









前言
stanford是著名的斯坦福大学自然语言处理工具包,现在支持的语言不仅仅是英语,而可以支持多方国家语言,中文就是其中的一部分.python中也有对应的nltk库,但核心的源代码还是JAVA.所以,我分享一些关于在eclipse中怎么使用stanford的过程
stanford的安装使用
我将stanford的相关jar包放到了我的百度云,不过也可以去官网下载(有点慢)
https://pan.baidu.com/s/1slnbQu5
将这些jar包导入项目中就好啦,有时候jvm容量可能hold不住,可以使其扩容,具体可以参照这份博客:
http://blog.csdn.net/qq_30843221/article/details/52316444
安装好就这样啦:
stanford的代码样例
由于我在使用stndford的中文分词的过程中老报错,所以我改用了hanlp来作分词,stanford来对分词后的结果构建依存关系树.关于hanlp的使用可以参照:
http://blog.csdn.net/qq_30843221/article/details/52326254
import java.util.ArrayList;
import java.util.List;
import com.hankcs.hanlp.HanLP;
import com.hankcs.hanlp.seg.Segment;
import com.hankcs.hanlp.seg.common.Term;
import edu.stanford.nlp.ling.CoreLabel;
import edu.stanford.nlp.parser.lexparser.LexicalizedParser;
import edu.stanford.nlp.trees.GrammaticalStructure;
import edu.stanford.nlp.trees.GrammaticalStructureFactory;
import edu.stanford.nlp.trees.Tree;
import edu.stanford.nlp.trees.TreebankLanguagePack;
import edu.stanford.nlp.trees.TypedDependency;
public class DemoStandFord {
public static void main(String[] agrs) throws Exception{
LexicalizedParser lp = LexicalizedParser.loadModel("edu/stanford/nlp/models/lexparser/chinesePCFG.ser.gz");
String sentence = new String("大家好,我的名字叫作Quincy.");
Segment segment = HanLP.newSegment(); //使用了HanLP来进行分词
List<Term> termList = segment.seg(sentence);
StringBuilder termsBuilder = new StringBuilder();
for(Term term: termList){
termsBuilder.append(term.word + " "); //只保存词原,不保留词性
}
String[] terms = termsBuilder.toString().split(" "); //分词后的结果:[大家 好 我 的 名字 叫 作 Quincy ]
List<CoreLabel> rawWords = new ArrayList<CoreLabel>(); //将分词结果映射成为词条库
for(String word: terms){
CoreLabel l = new CoreLabel();
l.setWord(word);
rawWords.add(l);
}
Tree parse = lp.apply(rawWords);
parse.pennPrint();
System.out.println();
TreebankLanguagePack tlp = lp.getOp().langpack();
GrammaticalStructureFactory gsf = tlp.grammaticalStructureFactory();
GrammaticalStructure gs = gsf.newGrammaticalStructure(parse);
List<TypedDependency> tdl = gs.typedDependenciesCCprocessed();
System.out.println(tdl);
}
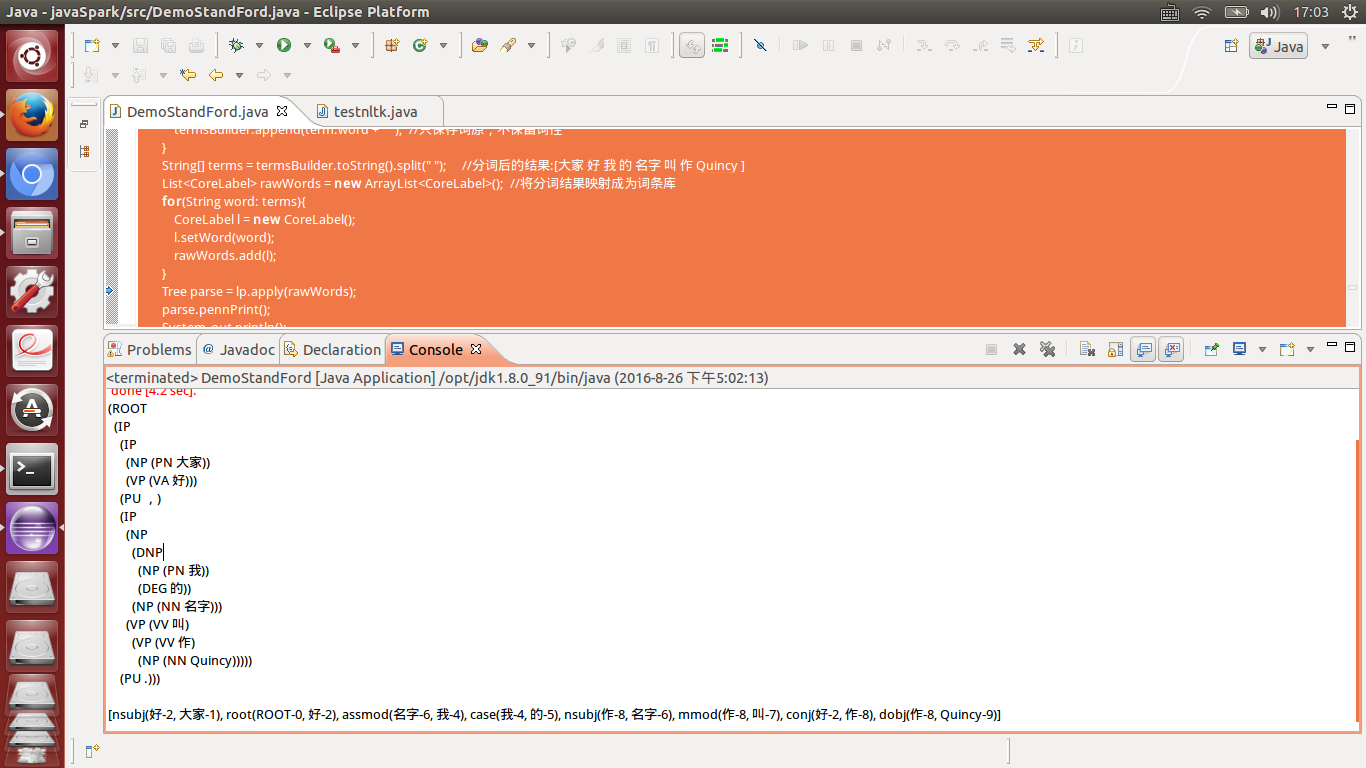
}结果效果图:
stanford的依存关系资料可以参照:
https://github.com/Quincy1994/standfordParser/blob/master/Stanford%E4%BE%9D%E5%AD%98%E5%8F%A5%E6%B3%95%E5%85%B3%E7%B3%BB%E8%A7%A3%E9%87%8A.docx















 724
724

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









