程序调试:gcc -Og -o p p1.c p2.c
寄存器
函数参数第1到第6个参数:%rdi %rsi %rdx %rcx %r8 %r9 返回值 %rax 栈指针 %rsp 被调用者保存 %rbx %rbp %r12 %r13 %r14 %r15 调用者保存:所有其他寄存器,除了栈指针%rsp,都分类为调用者保存寄存器 操作数格式
$lmm 立即数寻址 %rax 寄存器寻址 lmm 内存绝对寻址 (lmm) (%rax) 间接寻址 lmm(%rax) 基址+偏移量寻址 (%rax+lmm) (%rax,%rsi) 变址寻址 (%rax+%rsi) (,%rsi,s) 比例变址寻址 (s*%rsi) (%rax,%rsi,s) 比例变址寻址 (%rax+s*%rsi) 数据传输指令:mov,字节b,字w,双字l,四字q
将一个值从一个内存位置复制到另一个内存位置需要两条指令——第一条指令将源值加载到寄存器中,第二条将该寄存器值写入目的地址。 间接引用指针就是将指针放在一个寄存器中,然后在内存引用中使用这个寄存器。 栈
压栈 pushq:将栈指针减8,然后将值写到新的栈顶地址 出栈 popq:从栈顶读出数据,然后将栈指针加8 算法指令
inc 加1 dec 减1 neg 取负 not 取补 add sub imul div 加减乘除 xor 异或 or 或 and 与 加载有效地址(leaq):从内存读取数据到寄存器,但是不引用内存。它的第一个操作数看上去是内存引用,但是该指令并不是从指定的位置读入数据,而是将有效地址写入到目的操作数。 long scale(long x,long y,long z){
long t = x + 4 *y + 12 *z;
return t;
}
// 汇编代码 x rdi ; y rsi; z rdx
scale:
leaq (%rdi,%rsi,4), %rax ; rax=x + 4*y
leaq (%rdx,%rdx,2), %rdx ; rdx=3*z
leaq (%rax,%rdx,4), %rax ; rax=x+4*y + 4*(3*z)
移位操作:sal(shl) 左移;sar 算术右移(填符号位),shr 逻辑右移(填0)
移位量可以是一个立即数,也可以放在单字节寄存器%cl中(只允许这个%cl寄存器) 移位操作对w位长的数据值进行操作,移位量由%cl寄存器的低m位决定,这里2m=w。当%cl=0xFF,对于salb,2 3=8,所以会左移7位,salw会移15位,sall会移31位,而salq会移63位 乘法:
imulq %rdx, %rsi;有符号乘法生成64位,高位溢出丢掉 全乘法:要求一个参数必须在寄存器%rax中,而另一个作为指令的源操作数给出。然后乘积存放在寄存器%rdx(高64位)和%rax(低64位中)。
// mul.c
// cc mul.c -O2 -S
#include <inttypes.h>
typedef unsigned __int128 uint128_t;
typedef __int128 int128_t;
void store_uprod(uint128_t *dest,uint64_t x,uint64_t y){
*dest = x * (uint128_t) y;
}
void store_uprod2(int128_t *dest,int64_t x,int64_t y){
*dest = x * (int128_t)y;
}
store_uprod:
movq %rsi, %rax
mulq %rdx
movq %rax, (%rdi) ;存储低8字节在目的地 小端序机器
movq %rdx, 8(%rdi) ;存储高8字节在目的地+8
ret
store_uprod2:
movq %rsi, %rax
imulq %rdx
movq %rax, (%rdi)
movq %rdx, 8(%rdi)
ret
除法:
有符号除法指令idivq将寄存器%rdx(高64位)和%rax(低64位)中的128位作为被除数,而除数作为指令的操作数给出,指令将商存储在寄存器%rax,将余数存储在寄存器%rdx中。 无符号除法指令idivq将寄存器%rdx(高64位,置为0)和%rax(低64位)中的128位作为被除数,而除数作为指令的操作数给出,指令将商存储在寄存器%rax,将余数存储在寄存器%rdx中。 void remdiv(long x,long y,long *qp,long *rp){
long q=x/y;
long r=x%y;
*qp = q;
*rp = r;
}
void remdiv2(unsigned long x,unsigned long y,unsigned long *qp,unsigned long *rp){
long q=x/y;
long r=x%y;
*qp = q;
*rp = r;
}
// x rdi,y rsi,qp rdx,rp rcx
