






我们在前面讲了存储层,以及从次磁盘中将页面加载到缓冲池【Buffer Pool】中,现在我们继续往上,来讨论如何支持 DBMS 的执行引擎从页面中读取/写入数据。这部分是访问方法层的功能,它负责通过索引或者表本身,设置是其他机制来实现功能,
这里会涉及两种类型的数据结构:
- 哈希表(无序)
- 树(有序)
1 数据结构
DBMS 内部很多地方都在使用数据结构:
-
内部元数据:比如页目录【Page Dictionary】,或者页表【Page Table】,使用哈希结构,它们负责将页ID【Page ID】映射到磁盘中页的位置或者在缓冲区中的位置。
-
核心数据存储:比如索引组织的表,其中实际的元组本身在 b+ 树的叶节点中,所以你可以让你的表直接在数据结构中表示,而不是无序的热文件
-
临时数据结构:我们还可以使用这些数据结构来执行查询【Query】,生成临时或临时的数据集合,这样可以更有效地执行查询【Query】,这这基本上就是我们现在要非常快速地实现哈希联接的方式,以使用哈希联接非常快速地实现联接,所以我们会动态地建立一个哈希表,并用表中的数据填充或者扫描进行连接,然后扔掉哈希表,所以你知道我们在构建哈希表并不意味着它会持续很长时间
-
表索引
2.设计考虑
数据组织【Data Organization】:我们如何在内存/页面中布局数据结构以及存储哪些信息以支持高效访问。
并发性【Concurrency】:如何让多个线程同时访问数据结构而不引起问题。
3. hash table
哈希表实现了将键映射到值的无序关联数组【unordered associative array】。
它使用哈希函数来计算给定键在该数组中的偏移量,从中可以找到所需的值。
空间复杂度:O(n)
时间复杂度:
- 平均:O(1)
- 最差:O(n)
3.1 静态哈希表【Static Hash Table】
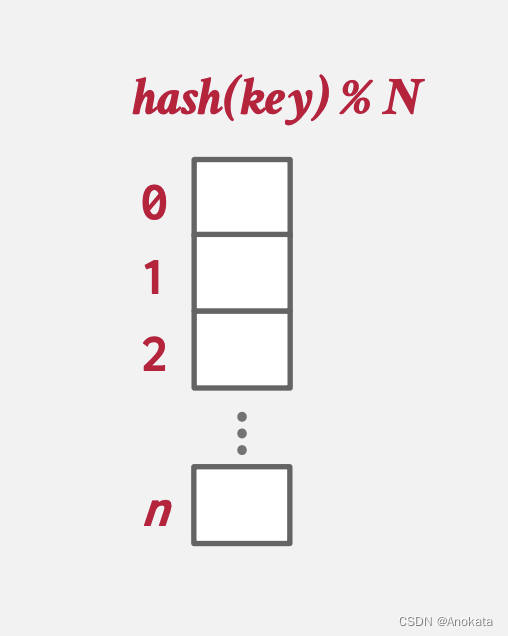
分配一个巨大的数组,该数组为您需要存储的每个元素分配一个槽。
要查找某个键对应的条目,请将元素键的哈希值与数组大小 N 取余,就可以得到他在数组中的偏移量
