






问题:DBMS 是如何管理其内存和磁盘之间来回移动数据的?
答案:在决定如何在磁盘中来回移动数据时,我们必须考虑两个关键方面:
空间控制【Spatial Control】:
- 将页【pages】写在在磁盘的什么地方?
- 以及如何布局它们,才可以使得我们最大化的利用串行IO,因为磁盘的顺序读取很快,但是随机读取很慢(因此我们的目标是使经常一起访问的页【pages】在磁盘上物理上尽可能靠近)。
时间控制【Temporal Control】:
- 何时将页面读入内存,何时将其写入磁盘?
- 目标是最大限度地减少因必须从磁盘读取数据而导致的停顿【stall】数量
解决方法是基于空间与时间的权衡~
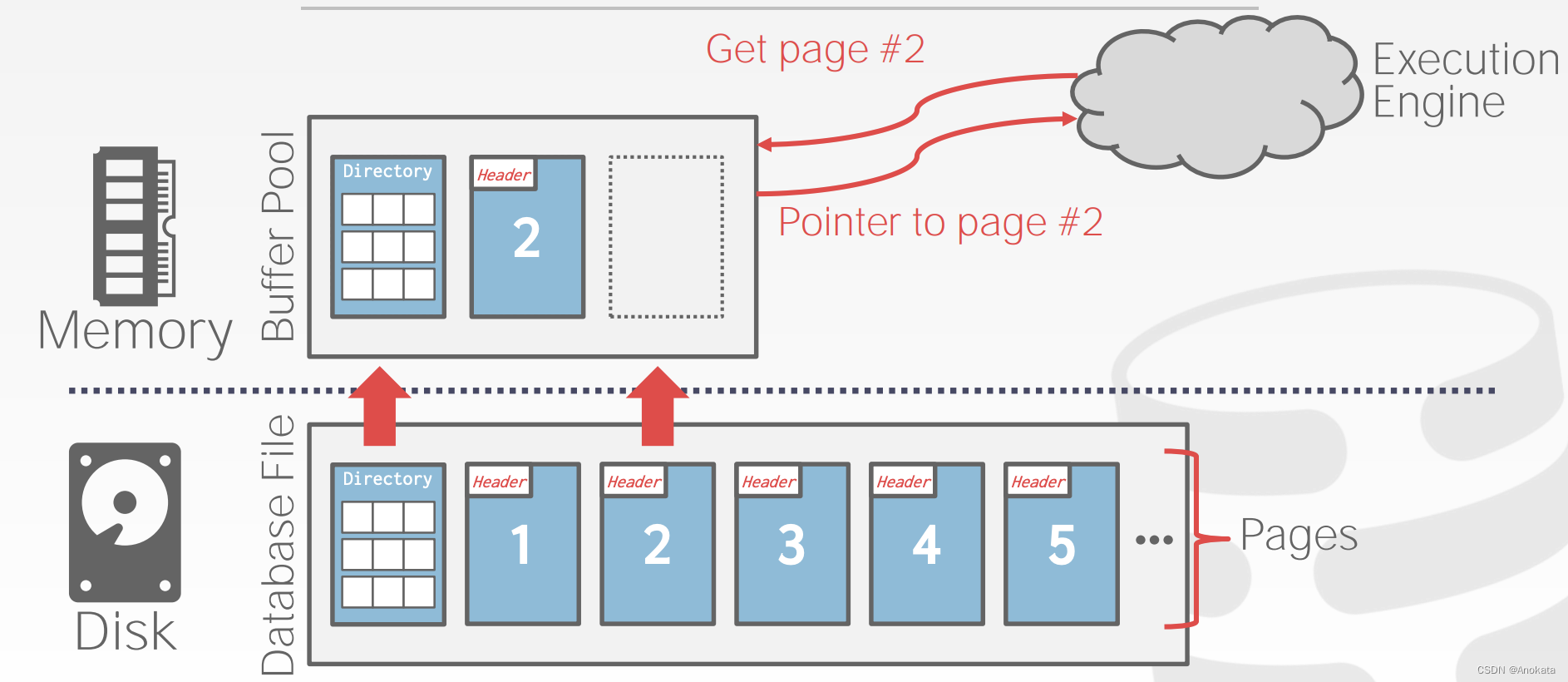
注:为什么数据库不适用操作系统的虚拟内存,而要用Buffer Pool ?
因为我们对查询【query】想要做什么有更好的了解,因此我们可以做好准备,并从磁盘读取数据并将其写入内存,而因为操作系统只看到粒度级别的,比如在页【page】上的读【read】和写【write】,不了解实际查询【query】如何访问这些页面,毕竟操作系统对所有的页【pages】都一视同仁,而在数据库系统中,有的页【pages】对应的是所有,有的页【pages】对应的是数据,所以所有的页【page】不因该被视为是一样的。
1 Buffer Pool Manager
1.1 Buffer Pool organization
在高层次上,缓冲池【Buffer Pool】就是一个从操作系统分配得到的一个很大的内存区域【Memory Region】,并基于数据库的页大小(Postgres时8kb,Mysql是16kb),在逻辑上将它们分为固定大小的页。数据库将在它自己的地址空间中管理它,将用它来复制查询【query】所需从磁盘访问的页【page】,并将它们放入缓冲池【buffer pool】中(需要注意的是,内存中帧对应的页不需要像磁盘中那样连续)。