remdiv:
movq %rdi, %rax ; x低8字节存储在%rax
movq %rdx, %r8 ; qp地址存储在r8
cqto ; 符号扩展%rdx为全0或全1
idivq %rsi ; 除法 y
movq %rax, (%r8) ; 商存储在*qp
movq %rdx, (%rcx) ; 余数存储在*rp
ret
remdiv2:
movq %rdx, %r8
movq %rdi, %rax
xorl %edx, %edx ; 将%rdx置为0
divq %rsi
movq %rax, (%r8)
movq %rdx, (%rcx)
ret
条件码
CF:进位标志。最近的操作使最高位产生了进位。用来检查无符号操作的溢出 ZF:零标志。最近的操作得出的结果为0 SF:符号标志。最近的操作得到的结果为负数。 OF:溢出标志。最近的操作导致一个补码溢出——正溢出或负溢出 CMP指令根据两个操作数之差来设置条件码,不会修改目的操作数。CMP S1,S2 ;S2-S1 TEST指令根据两个操作数AND来设置条件码,不会修改目的操作数。TEST S1,S2 ; S1&S2
testq %rax,%rax 用来检查%rax是负数、零,还是正数 根据条件码的某种组合,将一个字节设置为0或者1.
sete 相等或零设置为1 setne 不相等或非零设置为1 sets 负数设置为0 setns setg setge setl setle:有符号大于 大于等于 小于 小于等于 seta setae setb setbe:超过(无符号>) 超过或等于 低于 低于或等于 int comp(int a,int b){
return a<b;
}
// a in %rdi ,b in %rsi
comp:
cmpl %esi, %edi
setl %al
movzbl %al, %eax
int test(long a){
return a>=0;
}
// a in %rdi
comp:
testq %rdi, %rdi
setge %al
movzbl %al, %eax
跳转指令:jmp Label 使用控制的条件转移。但条件满足的时,程序沿着一条执行路径执行,而当条件不满足时,就走另一条路径。
无条件跳转:jmp
直接跳转:跳转目标是作为指令的一部分编码的。jmp Label 间接跳转:跳转目标是从寄存器或内存位置中读出的。jmp *Operand 有条件跳转:只能是直接跳转
相等与不相等:je(jz) jne(jnz) 负数与非负数:js jns 有符号比较:jg(jnle) jge(jnl) jl(jnge) jle(jng) 无符号比较:ja(jnbe) jae(jnb) jb(jnae) jbe(jna) rep(repz):空操作,可以忽略。因为在AMD中,当ret指令通过跳转指令到达时,处理器不能正确的处理它,所以加入rep空操作。 jmp 相对寻址,以当前jmp指令的下一条指令地址+jmp后的数字,如下objdump -d中有详细展示 // jmp.c
long lt_cnt = 0;
long ge_cnt = 0;
long absdiff_se(long x,long y){
long result;
if (x<y){
lt_cnt++;
result = x-y;
}else{
ge_cnt++;
result = x-y;
}
return result;
}
// cc jmp.c -Og -S
// x in %rdi ,y in %rsi
// cat jmp.s
absdiff_se:
cmpq %rsi, %rdi ; compare x:y
jge .L2 ; x>=y 跳转 .L2
addq $1, lt_cnt(%rip) ; lt_cnt++
movq %rsi, %rax ; rax = y
subq %rdi, %rax ; rax = y-x
ret
.L2:
addq $1, ge_cnt(%rip) ; ge_cnt++
movq %rdi, %rax ; rax = x
subq %rsi, %rax ; rax = x-y
ret
// cc jmp.c -Og -c
// objdump -d jmp.o
0000000000000000 <absdiff_se>:
0: 48 89 f8 mov %rdi,%rax
3: 48 39 f7 cmp %rsi,%rdi
6: 7d 0c jge 14 <absdiff_se+0x14> ; 0x14 = 0x08 + 0x0c
8: 48 83 05 00 00 00 00 addq $0x1,0x0(%rip) # 10 <absdiff_se+0x10>
f: 01
10: 48 29 f0 sub %rsi,%rax
13: c3 retq
14: 48 83 05 00 00 00 00 addq $0x1,0x0(%rip) # 1c <absdiff_se+0x1c>
