






论文:https://arxiv.org/pdf/1802.04942.pdf
摘要:
论文将 ELBO(evidence lower bound)分解成多项,用于调整隐变量之间的关系,提出 β-TCVAE 算法,是 β-VAE 的加强和替换版本,并且在训练中不增加任何超参数。论文进一步提出 disentanglement 的规则的无分类方法 MIG( mutaul information gap)。
介绍:
论文主要做了四个贡献:① 分解 ELBO, 解释 β-VAE 的成功之处 ② 提出一个方法:基于随机训练中的权重采样,且不增加任何超参数 ③ 引入 β-TCVAE 发现更多可解释隐变量,在随机初始化情况下具有更强的鲁棒性 ④ 从信息论视角处理 disentanglement ,无分类器和可生成随机分布和无标准分布的隐变量。
背景:
① VAE 提出一对隐变量模型,顶层的 generative 生成模型和底层的 inference 推断模型,VAE 没有直接求解 likelihood estimation (似然估计),由于该 likelihood 很难直接求解。VAE 的训练是直接由优化 ELBO 进行的,以下是核心方程:

decoder ![]() 和encoder
和encoder ![]() 由深度神经网络调整参数,同时在 VAE 的论文中为了更好的求解使用再参数化的技巧,引入高斯分布,此处不再赘述。
由深度神经网络调整参数,同时在 VAE 的论文中为了更好的求解使用再参数化的技巧,引入高斯分布,此处不再赘述。
② β-VAE 在 VAE 的基础上增加了一个惩罚项,核心方程如下:

在 β-VAE 的论文中指出,如果 p(z) 是因子(阶乘)的,隐变量表示会变得更加独立。但是 β-VAE 没有明确为什么在 KL 散度项(公式中右边第二项)中加入惩罚因子会使得学习隐变量变得更加 disentangled。
③ InfoGAN 是 GAN (generative adversarial network)的延伸(变种),GAN 通过最大化探索数据和小部分隐变量之间互信息来增强隐变量的表示。
ELBO分解:
将 KL 散度公式分解成如下表达方式
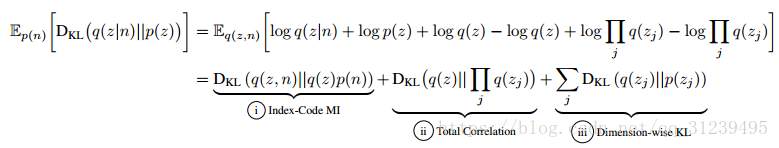
分析上述分解式:① index-code MI 表示在经验上的分布 q( z, n )的变量和隐变量之间的互信息,可以看做在 p(x) 和 q(x)持续且偏置的估计, index-code MI 的期望是一个下届。 p(n) 是一个经验分布,更高的 index-code MI 会在分辨经验采样有更好的效果。② 表示 total correlation ( TC ),TC 作为惩罚使得模型在分布中寻找统计独立性因子,更重的惩罚(TC 的值越大)引起更大的 posterior 后验学习分布中语义的统计独立性,这其中会包括更加 disentangled 表示。③ dimension-wise KL 阻止独立变量太偏离它们所对应的先验分布。
β-VAE 分析:
β-VAE 在传统的 ELBO 中的 KL 散度项添加了惩罚项,鼓励更低的 total corelation 但同时也惩罚了 index-code MI. 更低的 total corelation 是 β-VAE 表现优异的核心所在。
使用小样本权重采样:论文提出一个方法来随机估计分解项,可以分别使得每一个分解项都可以测量。![]()
上述公式计算需要整个经验数据,但是这在训练中是不希望发生的。论文提出的方法没有增加超参数或者内部更多的优化方法环路。传统的蒙特卡洛近似基于 p(n) 的采样经常会 过低估计 q(z). 比如 n 取样自 z 时, q(z|n) 接近0, 而正确的值应该很大。因此,论文借鉴重要性采样的思路,训练时,估计函数 logq(z) 时使用权重,公式如下:
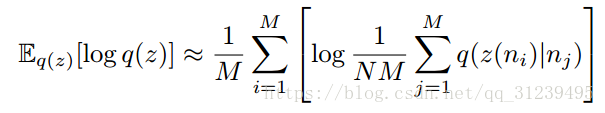
因为原期望是一个下届,所以这个估计是偏置的。
β-TCVAE公式:
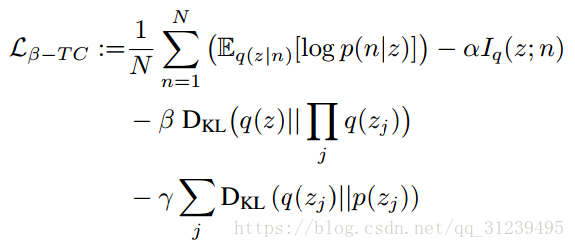
在论文中使得![]() ,调整β的值进行调训练。
,调整β的值进行调训练。
通过MIG评估 disentanglement:论文提出了一种新的在隐变量和分类准确性的基于经验的互信息标准 empirical mutual information (MIG),在隐变量 z 和分类标准准确性因素 vk 中的 MIG 可以使用联合分布:
![]()
进行估计,并且假设![]() 和生成方式对经验数据已知。则:
和生成方式对经验数据已知。则:
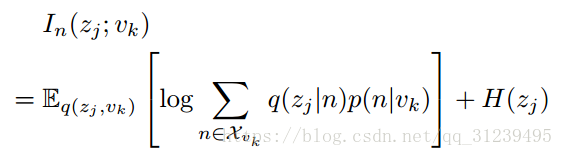
通过求得两个变量之间最大的互信息来加强轴间校准,公式可以转化为: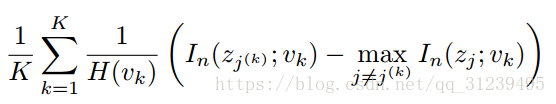
上述公式的第一项与因素的旋转有关,如果隐变量不是轴向排列的,每个变量可能包含更多的信息,可能会被认为是两个或者更多的因素。第二项与表示得简洁度有关,如果一个隐变量是基于某一个因素的,其他变量就不必也关联这个因素了。
下表对比了各个不同的标准的优劣势:
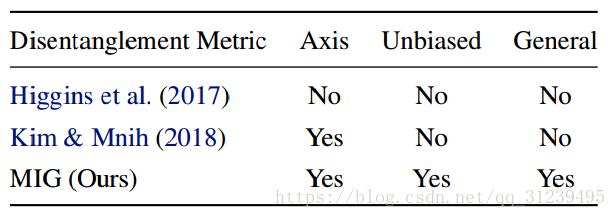
结论:β-TCVAE相对与 β-VAE效果更好,并且不增加多余的网络结构和超参数。

















 1178
1178

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