- 内存区域【Memory Region】被组织为固定大小页【pages】的数组。
- 该数组中的条目,也被称为帧【frame】,其大小等于页【page】的大小(至于为什么这么叫,因为别的术语都有其含义,比如page,slot,block)。
- 当 DBMS 请求某个页【page】时,会将该页【page】的一个精确副本放入其中一个帧【frame】中,注意这里一般不涉及marshing或者序列化处理,它只是逐字节复制罢了。
- 脏页会被缓冲,不会立即写入磁盘,后面我们会在讲持久化和恢复时重温。这里面涉及的时写通【write through】和写回的【write back】(有一个单独的日志文件,叫做预写日志【write ahead log】,它会跟踪我们所做的更改,我们会确保在脏页之前刷新到磁盘中)区别。

1.2 Buffer Pool Meta Data
页表【Page Table】(并非操作系统的页表)负责跟踪当前内存中的页【page】。你可以将页表想象为一个哈希Map,它将页ID【Page ID】映射到帧【frame】(其在缓冲池中的位置),如下所示:

当执行引擎请求访问某个页时,页表【page table】需要告知其在缓冲之中的位置,或者告知其不在缓冲池中。在这种情况下,我必须去我的页目录【page direction】找到那个页ID在磁盘上的位置,然后决定把它复制到哪个帧里。
需要注意的是,数据库是一个线程安全的应用,当多个线程同时访问一个页表中不存在的页面时,我们需要避免多线程对页表替换更新。因此,每当我们访问一个页面时,我们需要在页表【page table】中将他钉住【pin】,这特别像一个引用计数器【reference count】,该计数表明当前有多少活跃的查询正在访问该页。我们在页表【page table】中存储这个引用计数器,而不是在页【page】中,因此当某个页被驱逐出去时,我们也不需要额外再去存储其对应的引用计数器,它只会存在于内存中,也就是页表中。