1b: 01
1c: 48 29 f0 sub %rsi,%rax
1f: c3 retq
用条件传送来实现条件分支。 这种方法计算一个条件操作的两种结果,然后再根据条件是否满足从中选取一个。
指令 cmov S,D
相等(或零)与不相等(或非零):comve(comvz) comvne(comvnz) 负数与非负数:comvs comvns 有符号比较:comvg(comvnle) comvge(comvnl) comvl(comvnge) comvle(comvng) 无符号比较:comva(comvnbe) comvae(comvnb) comvb(comvnae) comvbe(comvna) 由于当前的CPU通过使用流水线来获得高性能。当机器遇到条件跳转时,只有当分支条件求值完成之后,才能决定分支往哪边走。处理器采用非常精密的分支预测逻辑来猜测每条跳转指令是否会执行。只要它猜测的比较可靠,指令流水线中就会充满指令。另一方面,错误预测一个跳转,要求处理器丢掉它为该跳转指令后所有指令已做的工作,然后开始用从正确位置处起始的指令去填充流水线。这样一个错误预判会招致很严重的惩罚,浪费15~30个时钟周期,导致程序性能严重下降。 而条件传送,先各分支求值,没有跳转,性能稳定。但是当分支计算复杂时,程序性能可能会下降。 long absdiff(long a,long b){
if (a>b)
return a-b;
else
return b-a;
}
// cc absdiff.c -O1 -S
// a in %rdi, b in %rsi
absdiff:
movq %rdi, %rdx
subq %rsi, %rdx ; rdx = a-b
movq %rsi, %rax
subq %rdi, %rax ; rax = b-a
cmpq %rsi, %rdi ; compare a:b
cmovg %rdx, %rax ; if a>b, rax = rdx(a-b)
ret
long fact_do(long n){
long result = 1;
do {
result *=n;
n = n-1;
}while(n>1);
return result;
}
long fact_do_goto(long n){
long result = 1;
loop:
result *=n;
n = n-1;
if (n>1) goto loop;
return result;
}
// n in %rdi
fact_do:
movl $1, %eax
.L2:
imulq %rdi, %rax
subq $1, %rdi
cmpq $1, %rdi ; compare x:1
jg .L2 ; if > , goto .L2
ret
long fact_do_while(long n){
long result = 1;
while(n>1) {
result *=n;
n = n-1;
};
return result;
}
long fact_do_while_goto(long n){
long result = 1;
if(n<=1) goto done;
loop:
result *=n;
n = n-1;
if (n>1) goto loop;
done:
return result;
}
fact_do_while:
movl $1, %eax
cmpq $1, %rdi
jle .L4
.L3:
imulq %rdi, %rax
subq $1, %rdi
cmpq $1, %rdi
jne .L3
ret
.L4:
ret
// 返回0表示有偶数个1,返回1奇数个1
long func_a(unsigned long x){
long val=0;
while(x){
val ^= x;
x >>= 1;
}
return val&1;
}
long func_a_goto(unsigned long x){
long val=0;
goto test;
loop:
val ^= x;
x >>= 1;
test:
if (x!=0) goto loop;
return val&1;
}
func_a:
movl $0, %eax
jmp .L7
.L8:
xorq %rdi, %rax
shrq %rdi
.L7:
testq %rdi, %rdi
jne .L8
andl $1, %eax
ret
long fact_for(long n){
long i;
long result = 1;
for(i=2;i<=n;i++){
result *= i;
}
return result;
}
long fact_for_goto(long n){
long i = 2;
long result = 1;
goto test;
loop:
result *= i;
i++;
test:
if (i<=n) goto loop;
return result;
}
// n in %rdi
fact_for:
movl $1, %edx
movl $2, %eax
jmp .L10
.L11:
imulq %rax, %rdx
addq $1, %rax
.L10:
cmpq %rdi, %rax
jle .L11
movq %rdx, %rax
ret
P调用Q,共同机制
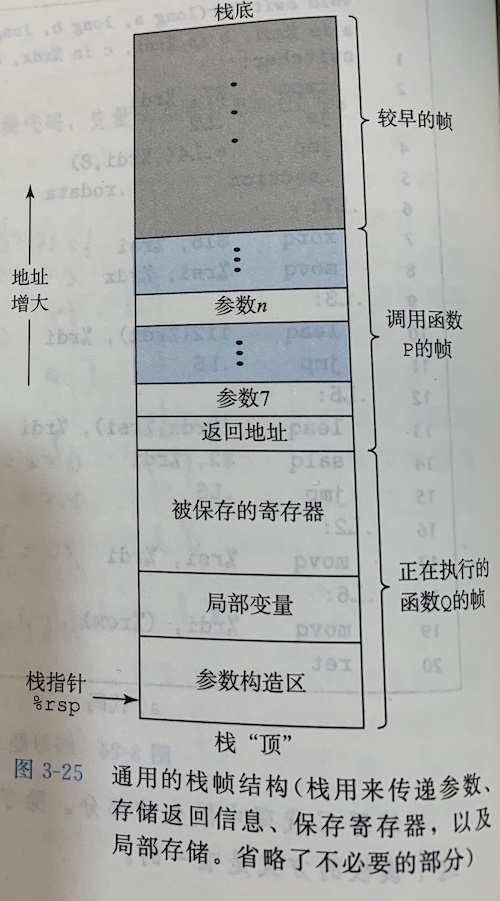
传递控制:在进入过程Q的时候,程序计数器必须被设置为Q的代码的起始地址,然后在返回时,要把程序计数器设置为P中调用Q后面那条指令的地址 传递数据:P必须能够向Q提供一个或多个参数,Q必须能够向P返回一个值 分配和释放内存:在开始时,Q可能需要为局部变量分配空间,而在返回前,又必须释放这些存储空间 当x86-64过程需要的存储空间超出寄存器能够存放的大小时,就会在栈上分配空间。这个部分称为过程的栈帧(stack frame)
参数大于6个的部分参数放在栈中 栈上的局部存储
寄存器不足够存放所有的本地数据 对一个局部变量使用地址运算符’&',因此必须能够为它产生一个地址。(leaq 18(%rsp), %r9 ; 参数 &x3) 某些局部变量是数组或结构,因此必须能够通过数组或结构引用被访问到。 void proc(long a1,long *a1p,
int a2,int *a2p,
short a3,short *a3p,
char a4, char *a4p
){
*a1p += a1;
*a2p += a2;
*a3p += a3;
*a4p += a4;
}
long call_proc(){
long x1 = 1;
int x2 = 2;
short x3 = 3;
char x4 = 4;
proc(x1,&x1,x2,&x2,x3,&x3,x4,&x4);
return (x1+x2)*(x3-x4);
}
// rdi rsi rdx rcx r8 r9
proc:
movq 16(%rsp), %rax ; 获取 *a4p
addq %rdi, (%rsi) ; *a1p += a1
addl %edx, (%rcx) ; *a2p += a2
addw %r8w, (%r9) ; *a3p += a3
movl 8(%rsp), %edx ; 获取 a4
addb %dl, (%rax) ; *a4p += a4;
ret
call_proc:
subq $16, %rsp ; 分配参数栈空间
movq $1, 8(%rsp) ; 局部变量x1
movl $2, 4(%rsp) ; 局部变量x2
movw $3, 2(%rsp) ; 局部变量x3
movb $4, 1(%rsp) ; 局部变量x4
leaq 1(%rsp), %rax ; &x4
pushq %rax ; 参数 &x4
pushq $4 ; 参数 x4
leaq 18(%rsp), %r9 ; 参数 &x3
movl $3, %r8d ; 参数 x3
leaq 20(%rsp), %rcx ; 参数 &x2
movl $2, %edx ; 参数 x2
leaq 24(%rsp), %rsi ; 参数 &x1
movl $1, %edi ; 参数 x1
call proc
movslq 20(%rsp), %rax ; x2 int->long
addq 24(%rsp), %rax ; rax=x1+x2
movswl 18(%rsp), %edx ; x3 short->int
movsbl 17(%rsp), %ecx ; x4 char->int
subl %ecx, %edx ; edx=x3-x4
movslq %edx, %rdx ; edx int->long
imulq %rdx, %rax ; rax = (x1+x2)*(x3-x4)
addq $32, %rsp ; 释放栈空间
ret
寄存器中的局部存储空间:当寄存器不足于保存临时变量时,使用栈保存。
根据惯例,寄存器%rbx、%rbp和%r12~%r15被划分为被调用者保存寄存器。当过程P调用过程Q时,Q必须保存这些寄存器的值,保证它们的值在Q返回到P时与Q被调用时是一样的。所有其他寄存器,除了栈指针%rsp,都分类为调用者保存寄存器。这就意味着任何函数都可以修改它们。也就是说,过程P在某个此类寄存器中有局部数据,然后调用过程Q,因为Q可以随意修改这个寄存器,所以在调用之前首先保存好这个数据时P(调用者)的责任。 递归 rfact:
cmpq $1, %rdi
jg .L8
movl $1, %eax
ret
.L8:
pushq %rbx ; save rbx
movq %rdi, %rbx ; store n
leaq -1(%rdi), %rdi ; n=n-1
call rfact
