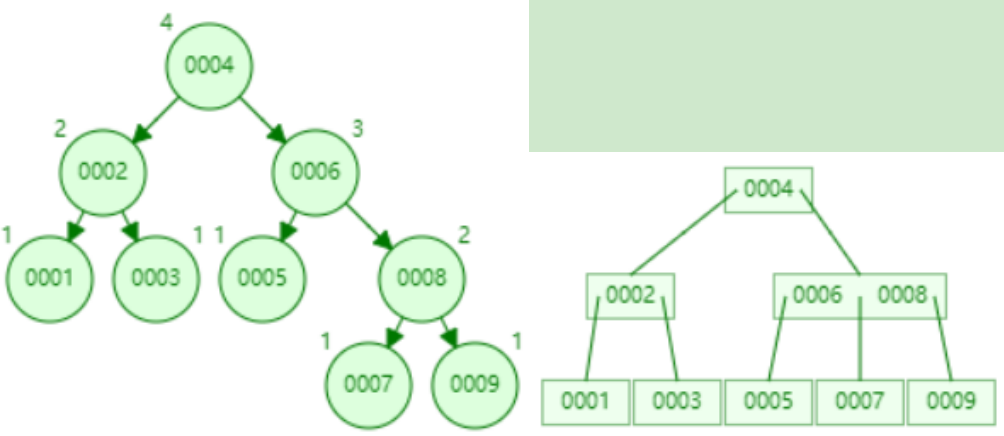
B+树中的根节点和支节点存储的是(关键字和节点引用),相比于B树,单位节点要存储更多的关键字,数据量相同的情况下,B+树的高度要小于B树
B+树的叶子节点存储的是(关键字和数据区),叶子节点是顺序排列的并且相邻叶子节点具有相互引用的关系,非常适合排序
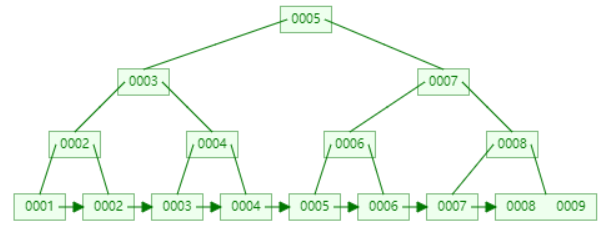
下面以连续添加 1、2、3、4、5、6、7、8、9 为例:
- 添加数据1

- 添加数据2
- 添加数据3
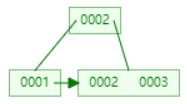
- 添加数据4
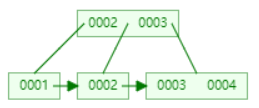
- 添加数据5
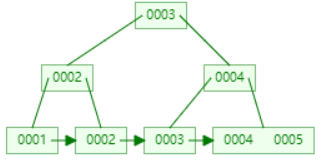
- 添加数据6
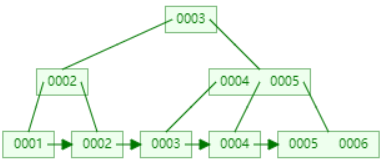
- 添加数据7
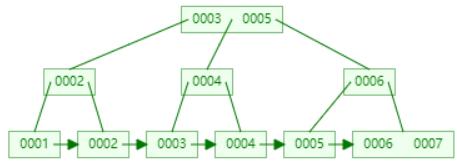
- 添加数据8

