









作为计算机视觉中的一个经典的问题,语义分割已经受到了学界的广泛关注。语义分割是针对输入的图像的每个像素,预测出该像素属于何种类别。这种相对于目标检测提供边界框信息而言,能够产生更加稠密的预测,因此提供的信息也相对于目标框更为丰富,比如能够提供目标在图像中的准确边界信息等。因此,语义分割在自动驾驶等需要精细化信息的领域上有着非常大的应用前景,能够为计算机针对场景进行理解提供重要帮助。
而随着AlexNet和VGG在图像识别领域的成功,深度卷积神经网络逐步走入大家的视野,紧接着一系列基于CNN(深度卷积神经网络)的语义分割方法被提出,从2015年CVPR最佳论文FCN,到2016年的DeepLab,2017年CVPR的PSPNet,基于CNN的方法已经在语义分割领域占据无与伦比的地位。
而针对于实时语义分割的方法,近年来也越来越受到研究者的关注。像FCN、PSPNet这种方法虽然能获得非常高的准确度,但是运算速度上并不能令人满意,也就是说,这类方法能让计算机“看得准”,但是没办法让计算机“看得快”。而什么方法能够让计算机既能够“看得准”,又能“看得快”,就是一个非常值得研究的问题了。因此,本文主要综述现有的一些语义分割方法,试图将实时语义分割的发展脉络丛几个角度梳理出来展现给大家。
- 实时语义分割的重要性和语义分割的应用领域
首先来说说实时语义分割有什么应用领域,首先就是自动驾驶,如图 1所示:
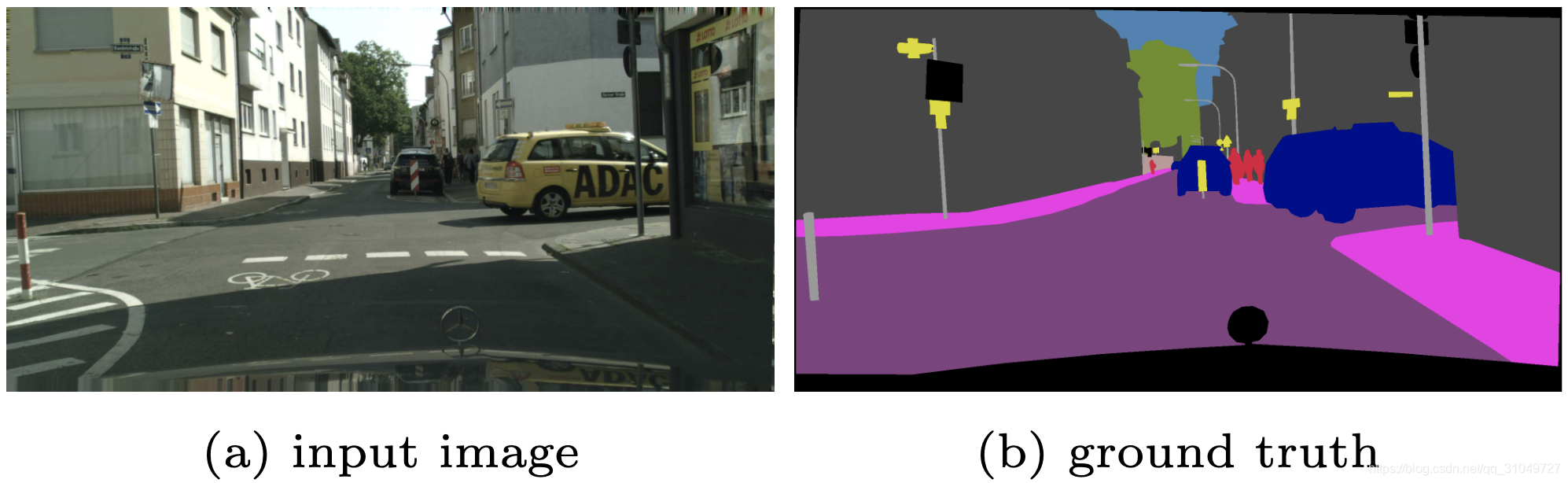
图 1 语义分割在自动驾驶上的应用
给定一张街景图像,需要计算机能够根据这个图像,迅速的针对场景中的各种目标和区域进行理解,比如知道可行驶的道路在哪里,人行道在哪里,前方多远的地方存在行人或者车辆。有人可能要问了,这不是一般的语义分割都可以做到吗?但是实际使用的时候,首先一般不会在车上搭载专门的GPU或者服务器用于计算。此外,就算搭载了专门的GPU,经典的高准确性神经网络比如FCN或者PSPNet的运行速度还是只能达到1-10FPS,相对于摄像头的生成速度过于缓慢。这样万一出现突发事件,比如有一个行人或者车辆闯入我们的车道,处理速度就会跟不上,进而导致无法做出有效反应酿成事故。因此,实时语义分割的重要性也就体现出来了。实时语义分割的目的是在于让计算机又能“看得快”又能“看得准”。当然,我们都知道天下没有免费的午餐,因此我们需要在这两者之间做一定的权衡和取舍,使得计算机在看得快的同时,又能看的比较准。这就是实时语义分割的重中之重。
此外,还有一些实时语义分割的其他应用,比如在手机端人像的抠图,如图 2所示,在学界被称为Matting。目标就是给定包含人的图像,需要将人(前景)和场景(背景)进行细致的二分类,包括最难以分类的头发梢等部位。

