







1 项目介绍
1.1 研究目的和意义
随着大数据时代的到来,电影产业积累了海量的用户评论数据,这些数据中蕴含着观众的情感倾向与偏好信息,为电影推荐和市场策略制定提供了宝贵资源。然而,如何高效地从这浩瀚的数据海洋中提炼出有价值的情感洞察成为一大挑战。针对这一背景,开发一个高效的大数据电影评论情感分析系统显得尤为重要。
本项目旨在设计并实现一个基于LSTM(长短时记忆网络)算法的电影评论情感分析系统,利用Python编程语言进行开发,并结合爬虫技术自动收集在线电影评论数据。系统以Django框架构建后端服务,旨在为电影行业提供一个强大的工具,能够实时分析观众情感反馈,辅助决策制定。
通过编写定制化的网络爬虫,系统从多个主流电影评论平台上自动抓取大量评论数据。随后,数据经过预处理,包括去噪、分词和向量化,为深度学习模型的训练做好准备。核心部分应用LSTM算法构建情感分类模型,该模型能够学习评论文本的时间序列特性,有效捕获语境中的情感变化。通过大量的训练迭代,模型在验证集上展现出高精度的情感分类性能。系统前端采用响应式设计,基于Django构建的API接口实现了与用户友好的交互界面,允许用户查询特定电影的情感分析报告。
总之,该系统不仅能准确区分正面与负面评论,还能在一定程度上识别出评论中的微妙情感倾向,如轻微的不满或高度的赞赏。系统在实际应用中显著提高了情感分析的效率和准确性,为电影制作方、发行商提供了即时的情感趋势洞察,帮助他们更好地理解观众喜好,指导内容创作与营销策略。此外,项目的成功实施证明了结合LSTM的深度学习方法在处理非结构化文本数据,特别是在情感分析领域的强大潜力,为进一步拓展到其他领域的文本分析应用奠定了坚实的基础。
1.2 系统技术栈
Python
MySQL
LSTM
Django
Scrapy
1.3 系统角色
管理员
用户
1.4 算法描述
LSTM(Long Short-Term Memory)作为一种深度学习技术,在应对序列数据分析任务上展现出卓越效能。它巧妙设计了门控机制及记忆单元,有效缓解了标准循环神经网络(RNN)面临的梯度消失和梯度爆炸难题,进而强化了对序列数据长期依赖性的捕获能力。
LSTM单元的创新之处,在于其精细的内部结构,包括输入门、遗忘门和输出门。这些门机制如同智能阀门,精心筛选信息流:输入门判断哪些新信息值得存入记忆;遗忘门则分辨并抛弃不再重要的旧信息;输出门调控记忆单元的内容如何影响下一步的输出,确保了信息的有效管理和利用。
记忆单元作为LSTM的核心组件,承担着存储序列数据长期状态的重任,使得模型能在适当时候召回这些重要信息,这对于处理如自然语言、语音分析及时间序列预测等时序相关任务至关重要。
LSTM算法的强项还体现在其深度的特征学习能力,能从序列数据中抽取出复杂的模式和规律,为预测和分类任务提供坚实基础。这一点在推荐系统设计中尤为重要,比如电影推荐场景下,LSTM能够依据用户过去的观看记录,精妙预测未来偏好,推动个性化推荐策略的实施。
LSTM的灵活性不仅限于此,它还能与其他深度学习模型集成,例如与卷积神经网络(CNN)的联姻,形成复合模型,以增强处理跨模态数据(文字、图像、声音等)的能力,进一步优化推荐系统的表现力。
实施LSTM算法时,科研人员普遍采用Python编程语言,配合TensorFlow或PyTorch等深度学习框架,这些工具的高效率与易用性大大简化了模型构建与训练流程。同时,结合前端技术如Vue和后端框架如Django,可将LSTM模型无缝融入实际应用,为用户带来流畅的互动体验和智能化推荐服务。
总之,LSTM算法凭借其独特的结构设计、优异的特征学习性能以及广泛的适用性和扩展性,在序列数据分析,特别是在电影评论情感分析系统中,展现了提升推荐精准度与用户体验的潜力,对促进影视行业的个性化服务发展具有积极意义。
1.5 系统功能框架图