- 添加数据9
MySQL索引
满足业务情况下,创建索引的原则
建议使用自增长作为主键
索引列的数据不建议为空,为空反而会消耗更多的存储空间
索引列的数据类型占用存储空间越少越好,因为索引本身也是占用磁盘空间的
索引列的数据重复率不要超过80%,否则索引会失效。针对重复率高的字段可以使用枚举类型
频繁更新的列不要创建索引
-
普通索引
普通索引是最基本的索引,仅用于加速查询,没有任何限制:可以为空、可以重复 -
唯一索引
唯一索引与普通索引类似,但索引列的值必须唯一 -
主键索引
主键索引是一种特殊的唯一索引,一个表只能有一个主键,不允许有空值 -
组合索引(复合索引)
组合索引是多列值组成的一个索引,专门用于组合搜索,使用组合索引时遵循最左前缀原则 -
全文索引
全文索引主要用来查找文本中的关键字,而不是直接与索引中的值相比较,目前只有char、varchar,text 列上可以创建全文索引
MySQL存储引擎
| 存储引擎 | MyISAM | InnoDB |
|---|---|---|
| 支持事务 | 否 | 是 |
| 支持行锁 | 否 | 是 |
| 支持外键 | 否 | 是 |
| 支持表锁 | 是 | 是 |
| 支持全文索引 | 是 | 5.6+支持 |
| 适合的操作类型 | 大量查询 | 大量的添加、删除、修改 |
| MySQL默认存储引擎为InnoDB,可以通过修改配置文件的方式来指定MyISAM |
MyISAM
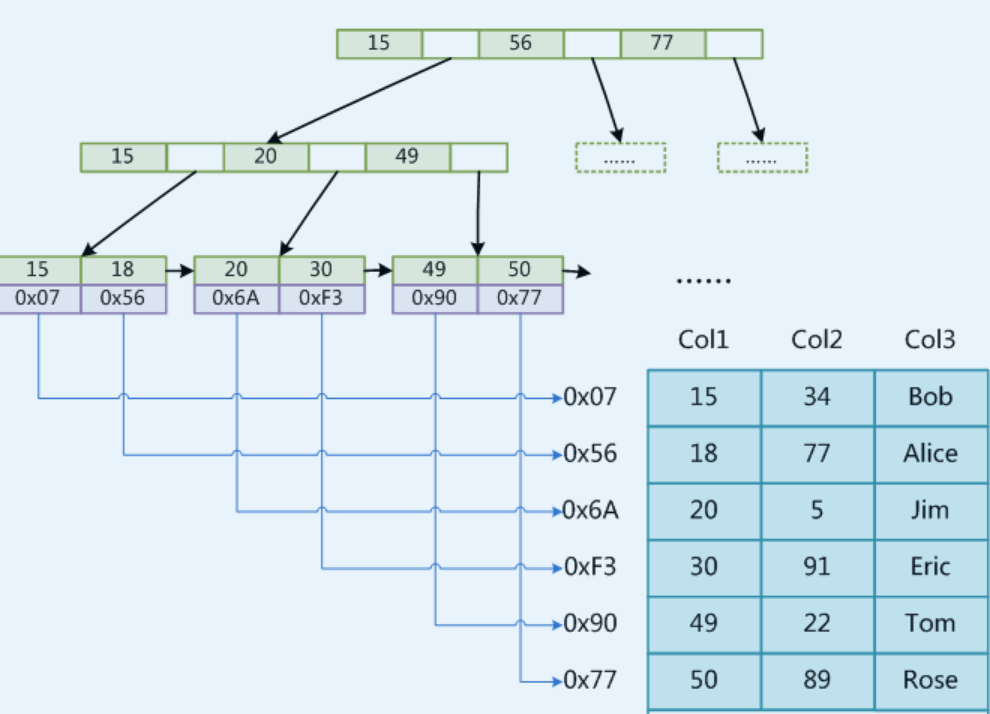
该数据引擎中只有非聚簇索引,非聚簇索引的key和data是分开存储的】
MyISAM使用B+Tree作为索引结构时,叶节点的data域存放的是数据记录的内存地址
InnoDB
MySQL 默认数据引擎 InnoDB 中,数据在进行添加时必须和某一个索引列进行绑定,绑定优先级如下:
1、如果有主键,则和主键进行绑定
2、如果没有主键,则和唯一键进行绑定
3、如果没有唯一键,则根据系统生成的6字节rowid进行绑定
结论:和数据进行绑定的索引称之为聚簇索引,反之为非聚簇索引。一张表中只能有一个聚簇索引,非聚簇索引可以有多个
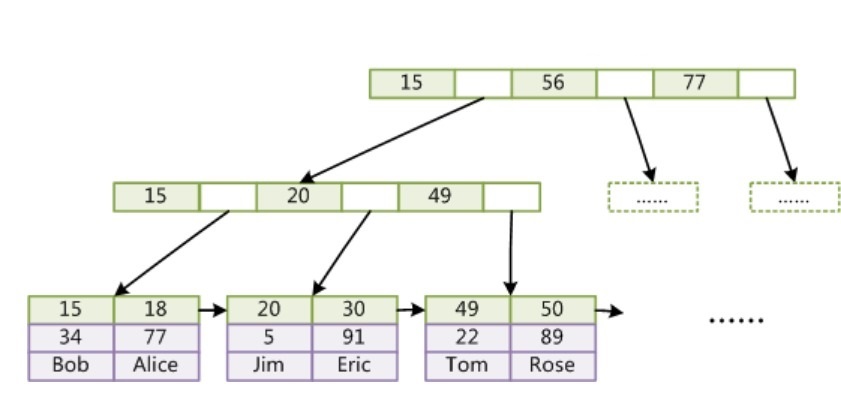
InnoDB引擎使用B+Tree作为索引结构时,聚簇索引中叶子节点的data域存放的是完整的数据记录
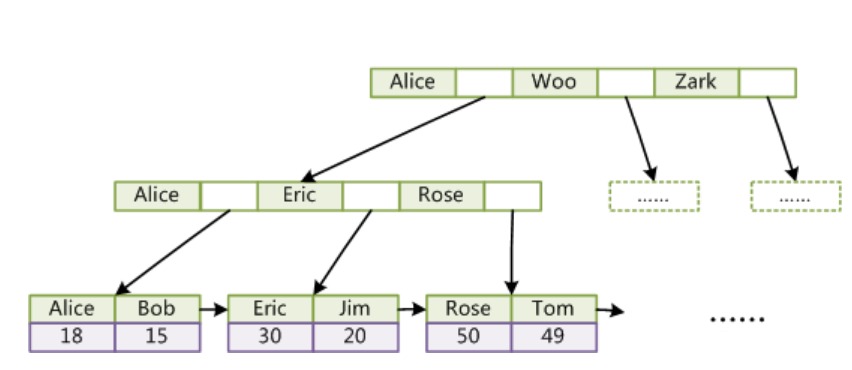
InnoDB引擎使用B+Tree作为索引结构时,非聚簇索引中叶子节点的data域存放的是主键,通过非聚簇索引搜索时需要通过主键来回查
MySQL执行计划 - explain
- 测试数据
SET NAMES utf8mb4;
SET FOREIGN_KEY_CHECKS = 0;
-- ----------------------------
-- Table structure for demo_department
-- ----------------------------
DROP TABLE IF EXISTS `demo_department`;
CREATE TABLE `demo_department` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键',
`code` varchar(10) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '编号',
`name` varchar(10) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '名称',
`remark` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL DEFAULT '' COMMENT '介绍',
PRIMARY KEY (`id`) USING BTREE,
UNIQUE INDEX `index_code`(`code`) USING BTREE,
INDEX `index_name`(`name`) USING BTREE,
FULLTEXT INDEX `index_remark`(`remark`)
) ENGINE = InnoDB AUTO_INCREMENT = 79 CHARACTER SET = utf8 COLLATE = utf8_general_ci COMMENT = '部门表' ROW_FORMAT = Dynamic;
