







0前言
代码请访问github的个人储存库里下载,喜欢的给个Star喔。
实验要求:完成插补实验
实验工具: 1、excel表格
2、记事本txt文件
3.、pycharm
4、JBPCAfill.jar包
1前期处理
1.2删除特殊字符
表格中含有None,#NULL!的字符,表示数据缺失,在表格统计数据个数时,字符None,#NULL!影响统计的数量,所以这些字符需要删除。代码在first包里的Prepare.py里。
思路:两个for循环对行和列进行扫描,遇到None或#NULL!字符,对其赋空值。
2.EM算法插值
2.1 步骤
1、下载ycimpute库,里面含有EM算法的插值函数
2、插入’index’字段名,目的是后期为筛选出非空的数据进行文字转数字,最后根据index值还原顺序
2、地址和手机号码都是文本类型,而EM算法的插值函数要求特征值全部为数字类型,于是将文本标签转为数字
4、选定特征值,
5、使用ycimpute库里的EM()函数插值
6、将数字类型的地址和手机号转成文本标签
步骤思路图
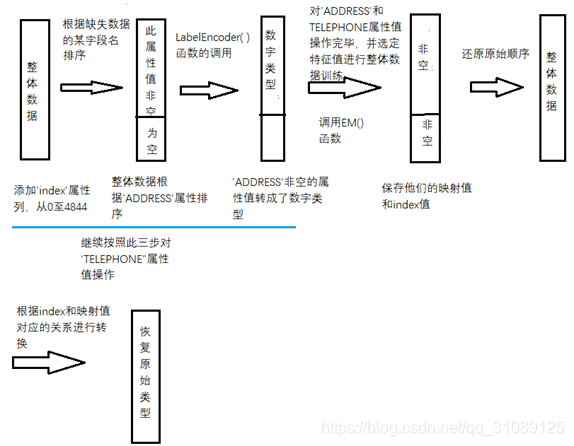
2.2 备注
代码操作如first包里的em.py所示,并且调用了toencoding.py代码
3 多重插值
代码操作如first包里mice.py所示,直接调用ycimpute库里的MICE函数,代码操作思路与EM算法操作相似,只需将from ycimpute.imputer import EM 改from ycimpute.imputer.mice import MICE,调用MICE函数里的插补函数即可。
4.比较EM算法、PPCA算法、BPCA算法的插值误差
4.1前期测试集的选取
1、将txt文件转成csv表格,代码如two包里的txttocsv所示
2、观察表格中各个属性的特点,车牌号是单一的,而其他因素都会影响着车的速度,对于时间的处理,我选择了取间隔时间,当前时间与下一个的时间间隔代码在two包的Diff.py里。
3、测试集的代码位于two包里的share.py里, 此测试集代码可以保证每次运行都得到相同的测试集,找到测试集的下标并保存。并将其速度赋值为空。将测试集和训练集全部存入另一张表格。
4、对trafficflow21.csv里的特征值进行标准化处理
4.2. bpca算法的操作
4.2.1.前期处理
对于ppca算法,python2有直接安装的包,python3安装则会出错,于是我将ppca插值算法的包里函数直接复制粘贴到ppca.py里。对ppca插值算法的操作代码在two包的ppcamake.py里。分离出训练的特征值,进行标准化处理,对空值全部赋999操作,如two包的bpcapre.py所示,然后将转成txt文件。
4.2.2.操作步骤
在BPCA的jar包下载了JBPCAfill.jar,此包由Shigeyuki Oba所编写,此jar包作用是采用bpca算法对缺失的数据进行插补。此jar包的使用方法如图从网站截图而来。