同时页表【pge table】还为每个页【page】维护着附加元数据,这些元数据时负责记录在整个系统中如何使用这些页面:
- dirty flag:告知有其他查询自加载到内存中后修改了该页【page】
- pin/reference counter:跟踪需要此页面保留在内存中的工作线程的数量,因此当我们运行驱逐策略时,它不能被驱逐
- access tracking information:记录谁正在访问过页面,最后一次页面访问的时间等等
所以,当我们访问某个不存在于缓冲池中的页【page】时,那么它需要将这个位置锁存【latch】起来,然后去后台检出该页【page】,更新页表,并释放锁存【latch】。
如果我要读它,我会把它钉住,即使我要给它写入的话,我也会把它钉住,但如果我只是读它,我不会保留任何额外的信息,一旦我完成了读取,我就可以把引脚扔掉,如果我在写它,我必须维护一个脏标志,表示我修改了这个东西,这是为了防止数据库系统把它写回磁盘时直接扔掉它,因为它知道当它访问时,其他查询修改了页面因此我们必须确保这些更改最终会回到磁盘。
1.3 Lock 和 Latch
锁【lock】:
- 保护数据库的逻辑内容免受其他事务的影响。
- 在事务期间内持有
- 需要能够回滚更改
锁存器【latch】:
- 护 DBMS 内部数据结构的关键部分免受其他线程的影响
- 在操作期间持有
- 不需要能够回滚更改
简单的讲,锁是用户空间下的,用户保护一个高级概念,比如元组【tuple】,表【table】,数据库【database】等,需要注意的是,锁是有死锁检查以及其他保护策略的,而锁存器是系统空间下,他是低级的原语,我们主要用它保护数据库系统内的临界区,主要是数据库开发使用,他本质上等同于mutext,而且它没有死锁检查以及其他保护策略。
1.3 页表和页目录
页目录【page dictionary】是从页ID【Page ID】到数据库文件中页位置【page location】的映射。
