







一、克隆虚拟机中的linux操作系统后,需要
1、修改网卡:vim /etc/udev/rules.d/70-persistent-net.rules

2、修改ip地址

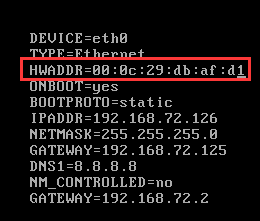
删红框内地址(亲测了,不删会配不了ip地址),修改ip地址
3、修改主机名

4、重启网卡:service network restart
5、修改域名
打开本机电脑
‘
添加linux里的ip地址及主机名

(已经有了ip地址,可以通过远程访问软件访问了)
6、linux添加主机和ip地址的映射vi /etc/hosts
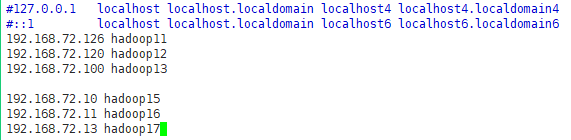
二、xshell远程访问虚拟机的linux操作系统
1、新建连接
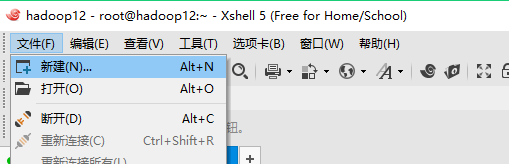
2、设置属性

3、点连接

4、填用户名
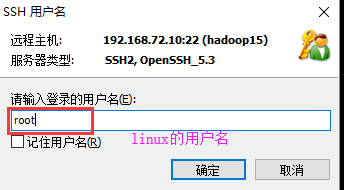
5、填密码

二、linux命令行
1、查看ip地址:ifconfig
2、向其他虚拟机发送文件(前提是已经配置了ssh):scp -r /etc/hosts hadoop12:/etc/
批量拷贝:for i in {0…7} ;do scp -r /spark/spark-2.3.1-bin-hadoop2.6/ hadoop1$i:/spark;done
3、查看防火墙状态:service iptables status
4、删除所有txt文件:rm -rf *.txt
5、创建文件夹:mkdir (文件名)
6、查看目录下的文件:ls
7、查看目录文件及文件的详细信息:ll
8、删除大片内容:选中,然后按d
9、撤销上次操作 :u
10、window内容复制到Linux,在window复制好内容,进linux编译环境下,先按i(保险之做),按shift和insert (有的电脑没有insert键,找台有insert键的电脑吧)
11、解包:tar -xvf xx.tar
12、解压包 :tar -zxvf xx.tar.gz
13、免密配置的命令:ssh-keygen/ssh-copy-id
14、格式化dfs:hadoop namenode –format(只能使用一次)
15、hadoop yarn-client 模式下运行ipython notebook: PYSPARK_DRIVER_PYTHON=ipython PYSPARK_DRIVER_PYTHON_OPTS=“notebook” HADOOP_CONF_DIR=/bigdata/hadoop-2.6.1/etc/hadoop/ pyspark --master yarn --deploy-mode client
16、将虚拟机的文件通过远程软件拷贝到本地命令 :sz xx
三、远程访不上虚拟机的操作系统的解决方法
1、

要使其是启用状态
2、虚拟机里ip地址和本机的地址要在同一局域网内。















 354
354











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