-- ----------------------------
-- Table structure for demo_staff
-- ----------------------------
DROP TABLE IF EXISTS `demo_staff`;
CREATE TABLE `demo_staff` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键',
`department_code` varchar(10) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '部门编号',
`code` varchar(10) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '编号',
`position` varchar(225) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '职位',
`name` varchar(225) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '名称',
`age` tinyint(3) NOT NULL COMMENT '年龄',
`sex` enum('男','女') CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL DEFAULT '男' COMMENT '性别',
`remark` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL DEFAULT '' COMMENT '介绍',
PRIMARY KEY (`id`) USING BTREE,
INDEX `index_department_code`(`department_code`) USING BTREE
UNIQUE INDEX `index_code`(`code`) USING BTREE,
INDEX `index_position_name_age`(`position`, `name`, `age`) USING BTREE,
) ENGINE = InnoDB AUTO_INCREMENT = 1380 CHARACTER SET = utf8 COLLATE = utf8_general_ci COMMENT = '员工表' ROW_FORMAT = Dynamic;
-- ----------------------------
-- Table structure for demo_wages
-- ----------------------------
DROP TABLE IF EXISTS `demo_wages`;
CREATE TABLE `demo_wages` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键',
`staff_code` varchar(10) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '员工编号',
`foundation_score` smallint(11) NOT NULL DEFAULT 0 COMMENT '基础工资',
`performance_score` decimal(10, 2) NOT NULL DEFAULT 0.00 COMMENT '绩效工资',
PRIMARY KEY (`id`) USING BTREE,
UNIQUE INDEX `index_staff_code`(`staff_code`) USING BTREE,
INDEX `index_foundation_performance`(`foundation_score`, `performance_score`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 2029 CHARACTER SET = utf8 COLLATE = utf8_general_ci COMMENT = '工资表' ROW_FORMAT = Dynamic;
执行计划相关字段说明