- 所有更改都必须记录在磁盘上,以便 DBMS 在重新启动时能够找到它
页表【page table】是从页ID【Page ID】到缓冲池的帧中该页副本的映射。
- 这是一个不需要存储在磁盘上的内存数据结构
2 分配策略
全局政策【Global Policy】:
- 为所有活跃的查询做出决策
局部政策【Local Policy】:
- 将帧分配给特定查询,而不考虑并发查询的行为
- 但仍然需要支持共享页面
这两种策略各有优势,现代数据库是基本都是这两种策略的组合。
2.1 缓冲池优化
- 多个缓冲池【Multi Buffer Pool】
- 预取【Pre-Fetching】
- 扫描共享【Scan-Sharing】
- 缓冲池绕过【Buffer Pool Bypass】
2.1.1 多个缓冲池
DBMS 并不总是为整个系统提供一个缓冲池。
- 多个缓冲池实例
- 每个数据库一个缓冲池
- 每种页类型一个缓冲池
将内存分区到多个池有助于减少锁存器【Latch】争用(因为锁存器是锁整个页表,所以他会成为性能瓶颈),并提高局部性。
方法1 Object ID --- SQL Server的方案
在记录 id 【record ids】中嵌入对象标识符【object identifier】,然后维护从对象到特定缓冲池的映射。

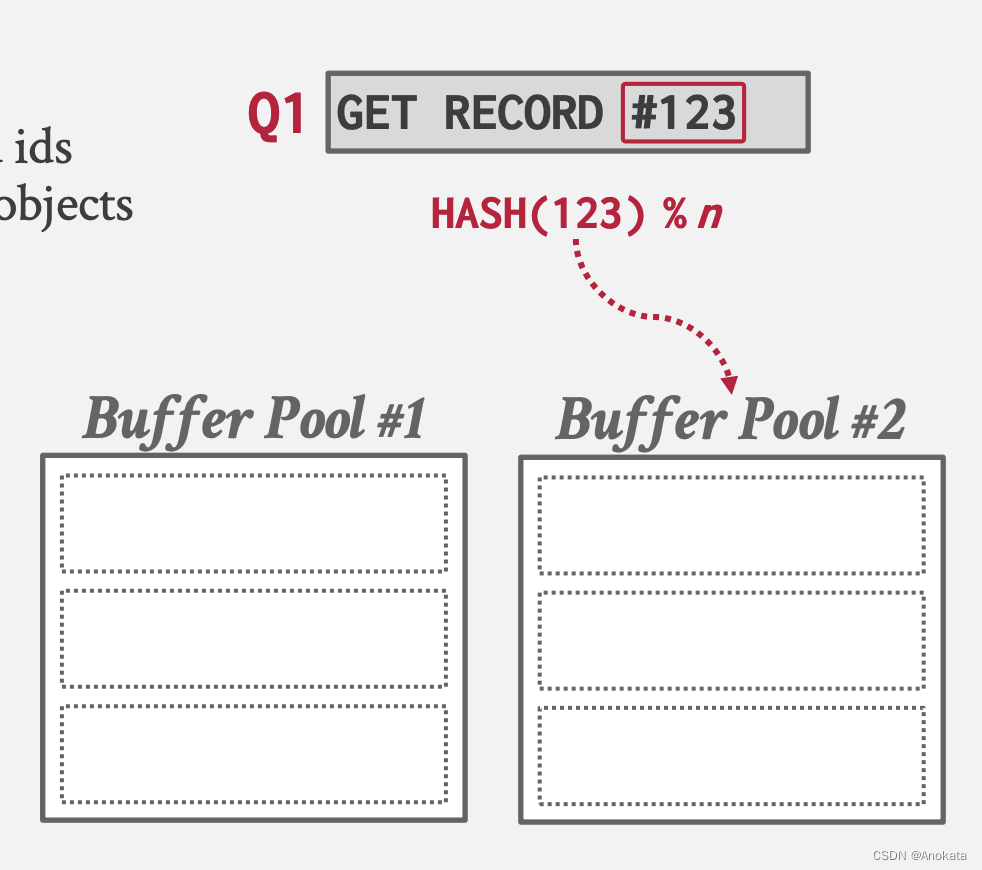
方法2 Object ID --- MySQL的方案
- 对页 ID 进行 hash,以选择要访问的缓冲池。
2.1.2 预取
DBMS还可以根据查询计划预取页面:
- 顺序扫描
- 索引扫描
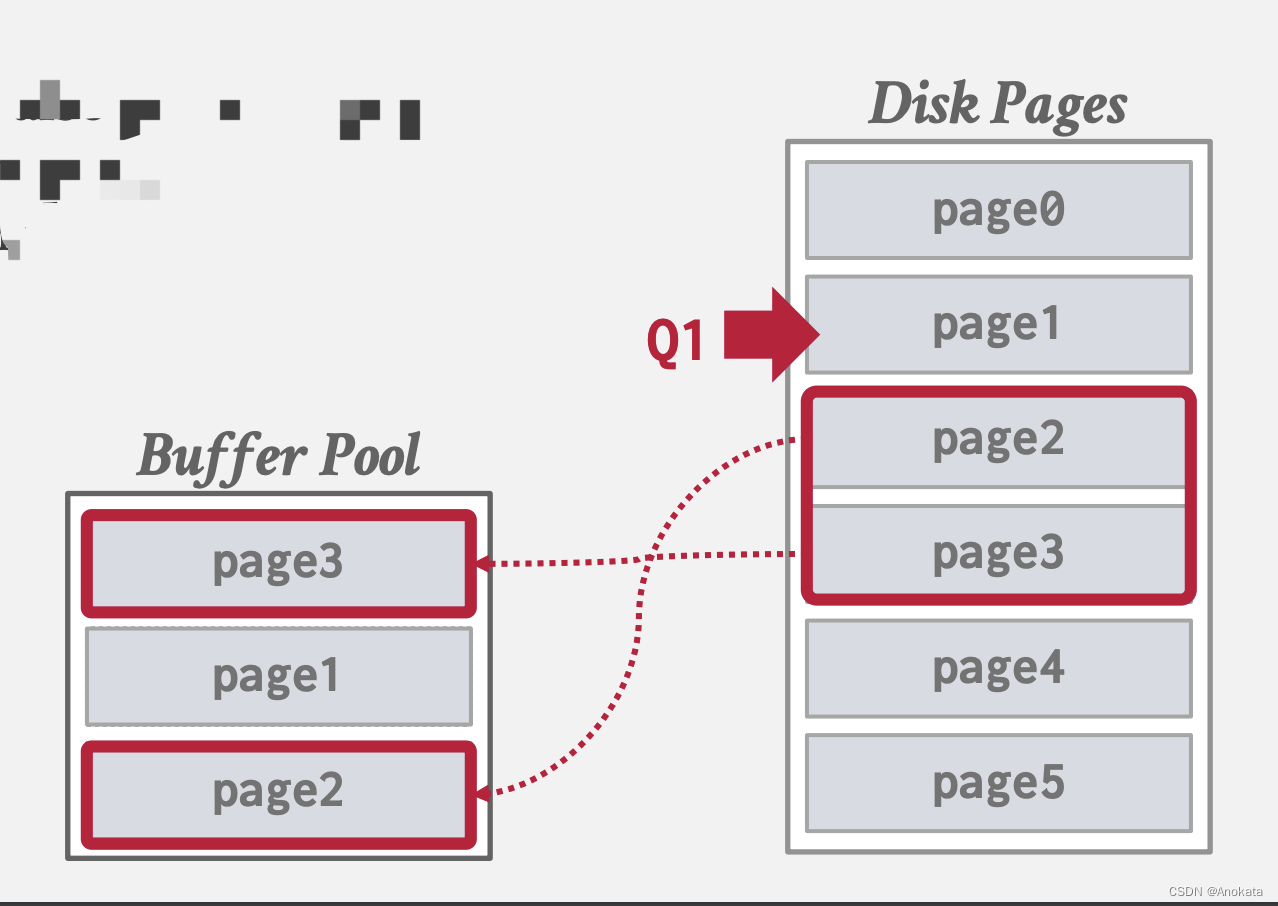
顺序扫描预取前(栗子里是游标分页):

顺序扫描预取后:
索引扫描预取前:


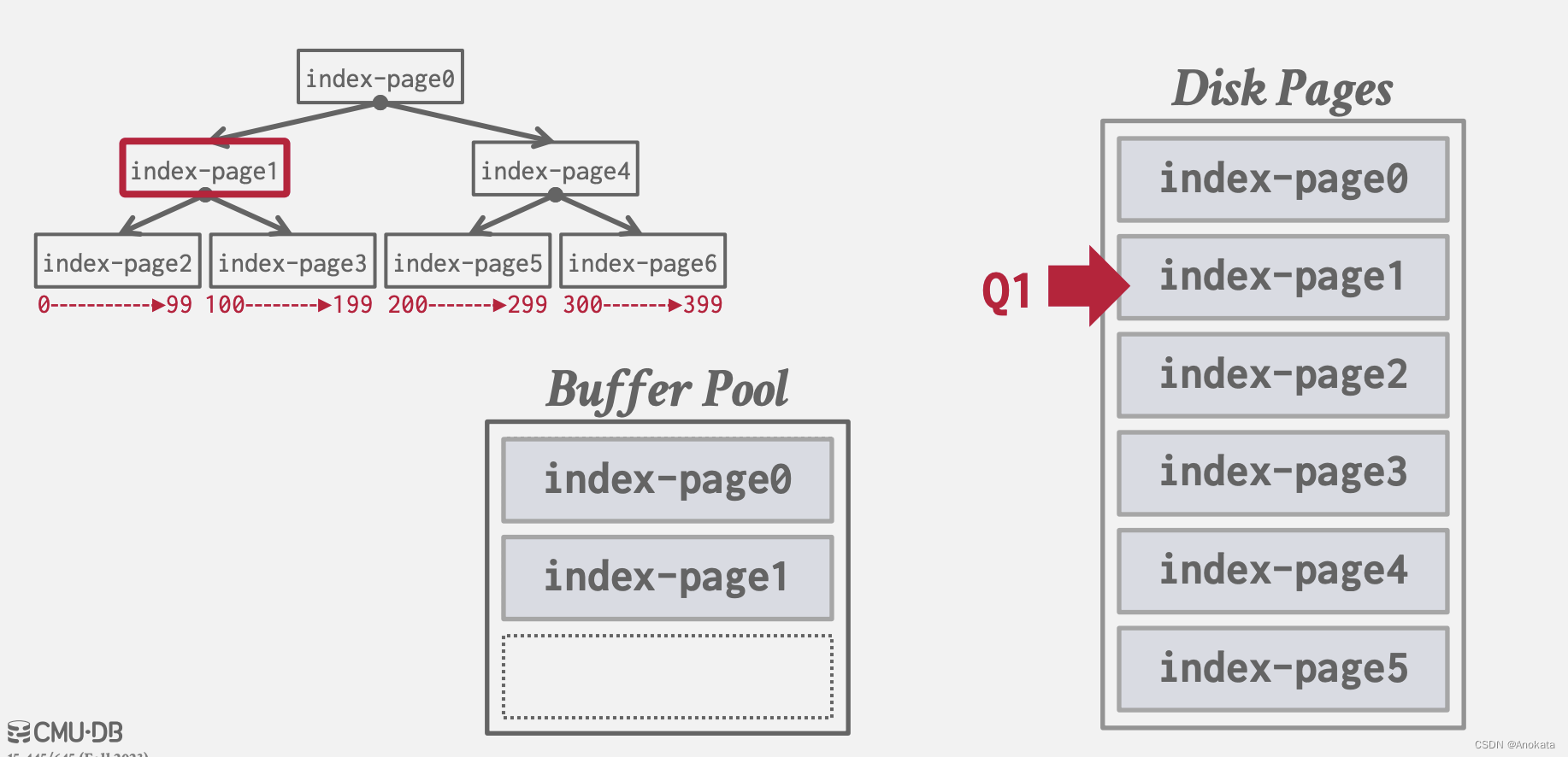
索引扫描预取前后:
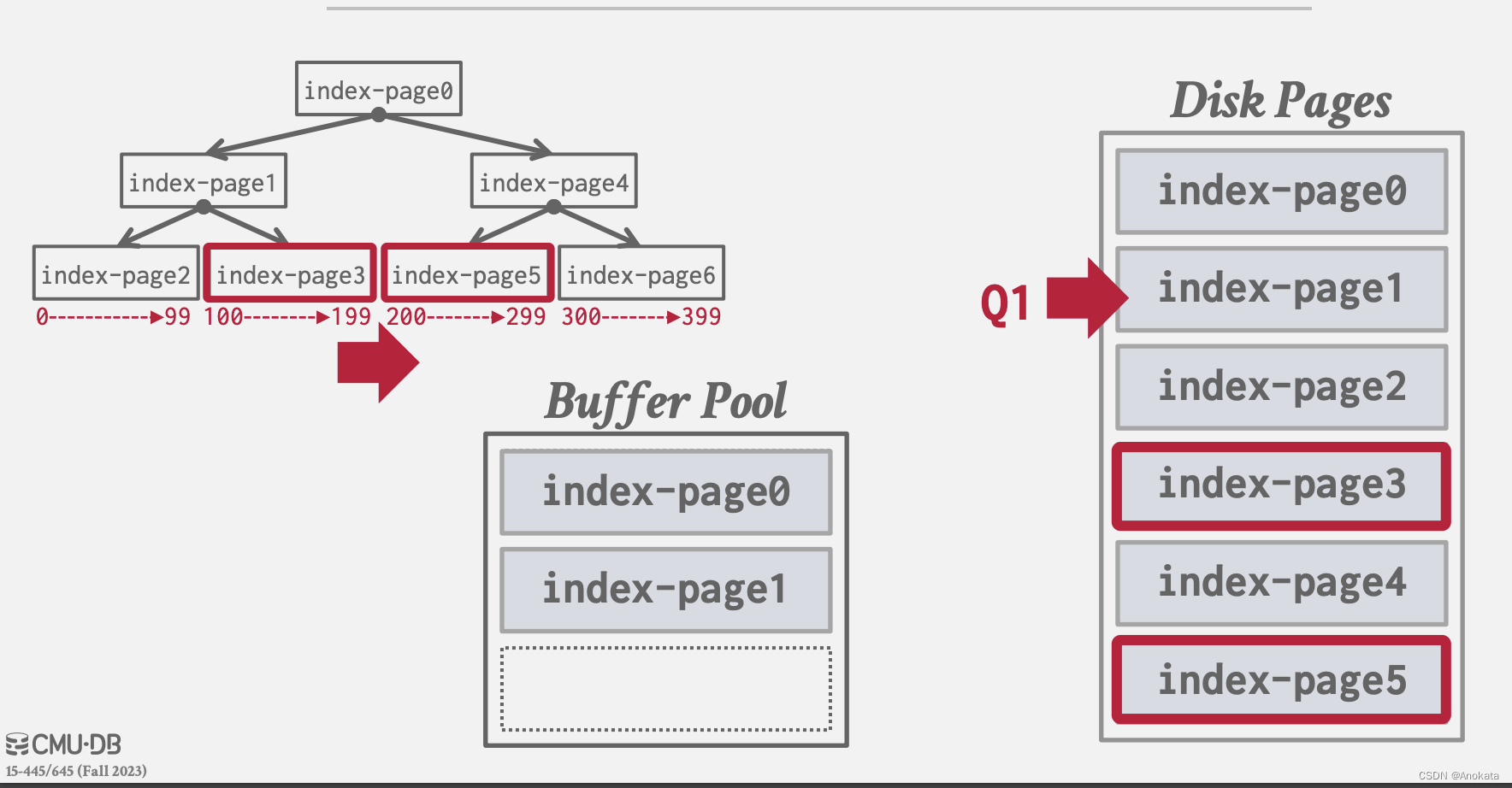
根据查询计划,我们 需要页0,页1,而根据条件,我们需要检出页3,以及预取页5,而操作系统是无法做到的,因为页3和页5是不连续的。数据系统能知道这样的原因是,每一个页节点都有一对兄弟节点的指针,页3的兄弟节点是页5,因此数据库系统可以提前预取。
2.1.3 扫描共享(也叫同步扫描)
这里的基本思想是出现了一堆查询,它们想要访问同一个表,其中一个开始,它开始扫描页面,,我们可以识别出它们需要相同的数据,我们背靠背,我们的游标连接到它们的游标上,我们就可以同时读取相同的页。
扫描共享实际上处于访问方法【access method】最低的物理层。
如果一个查询想要扫描表,而另一个查询已经在执行此操作,则 DBMS 会将第二个查询的游标附加到现有游标上。
例子:
- 完全支持 DB2、MSSQL、Teradata 和 Postgres,即对于不完全相同但读取相同页【page】的查询,这种完全扫描共享。
- Oracle 仅支持相同查询的游标共享,简而言之,他是通过对查询座字符串hash,因此任何不一样,都会的导致无法命中。
栗子:
我们针对A表的val字段做加和【sum】,
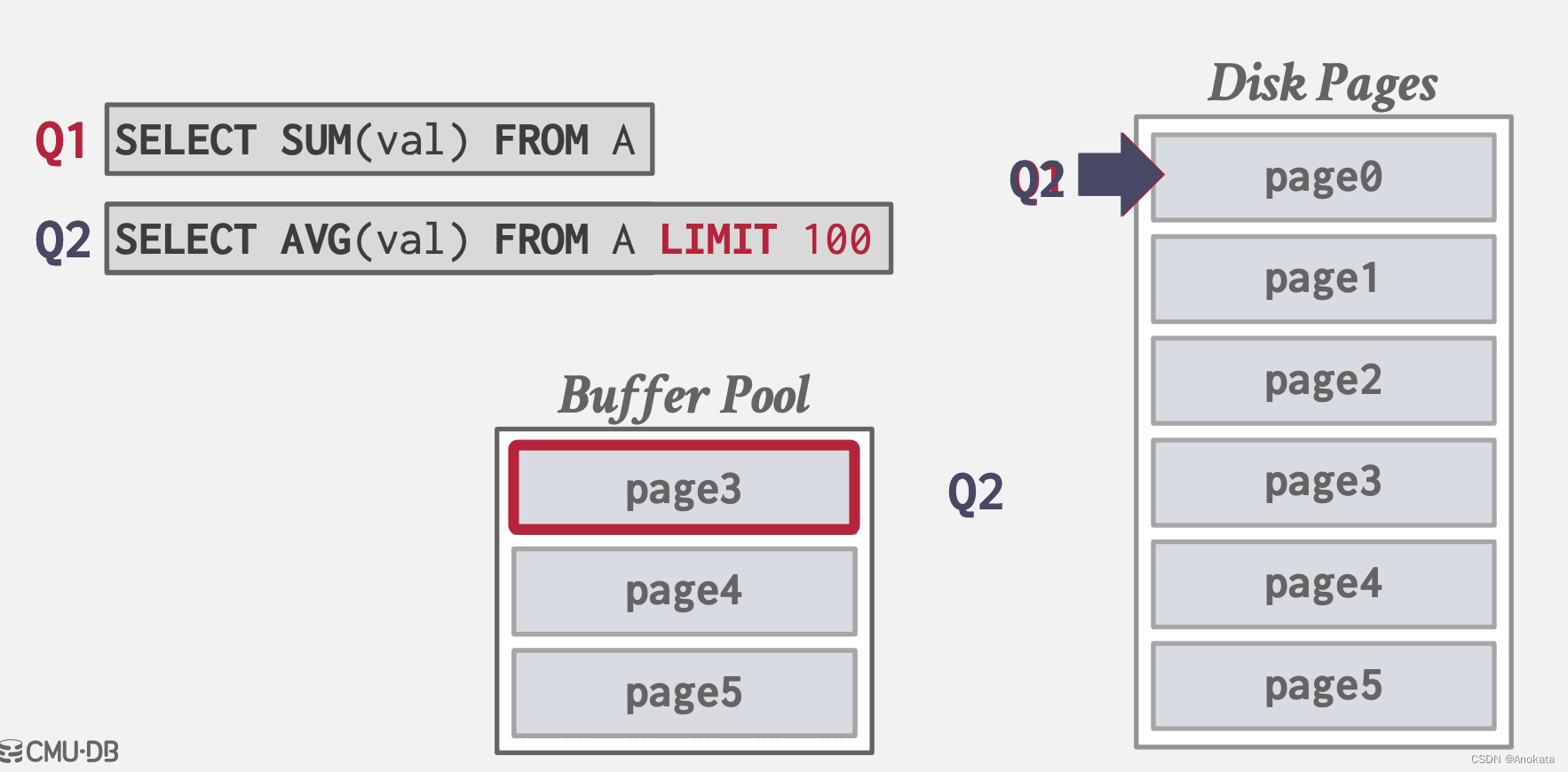
它把游标【Cursor】移到页面上,开始读取它们,把它们取到缓冲池中,首先它得到第0页,它不在那里,所以它把它放到内存中,然后是第1页,以此类推。现在我们到第三页,我们还没有讨论过驱逐政策,但第0页是最后一个被使用的,所以我们继续把第0页驱逐出去,以放置第3。
现在Q2出现了,操作相同的表,但Q2不是加和,而是求平均值,最笨的办法,就是让 Q2 的游标到最开始。而聪明的办法是让Q2的游标附着到Q1的游标上,随着Q1指定到最后并结束,Q2会再回过头来把前面漏掉的页重新检索出来计算。
但是如果Q2里面有limit或者窗口函数,那么共享就会变得棘手!!