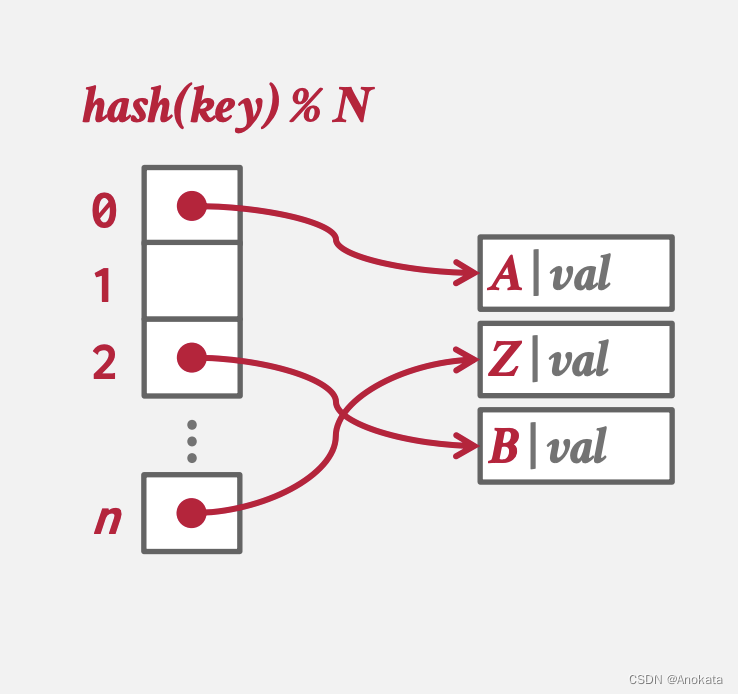
当然,在实际中,我们并不会在数组中存储 key,本质上存储的其实是一个指向其他地址的指针,该指针所在的结构中存储着 key 和其对应的值。
至于为什么我们要存储key,这是因为哈希碰撞。
不切实际的假设
- 假设1:元素数量提前已知并固定:在某些场景下是可以做到的,比如Buffer Pool,他的总大小以及页大小是已知的,因此我们可以计算出来元素总量,但是像索引,它随着数据插入会越来越多,因此它的元素数量是无法预知的
- 假设2:每个键都是唯一的。
- 假设3:完美的哈希函数保证不会发生冲突:如果 key1≠key2,则 hash(key1)≠hash(key2)
当我们在构建哈希表时,我们会考虑以下两点:
- 哈希函数【Hash Function】
- 如何将大的 Key 空间,映射到更小的有限的域【Domain】里
- 在速度与冲突率/碰撞率之间权衡
- 哈希方案【Hash Schema】
- 哈希模式是我们在完成哈希【hash】之后用来处理碰撞的机制
- 在分配一个大的哈希表与花费额外的计算来实现对 Key 的 GET/PUT 之间权衡
3.2 哈希函数
对于任意的 Key ,哈希函数可以返回一个数字(通常都是64位的)来代表该 Key 。
我们不想对 DBMS 哈希表使用加密哈希函数(例如 SHA-256)。并且,我们希望哈希函数可以在保证速度的情况下,提供更低的碰撞率。
下面是系统所使用的哈希函数的一个快速概述:
- CRC-64 (1975):用于网络中的错误检测。
- MurmurHash (2008):设计为快速、通用的哈希函数,redis也是用的它
- Google CityHash (2011):设计针对于短密钥(<64字节)更快
- Facebook XXHash (2012):来自 zstd 压缩的创建者。
- Google FarmHash (2014):CityHash 的新版本具有更好的碰撞率。
3.3 静态哈希方案【static hash schema】
方法1:线性探针哈希【Linear Probe Hashing】
方法2:布谷鸟哈希【Cuckoo Hashing】