id【表示查询中执行select子句或操作表的顺序】
select_type【查询类型】
sample: 简单查询,不包含子查询和union
primary: 查询中包含任何复杂的子查询,则最外层的查询将被标记为Primary
union: 若第二个select出现在union之后,则被标记为union
dependent union: 与union类似,此处表示 union 或 union all 联合而成的结果会受外部表影响
union result: 从 union 表获取结果的select
subquery: 在select或where列表中包含子查询
dependent subquery: subquery的子查询要受到外部表查询的影响
derived: from子句中出现的子查询
type【访问类型】,访问效率从高到低以此为:一般情况下,查询至少达到range级别,最好能达到ref级别
system >
const > 该表至多有一个匹配行
eq_ret > 利用唯一索引进行数据查找
ref > 利用非唯一索引进行数据查找
ref_or_null >
index_merge > 查询过程中,需要多个索引来组合使用
unique_subquery > 利用唯一索引来关联子查询
index_subquery > 利用索引来关联子查询
range > 利用索引查询的时候限制了范围
index > 全索引扫描
all 全表扫描
possible_keys【查询时可能用到的索引】
key【查询时实际使用到的索引】
key_len【索引中使用的字节数】
ref【显示索引的哪一列被使用了】
rows【找出所需记录需要读取的行】
extra【额外信息】
using filesort: 无法利用索引进行排序,只能利用排序算法进行排序
using temporary: 建立临时表来保存中间结果,查询完成后把临时表删除
using index: 使用了覆盖索引,索引被用来读取数据,而非真正的查找。如果与using where同时出现,表明索引被用来执行索引键值的查找
using where: 使用where进行条件过滤
using join buffer: 使用连接缓存
回表查询
非聚簇索引的叶子节点上存储的是主键ID,在使用非聚簇索引查询时返回的是主键ID,再根据主键ID去聚簇索引上查找最终的数据