图 2 语义分割在Matting上的应用
此外,还有针对人脸的场景理解,这些应用往往是需要应用于手机端,在计算资源受限的同时需要做到实时产生结果,这也是实时语义分割的一个重要应用。


图 3 语义分割在面部理解上的应用
- 实时语义分割的关键问题
既然说到了实时语义分割,那么必须要来聊一聊这个领域里面到底存在什么样的科学问题,有哪些问题是需要我们去重点思考和解决的。实时语义分割,顾名思义就是由两个部分组成,一个是实时,一个是语义分割。
1)语义分割
首先,实时语义分割说到底也还是一个语义分割问题,语义分割目标是在给定图像或者图像序列中,给每个像素划分该像素对应的类别。由于相当于要给每一个像素都要给出一个类别判断,所以也被看作是一种稠密估计(Dense Prediction)问题。
而语义分割里面有什么问题呢?首先最关键的一点在于,训练所需的标签难以获取。在图像分类中,一张图像要给定一个类别标签可能只需要几秒钟,就算目标检测中要画出目标框的位置,也只需要不到半分钟时间。而一张语义分割的标签图像,比如Cityscapes中的1024*2048的大小的图像,官方给出的标注时间大概在5分钟左右一张,人工标注成本可想而知。针对这个,最近几年有一些关于弱监督的语义分割研究开始出现,比如利用不那么精确的标签来训练网络获得比较好的结果,或者利用网上的大量图像数据来自动生成一部分数据,这些都是解决语义分割数据问题的手段,但是和我们今天所要重点讨论的实时语义分割关系并不大,因此就不再赘述。
此外,同样是数据上,由于语义分割需要大量的精细化图像来对场景产生更为准确的理解和判断,所以一般语义分割的图像都是非常大的,就算小图一般也有几百乘几百,大到1024*2048,甚至在遥感领域做分割的几千乘几千的图像都有。为了保证效果,一般都会尽量减少其中的降采样操作以免图像质量变差,但是这样一来在训练的时候计算资源的消耗会增长的非常厉害,训练的时候一张11G的显卡可能只能放得下两张图像,batchsize过小导致BN层更新的时候均值和方差计算非常不准,进而影响训练效果。这也是为什么高精度语义分割近年来很少出现轰动性的研究成果,一方面因为数据集的效果基本上刷到极限了,另一方面就是大家都逐渐开始玩不起了(指硬件条件不够)。针对这个问题,也有一部分研究成果,比如Kaiming He的Global Normalization,或者一些其他的训练手段,这里也不细讲了。
2)实时
接下来是本篇的关键问题,实时。首先实时的定义是什么,虽然很多文章标榜自己能够做到实时,甚至标题名字中包含了Real-Time这个词,但是这些文章中并没有给出实时的具体解释。就目前的文章里面看到的,一般大家会在30FPS的位置画一条虚线,如图 4所示为ICNet中给出的Inference time和Accuracy的对比图。