我们将在高级数据库课程中介绍其他几种方案:
- 罗宾汉哈希【Robin Hood Hashing】
- 跳房子哈希【Hopscotch Hashing】
- 瑞士表【Swiss Tables】
3.3.1 线性探针哈希【Linear Probe Hashing】
它是一个巨大的表【table】(可以将它看作是一个巨大的环形缓冲【circular buffer】),他有很多插槽【slots】,通过线性搜索表中的下一个空闲槽来解决冲突。
要想插入元素,我们首先要对 Key 做哈希,如果对应的槽是自由的/空的【free】,我们就可以在这里插入元素,而如果对应的槽不是自由/空的【Not Free】,那就查找下一个自由/空的【free】槽(我们会一直查找,直到找到为止,但是如果遍历一圈回来的话,那说明该表已经满了,那就需要崩溃或者扩容了),并在那里插入元素。
- 要确定某个元素是否存在,请散列到索引中的某个位置并自此开始扫描【scan】。
- 必须将键【key】存储在索引中才能知道何时停止扫描。
- 插入和删除是查询的一般化
示例:谷歌的 absl::flat_hash_map
线性探针哈希【Linear Probe Hashing】也被称为开放寻址【Open Addressing】
栗子:
1️⃣ 插入元素A时,我们通过哈希函数计算出槽,并将key和value均存储进去,存储key的目的是为了查询时的扫描
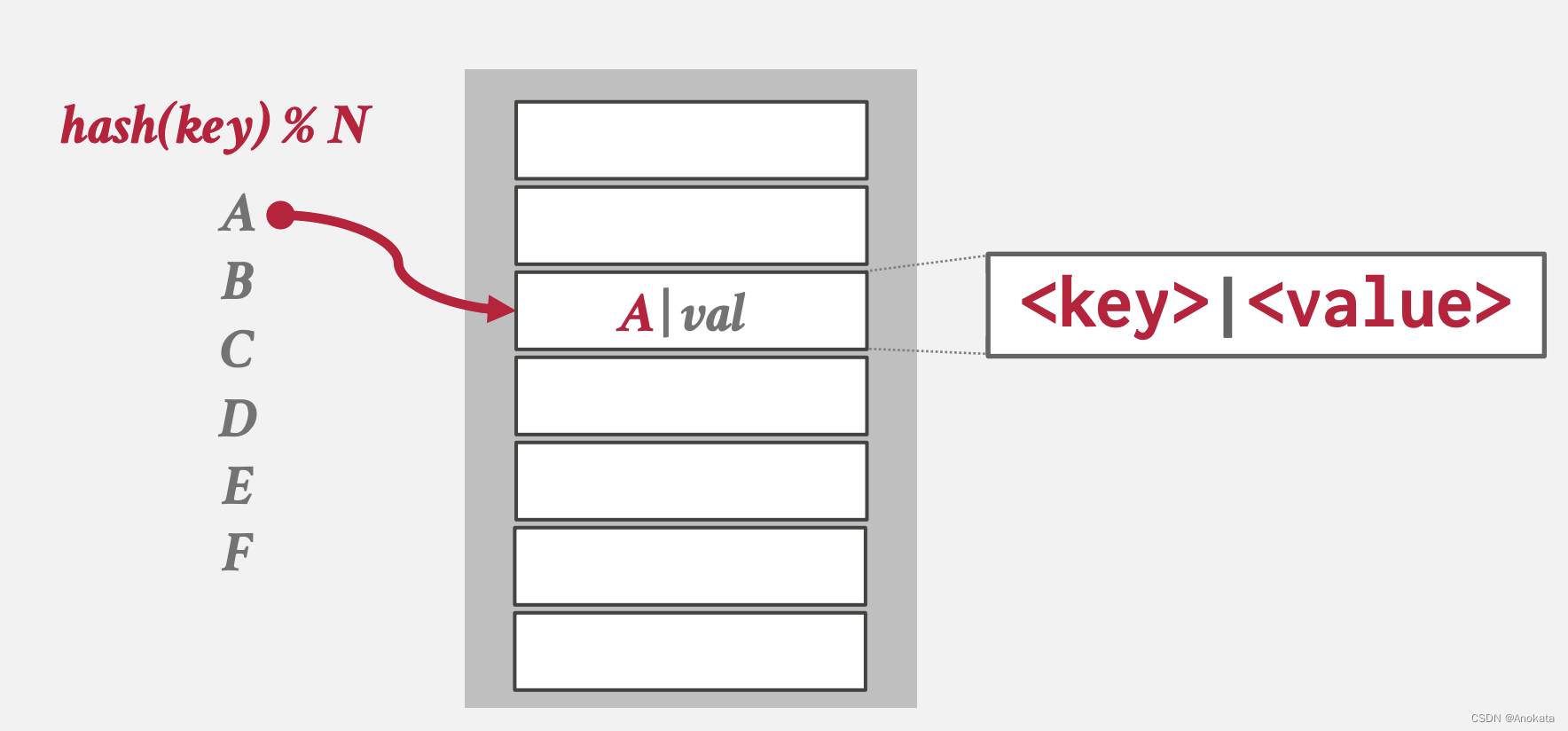
2️⃣ 插入元素C时,哈希函数算出它与元素A的插槽一致,这时候我们需要向后扫描,找到最近的空槽

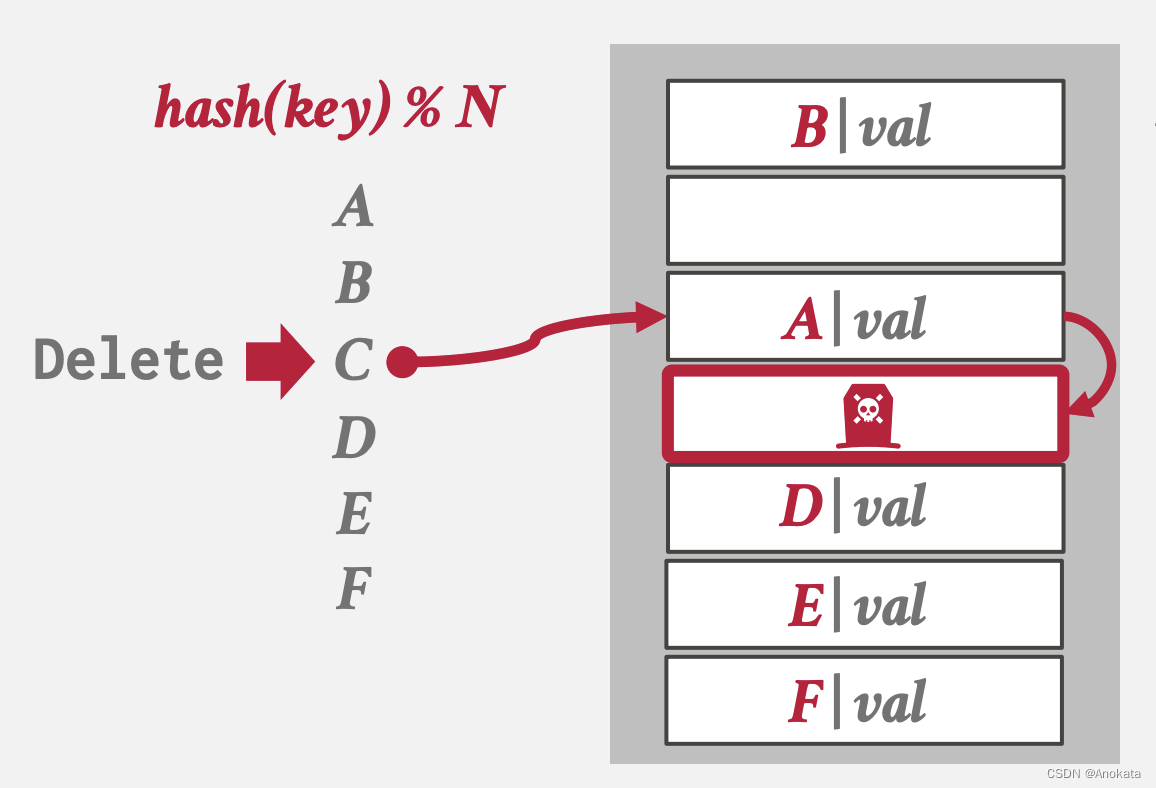
问题点 1 删除问题
1️⃣ 当A~F 元素全部插入后,我们删除元素C,我们通过扫描找到了C,
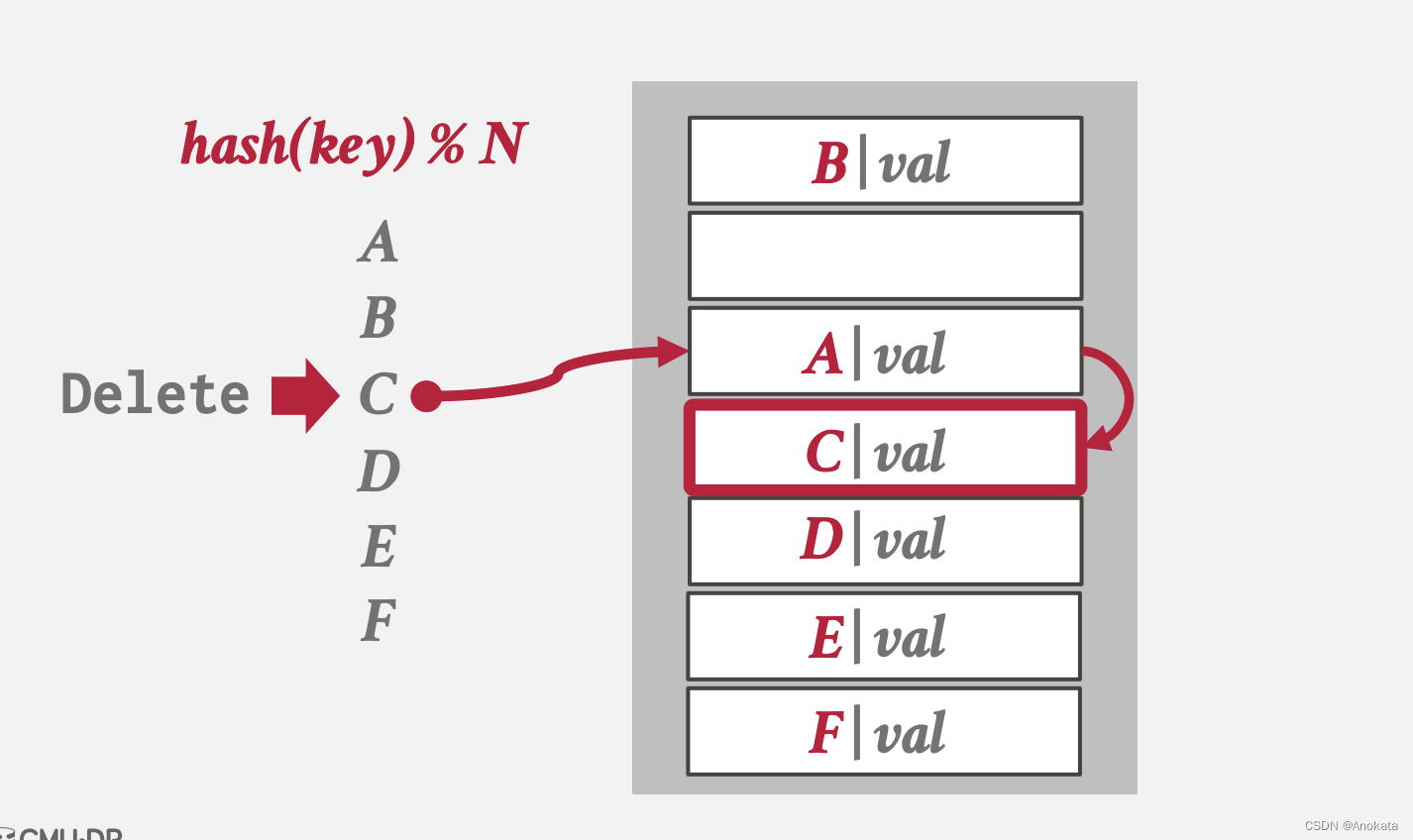
然后我们删除元素C
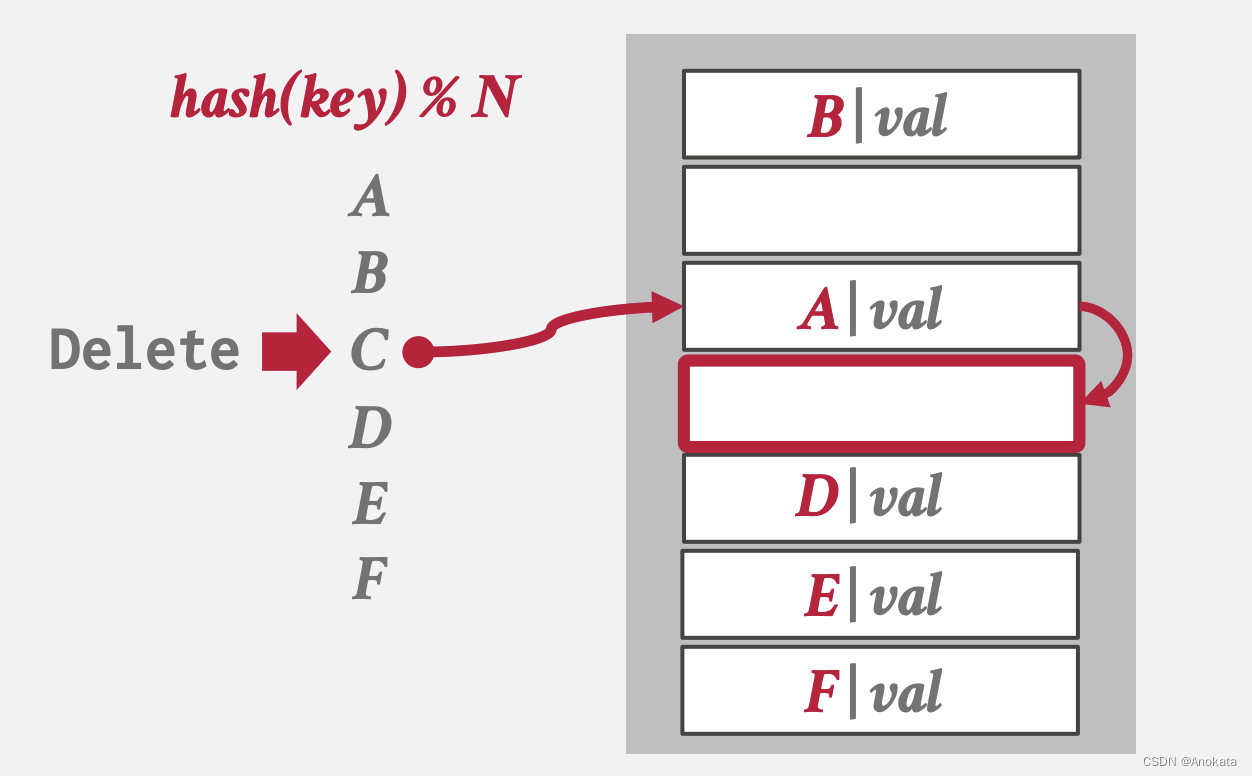
2️⃣ 此时,我们来查询元素D,但是元素D 本来是哈希到元素C所在的位置,而该位置现在变成空的,我们可以认为D元素不会在哈希表里了