覆盖索引
当查询字段(select列)和 查询条件字段(where子句)全都包含在一个索引 (普通索引、唯一索引、联合索引)中时,可以直接使用索引查询而不需要回表

组合索引 - 最左匹配原则
EXPLAIN
SELECT * FROM demo_staff WHERE position = '职位名称<63>';
EXPLAIN
SELECT * FROM demo_staff WHERE position = '职位名称<63>' AND `name` = '员工姓名<995765511>' AND age = '58';
EXPLAIN -- 优化器会自动优化 name 和 age 的顺序
SELECT * FROM demo_staff WHERE position = '职位名称<63>' AND age = '58' AND `name` = '员工姓名<995765511>';

模糊搜索 - like
EXPLAIN
SELECT * FROM demo_staff WHERE position like'职位名称<6%';

文本索引
EXPLAIN
SELECT * FROM demo_department WHERE MATCH ( remark ) against ( 'JVM' );

隐式转化 - 数据类型不匹配

对查询条件进行计算或使用函数
注意:mysql8.0开始,通过函数索引可以避免索引字段使用函数时失效的情况
or(不推荐)

注意1:or两边的字段不同时,两边的索引都要生效才行


注意2:or连接的字段相同时,or 条件很多的情况下,可以使用in来优化
is null(不推荐)
注意:null 数据超过80%时索引会失效,不建议使用,建议使用默认值代替