imulq %rbx, %rax ; result = n*rfact(n-1)
popq %rbx ; restore rbx
ret
嵌套数组:行主序,对于int P[M][N]类型的数组,P[i][j] 地址为 P+(i*N+j)*4 #define N 16
typedef int fix_matrix[N][N];
int fix_prod_ele(fix_matrix A,fix_matrix B,long i,long k){
long j;
int result =0 ;
for(j=0;i<N;j++){
result += A[i][j] + B[j][k];
}
return result;
}
// A in %rdi ,B in %rsi,i in %rdx ,k in %rcx
fix_prod_ele:
movq %rdi, %r9 ; r9=A
movq %rsi, %r10 ; r10=B
movl $0, %r8d ; result = 0
movl $0, %eax ; j = 0
jmp .L3
.L4:
movq %rdx, %rdi ; rdi = i
salq $6, %rdi ; rdi = 64*i
addq %r9, %rdi ; rdi = A+64*i
movq %rax, %rsi ; rsi = j
salq $6, %rsi ; rsi = j*64
addq %r10, %rsi ; rsi = B+j*64
movl (%rsi,%rcx,4), %esi ; M[B+j*64+4*k]【B[j][k]】
addl (%rdi,%rax,4), %esi ; esi = M[A+64*i+4*j]+M[B+j*64+4*k]
addl %esi, %r8d ; r8d += esi
addq $1, %rax ; rax ++
.L3:
cmpq $15, %rdx ; compare i:n
jle .L4 ; if <= ,goto .L4
movl %r8d, %eax ; return result
ret
变长数组:对于int A[m][n],A[i][j]地址为i * n+j,必须用乘法指令对i伸缩n倍(i * j),而不能使用一系列的移位和加法 结构struct的所有组成部分都存放在内存中一段连续的区域内,而指向结构的指针就是结构第一个字节的地址联合 数据对齐,通常为2、4、8 使用
开始和停止
quit 退出GDB run 运行程序(在此给出命令行参数) kill 停止程序 短点
break multscore:在函数multscore入口处设置断点 break * 0x400540:在地址0x400540处设置断点 delete 1:删除断点1 delete:删除所有断点 执行
stepi:执行一条指令 stepi 4:执行4条指令 nexti:类似于stepi,但以函数调用为单位 continue:继续执行 finish:运行到当前函数返回 检查代码
disas:反汇编当前函数 disas multscore:反汇编函数multscore disas 0x400544:反汇编位于地址0x400544附近的函数 disas 0x400540,0x40054d 反汇编指定地址范围内的代码 print /x $rip:以16进制输出程序计数器的值 检查数据
print $rax:以十进制输出%rax的内容 print /t $rax:以二进制输出 print 0x100:以十进制输出0x100 print /x ($rsp+8):以16进制输出%rsp的内容加上8 print *(long *)($rsp+8):输出位于地址%rsp+8处的长整数 x/2g 0x7fffffffe818:检查从地址0x7fffffffe818开始的双(8字节)字 x/20b multscore:检查函数multscore的前20个字节 有用的信息
info frame:有关当前栈帧的信息 info registers:所有寄存器的值 help 缓冲区溢出:8字节buf,上面是%rbp值,所以当输入小于等于15个字符时,程序不会崩溃 [root@localhost csapp]# ./a.out
123456
123456
[root@localhost csapp]# ./a.out
123456789012345
123456789012345
[root@localhost csapp]# ./a.out
1234567890123456
1234567890123456
Segmentation fault (core dumped)
// echo.c
#include <stdio.h>
void echo(){
char buf[8];
gets(buf);
puts(buf);
}
int main(){
echo();
return 0;
}
// cc echo.c
// objdump -d a.out
...