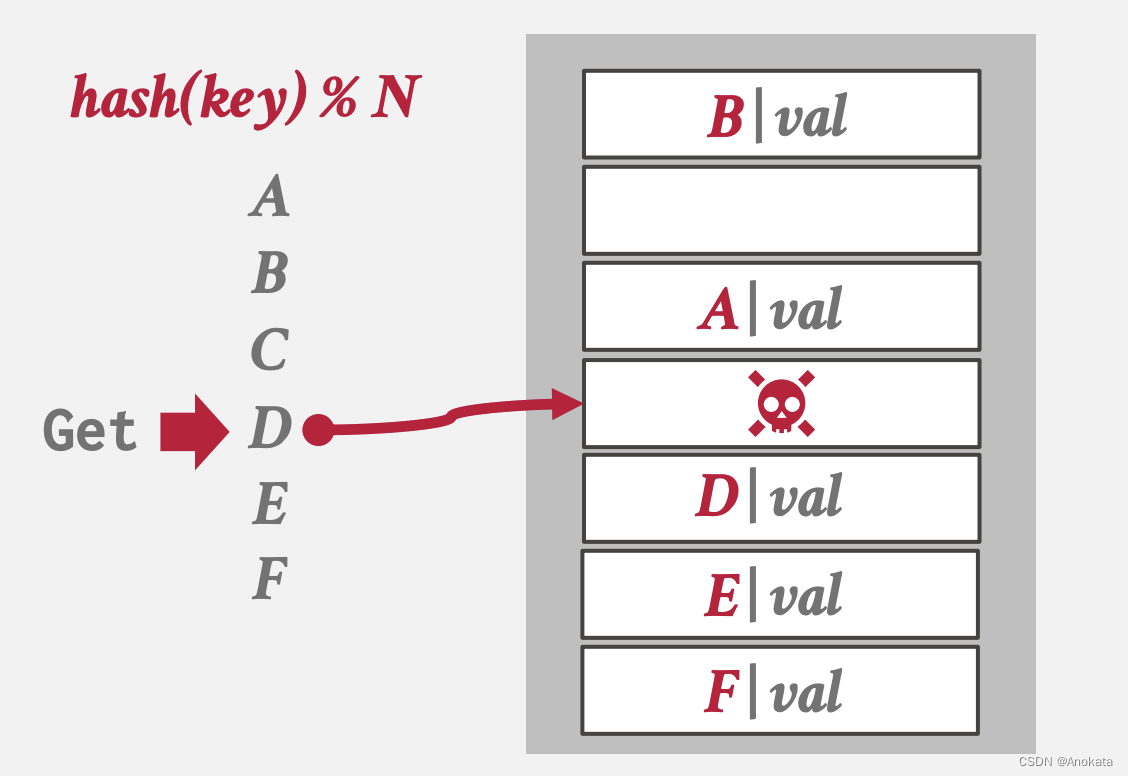
解决办法一 移动【Movement】:重新散列后面的键【Key】,直到碰到第一个空槽为止。但是这可能会导致全表的重新组织,代价太大了,没有任何系统采用这种办法
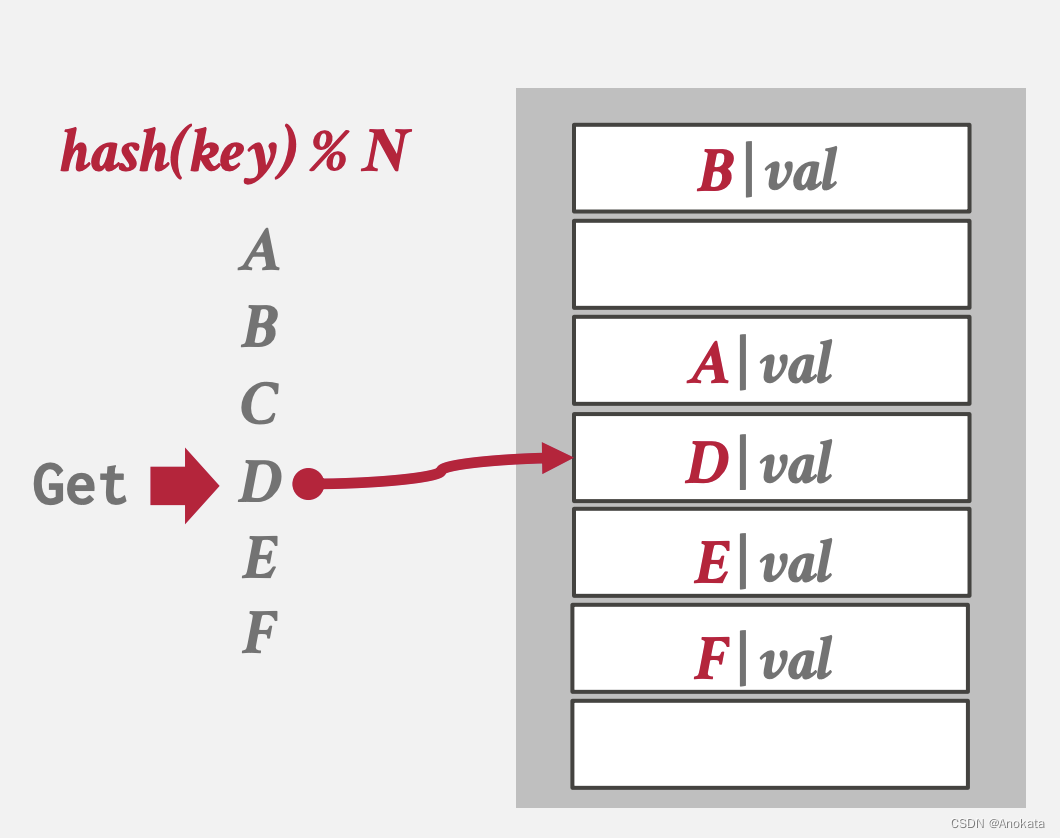
解决方法二 墓碑【Tombstone】,即设置一个标记来指示槽中的条目已被逻辑删除。
- 插槽可以重用给新的 Key。
- 可能需要定期进行垃圾收集,否则会浪费资源。
问题点 2 不唯一键
这里有两种方法:
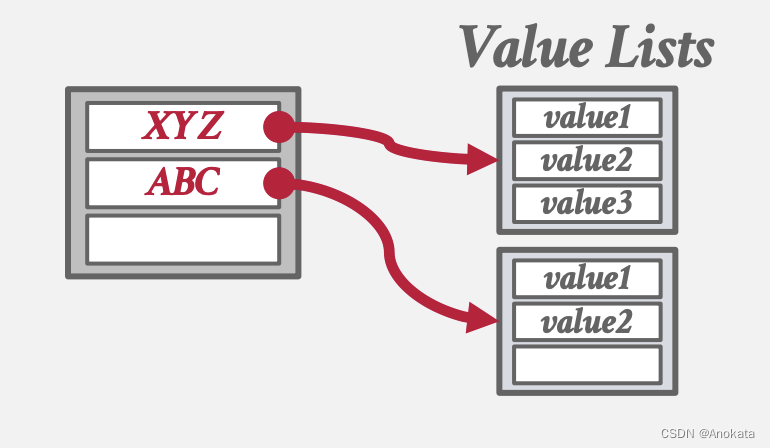
方法 1 单独的链表【Separate Linked List】
- 将每个键的值存储在单独的存储区域中,比如一个链表中。
- 但是,如果重复项数量较多,值的列表可能会溢出到多个页【page】上。
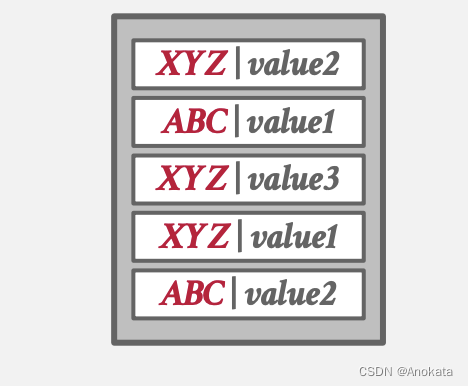
方法 2 冗余键【Redundant Keys】
- 将重复的键【keys】的条目【entries】一起存储在哈希表中。但是删除时,需要key+value u一起来定位删除哪一个元素
- 这是大多数系统所做的。
优化点
- 基于键的类型和大小的专用哈希表实现,比如当哈希的键【key】是字符串时,字符串可以是几个字节,也可能是几兆的,此时我们可能只是想在数组中存储到该字符串的指针,而不是将字符串存储在插槽中
- 将元数据(比如墓碑,比如null,比如空等)信息存储到一个单独的数组中,比如通过压缩位图,来记录某个插槽时墓碑还是null等信息。
- 使用表版本【table】+槽版本【slot versioning】控制元数据快速使哈希表中的所有条目失效。因为一次性分配内存的代价是比较大的,我们希望可以重复利用创建的数组,为此我们为表和插槽增加了版本元数据,当插槽的版本低于表版本时,我们可以认为任何东西已经被删除了,我们可以忽略在这里看到任何东西。
3.3.2 布谷鸟哈希【CUCKOO HASHING】
布谷鸟哈希使用多个哈希函数,以在哈希表中查找多个位置来插入记录。
- 插入时,检查多个位置,并选择空的位置。
