







神经网络和深度学习
- 神经网络:一种可以通过观测数据使计算机学习的仿生语言范例
深度学习:一组强大的神经网络学习技术
神经网络和深度学习目前提供了针对图像识别,语音识别和自然语言处理领域诸多问题的最佳解决方案。传统的编程方法中,我们告诉计算机如何去做,将大问题划分为许多小问题,精确地定义了计算机很容易执行的任务。而神经网络不需要我们告诉计算机如何处理问题,而是通过从观测数据中学习,计算出他自己的解决方案。自动地从数据中学习看起来很有前途。然而直到2006年我们都不知道如何训练神经网络使得它比传统的方法更好,除了一些特定问题。直到2006年称为深度神经网络的学习技术被提出,这些技术现在被称为深度学习。它们得到了很好的发展,今天,深度神经网络和深度学习在计算机视觉、语音识别和自然语言处理等许多重要问题上取得了出色的表现。
初识神经网络
人类的视觉系统是世界上最棒的系统之一,比如下列一串手写数字:
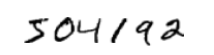
大多数人都可以一眼看出它是504192。在我们大脑的每一个半球,都有主要的视觉皮质 V1 ,它包含了1.4亿个神经元,在这些神经元之间有数百亿的接触。然而人类的视觉不仅仅包含了 V1 ,而是一系列的视觉皮质 V1,V2,V3,V4,V5 ,逐步进行更复杂的图像处理。我们大脑里有一台超级计算机,通过数亿年的进化,可以很好的适应这个视觉世界。识别手写数字并不容易,我们人类惊人地可以理解我们眼睛所看到的东西,但这些工作都是在我们不知不觉中就完成了,我们根本不知道我们大脑完成了多么负责的工作。
神经网络解决这类问题通过不一样的方式。思想是把大量的手写数字作为训练样本,然后生成一个可以通过训练样本学习的系统。换句话说,神经网络使用样本自动地推断出识别手写数字的规则。此外,通过增加训练样本的数量,该网络可以学到更多,并且更加准确。因此,当我展示下图100个训练样本时,可能我们可以通过使用成千上万甚至上亿的训练样本来建立一个更好的手写识别系统。、

该文我们将写一个程序实现一个神经网络,学习如何识别手写数字。在不使用神经网络代码库的情况下,74行代码就可以完成。但是这短短的代码识别数字的准确率超过96%。此外,后面的文章我们将可以实现准确率高达99%的方法。事实上,最好的商业神经网络现在已经很好了,银行可以用它们来处理支票,并通过邮局来识别地址。
的确,如果这篇文章只是描述如何实现一个手写数字识别的代码,那么很短的篇幅就可以讲完。但是在这个过程中,我们会讲到许多神经网络的核心思想,包括两种重要类型的神经元(感知机和sigmoid神经元),和标准的神经网络的学习算法,被称为随机梯度下降法。整篇文章我致力于解释为什么这样做,并且建立你的神经网络观念。在本文的结尾,我们将了解深度学习是什么,和为什么它很重要。
感知机
感知机是一类人造神经元,在许多神经网络中,主要的神经元模型是sigmoid神经元。我们将很快的了解什么是sigmoid神经元,但是想要知道为什么sigmoid要这么定义,就需要我们花点时间去了解感知机。
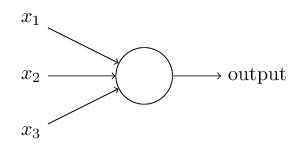
感知机如何工作?一个感知机通过一些二进制的输入 x1,x2,... ,然后产生一个二进制的输出:
在上图中,感知机有三个输入 x1,x2,x3 ,通常它可以有更多或者更少的输入。Rosenblatt提出了一个简单的规则来计算输出,它用权重 w1,w2... 来表示各个输入对输出的重要性。神经元的输出,要么是0要么是1,由权重和 ∑jwjxj 的值是否小于或者大于某一阈值。和权重一样,阈值也是一个实数,它是神经元的一个参数。用代数式表达就是:
以上就是感知机的工作原理。
这是基本的数学模型,你可以认为感知机是一种通过权衡各个因素做出决定的设备。举个例子,假设周末就要来了,你们城市有一场奶酪节,你很喜欢奶酪,你正在犹豫要不要去参加,你可能通过权衡下面三个因素来做出你的决定:
- 当天天气怎么样
- 你的男朋友或者女朋友要不要一起去
- 交通是否方便
我们可以通过对应的二进制变量 x1,
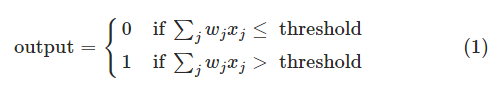
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3703
3703

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