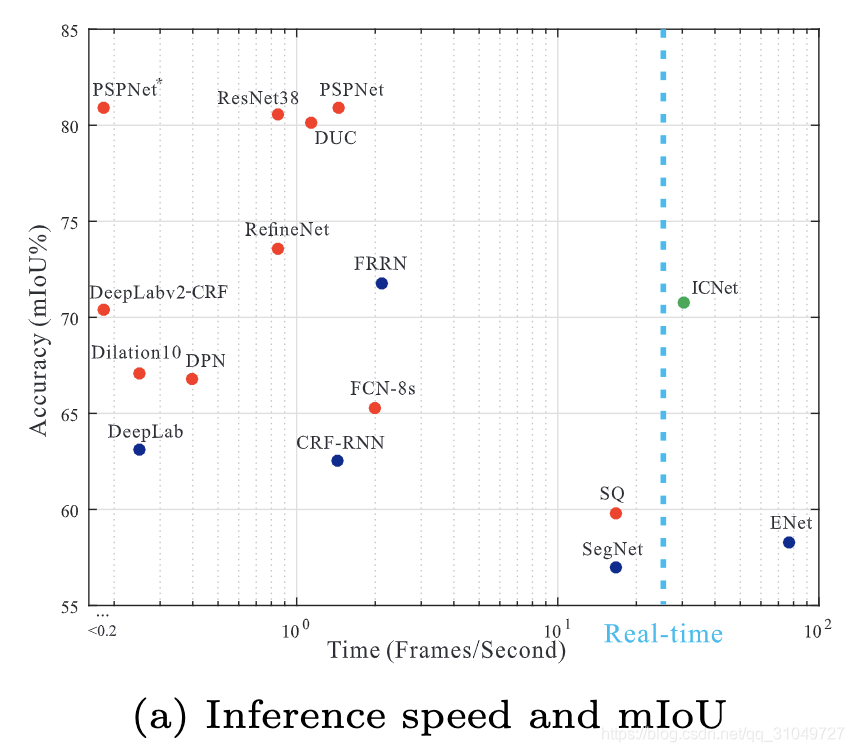
图 4 ICNet中总结的各方法速度精度对比
此外就是,怎样才能做到实时?为什么以前的一些高精确度的网络做不到实时?这里面我觉得有几方面的问题:
(1)首先是现有的高精度语义分割网络,大多是基于一个Encoder-Decoder架构,即前面通过Encoder编码图像内的有效信息,然后通过Decoder来进行解码,如图 5所示。而在选取Encoder编码器的时候,一般都会选择像是AlexNet,VGG,ResNet等在ImageNet上预训练好的分类网络,而这些网络为了能够有更好的特征提取的效果,会把网络设计的很深,网络参数设计的很多,以此提升网络的非线性拟合能力。而这种网络参数和层数一旦上去,计算操作就会大大增加,进而影响到处理一张图像的速度。
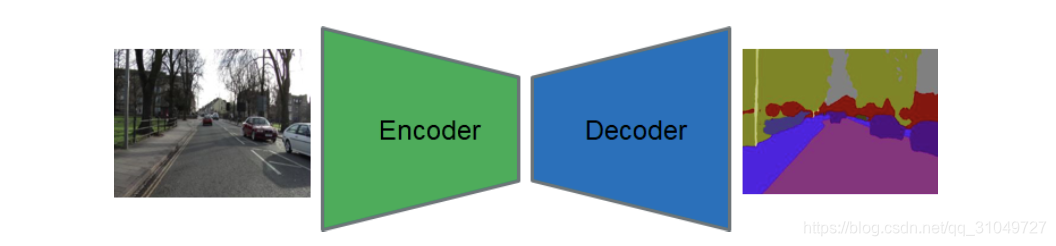
图 5 经典语义分割网络的编码-解码结构
(2)第二个就是现有语义分割网络要处理的图像大小比较大,动不动几千乘几千的大小,对于基于卷积操作的CNN是一个不小的负担。因此,怎样能在不损失精度情况下,降低待处理图像的分辨率也是加速的一种有效手段。
(3)最后就是,如果只采用一个浅层网络,自然效果不会好到哪里去,但是相对而言,运算速度上由于参数更少操作更少,所以运算速度会相对比较快。而是用一个深层网络的话,操作就会成倍增加然后拖慢运行时间,但是准确度会提升很多。那么,有没有一个办法取两者的优点,得到一个运算很快效果也很好的网络呢?这也是第三种方法,从两个分支的角度出发来考虑问题。
- 现有语义分割数据集
现有的语义分割数据集大多数为以下几种,本文只综述传统语义分割的数据集,不考虑额外的如面部理解,Matting领域的数据集。
- Cityscapes
这是目前语义分割领域应用最广泛的数据集之一,由奔驰公司牵头制作,主要面向场景为自动驾驶。在欧洲多个城市收集了大量图像和视频数据并进行了标注。
数据集中包含精标注5000张,训练集2975张,val集500张,test集1525张,每张图像大小均为1024*2048。共标注了30个小类,一般会将30小类划分为19个类别进行训练。此外,还有20000张粗标注图像可以用于训练网络。标注示例如图 6所示,左侧为精标注图像,右侧为粗标注图像。


图 6 Cityscapes标注示例
- PASCAL VOC
PASCAL VOC为图像识别和分类提供了一整套标准化的优秀的数据集,从2005年到2012年每年都会举行一场图像识别challenge。该挑战的主要目的是识别真实场景中一些类别的物体。在该挑战中,这是一个监督学习的问题,训练集以带标签的图片的形式给出。这些物体包括20类。在分割这个子任务中,目标是在给定图像中,从背景中分割出前景。标注示例如图 7所示:

图 7 PASCAL VOC 数据集标注示例
- PASCAL Context
为了更好的评估语义分割这一任务,后来有研究者提出了这个PASCAL Context数据集。PASCAL Context 总共有459个标注类别,包含 10103 张图像,其中 4998 用于训练集,5105 用于验证集。现在最广泛地用法是使用其中出现频率最高的 59 个类别最为语义标签,其余类别标记为背景即background。标注示例如图 8所示。可以看到,这一数据集相比于VOC数据集,场景更多,前景也更多更复杂。

图 8 PASCAL Context标注示例
- ADE20K
ADE20K是包含20000张图像的室内数据集,该数据集有150个类别,可以说是类别数最多的语义分割数据集,因此相对于其他数据集来说更难更不容易学习。标注示例如图 9所示。

图 9 ADE20K数据集标注示例
- 实时语义分割解决方案:从特征提取角度思考
如同上文所说,实现实时语义分割的方法大致分为三种,第一种就是从特征提取的角度思考问题。这种方式非常直接也很简单,直接二话不说,换一个更简单的BackBone用以特征提取就好了。VGG19,ResNet50,ResNet101参数量太大?那我就换个小点的,ResNet18?不行再换成专用的Xception18,MobileNetv2?这种直截了当的方式,能取得非常明显的效果,代表性的有ENet,SQ,ESPNet等,下面一个一个介绍。
首先是ENet,它是比较早的一篇关于实时语义分割的文章,文章在2016年挂在arXiv上,虽然看样子没有被收录,但是由于做的很早,所以目前为止很多做实时语义分割的文章都会对其进行引用。
ENet主体是基于ResNet,并应用了一些trick,比如空洞卷积(dilated convolution)和非对称卷积(asymmetric convolution)。但是,该网络结构中,所有卷积层channel数最高只有128,相对于ResNet50里面的2048降低了非常多,因此我认为这个网络参数量小,运算速度快,主要还是靠的通道数减少进而减少了计算量。不过因为backbone是强大的resnet,因此,网络性能上还没有受到太大影响。该网络结构如图 10所示。
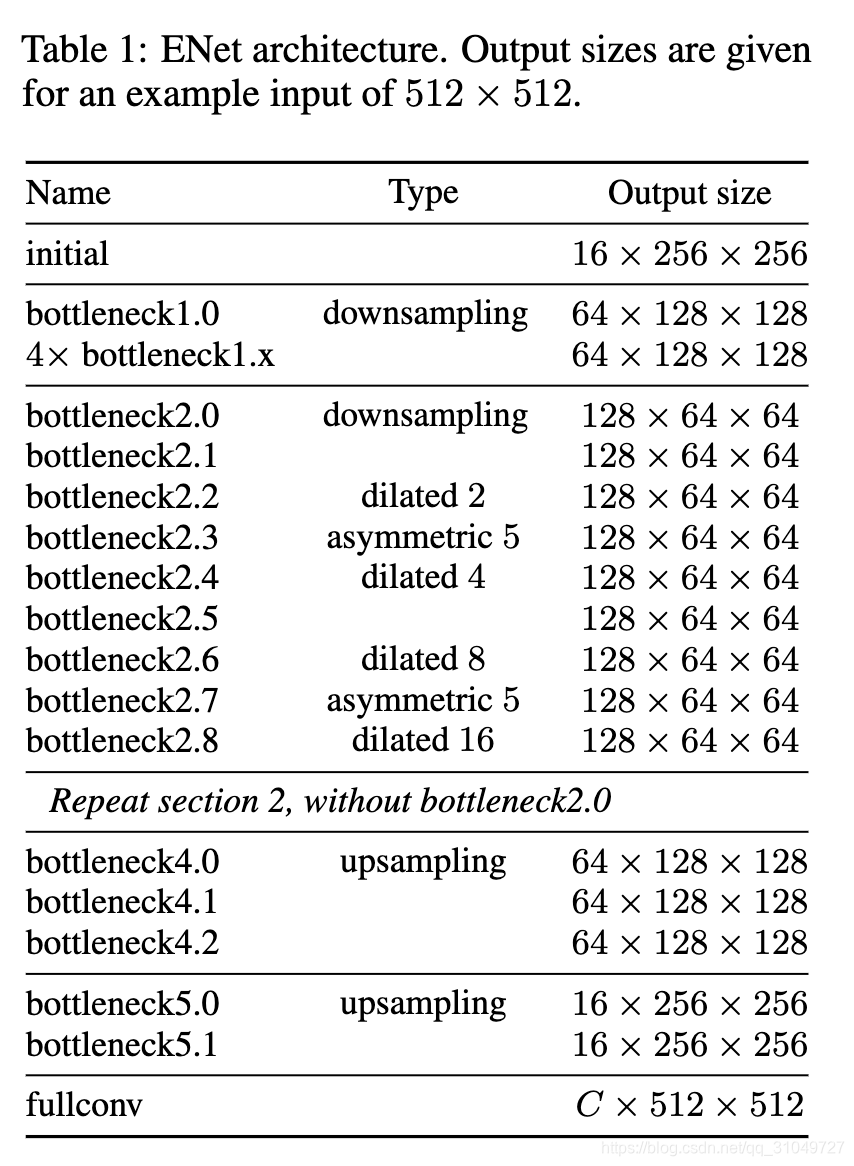
图 10 ENet网络结构图
接下来就是SQ方法,它和ENet一般会被一起引用,因为它也是做的时间非常早的一个方法,是2016年NIPS Workshop中的文章。网络结构如图 11所示:
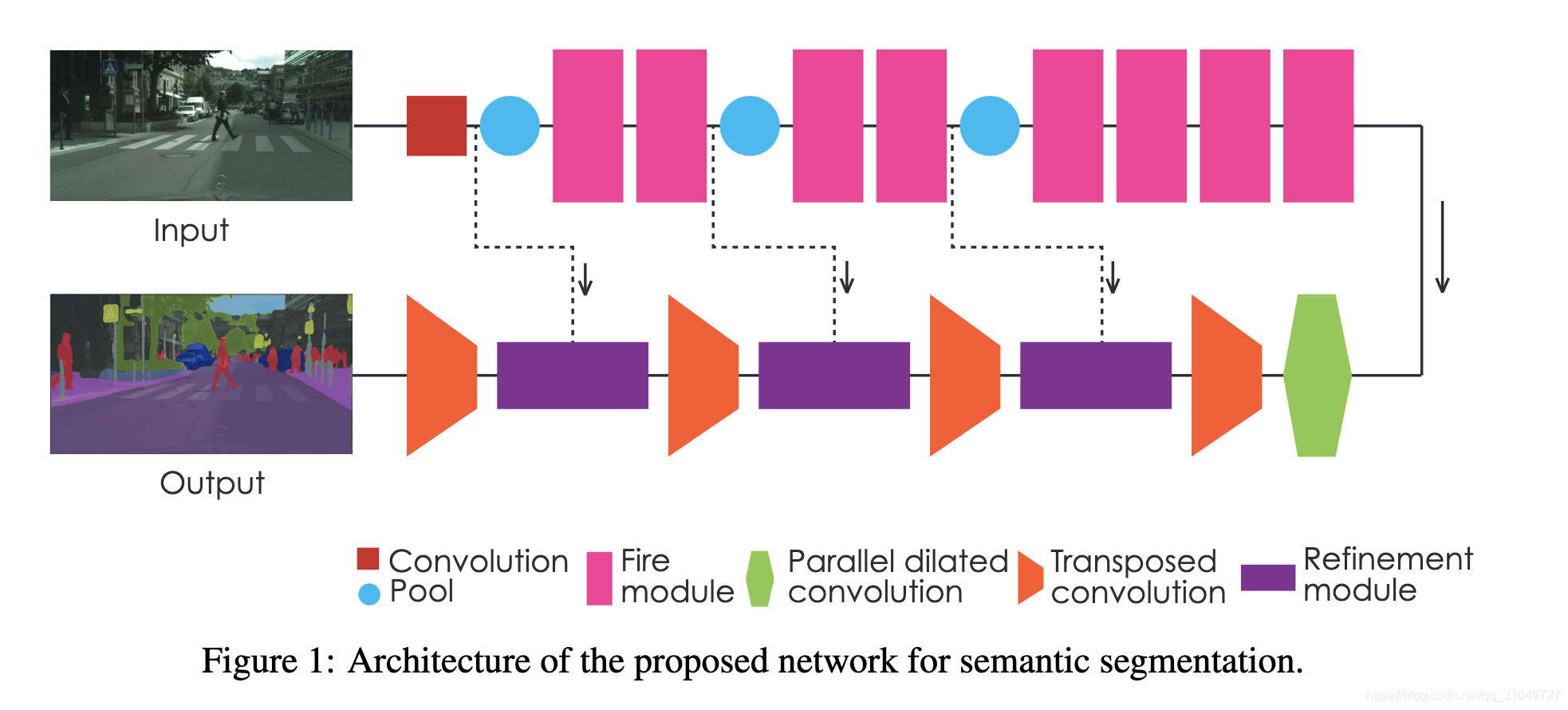