- 如果没有可用的位置,则从其中之一驱逐该元素,然后重新散列它以找到新的位置。
查找和删除始终为 O(1),因为无论我们有多少个哈希函数,我们只知道,在每次计算后,我们就知道要去哈希表中的某个位置。
栗子:
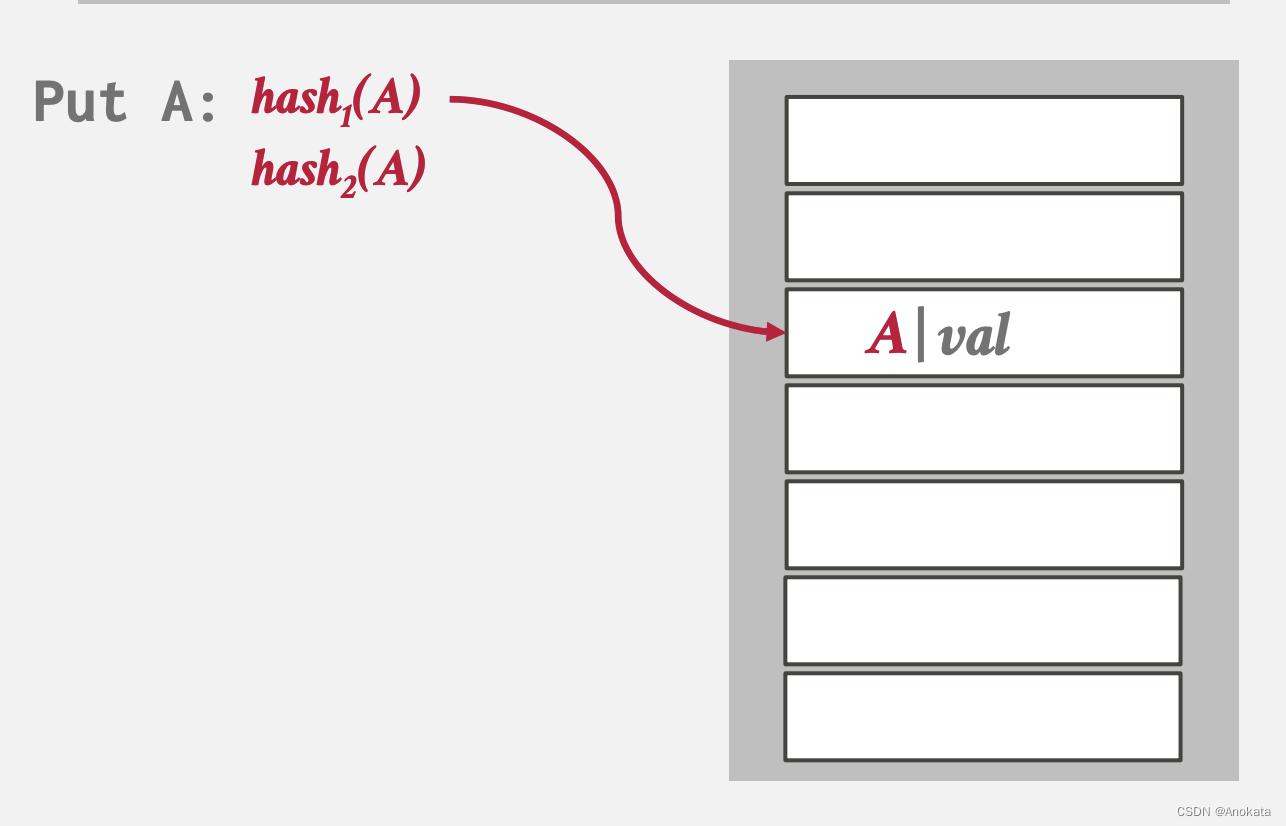
1️⃣ 当我们插入元素A时,根据hash函数计算,我们可以得到两个候选槽位
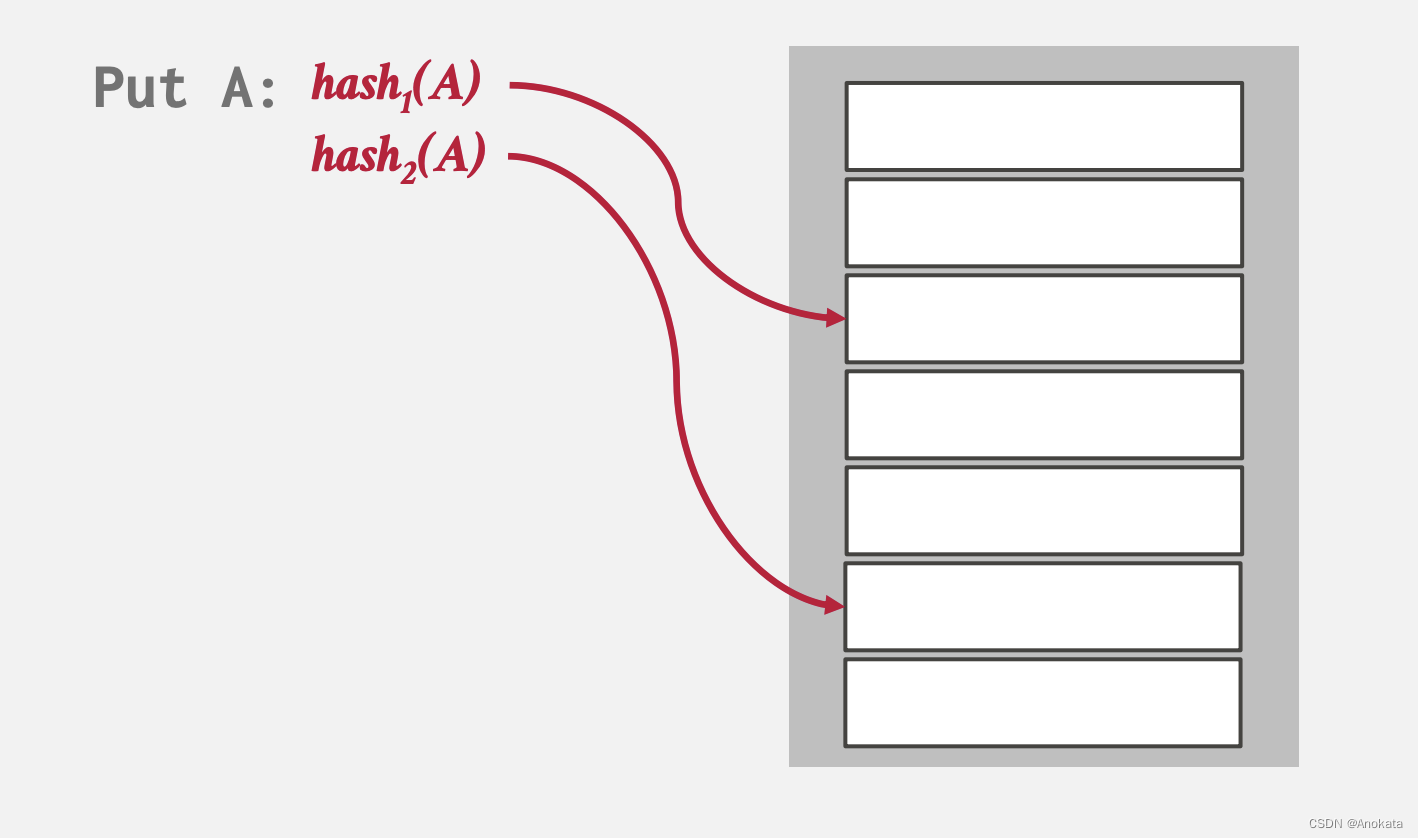
2️⃣ 这时候我们可以任意选择一个位置,假设我们选择第一个位置:
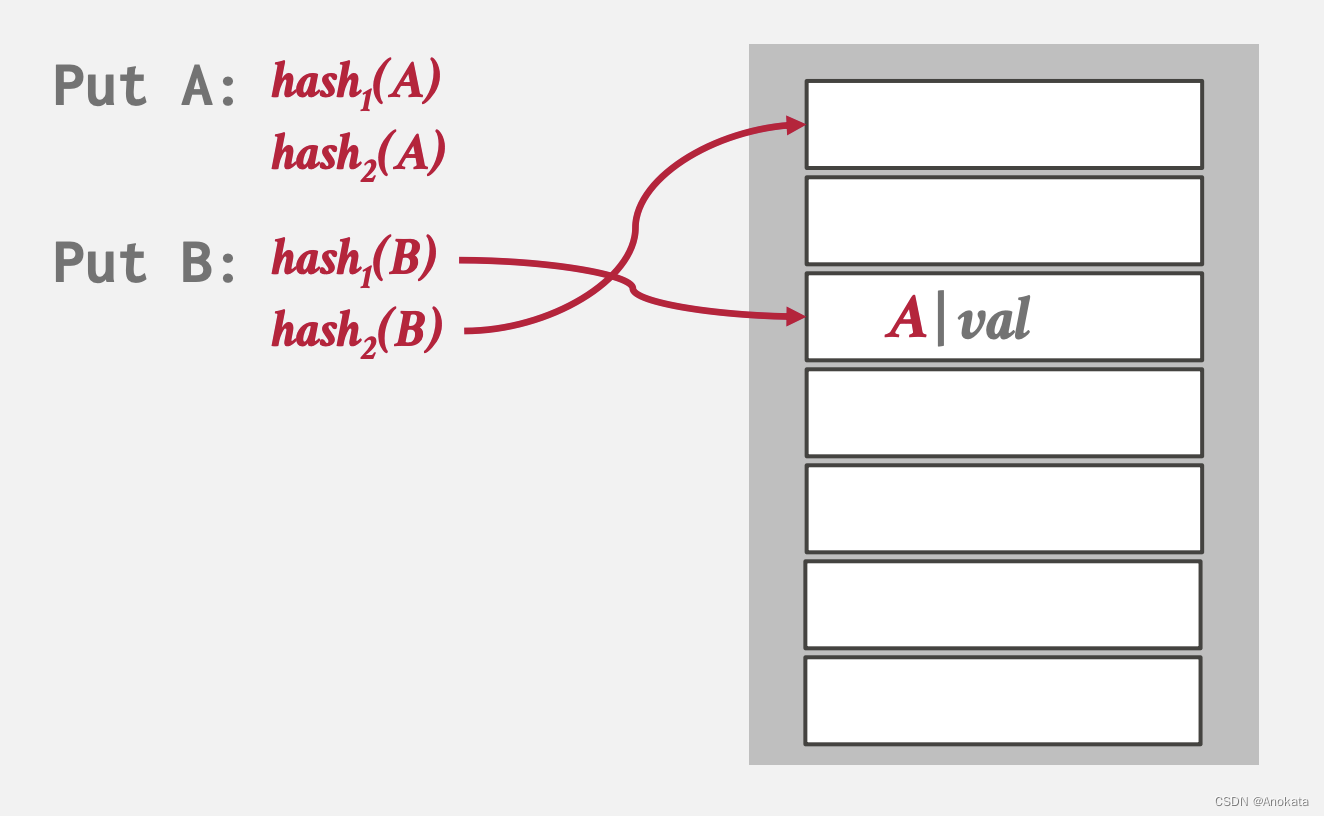
3️⃣ 然后我们插入元素B,经过哈希计算后,其中有一个位置与元素A重合了
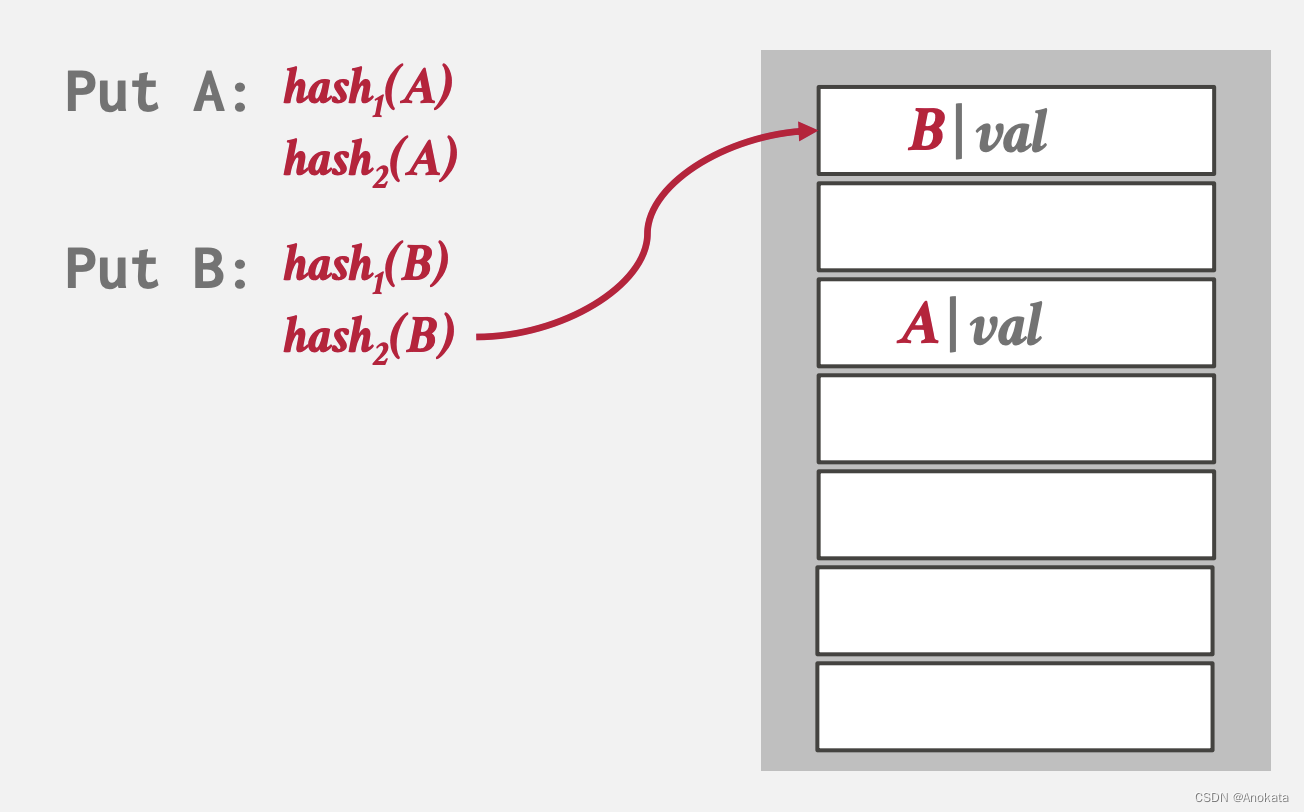
4️⃣ 这时候我们选择空槽进行插入:
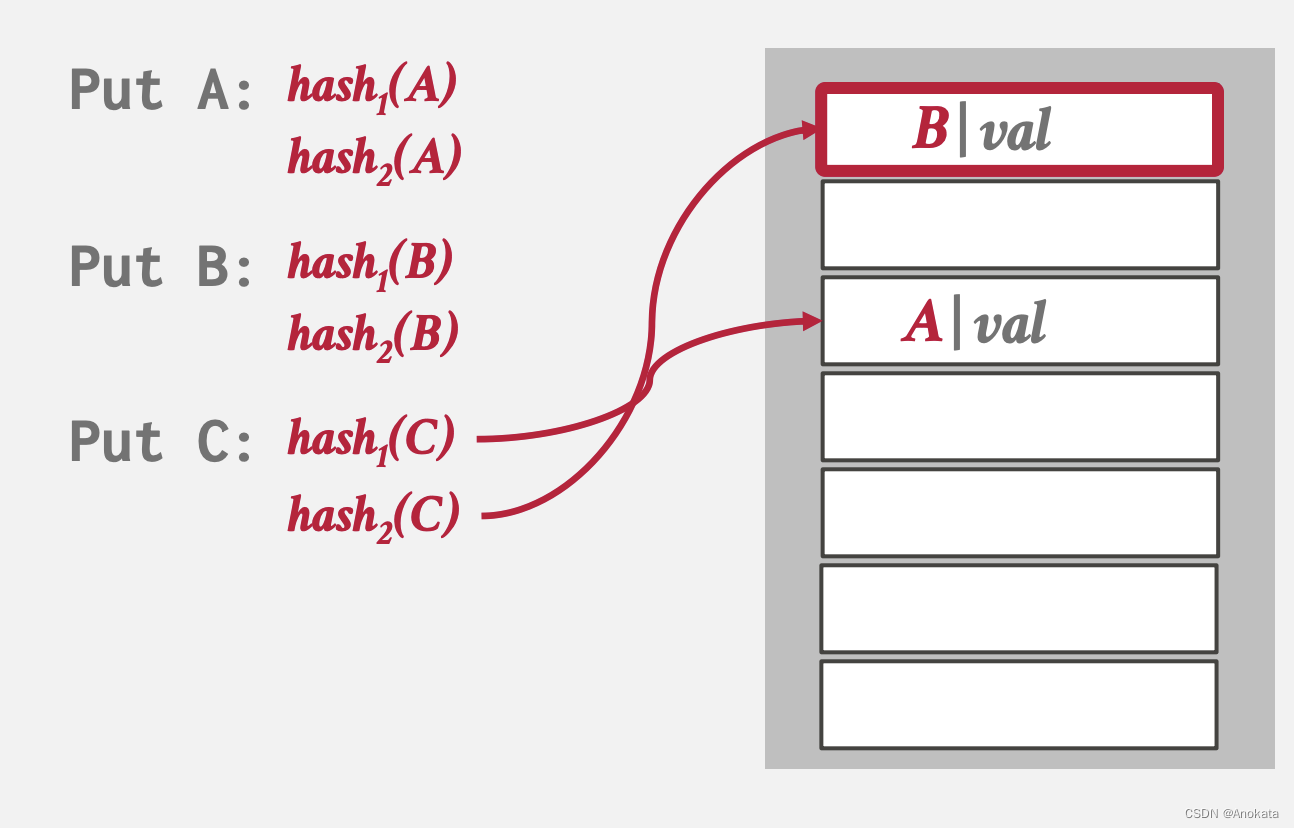
 5️⃣ 当插入元素C时,假设哈希函数计算的槽位都被占用了
5️⃣ 当插入元素C时,假设哈希函数计算的槽位都被占用了
6️⃣ 假设我们投硬币,选择了元素B被驱逐,然后C插入了进去,然后B经过哈希计算后,将A元素驱逐,B插入了进去,然后A元素经过哈希计算后,插入到了一个新位置上
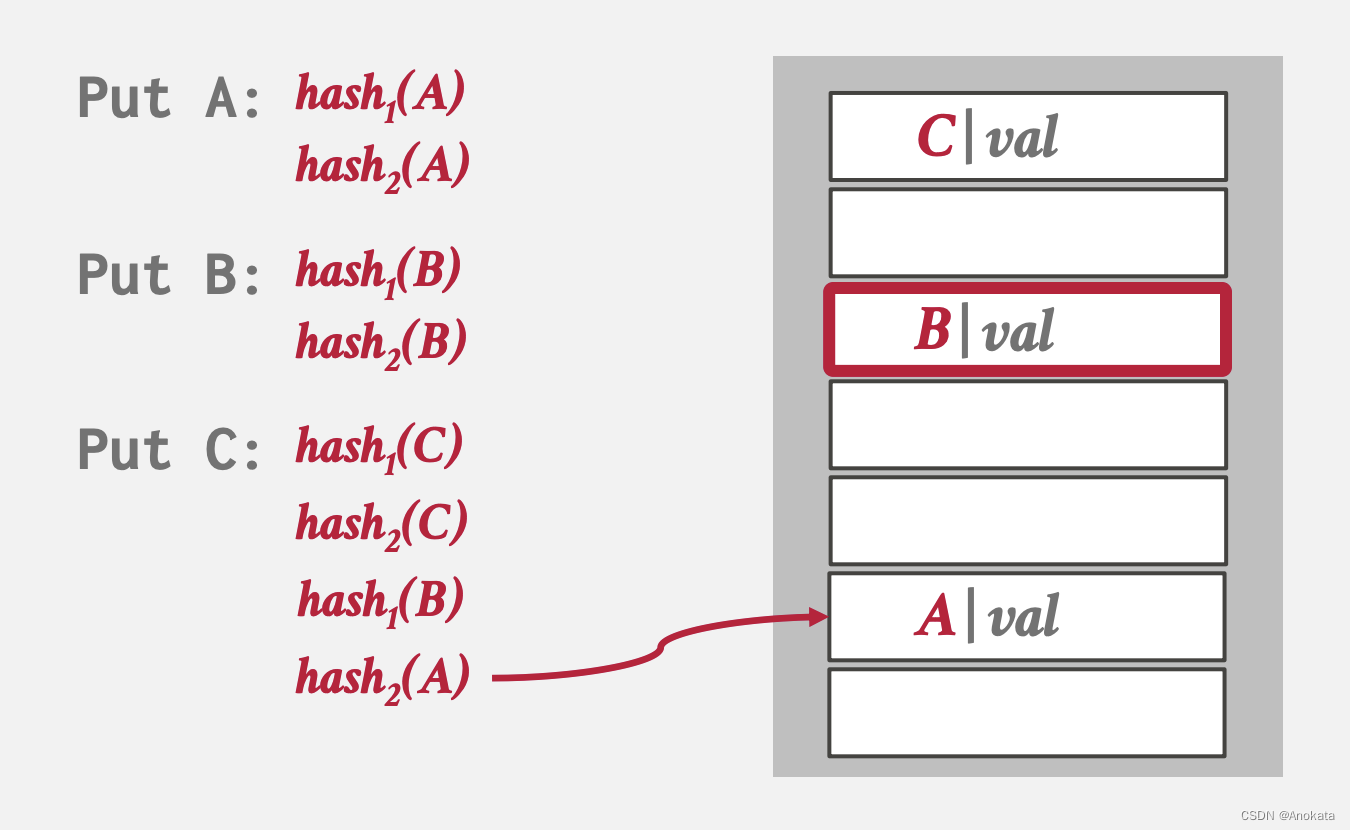 7️⃣ 当我们陷入无限循环时,即绕了一圈又回来了(你只需要跟踪我放进去的键和我一开始放进去的键是否时一样的),那这时候就需要将哈希数组扩容并进行rehash
7️⃣ 当我们陷入无限循环时,即绕了一圈又回来了(你只需要跟踪我放进去的键和我一开始放进去的键是否时一样的),那这时候就需要将哈希数组扩容并进行rehash
8️⃣ 当我们查询元素B时,只需要重新计算哈希函数,然后进行key检查,就可以找打到元素
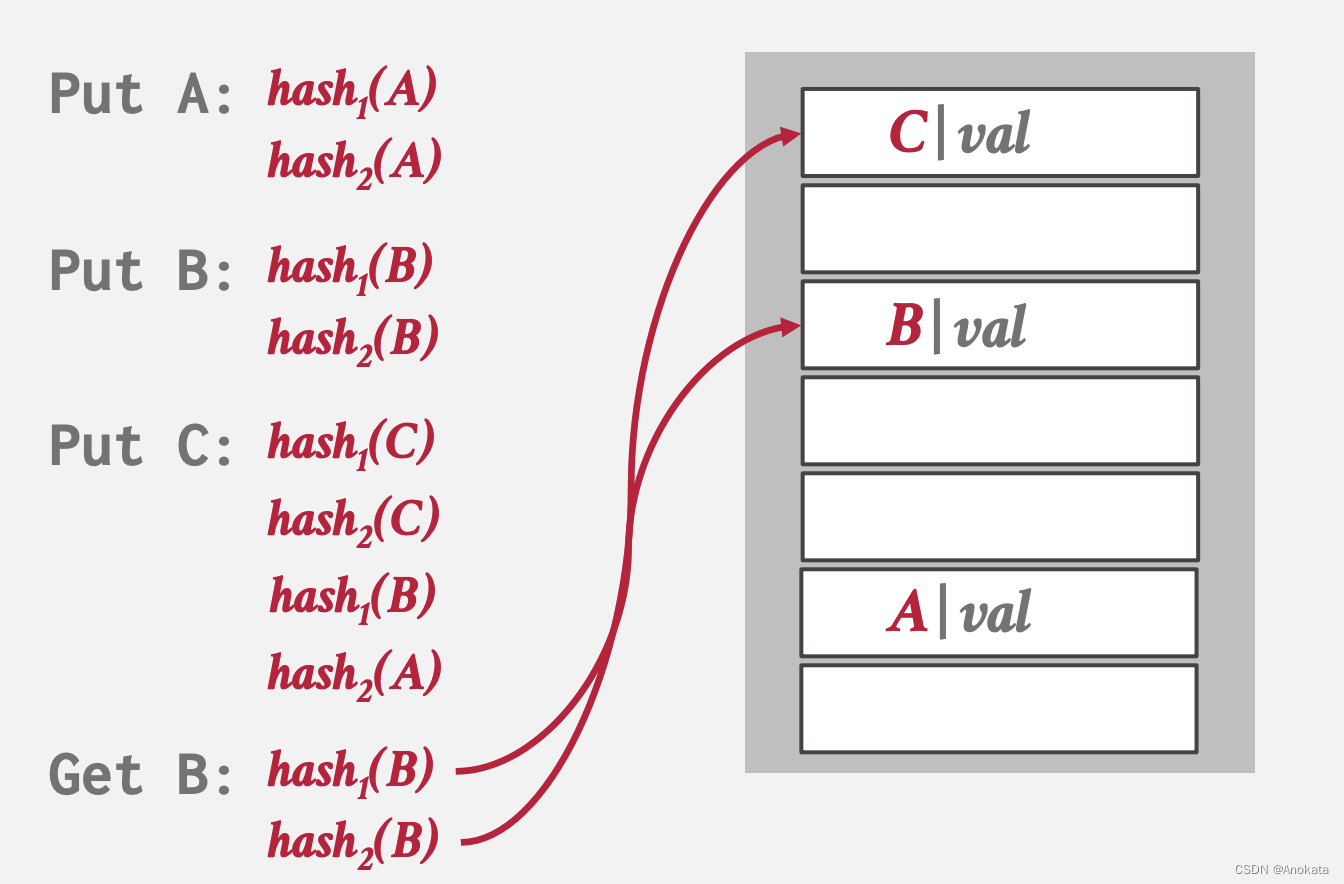
3.4 动态哈希方案【dynamic hash schema】
前面讲到的的哈希表要求 DBMS 知道它想要存储的元素的数量,否则,如果需要增加/缩小表的大小,则必须重建表。