is not null(不推荐)
注意:is not null 数据超过80%时索引会失效,不建议使用,建议使用默认值代替

in 和 exists
select * from A where id in (select id from B)
# in里面的B表先执行,适合外表A大而内表B小
select * from A where exists(select * from B where B.id=A.id)
# exists以外层A表为驱动表,适合外表A小而内表B大
not in(不推荐)
– 优化方案:左连接,条件:至少需要2个查询条件命中索引
select user_id from order_count where user_id not in ('1649123035720','1649123035724');
select
temp1.*,
temp2.user_id as userId
from order_count temp1
left join (select user_id from order_count where user_id in ('1649123035720','1649123035724')) temp2
on temp1.user_id = temp2.user_id
where temp1.user_id = '1649123035728' and temp2.user_id is null;
limit 优化
对于 limit m,n 分页查询,越往后面翻页(即m越大的情况下)SQL的耗时会越来越长。当检索数据为 limit m,n 时,则需要排序前 m+n 条记录,最终只返回 m和m+n 间的 n 条数据,其他数据丢弃
使用索引覆盖 + 子查询优化
因为有主键 id,并且在上面建了索引,所以可以先在索引树中找到开始位置的 id 值,再根据找到的 id 值查询行数据
select id,name from table_name where id > (select id from table_name order by id limit 866612, 1)
起始位置重定义(效率最高)
可以取前一页的最大行数的id(将上次遍历到的最末尾的数据ID传给数据库,然后直接定位到该ID处,再往后面遍历数据),然后根据这个最大的id来限制下一页的起点。比如此列中,上一页最大的id是866612
select id,name from table_name where id > 866612 limit 20
join 连表优化
连表查询最好不要超过三张表,连表时需要join的字段类型必须一致,否则会造成慢查询
可通过 EXPLANIN 查看SQL语句的执行计划,EXPLANIN分析的第一行的表即是驱动表
连接类型
- 内连接:INNER JOIN【求两个表的交集】【自动选择数据量小的表作为驱动表,大表作为被驱动表】
- 左连接:LEFT JOIN【求两个表的交集外加左表剩下的数据】【左边为驱动表,右边为被驱动表】
- 右连接:RIGHT JOIN【求两个表的交集外加右表剩下的数据】【右边为驱动表,左边为被驱动表】
连表算法 - 嵌套循环连接【Nested-Loop Join】
-
Simpe Nested-Loop Join
外层循环遍历a表,内层循环则遍历b表,如果满足连接条件,则组合两个表的列输出,最终生成连接后的临时表 -
Index Nested-Loop Join
通过外层表的匹配列的值直接与内层表匹配列的索引进行匹配,再遍历匹配上的记录进行匹配、合并、输出 -
Block Nested-Loop Join
通过缓存外层表的多条数据到Join Buffer里(通常是HASH表),然后批量与内层表的数据进行匹配、合并、输出。当内层表的匹配列不存在索引时可以使用Block Nested Loop Join
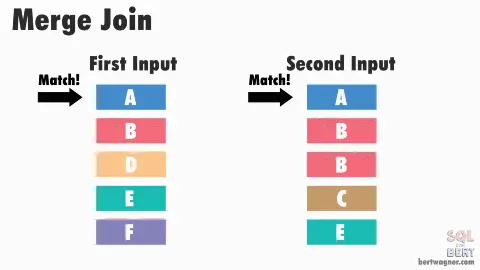
连表算法 - 排序合并连接【SORT MERGE JOIN】
排序合并连接SORT MERGE JOIN 也是嵌套循环连接 NESTED LOOP JOIN 的一种变体。 该算法要求连接中的两个数据集有序,如果数据集尚未排序,则需要先对它们进行排序
MySQL性能监控工具 - Performance Schema
Performance Schema 默认是开启的,如果需要关闭,必须通过修改 /etc/my.cnf 文件,一般不建议关闭
查看具体配置项的开启情况
select * from setup_instruments;
select * from setup_consumers;
update setup_instruments set ENABLED = 'YES',TIMED = 'YES' where `NAME` like 'wait%';
update setup_consumers set ENABLED = 'YES' where `NAME` like 'wait%';
监控数据库的连接情况
show processlist;
常用统计sql
--1、哪类的 SQL 执行最多?
SELECT DIGEST_TEXT, COUNT_STAR, FIRST_SEEN,LAST_SEEN FROM events_statements_summary_by_digest ORDER BY COUNT_STAR DESC;
--2、哪类 SQL 的平均响应时间最多?
SELECT DIGEST_TEXT,AVG_TIMER_WAIT FROM events_statements_summary_by_digest ORDER BY COUNT_STAR DESC;
--3、哪类 SQL 排序记录数最多?
SELECT DIGEST_TEXT, SUM_SORT_ROWS FROM events_statements_summary_by_digest ORDER BY COUNT_STAR DESC;
--4、哪类 SQL 扫描记录数最多?
SELECT DIGEST_TEXT,SUM_ROWS_EXAMINED FROM events_statements_summary_by_digest ORDER BY COUNT_STAR DESC;
--5、哪类 SQL 使用临时表最多?
SELECT DIGEST_TEXT,SUM_CREATED_TMP_TABLES,SUM_CREATED_TMP_DISK_TABLES FROM events_statements_summary_by_digest
ORDER BY COUNT_STAR DESC;
--6、哪类 SQL 返回结果集最多?
SELECT DIGEST_TEXT,SUM_ROWS_SENT FROM events_statements_summary_by_digest ORDER BY COUNT_STAR DESC;
--7、哪个表物理 IO 最多?
SELECT file_name, event_name, SUM_NUMBER_OF_BYTES_READ,SUM_NUMBER_OF_BYTES_WRITE FROM file_summary_by_instance
ORDER BY SUM_NUMBER_OF_BYTES_READ + SUM_NUMBER_OF_BYTES_WRITE DESC;
--8、哪个表逻辑 IO 最多?
SELECT object_name,COUNT_READ, COUNT_WRITE, COUNT_FETCH,SUM_TIMER_WAIT FROM table_io_waits_summary_by_table
ORDER BY sum_timer_wait DESC;
--9、哪个素引访问最多?
SELECT OBJECT_NAME, INDEX_NAME,COUNT_FETCH,COUNT_INSERT,COUNT_UPDATE,COUNT_DELETE FROM table_io_waits_summary_by_index_usage
ORDER BY SUM_TIMER_WAIT DESC;
--10、哪个索引从来没有用过?
SELECT OBJECT_SCHEMA, OBJECT_NAME, INDEX_NAME FROM table_io_waits_summary_by_index_usage
WHERE INDEX_NAME IS NOT NULL AND COUNT_STAR = 0 AND OBJECT_SCHEMA < 'mysal'
ORDER BY OBJECT_SCHEMA,OBJECT_NAME;
--11、哪个等待事件消耗时间最多?
SELECT EVENT_NAME,COUNT_STAR,SUM_TIMER_WAIT,AVG_TIMER_WAIT FROM events_waits_summary_global_by_event_name
WHERE event_name != 'idle'
ORDER BY SUM_TIMER_WAIT DESC;
--12-1、剖析某条 SQL 的执行情况,包括 statement 信息,stege 信息,wait 信息
SELECT EVENT_ID,sqL_text FROM events_statements_history WHERE sql_text LIKE '*%count(*)%';
--12-2、查看每个阶段的时间消耗
SELECT event_id, EVENT_NAME,SOURCE, TIMER_END - TIMER_START FROM events_stages_history_long WHERE NESTING_EVENT_ID = 1553;
--12-3、查看每个阶段的锁等待情况
SELECT event_id, event_name,source,timer_wait,object_name, index_name, operation,nesting_event_id FROM events_waits_history_long WHERE nesting_event_id = 1553;
















 3642
3642











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