图 11 SQ方法网络结构图
该文章的网络结构基于传统的先特征提取,然后再进行上采样,跟FCN差不太多,但是同时借鉴了Unet里面的同样大小的特征图进行skip,然后一起融合生成预测的方式。此外,还在特征提取网络头部分放置了一个Parallel dilated convolution模块,其实是通过不同dilation的卷积操作来获取不同大小的感受野,起到的作用其实跟PSPNet中的pyramid pooling module差不多,但是由于parallel dilated convolution模块中,不存在global pooling操作,感受野大小可能并不够大,效果可能没有pyramid pooling module模块效果好。此外,上采样是通过转置卷积来进行实现的,相比于双线性插值,能够学习的参数可能可以学到一些信息,能够使上采样以一种自适应的方式来学出来。不过最终看来,这篇文章能够做实时语义分割的最核心在于其用的是SqueezeNet这一high efficient网络来作为backbone提取特征,这才是它能够做实时的关键。
最后就是ESPNet一系列,ESPNetv1是2018年发表在ECCV上的实时语义分割文章,它的核心之处在于提出了一个Efficient Spatial Pyramid module,将一个传统的卷积操作分解成了一个卷积核为1*1的channel映射和多个并行的卷积,这样一来,一个输入channel为M,输出channel为N,卷积核n*n的卷积,参数量从n*n*M*N变为了M*N/K + K*n*n*(N/K)^2 = M*N/K + n*n*N*N/K = (n*n*N + M)*N/K,参数量变为了原来的(n*n*N + M)/(K*n*n*M) = N/KM + 1/n*n*M,由于N/K大于等于1,所以M越大,参数量下降的比例越大。
他们利用这种卷积解耦方式,设计了ESP module,如图 12(b)所示,其中不同的n代表相同大小卷积核采用不同大小的dilation rate,来取代本来在网络里面的大量3*3卷积。
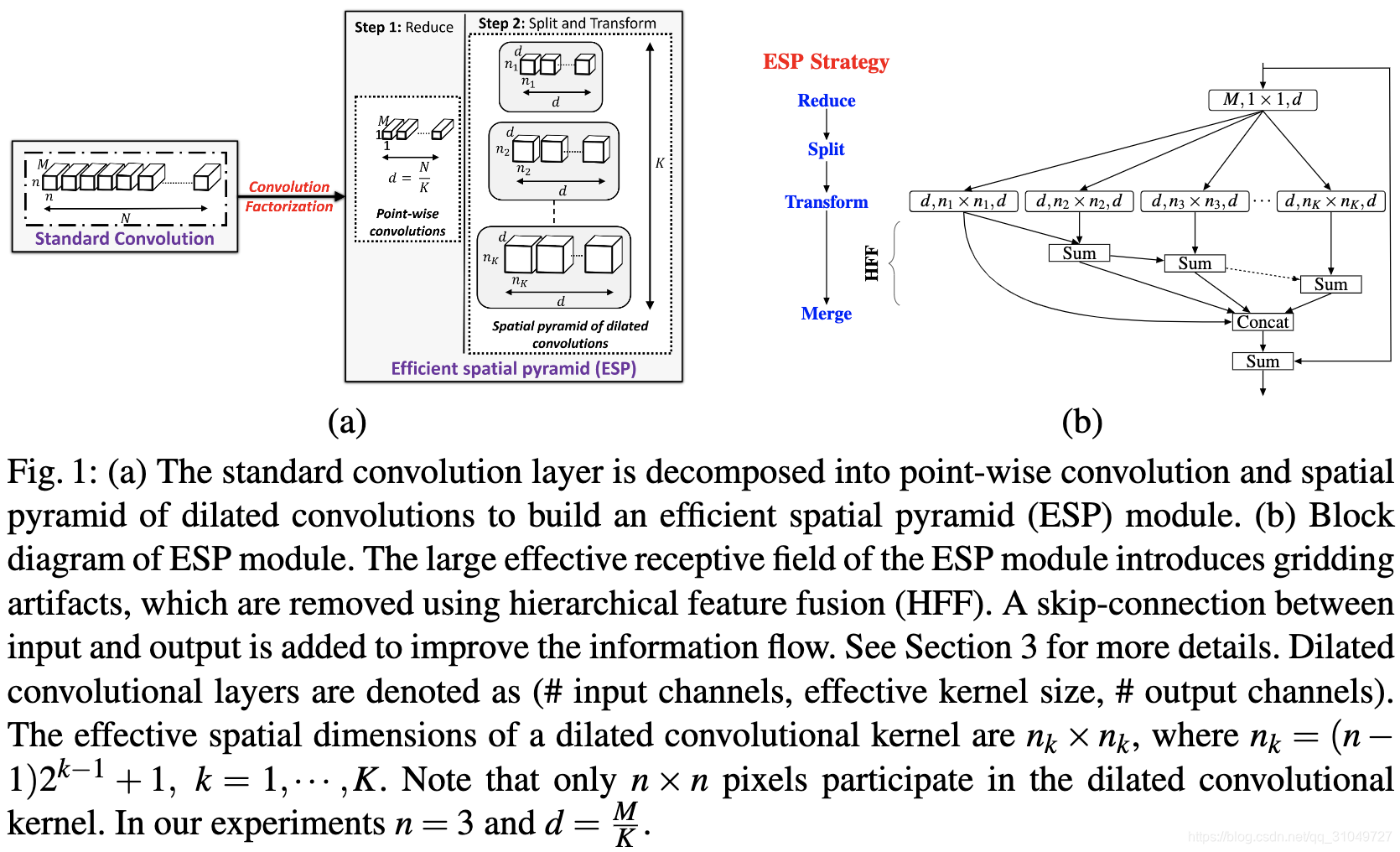
图 12 ESPNet卷积解耦示意图
通过这种方法,ESPNet减少了大量的参数量,进而能够达到一个接近实时的效果。后来,很多文章都或多或少借鉴了这种思路,在backbone上做文章,比如将特征提取网络channel维度降低,或者设计分离卷积,或者采用专门为实时任务设计的MobileNet网络作为backbone来达到实时语义分割的目的。虽然这方面工程应用上很容易,但是要通过这种思路来发好的论文还是很难的,很容易被固定思维困住落俗。
- 实时语义分割解决方案:从多分支角度思考
