







1 项目介绍
本项目旨在构建一个基于Python的图书借阅分析系统,融合MySQL数据库技术、KMeans聚类算法、Apriori关联规则学习及ARIMA时间序列预测模型,以期为图书馆管理提供深度的数据洞察与决策支持。面对图书馆管理智能化转型的需求,该项目针对当前图书馆在预测借阅趋势、细分读者需求上的挑战,提出了一套综合解决方案。
首先,通过MySQL数据库高效存储和管理图书借阅的大量数据,确保了数据处理的安全性和便捷性。接着,应用KMeans算法对读者群体进行细分,根据借阅行为的特征,如频率和偏好类型,识别出不同阅读习惯的读者群体,为个性化服务策略奠定基础。
在此基础上,利用Apriori算法分析借阅记录,揭示书籍借阅间的隐藏关联,帮助图书馆优化书籍布局,促进相关书籍的有效推荐。此外,系统还采用了ARIMA模型对图书借阅趋势进行精确预测,通过对历史数据的深入分析,科学预估未来的借阅需求,为图书馆资源调度和库存管理提供前瞻性的指导。
总之,该系统不仅显著增强了图书馆的服务质量和资源利用效率,还通过数据驱动的决策支持,推动了图书馆管理向更高层次的智能化迈进,其实践价值和推广潜力不言而喻。
1.1 系统技术栈
后端:Python
前端:Flask
线性回归预算算法:Sk-learn
关联规则挖掘算法:aproori
聚类算法:K-means
时间序列预测:arima
基于Python和Flask框架的图书借阅分析系统:前端采用 Flask web框架;后端采用Python框架;数据库使用MySQL;数据预测使用的是sklean算法;读者阅读偏好分析采用的是K-means算法、apriori算法、arima算法将这三种算法都实现出来在界面进行对比展示。
1.2 系统角色
管理员
用户
1.3 功能介绍:
登录
首页
权限管理
用户管理
数据展示
数据分析
信息词云分析
k-means
aproori
arima
1.4 系统功能框架图
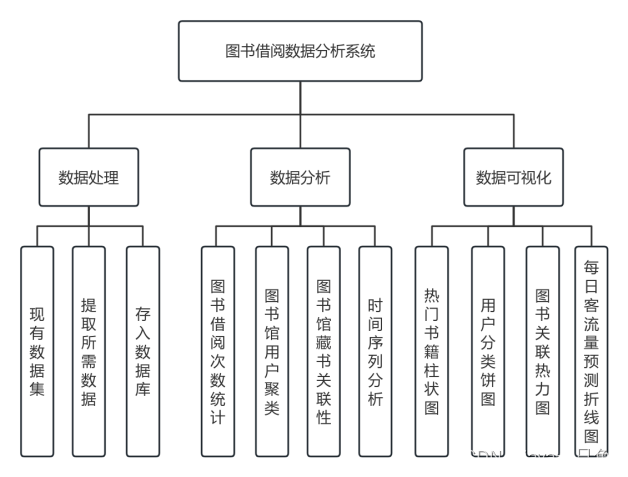
2.系统运行截图
2.1 登录
2.2 首页

2.3 用户管理
2.4 角色管理
2.5 数据展示
2.6 数据分析

2.7 词云

2.8 k-means
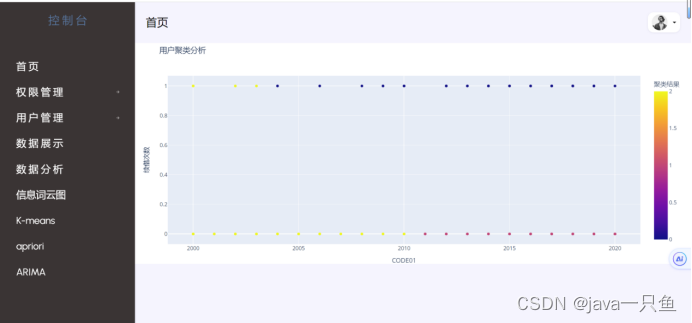
2.9 apriori
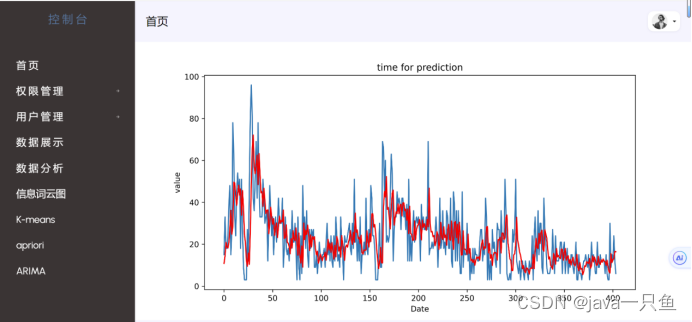
3.0 arima
编码不易需要源码和文档的用户加微信 Mrzys1















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