1.6 设计思路
数据收集:广泛搜集社交网络、聊天平台及社交媒体上的内容,确保数据集丰富多样,具有广泛代表性。
数据标注:基于大数据架构的评论情感分析,我们精准标注每位用户的在社交平台上的评论数据,明确平台的类别与评论关系,确保标注的可靠性和准确性。无论是图片还是文字。
数据增强:通过文本的转换、重组和替换来丰富数据多样性。针对评论情感分析,这样的文字处理技术显得尤为重要,因为捕捉和理解文本中的情感色彩,为情感分析提供更为全面和多样的训练数据。通过不断学习和优化,模型将能够更准确地识别和分析评论中的情感倾向,为相关应用提供有力的支持。
架构选择:选择合适的CNN架构作为基础,如使用已经在文字识别任务中表现良好的ResNet、VGG或自定义的CNN结构。
特征提取:设计能够有效提取汉字特征的卷积层和池化层,捕捉汉字的结构和笔画信息。
分类器设计:在CNN模型后端设计分类器,用于将提取的特征映射到具体的汉字类别。
训练策略:采用合适的损失函数和优化算法,如交叉熵损失和Adam优化器,进行模型训练。
超参数调整:通过实验调整学习率、批大小等超参数,找到最佳训练配置。
正则化和防止过拟合:应用Dropout、权重衰减等技术防止模型过拟合,提高模型的泛化能力。
性能评估:使用精确度、召回率、F1分数等指标评估模型性能,确保模型具有高准确率和可靠性。
交叉验证:采用交叉验证方法评估模型在不同数据子集上的表现,确保模型的稳定性和泛化能力。
2 系统功能实现截图
2.1 管理员功能模块实现
2.1.1 登录功能
2.1.2 电影信息

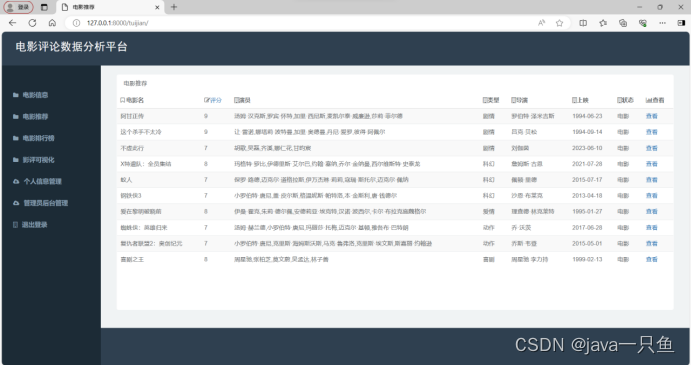
2.1.3 电影推荐
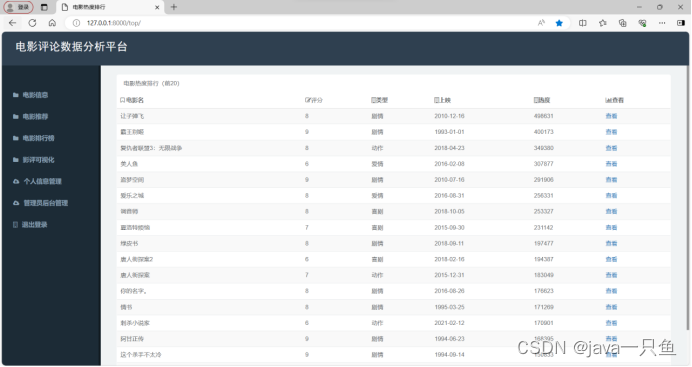
2.1.4 电影排行版















 2013
2013











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