刚刚说到除了从backbone角度思考问题,利用更好的backbone能够取得更好的特征提取也就是Encoder的效果,但是相对而言计算所需要的代价就越高。浅层网络运算速度快但是特征提取效果很差,这两者怎么进行一个权衡呢?这就是多分支这一类方法主要考虑到的问题。
ICNet是最早针对这个问题提出来并且想方法在精度与速度之间进行权衡的研究之一。如图 13所示为ICNet中针对PSPNet50的每一层的运算速度分析。
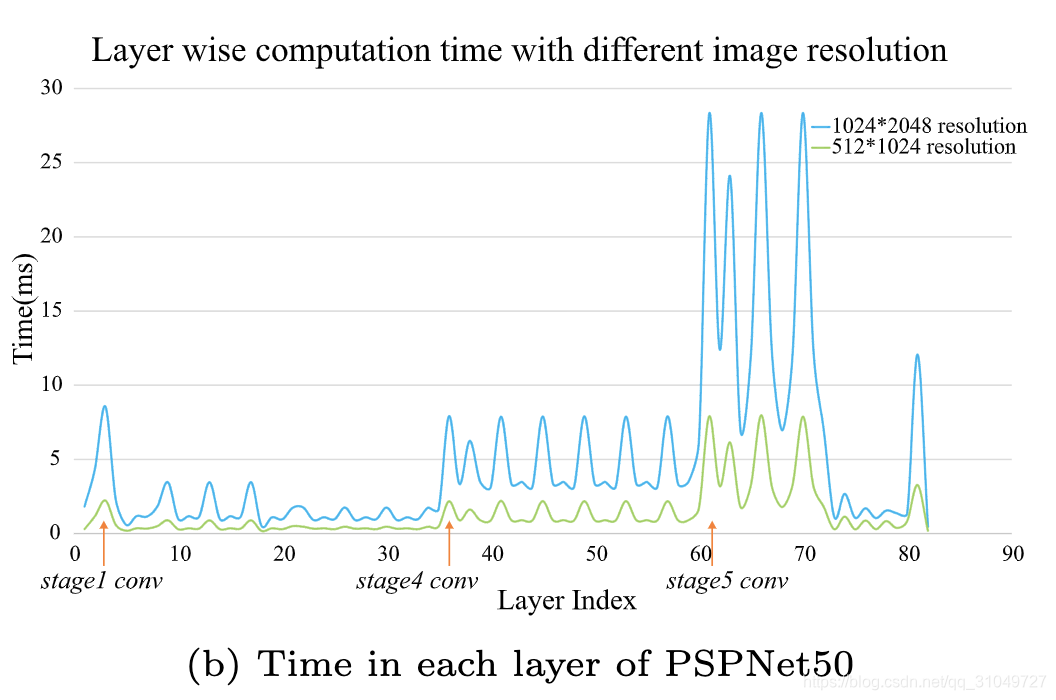
图 13 PSPNet50每层运算速度分析
他们发现,不同分辨率下的图像,经过相同的网络层,计算速度同样也是不一样的,更大的图像意味着更多的计算代价,而小图像就算经过相同的网络,相同的参数运算,也能够以一个较快的速度计算完成,但是得到的图像很小,在上采样过程中可能在边界处会引入大量误差。同时,我们也知道,一张图像经过浅层网络,一般保存下来的是边缘等空间结构信息。那么,我们能不能一方面通过原图像来经过浅层网络提取空间信息,另一方面用深层网络和经过降采样的图像提取空间上下文信息,然后将两者进行融合得到一个既有空间上下文又有图像细节的融合预测结果呢?答案是肯定的,ICNet就是最早利用这个思想的网络结构之一。ICNet的网络结构如图 14所示:
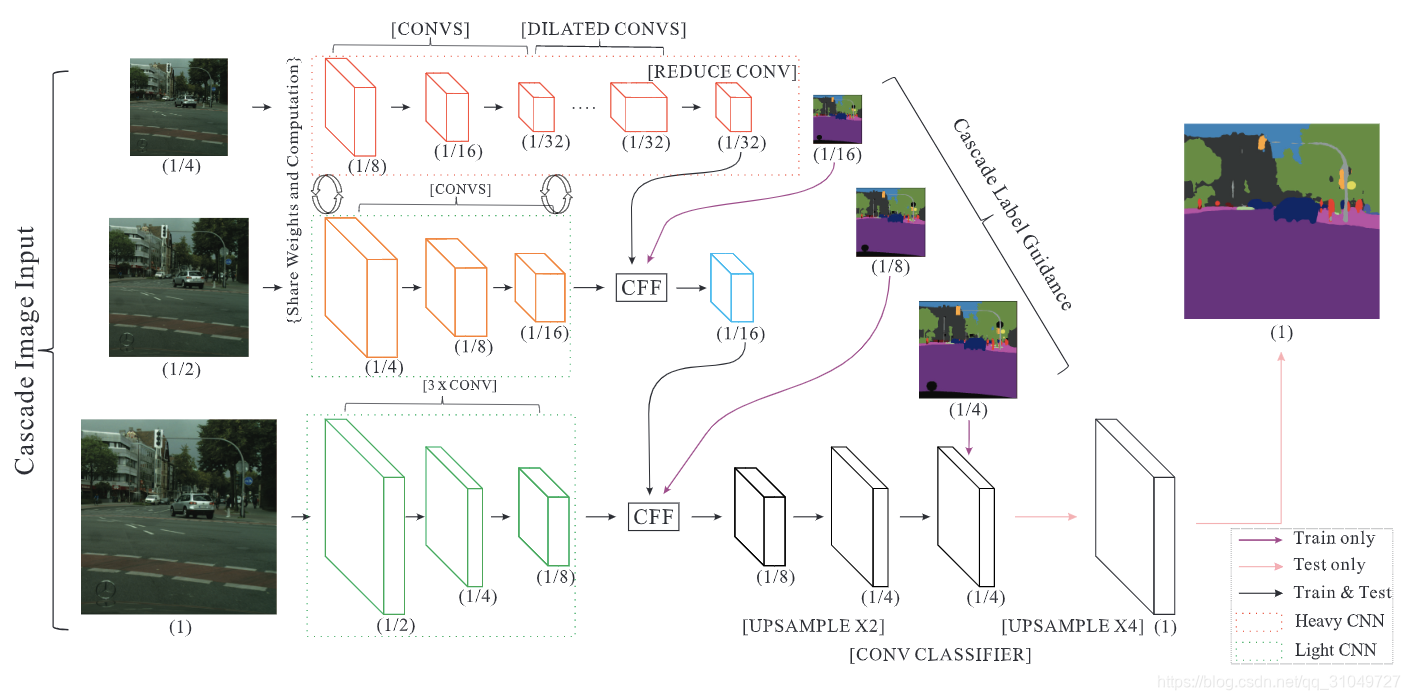
图 14 ICNet网络结构图
该文章的核心观点在于:用一个较小分辨率的图像通过一个完全的语义分割网络,然后生成一个分辨率较小的语义分割图,然后另外一个正常大小的图像,通过一个较浅层的网络,然后生成保留更多细节的预测图,然后将这两个预测图进行结合,最终生成最后的预测结果。网络结构图如所示,1/4和1/2大小的图像分别通过较深的语义分割网络,用1/16和1/8大小的图像进行监督,然后通过CFF模块进行特征层面的融合。当然,这并不是我们刚才说的单纯的“两分支”而是有三个分支在不同大小的图像上进行作用,然后给出不同大小的监督信息,这里也是借鉴了PSPNet中的Deep Supervision的思路。
此外,旷视也在2018年提出了BiseNet,也是这种思路的一个研究工作,BiseNet网络结构如图 15所示。
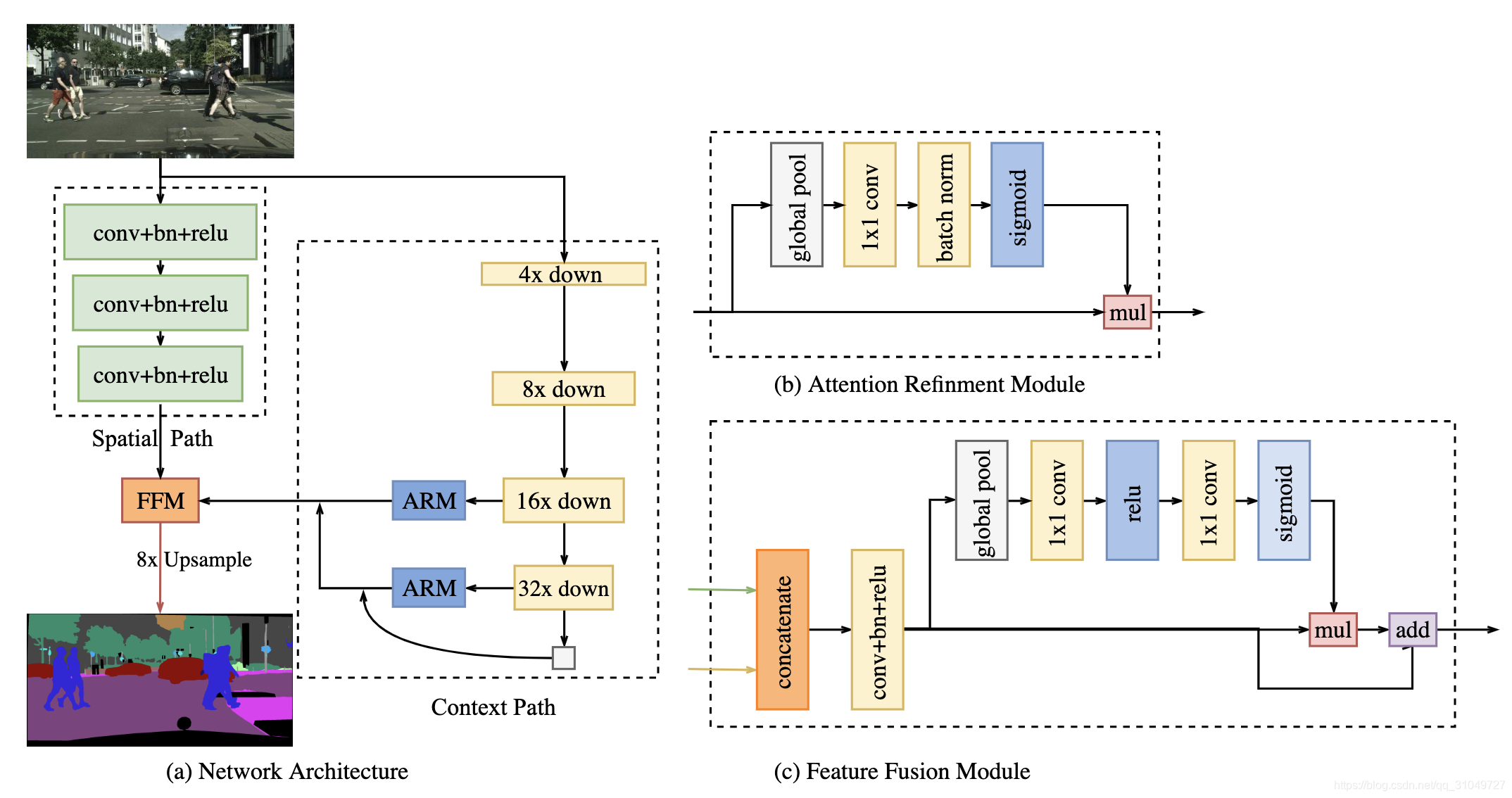
图 15 BiseNet网络结构图
该网络主要分为了两支,一支为spatial path也就是我们上文中提到的用于保存空间结构信息的一个分支,另一支则为Context Path,即用于捕捉场景上下文信息和高层次语义信息。Spatial Path只有3个conv+BN+ReLu模块,层数非常少,就算是原图输入,运算速度也足够快。Context Path中,不断得进行降采样,首先就用原图1/4分辨率输入到网络中,然后也没有应用dilated convolution来增加运算量,最后生成的图像为1/32原图分辨率大小,最后用一个Feature Fusion Module模块来进行空间信息和上下文信息的融合。最后生成一个1/8大小的图像,最后通过上采样回去。