还有一种极端的扫描共享,叫做持续扫描共享【CONTIONOUS SCAN SHARING】,但是没人实现过。
2.1.4 缓冲池绕过
顺序扫描操作符不会将获取的页面存储在缓冲池中以避免开销,而是放在一小块砖为该查询创建的一个工作内存中。
→ 内存被看作是运行的查询【query】的本地内存【local memory】。
→ 如果操作符需要读取磁盘上连续的大量页面,则效果很好。
→ 也可用于临时数据【temporary data】(排序【sort】、连接【join】)。
在 Informix 中称为“轻扫描【Light Scan】”
3 替换策略
当 DBMS 需要释放帧以为新页面腾出空间时,它必须决定从缓冲池中逐出哪个页面。
替换策略的目标:
- 正确性【Correctness】
- 准确度【Accuracy】
- 速度【Speed】
- 元数据开销【Meta-data overhead】:维护元数据的成本很高,我们需要跟踪页面的访问方式,这样我们就可以决定删除哪些内容
3.1 LRU
维护每个页面上次访问时间的单个时间戳。 当 DBMS 需要逐出一页时,选择时间戳最旧的一页。
- 保持页面排序,以减少驱逐时的搜索时间
3.2 C LO C K
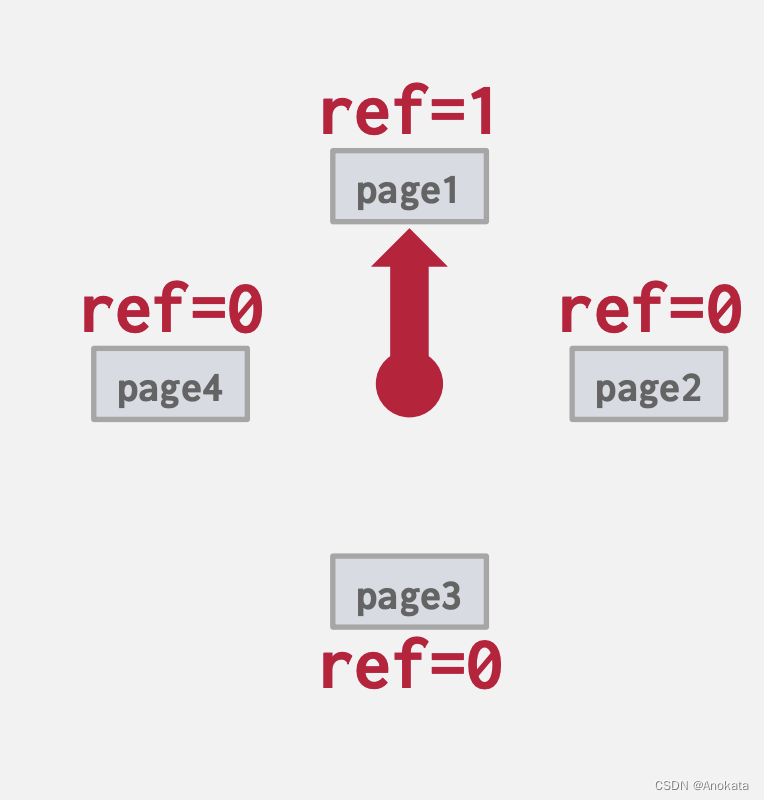
它类似于LRU,但是它不用为每一个页维护一个时间戳:
- 每一页都有一个引用位
- 当某个页被访问时,对应的引用位设置为1
用“时钟指针”组织环形缓冲区【circular buffer】中的页面:
- 扫描时,检查页面的位是否设置为 1。
- 如果是,则设置为0。 如果不是,那就驱逐。
缺点:
LRU + CLOCK 替换策略容易受到顺序洪泛【sequential flooding】的影响。
- 比如某个查询【query】执行了一个读取每个页面的顺序扫描
- 这会污染缓冲池,因为页面被读取一次,然后就不再读取了
- 在 OLAP 工作负载中,最近使用的页面通常是最好驱逐的页面。
LRU + CLOCK 仅跟踪页面上次访问的时间,但不跟踪页面访问的频率。
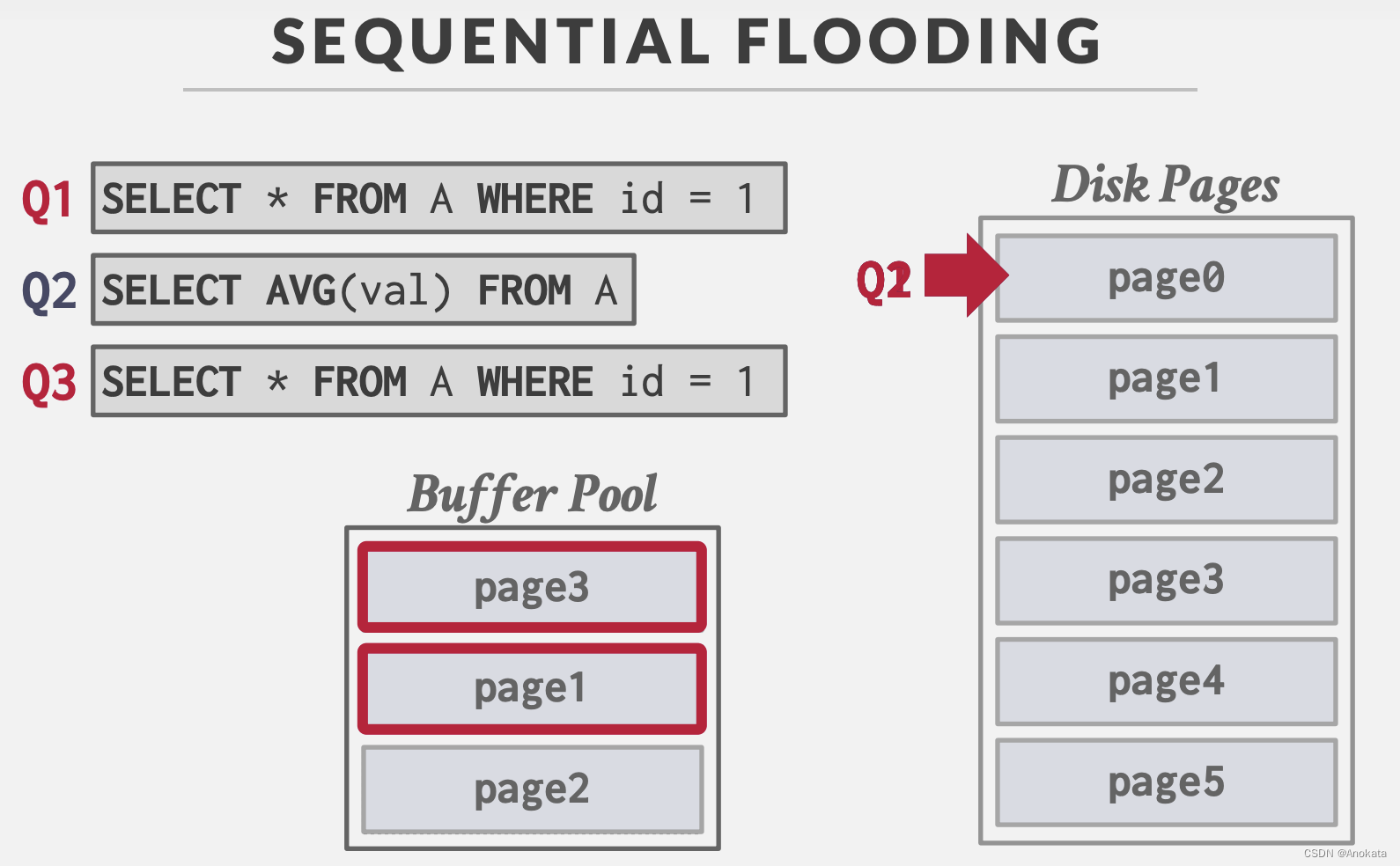
顺序洪泛:
Q1访问页1
Q2顺序访问所有页,当缓冲池不足时,页1由于是最早访问的页面,因此会被驱逐
Q3访问页1,而刚被驱逐!!!
3.3 LRU-K
以时间戳的形式跟踪对每个页面的最后 K 次引用的历史记录,并计算后续访问之间的间隔。
- 可以很好地区分引用类型
然后,DBMS 使用此历史记录来估计下次访问该页面的时间。
- 逐出具有最长预期间隔的页面。
- 为最近被驱逐的页面维护一个临时的内存缓存,以防止它们总是被驱逐。
3.4 MYSQL近似LRU-K