0000000000401136 <echo>:
401136: 55 push %rbp
401137: 48 89 e5 mov %rsp,%rbp
40113a: 48 83 ec 10 sub $0x10,%rsp
40113e: 48 8d 45 f8 lea -0x8(%rbp),%rax ; buf
401142: 48 89 c7 mov %rax,%rdi
401145: b8 00 00 00 00 mov $0x0,%eax
40114a: e8 f1 fe ff ff callq 401040 <gets@plt>
40114f: 48 8d 45 f8 lea -0x8(%rbp),%rax
401153: 48 89 c7 mov %rax,%rdi
401156: e8 d5 fe ff ff callq 401030 <puts@plt>
40115b: 90 nop
40115c: c9 leaveq
40115d: c3 retq
...
对抗缓冲区溢出
栈随机化:使栈的位置在程序每次运行都有变化。为了在系统中插入攻击代码,攻击者既要插入代码,也要插入指向这段代码的指针,产生这个指针需要知道这个字符串放置的栈地址,栈随机化避免了此类攻击。
可以在攻击代码前加入一段nop指令,运用蛮力攻击,只要地址落在这一段代码上即可实现攻击。 nop指令(no operation):是程序计数器加一,没有其他效果 栈破坏检测:程序每次随机产生一个值,当出现缓冲区溢出时,修改了哨兵值,函数运行完会检测此值是否改变。 限制可执行代码区域:限制栈只能读写,不能代码执行 // 栈破坏检测
// gcc echo.c -fstack-protector
[root@localhost csapp]# ./a.out
123456789
123456789
*** stack smashing detected ***: terminated
Aborted (core dumped)
0000000000401146 <echo>:
401146: 55 push %rbp
401147: 48 89 e5 mov %rsp,%rbp
40114a: 48 83 ec 10 sub $0x10,%rsp
40114e: 64 48 8b 04 25 28 00 mov %fs:0x28,%rax ; 栈保护
401155: 00 00
401157: 48 89 45 f8 mov %rax,-0x8(%rbp) ; 金丝雀canary值
40115b: 31 c0 xor %eax,%eax
40115d: 48 8d 45 f0 lea -0x10(%rbp),%rax ; buf
401161: 48 89 c7 mov %rax,%rdi
401164: b8 00 00 00 00 mov $0x0,%eax
401169: e8 e2 fe ff ff callq 401050 <gets@plt>
40116e: 48 8d 45 f0 lea -0x10(%rbp),%rax
401172: 48 89 c7 mov %rax,%rdi
401175: e8 b6 fe ff ff callq 401030 <puts@plt>
40117a: 90 nop
40117b: 48 8b 45 f8 mov -0x8(%rbp),%rax
40117f: 64 48 2b 04 25 28 00 sub %fs:0x28,%rax ; 查看是否栈溢出
401186: 00 00
401188: 74 05 je 40118f <echo+0x49>
40118a: e8 b1 fe ff ff callq 401040 <__stack_chk_fail@plt>
40118f: c9 leaveq
401190: c3 retq
支持变长栈帧:在较早版本的x86代码中,每个函数调用都使用了栈指针(frame pointer)。而现在,只有栈帧长可变的情况才使用。
pushq %rbp; movq %rsp,%rbp long vframe(long n,long idx,long *q){
long i;
long *p[n];
p[0]=&i;
for(i=1;i<n;i++)
p[i]=q;
return *p[idx];
}
vframe:
pushq %rbp
movq %rsp, %rbp ; 栈指针
subq $16, %rsp
leaq 15(,%rdi,8), %rax
andq $-16, %rax ; rax 取8n最靠近的16倍数
subq %rax, %rsp ; 分配给p
leaq 7(%rsp), %rcx
movq %rcx, %rax
shrq $3, %rax ; 除8
andq $-8, %rcx ; rcx为rsp向上取8的倍数,即p的起始地址