总的来说,这种方法应该是最近几年针对实时语义分割特别有效的一个方法,不管是效果上还是运算速度上都还算是挺令人满意,但是单纯这种方式目前很难去做出新意。怎么想都跟前面几篇文章要撞车的样子。
- 实时语义分割解决方案:从分辨率角度思考
最后一个角度就是从分辨率上进行切入,但是这个角度入手的文章我个人感觉跟这个方法能否实时应用的关系并不是特别大,但是由于有一些实时语义分割的文章提出这些操作,姑且还是把它梳理一下。当然不是说这个问题不重要,只是这个更像是影响整个语义分割领域的一个大问题,而非仅仅影响实时语义分割。
语义分割有一个非常严重的问题就是分辨率,如果输入图像一直保持是原图像大小,那么训练用的计算资源一定会吃不消,要么就是batchsize太小影响训练效果。所以大多数情况下,不管是训练还是最后的前向Inference的时候,都会采用1/4大小的图像进行推导,最后采用双线性插值等方式来进行上采样到原图大小。这样就会引入一个很严重的问题,在Encoder阶段通过pooling丢失的一些位置,边界等信息,丢失了就是丢失了,网络是没有办法从这些已经丢失了的信息中将其恢复出来的。因此,怎样设计一个高精度的上采样模块就是非常关键的了,也就是怎样设计一个好的Decoder。
那么就有人想通过引入一些额外的信息来指导网络进行上采样,获取高分辨率的预测。这种思路最早可以看到在2015年的FCN中就有体现,如图 16所示:
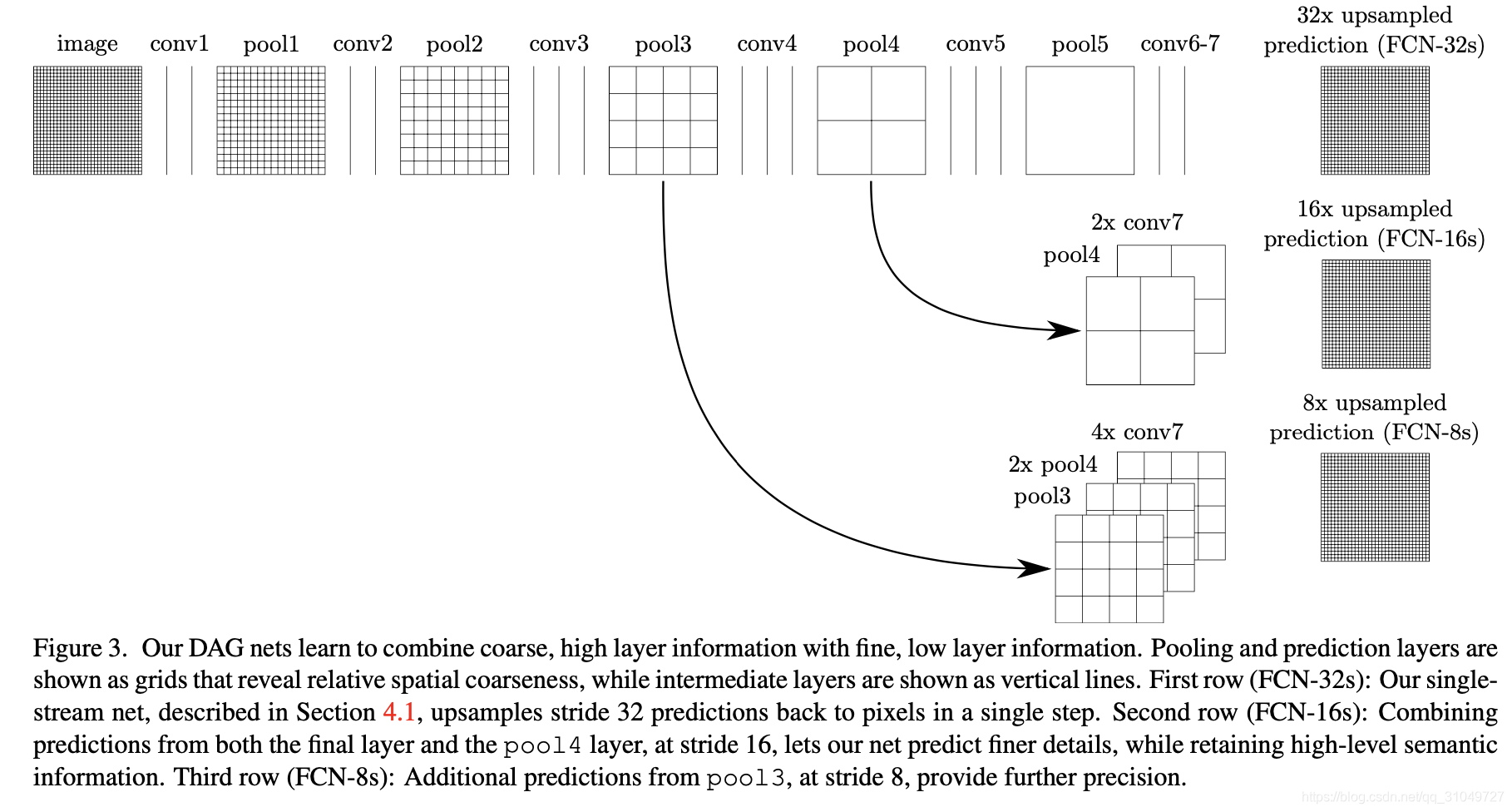
图 16 FCN网络结构图
可以看到,在最后给出1/32的特征图后,通过conv4的特征图和2*conv7一起进行上采样到了1/16大小的图像,或者通过4倍的conv7,2倍的conv4,1倍的conv3一起上采样得到1/8原图大小的预测图。这应该是最早使用这种浅层信息指导最终上采样的方法。此外,还有大名鼎鼎的Unet,用一种完全对称的方式来进行Encode和Decode,并在每个分辨率下用skip connection进行连接。还有DeconvNet同样采用了这种方式。
但是追根究底,这些方法也是仅仅将浅层信息直接引导过来,并没有针对这些信息进行有针对性的利用。后来有一些文章开始思考,想着设计一种可以学习的上采样,而非仅仅应用双线性插值来进行学习。