它使用单个 LRU 链表,但有两个入口点(“okd”与“young”)。
→ 新页面总是插入到old列表的头部。
→ 如果old链表中的页面再次被访问,则插入到young'链表的头部。

此时,我要访问页1,而它不在buffer pool中,我们将其加载到内存中,因为没空间了,我们需要驱逐页8,并将页1放在old链表的头部:
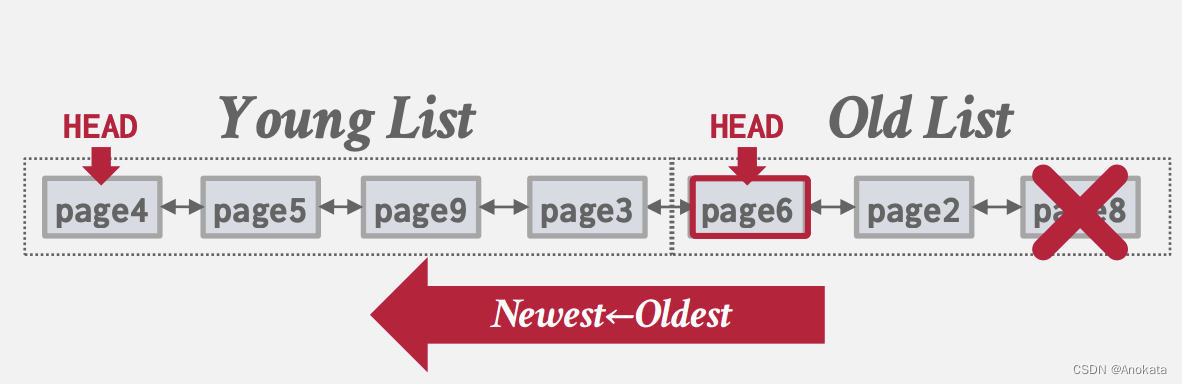

假设只页1再次被访问,我们可以识别到它已经在jold链表里了,因此我们将其放到young的头部,并滑动所有链表:
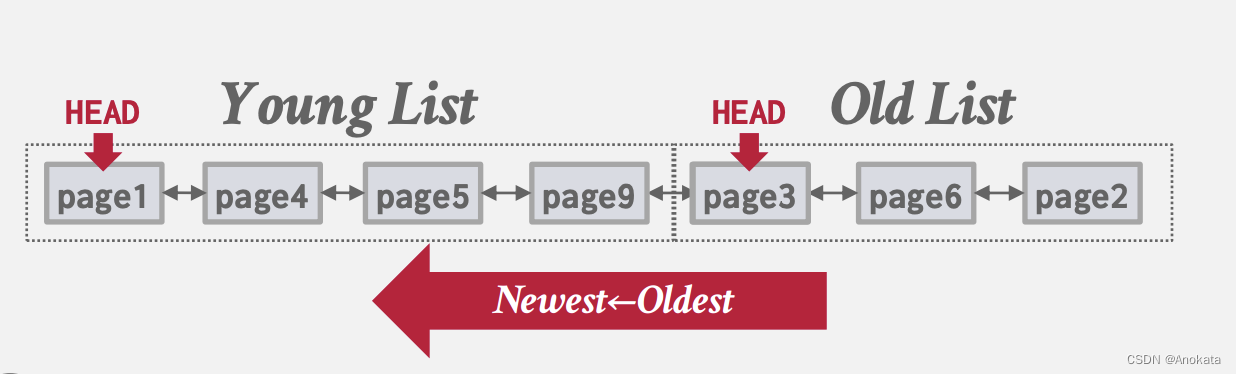
该方案于LRU不同点在于它ing不是维护之前访问之间的间隔, 但只要知道它在old和young链表的界限之内,那很可能是最近被访问的。
3.5 本地化LO C A L I Z AT I O N
DBMS 根据每个查询【Query】选择要驱逐的页面。 这最大限度地减少了每个查询对缓冲池的污染。
- 跟踪每个查询【Query】访问过的页面
示例:Postgres 维护一个查询专用的小型环形缓冲区【ring buffer】。
3.6 优先级提示【Priority Hint】
DBMS 了解查询【Query】执行期间每个页面的上下文。
它可以向缓冲池提供有关某个页面是否重要的提示。
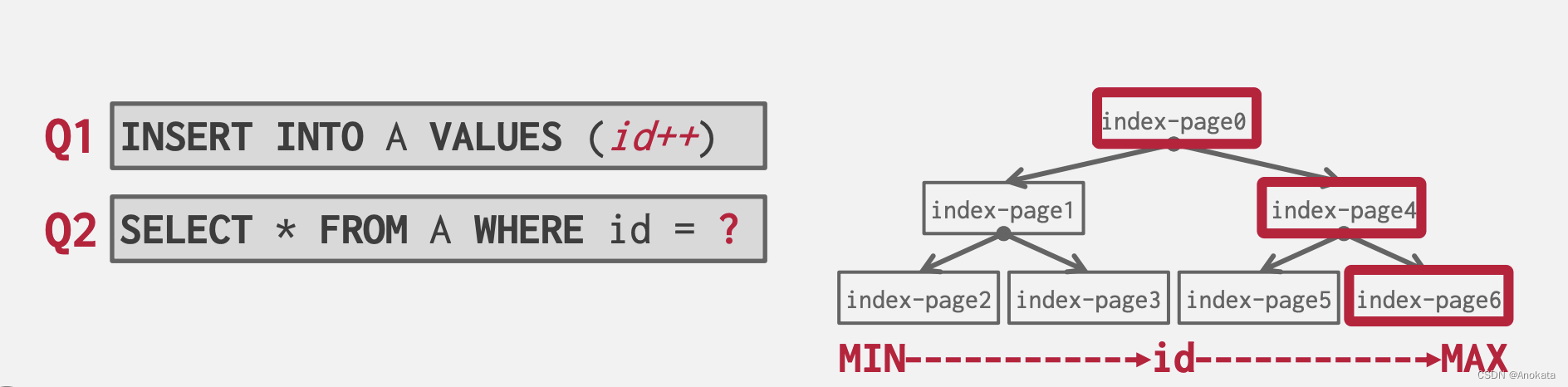
3.7 脏页
快速路径【Fast Path】:如果缓冲池中的页面不是脏的,那么 DBMS 可以简单地“删除”它。
慢速路径【Slow Path】:如果页脏了,则 DBMS 必须写回磁盘以确保其更改得以保留。
快速驱逐【n fast evictions】与将来不会再次读取的脏写页面之间的权衡。
3.8 后台写【Backgroung Write】
DBMS 可以定期遍历页表并将脏页写入磁盘。
当脏页被安全写入时,DBMS 可以逐出该页或只是取消设置dirty标志。
需要小心的是,系统在写入日志记录之前不会写入脏页......
3.9 问题
操作系统/硬件尝试通过重新排序和批处理 I/O 请求来最大化磁盘带宽。
但他们不知道哪些 I/O 请求比其他请求更重要。
许多 DBMS 告诉您切换 Linux 以使用截止日期【deadline】或 noop (FIFO) 调度程序。
→ 示例:Oracle、Vertica、MySQL
3.10 DISK I/O SCHEDULING
很多数据库在操作系统之上还有一个小的填充层,它将负责跟踪缓冲池管理器关于读取和写入的未完成的请求(DBMS 维护内部队列来跟踪来自整个系统对页的读/写请求),并决定如何将它们组合在一起以优化性能。