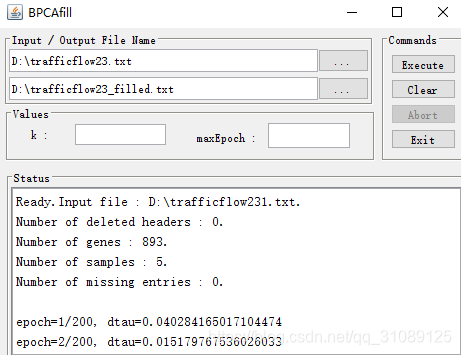
将trafficflow23_filled.txt转成csv格式。
4.3.PPCA算法插值
1.python2可直接导入下载的PPCA插值的代码库,python3导入出错,于是将将ppca包里的函数复制粘贴至two包的ppca.py里,ppcamake.py是调用ppca插值算法里的函数。
4.4.EM算法插值
调用ycimpute里的EM模块即可。将测试集的特征值带进EM里的插值函数。返回插值处理后的特征值数据集。
4.5.三者比较的结果的可视化
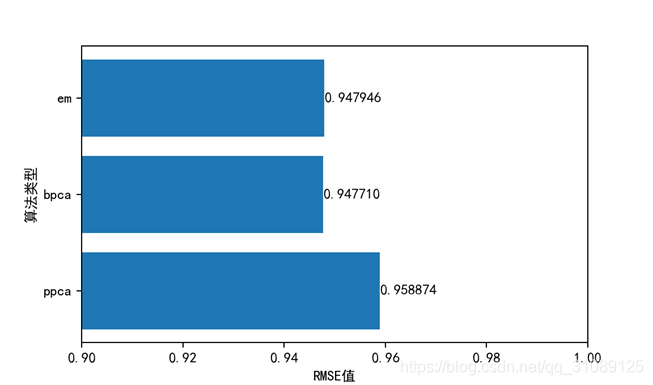
代码如two包里的share.py所示,调用Plotfigure函数,如two包里的mainfunction.py所示,mainfunction.py通过调用ppcamake, emmake, bpcamake,share模块里的函数里的处理后的特征值数据集。进行可视化分析。bpca算法和EM算法插值的效果几乎相同,可见bpca算法最有效。
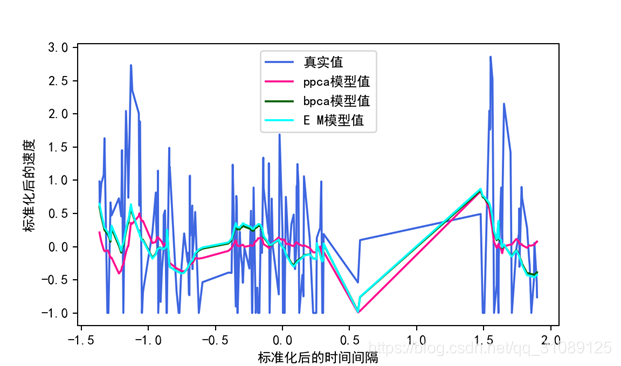
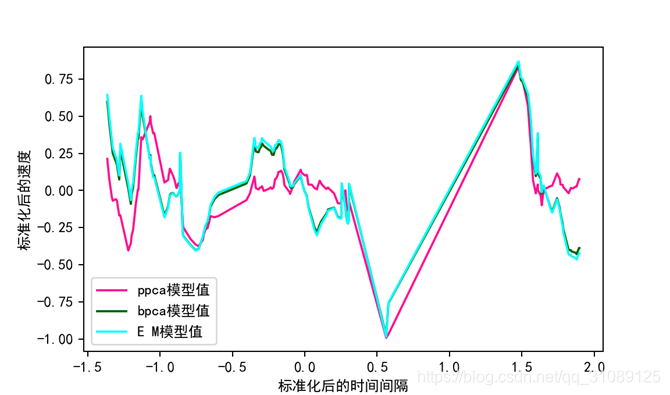
经验总结:
处理的数据存入表格,再进行操作,否则,会出现容易出现object类型
安装ycimpute库需要下载适合python版本的whl包
知识可以共享,数据打死也不会共享。

















 1337
1337

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