首先就是SegNet中的一种Unpooling模块,如图 17所示。SegNet中Encoder部分在进行pooling操作过程中,会将pooling取最大值的index记录下来,然后在Unpooling的时候,根据原来pooling模块记录下的index将最大值恢复到对应的位置,来提升上采样的效果。这是比较早的针对上采样来进行改进的文章。
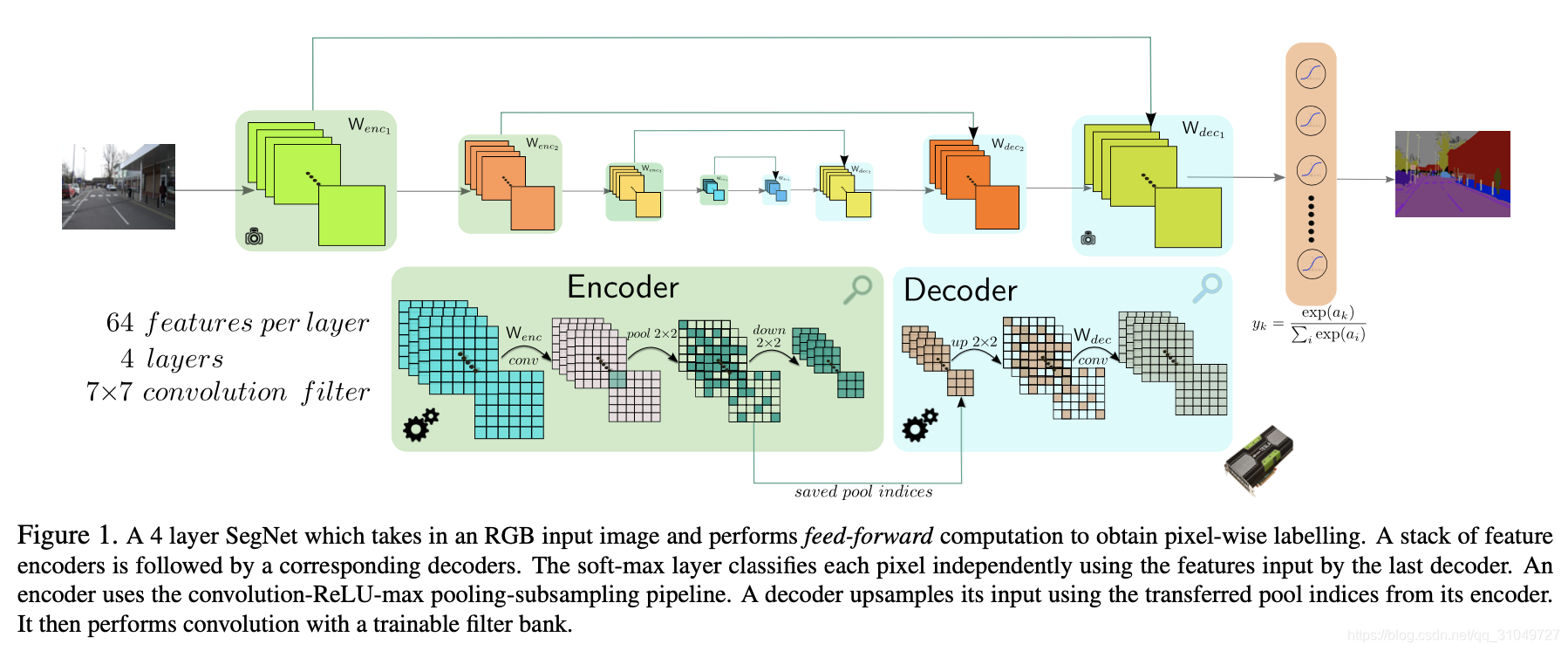
图 17 SegNet网络结构图
而另一篇文章,Decoders Matter for Semantic Segmentation: Data-Dependent Decoding Enables Flexible Feature Aggregation就是一篇专门针对Decoder进行设计的文章,该方法重点在于设计了一个Decoder模块,来进行一个有学习性质的上采样,文中称为Data Dependent Upsampling(DUpsampling),如图 18所示。
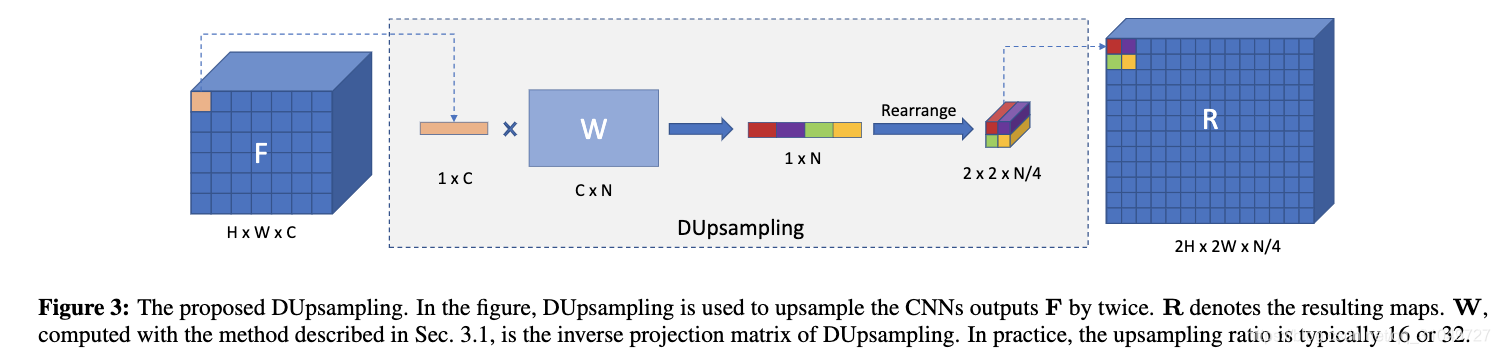
图 18 Decoders Matter 中DUpsampling模块示意图
可以看到,一个H*W*C的tensor,通过channel维度可以分解成H*W个1*1*C的tensor。每个C维的向量乘以一个变换矩阵之后再进行重组,可以变成一个空间维度2*2*N/4的一个tensor。最终每个2*2*N/4的tensor排列在一起就可以得到一个2H*2W*N/4的tensor。这种方式在超分辨率领域是非常常见的,也就是拿channel维度信息来换空间维度信息。通过这种可学习的方法。来让网络具备针对数据的自适应的上采样能力,最终获得一个高分辨率的预测图像。
总的来说,空间分辨率这个东西不仅仅是实时语义分割需要,同时高精度语义分割更需要高分辨率的预测。但是一旦设计出一个高性能上采样模块,对于两个任务而言都具备着重要的意义。
- 总结
最后进行一下总结,本文最关注的还是实时语义分割这个问题,目前实时语义分割主要包含三种思路,一个是采用高效backbone,另一个是利用多分支来在速度和精度上取权衡,最后一个就是通过设计高精度的上采样模块来获得高分辨率的预测。这三种方式各有各的优势,但是发展到现在,单纯的靠其中的一种方法,很难再去做出高水平的工作。我觉得实时语义分割重点还是要放在应用领域,找到好的应用场景比一个单纯刷点的工作更为重要。见过很多仅仅将成熟的网络利用到比如人像分割、指甲定位识别等领域,方法不见得有多创新,但是这些工作针对自己的应用有自己的思考,我还是更喜欢这些有实际价值的工作。不然研究了这么多,别人问一句你这研究的有啥用,然后你自己就傻眼了。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