leaq -8(%rbp), %r8 ; &i
movq %r8, 0(,%rax,8) ; p[0]=&i
movq $1, -8(%rbp)
jmp .L2
.L3:
movq %rdx, (%rcx,%rax,8) ; 循环赋值
addq $1, -8(%rbp)
.L2:
movq -8(%rbp), %rax
cmpq %rdi, %rax
jl .L3
movq (%rcx,%rsi,8), %rax
movq (%rax), %rax
leave
ret
媒体寄存器
AVX浮点体系结构的16个YMM寄存器(256位):%ymm0~%ymm15 SSE XMM寄存器(128位):%xmm0~%xmm15 浮点传送指令:不做任何转换的传送指令。X:XMM寄存器
传送单精度:vmovss M32,X 传送单精度:vmovss X,M32 传送双精度:vmovsd M64,X 传送双精度:vmovsd X,M64 传送对其的封装好的单精度:vmovaps X,X 传送对其的封装好的双精度:vmovapd X,X float float_mov(float v1,float *src,float *dst){
float v2 = *src;
*dst = v1;
return v2;
}
// v1 in %xmm0, src in %rdi, dst in %rsi
float_mov:
movaps %xmm0, %xmm1 ; copy v1
movss (%rdi), %xmm0 ; Read v2 from src
movss %xmm1, (%rsi) ; Write v1 to dst
ret ; return v2 in %xmm0
浮点数和整数转换即不同浮点格式之间进行转换
vcvttss2si X/M32,R32:单精度->整数 vcvttsd2si X/M64,R32:双精度->整数 vcvttss2siq X/M32,R64:单精度->四字整数 vcvttsd2siq X/M64,R64:双精度->四字整数 vcvtsi2ss M32/R32,X,X:整数->单精度 vcvtsi2sd M32/R32,X,X:四字整数->双精度 vcvtsi2ssq M64/R64,X,X:整数->单精度 vcvtsi2sdq M64/R64,X,X:四字整数->双精度 对于三个操作数的指令,第一个操作数读自内存或一个通用寄存器,第二个操作数数只会影响结果的高位字节,一般忽略,第三个操作数为目的寄存器 过程中的浮点代码
XMM寄存器%xmm0~%xmm7最多可以传递8个浮点参数。多于的使用栈 函数使用%xmm0来返回浮点数 所有的XMM寄存器都是调用者保存。被调用者可以不用保存就覆盖这些寄存器中的任何一个。当函数包含指针、整数、浮点数混合的参数时,指针和整数通过通用寄存器传递 浮点运算操作
vaddss vaddsd:浮点加 单精度 双精度 vsubss vsubsd:浮点减 vmulss vmulsd:乘 vdivss vdivsd:除 vmaxss vmaxsd:最大 vminss vminsd:最小 sqrtss sqrtsd:平方根 double funct(double a,float x,double b,int i){
return a*x-b/i;
}
funct:
cvtss2sd %xmm1, %xmm1 ; x -> double
mulsd %xmm0, %xmm1 ; a*x
pxor %xmm0, %xmm0 ; 0
cvtsi2sdl %edi, %xmm0 ; int -> double
divsd %xmm0, %xmm2 ; b/i
subsd %xmm2, %xmm1 ; a*x - b/i
movapd %xmm1, %xmm0
ret
定义和使用浮点常数:AVX浮点数不能以立即数作为操作数。编译器必须为所有的常量分配和初始化存储空间,然后代码再把这些值从内存读入。 double cel2fahr(double temp){
return 1.8*temp+32.0;
}
cel2fahr:
mulsd .LC0(%rip), %xmm0
addsd .LC1(%rip), %xmm0
ret
.LC0:
.long -858993459 ; 1.8的低4位
.long 1073532108 ; 1.8的高四位
.LC1:
.long 0
.long 1077936128
位级操作:
vxorps xorpd:异或 单精度 双精度 vandps andpd 浮点比较
vucomiss:单精度比较 vucomisd:双精度比较


























 428
428











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