动态哈希表根据需要逐渐调整自身大小。
- 链式哈希【Chained Hashing】
- 可扩展散列【Extendible Hashing】
- 线性哈希【Linear Hashing】
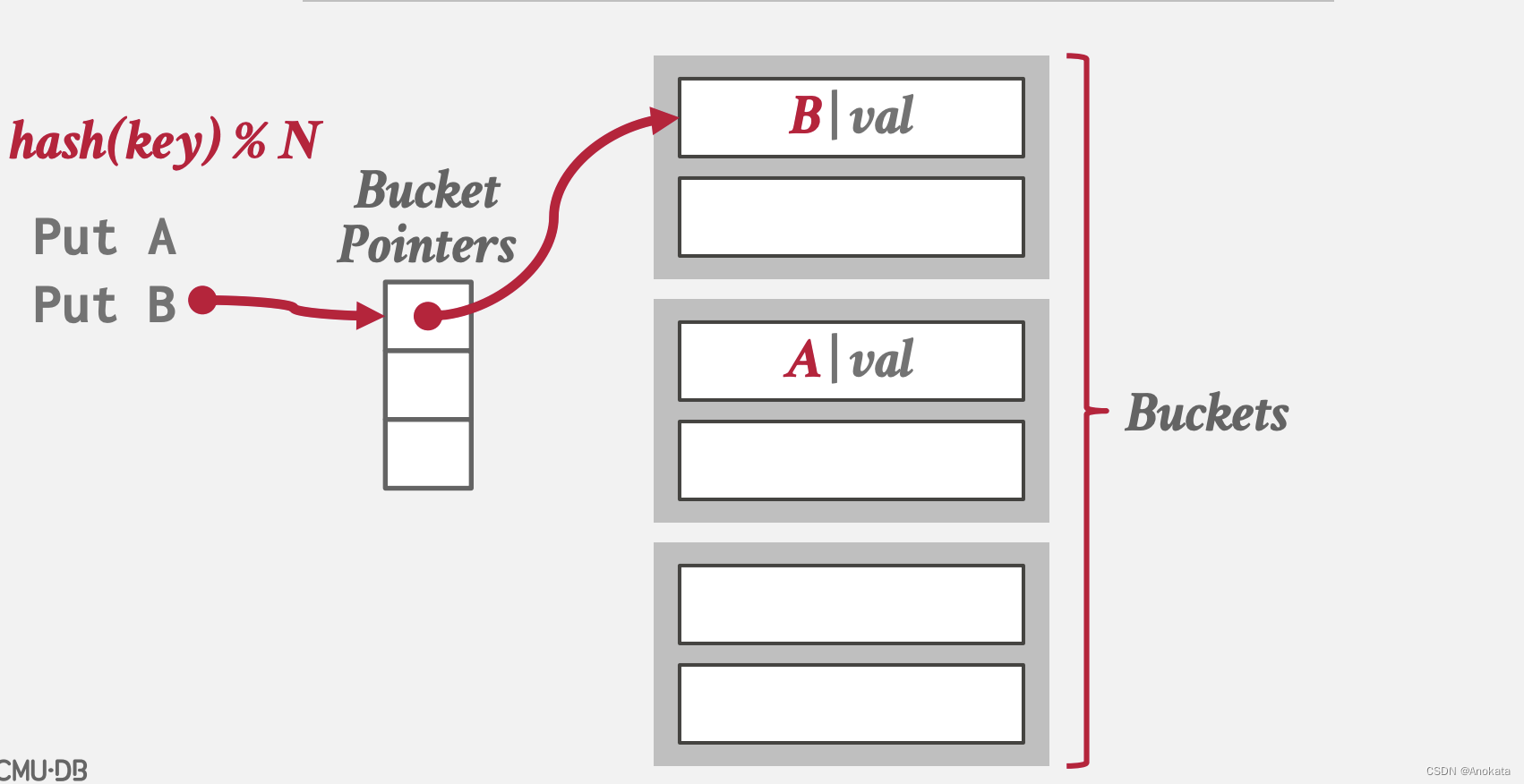
3.4.1 链式哈希【Chained Hashing】
为哈希表中的每个槽维护一个存储桶的链表。
通过将具有相同哈希键的所有元素放入同一个桶中来解决冲突。
- 要确定某个元素是否存在,请散列到其存储桶并扫描它
- 插入和删除是查找的一般化
栗子:
1️⃣ 简单的插入元素A,B
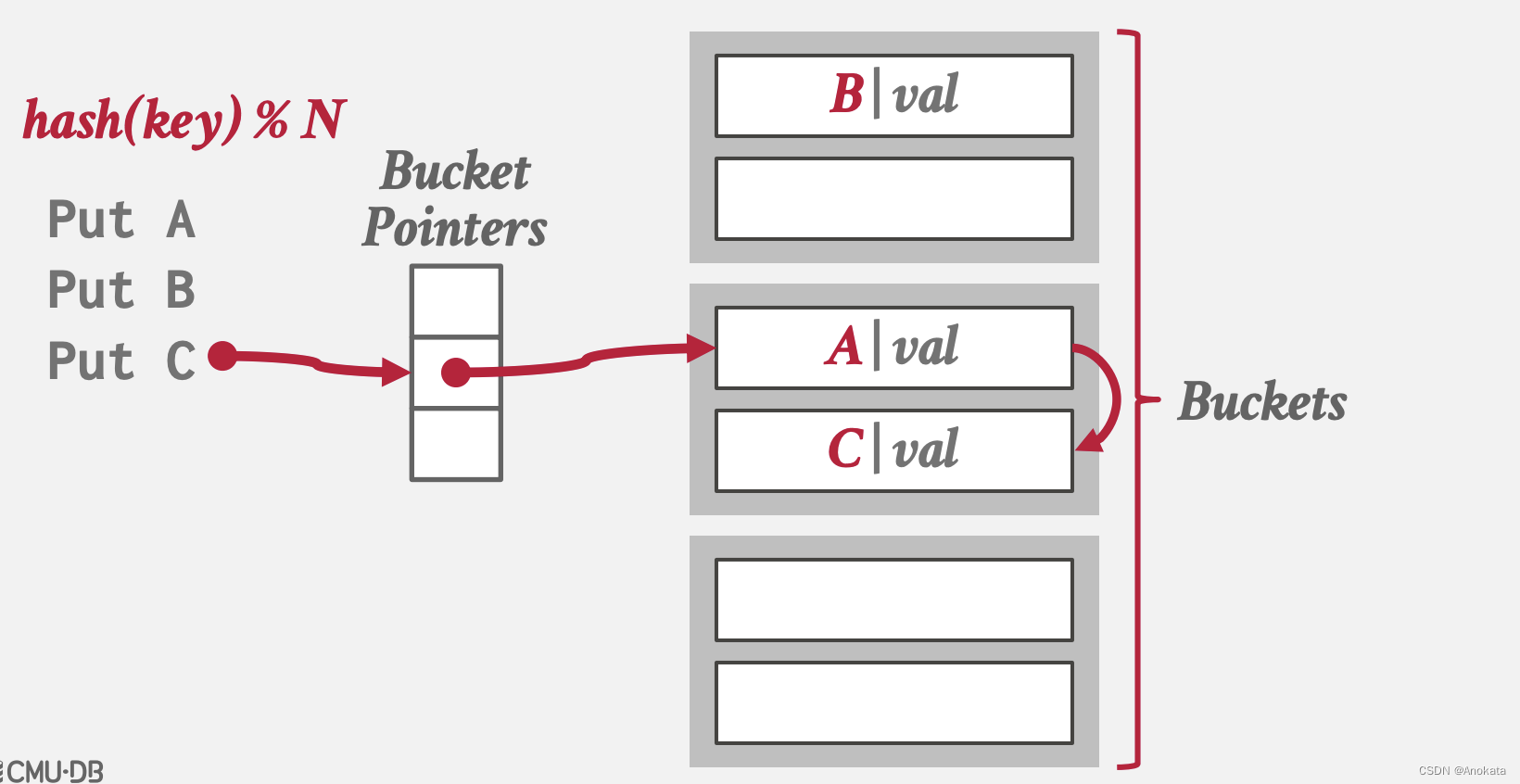
2️⃣ 当出现冲突时,通过链来解决
 3️⃣ 甚至可以在 bucket 中放入一个 bloom 过滤器,来协助我们过滤某个 key 是否在对应的链表里
3️⃣ 甚至可以在 bucket 中放入一个 bloom 过滤器,来协助我们过滤某个 key 是否在对应的链表里
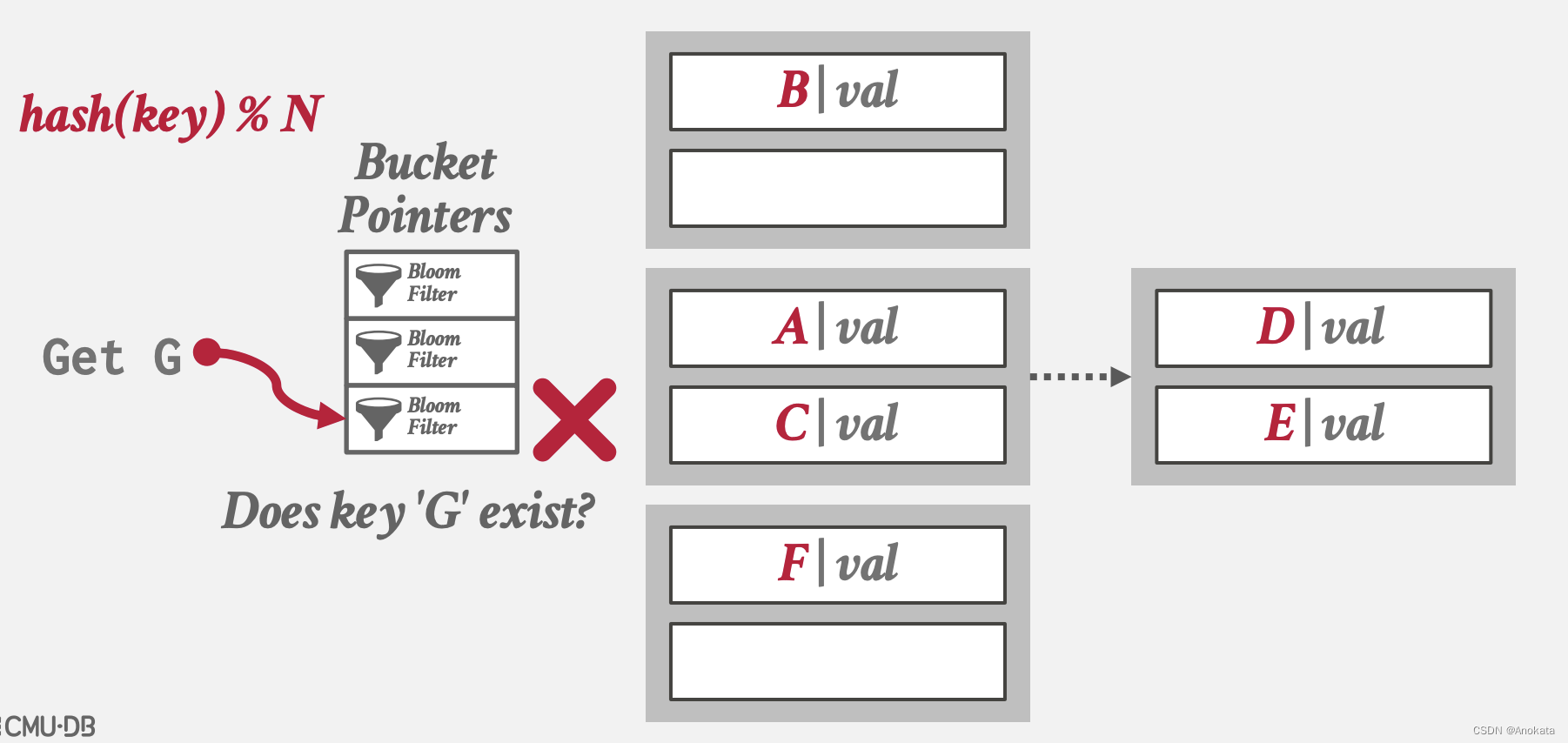
Bloom Filter
回答集合成员关系查询【Query】的概率数据结(位图)。它与索引不同,索引的目的是,给定一个 key ,它告诉你它在哪里,而 bloom 过滤器只是告诉你它会否存在。
-
假阴性永远不会发生
-
假阳性有时会发生
Insert(x) :使用 k 列函数将过滤器中的位设置为1
Lookup(x) :检查每个哈希函数结果的位是否为1
栗子:
1️⃣ 我们插入一元素时,经过哈希函数运算后,我们将其对应的位设置为 1:

2️⃣ 当我们进行查询时,就是曲检查每个哈希函数算出来的位是否全为1

3️⃣ 但是偶尔我们也会出现错误

3.4.2 可扩展散列【Extendible Hashing】
链式哈希方法逐步分割存储桶,而不是让链表永远增长。
多个槽位置可以指向同一个桶链。
在拆分时重新洗牌存储桶条目并增加要检查的位数。
→ 数据移动仅限于分割链。
栗子:
0️⃣ 首先,我们全局ID = 2,它不仅控制全局 Bucket 数组的大小,也控制哈希结果的有效位,左边的是槽点数组【Slot Point Array】,右边的是桶列表【Buckect List】,顶部两个槽位指向最顶上的桶数组,而下面的两个槽则分别指向不同的桶数组。
1️⃣ 数据查询A时,我们根据哈希结果的高位,哦判断出它们位于本地 1
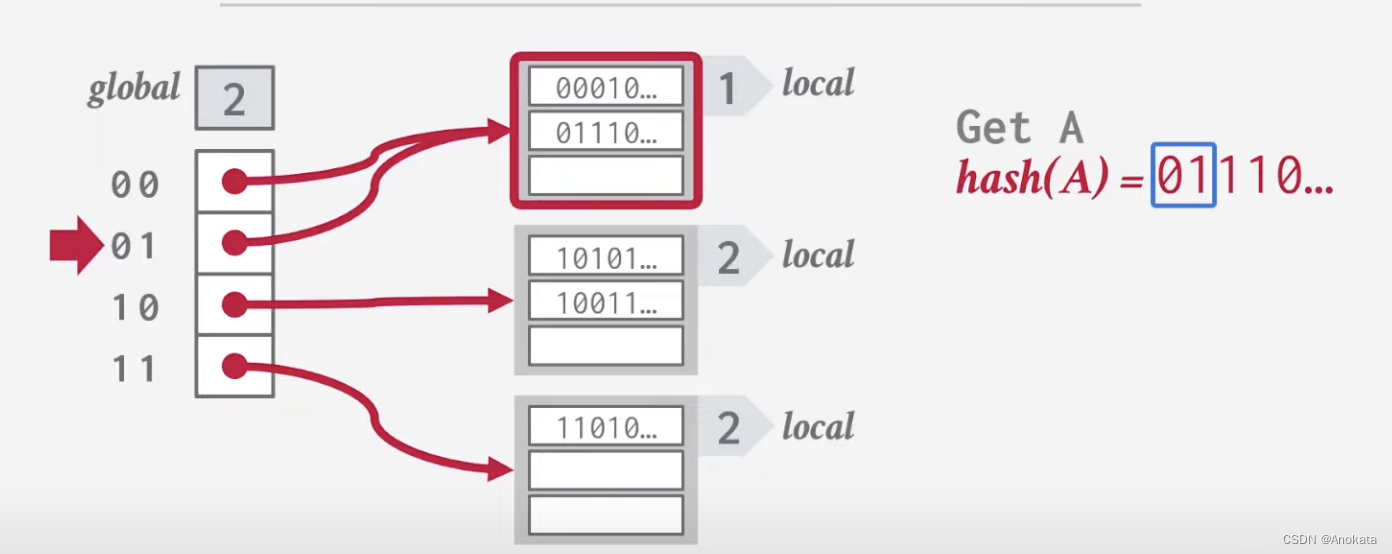
2️⃣ 当数据插入B时,根据哈希结果高位,我们将其置于本地 2 中
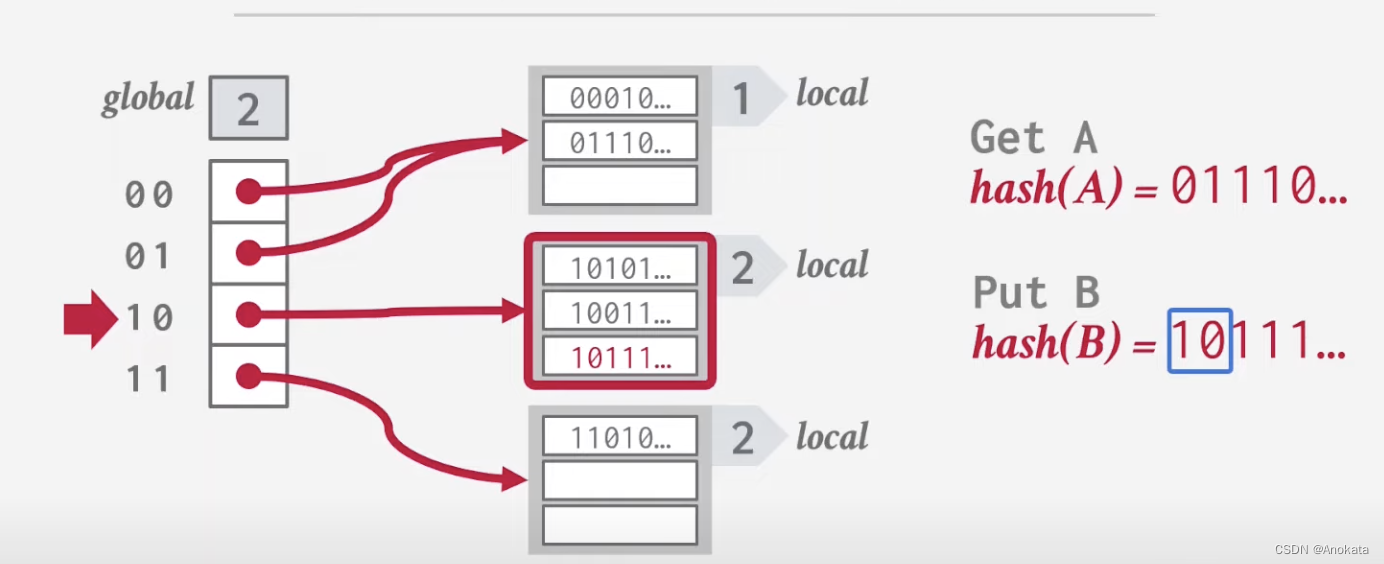
3️⃣ 当我们插入元素C时,它与元素B碰撞到相同的本地桶列表中,而这时候,该桶列表已经满了,
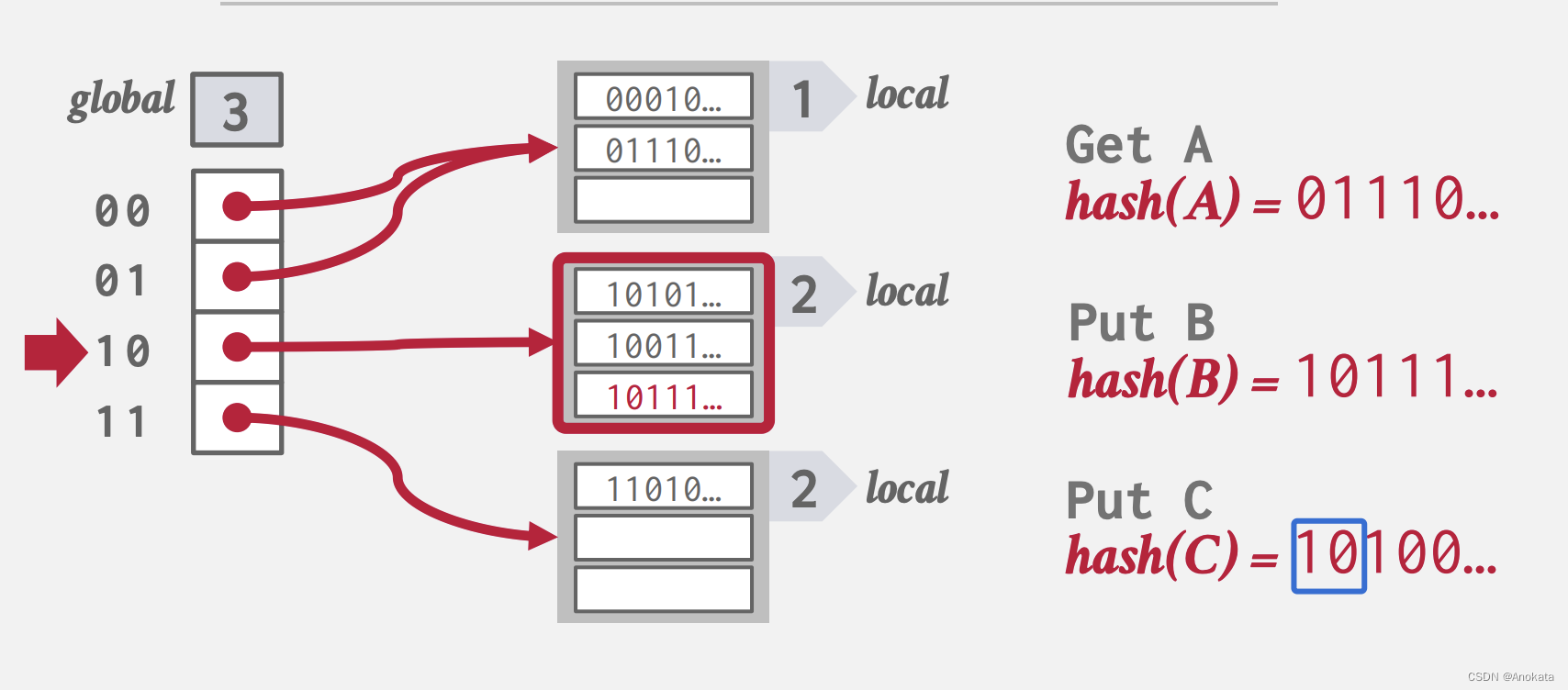
这时候我们需要将全局 ID 从 2 增加到 3
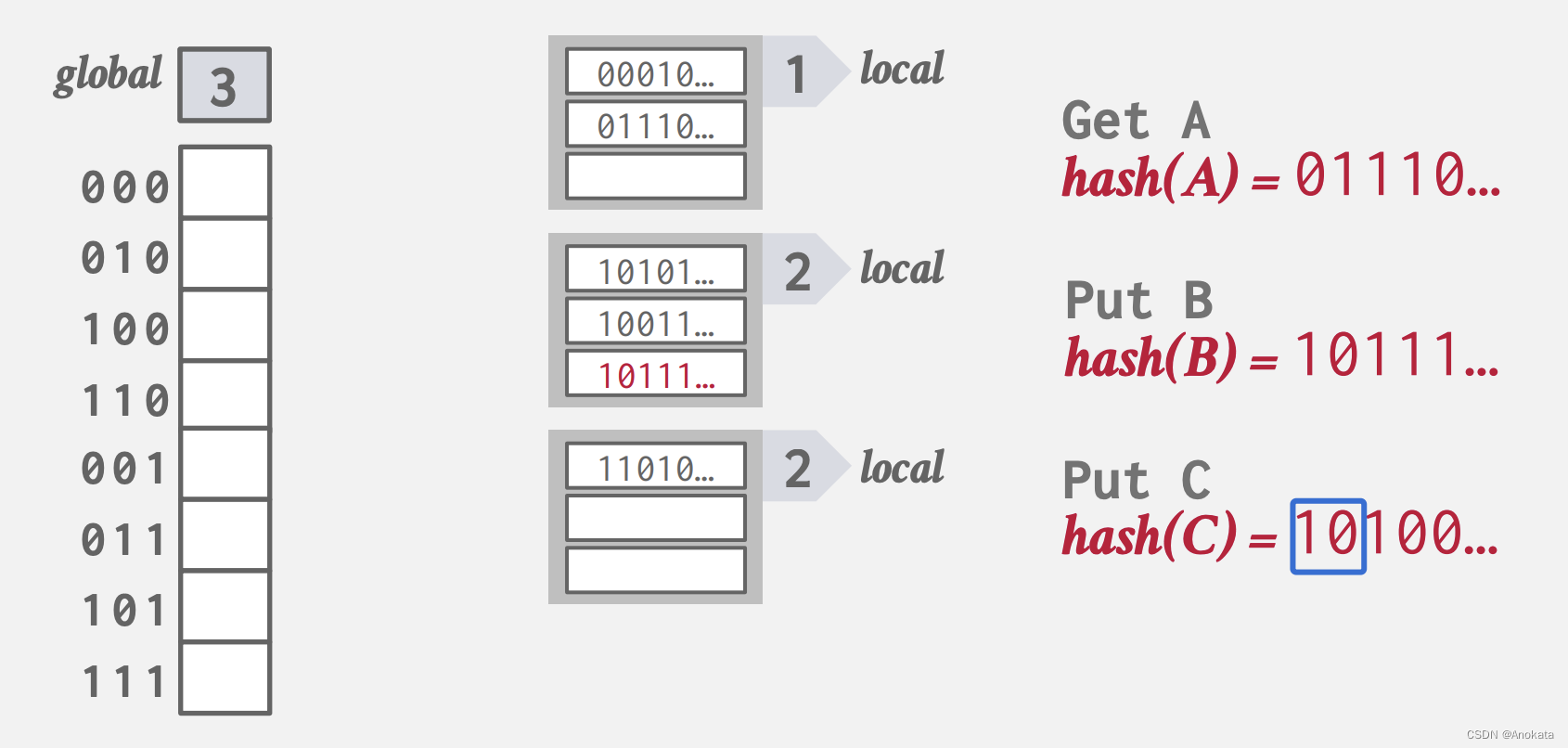
并将原来已经满了的本地桶列表的本地 ID 从 2 增加到 3 ,并拆为两个本地 ID = 3 的桶列表,而其他没有满的本地桶列表继续保持。

然后我们就可以将C插入到对应的桶列表中了
 3.4.3 线性哈希【Linear Hashing】
3.4.3 线性哈希【Linear Hashing】
哈希表维护一个指针,用于跟踪下一个要拆分的桶。
- 当任何桶溢出时,在指针位置分裂桶。
使用多个哈希来查找给定键所在的正确存储桶。
可以使用不同的溢出标准:
- 空间利用【Space Utilization】
- 溢出链的平均长度【Average Length of Overflow Chains】
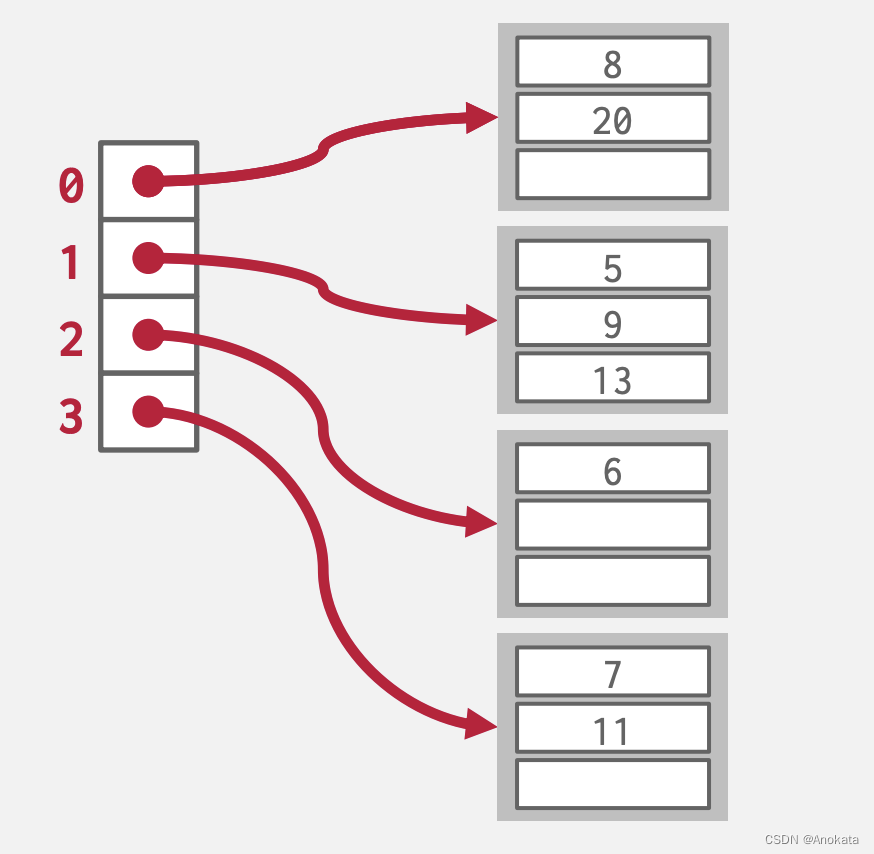
栗子:
1️⃣ 假设我们的桶列表现在长这样
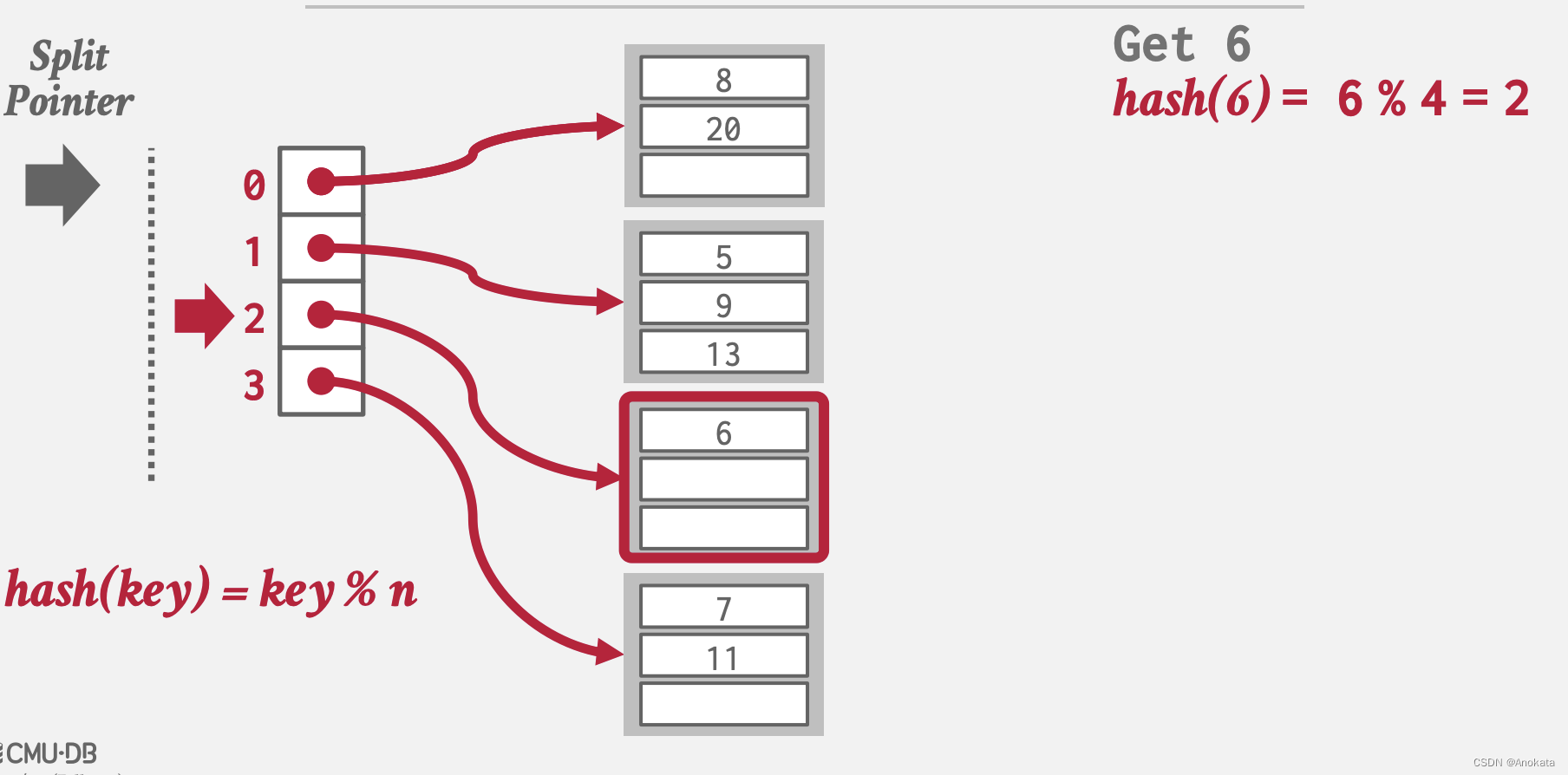
2️⃣ 当我们查询元素时,只需要哈希计算后找打到对应的 桶列表,在内部做扫描查询即可
3️⃣ 当我们插入元素时,而该元素哈希结果所在的桶列表满了,
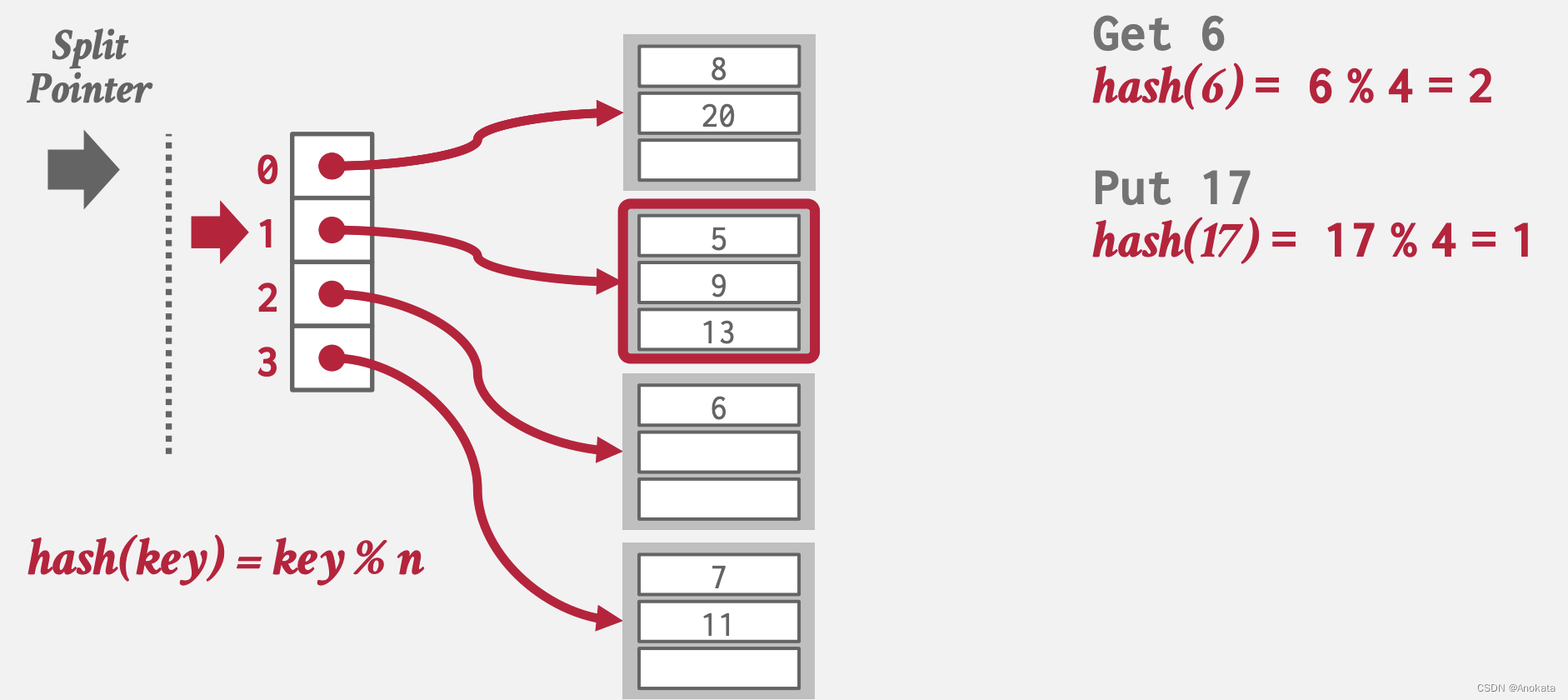
对于此,我们要做一个溢出:
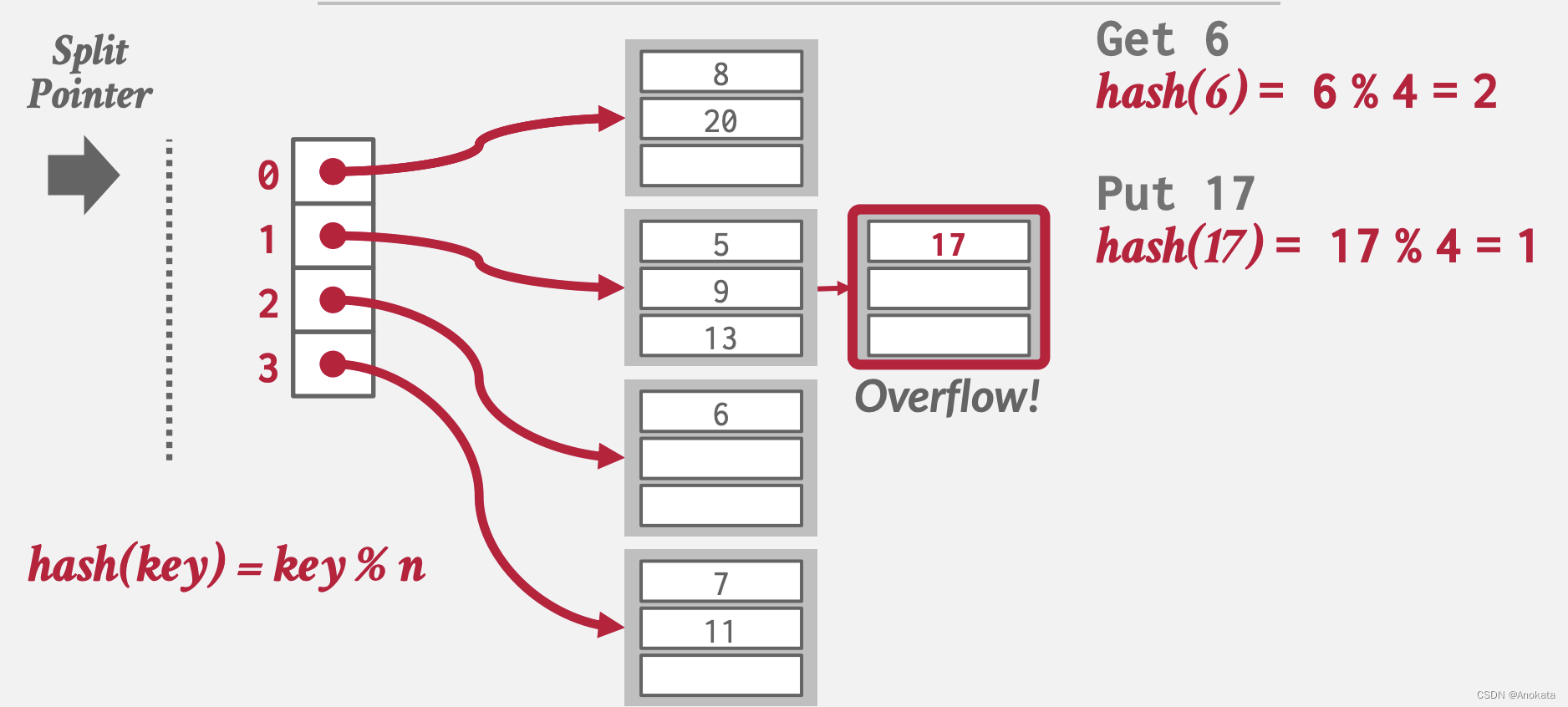