它本质上类似于基于不同的因素,决策不同IO请求的优先级:
- 顺序 I/O 与随机 I/O
- 关键路径任务【Critical Path Task】与后台任务【Background Task】
- 表、索引、日志、临时数据【Table vs. Index vs. Log vs. Ephemeral Data】
- 事务信息【Transaction Information】
- 基于用户的 SLA
操作系统不知道这些事情并且可能会妨碍。
3.11 OS PAGE CACHE
大多数磁盘操作都是通过操作系统 API 进行的。 除非 DBMS 告诉它不要这样做,否则操作系统会维护自己的文件系统缓存(也称为页面缓存【page cache,】、缓冲区缓存【buffer cache】)。
大多数 DBMS 使用直接 I/O (O_DIRECT) 来绕过操作系统的缓存。我们不希望操作系统缓存我们读写的页面,因为我们想要自己来处理。如果我们使用OS的缓存,那么带来的问题有:
- 页面的冗余副本:OS的页缓存【page cache】和数据库的buffer pool都有相同的页
- 不同的驱逐政策。
- 失去对文件 I/O 的控制:如果你不小心,你也会失去对磁盘上的内容何时被刷新的控制
3.12 FSYNC PROBLEMS
如果 DBMS 掉用 fwrite 会发生什么?
文件会被写入 OS 的页缓存【page cache】中,因为 OS 尝试智能,以使得速度变得更快,因此当 fwrite。返回时,页不一定被写入到磁盘中,它可能还在页缓存【page cache】中,至于什么时候会被写入磁盘,那完全是操作系统决定的。
那么如果 DBMS 调用 fsync 呢?
调用会阻塞,直到硬件返回数据已经被持久化,但是,硬件也会耍一些小游戏。
如果 fsync 失败(EIO),会发生什么?
→ Linux 将脏页标记为干净页,因为这并不是linux的panic,
→ 如果DBMS再次调用fsync,那么Linux告诉你flush成功了,但它其实在撒谎.
4 其他内存池
DBMS 需要内存来存储元组【tuples】和索引【index】以外的内容。
这些其他内存池可能并不总是由磁盘支持。取决于实现。
→ 排序 + 连接缓冲区【Sorting + Join Buffers】
→ 查询缓存【Query Caches】
→ 维护缓冲器【Maintenance Buffers】
→ 日志缓冲区【Log Buffers】
→ 字典缓存【Dictionary Caches】














 454
454











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