4️⃣ 现在,因为我们碰到溢出了,因此我们需要拆分,此时Split Pointer指向插槽 0 ,我们需要新增一个新的槽位 4,并需要将元素8和元素20进行rehash,且取模的因子也从 N 变成了 2N
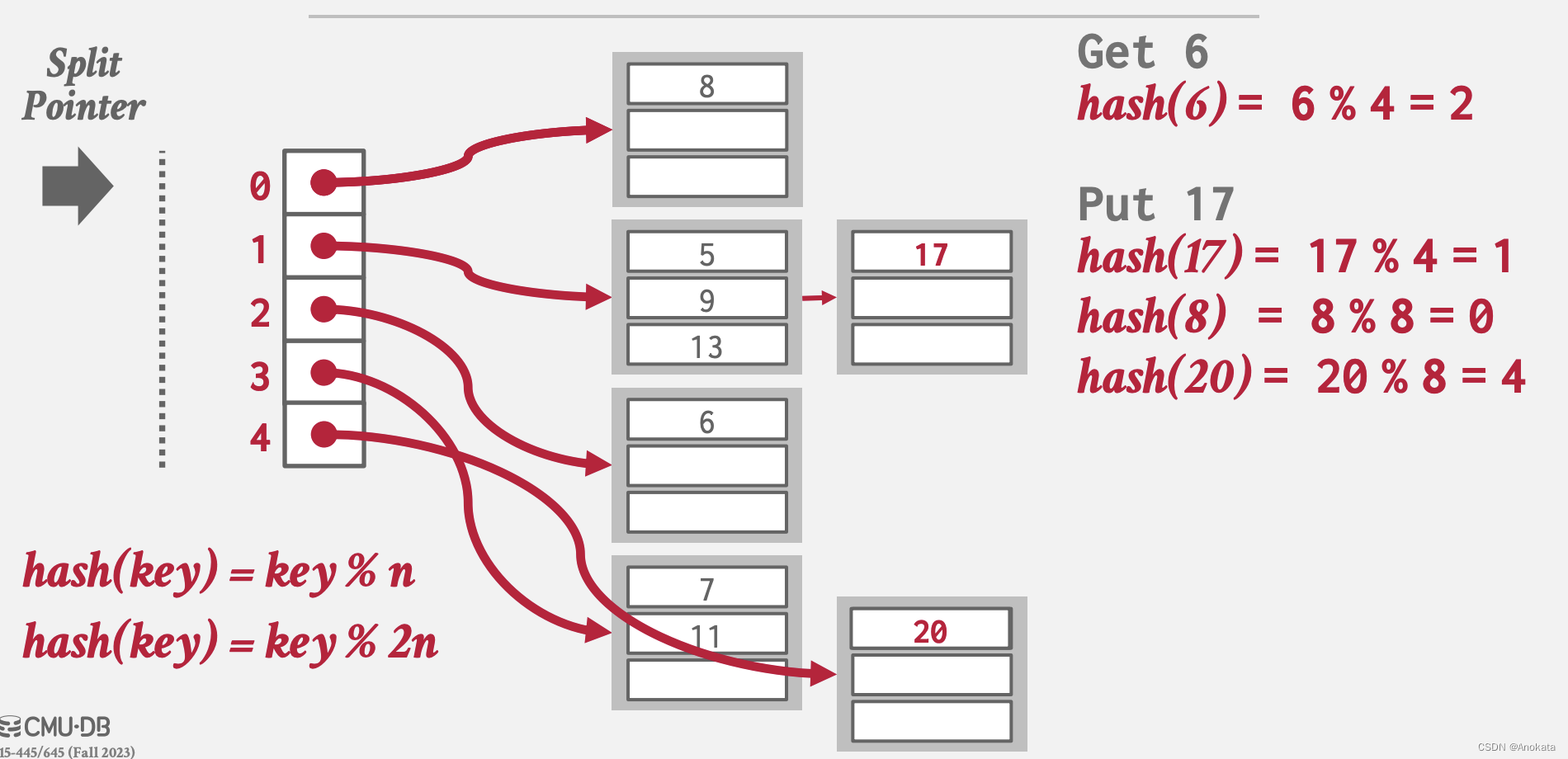
5️⃣ 接下来,拆分指针继续向下移动,但是此时不拆分
6️⃣ 我们查询元素20,因为其对应的原始插槽被拆分过,所以他需要计算两次哈希,兵最终找打到插槽4
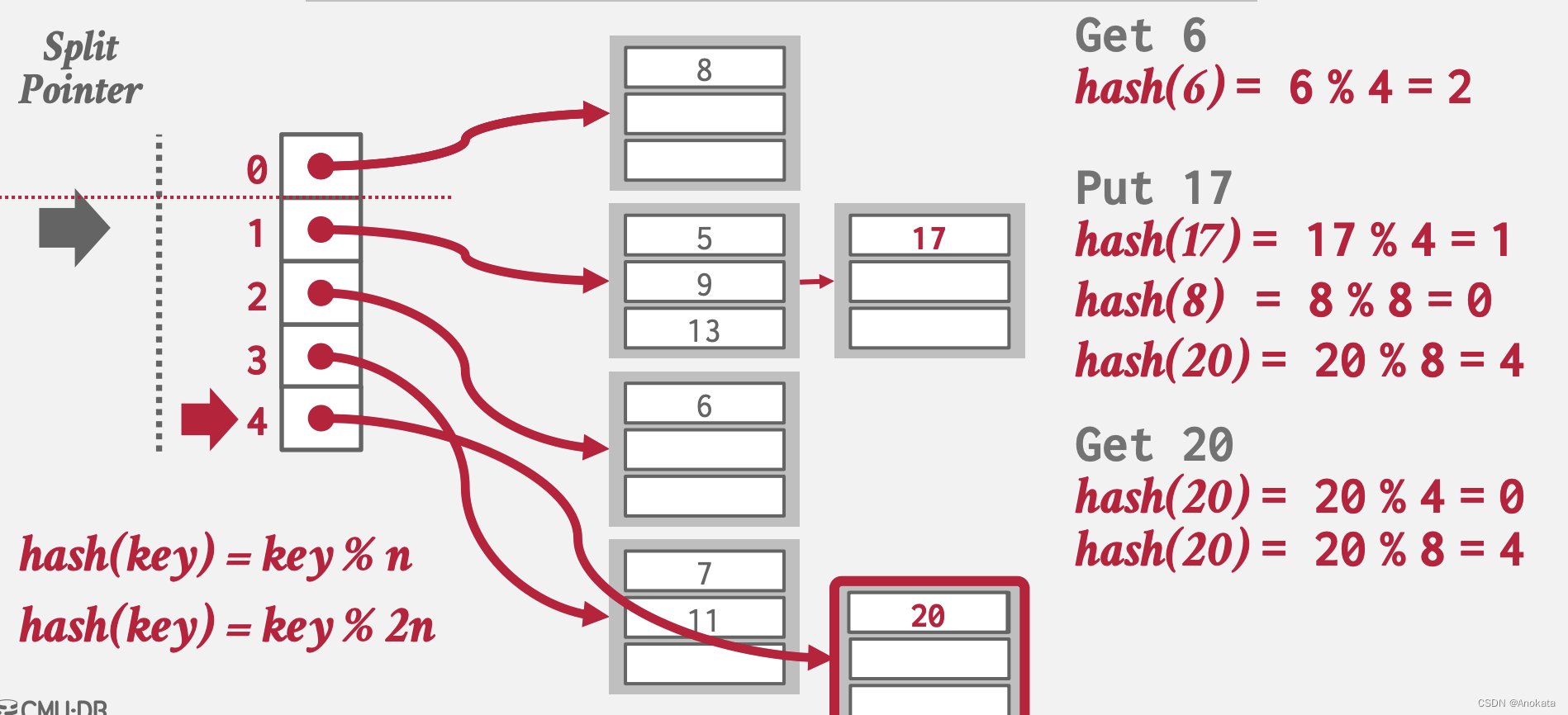 7️⃣ 我们继续查询元素9,通过哈希函数计算的到它在插槽1 ,而且当前拆分指针停留在插槽1处,因此它还没有被拆分,我们可以在插槽1对应的桶列表中查到元素
7️⃣ 我们继续查询元素9,通过哈希函数计算的到它在插槽1 ,而且当前拆分指针停留在插槽1处,因此它还没有被拆分,我们可以在插槽1对应的桶列表中查到元素
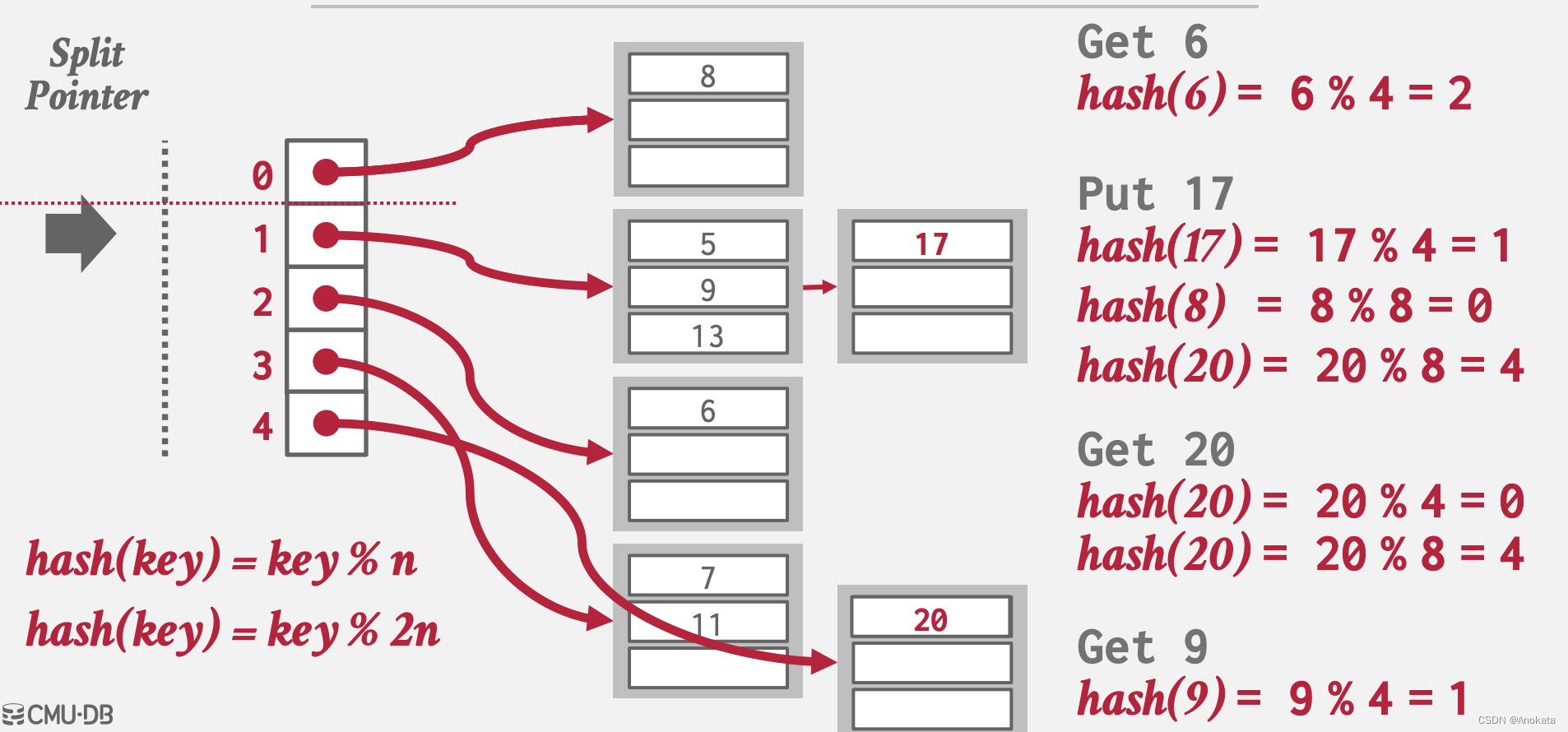
8️⃣ 最终,拆分指针会到最底部,这也预示着我们的插槽也变成了8个
根据拆分指针对桶进行拆分,最终会到达所有溢出的桶,当指针到达最后一个槽时,删除第一个哈希函数并将指针移回到开头。
如果拆分指针下方的“最大”的桶为空,则哈希表可以将其删除,并沿相反方向移动拆分指针。
栗子:
1️⃣ 当我们打算删除元素20时,此时拆分指针位于插槽1处
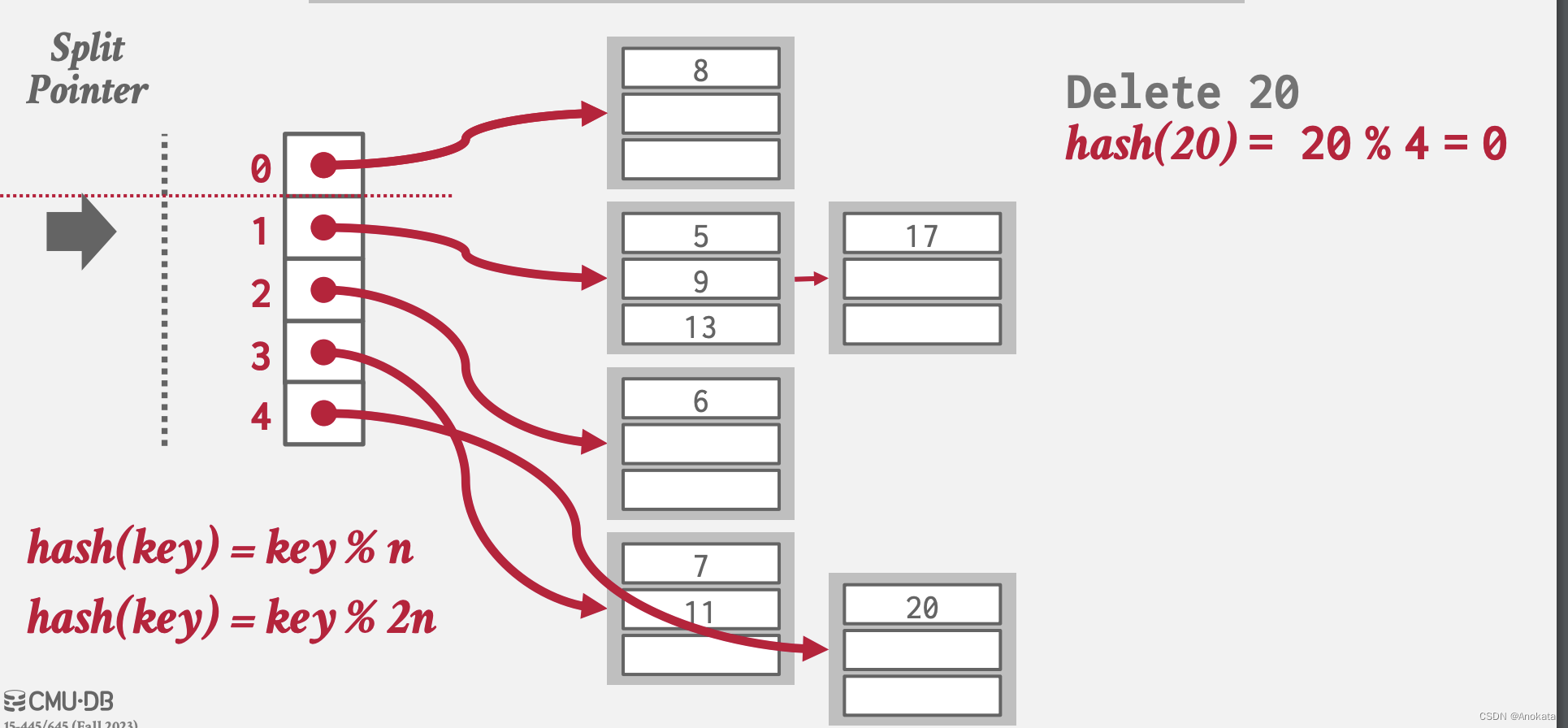
2️⃣ 通过计算我们的到它位于插槽4,然后我们删除该元素,这时候桶数组为空,我们需要删除最大的插槽及其桶数组,并将拆分枝上向上移动:
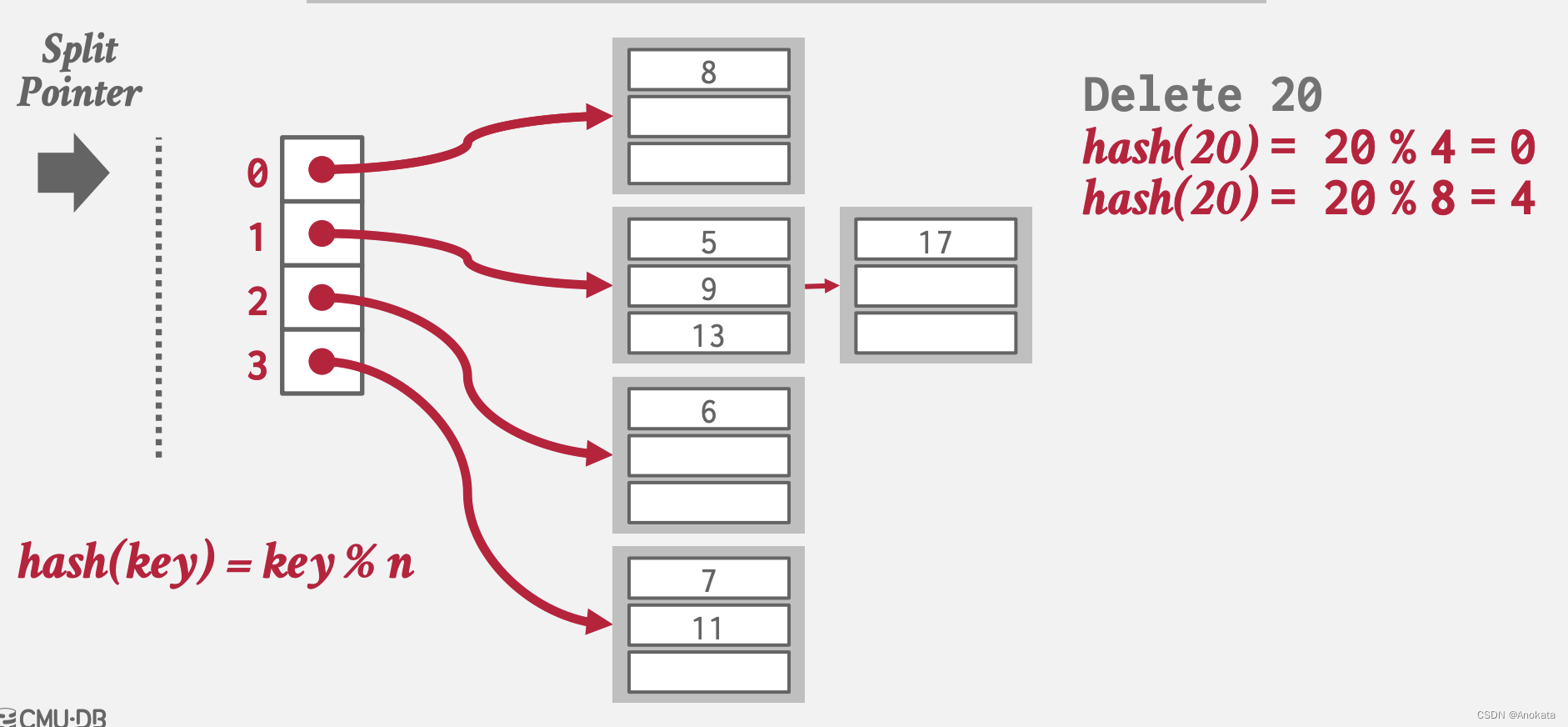
3.4 结论
哈希表是支持 O(1) 查找的快速数据结构,它在整个 DBMS 内部都有使用
- 速度和灵活性之间的权衡
但是哈希表通常不是会用于表的索引!!!!















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









