







目录
前言
分类问题的评价指标是准确率,回归算法的评价指标是MSE,RMSE,MAE.测试数据集中的点,距离模型的平均距离越小,该模型越精确。使用平均距离,而不是所有测试样本的距离和,因为受样本数量影响。
假设:

MAE
平均绝对误差(Mean Absolute Error),观测值与真实值的误差绝对值的平均值。公式为:
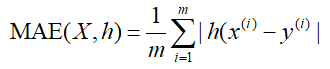
范围[0,+∞),当预测值与真实值完全吻合时等于0,即完美模型;误差越来大,值越大。
RMSE
均方根误差(Root Mean Square Error),其实就是MSE加了个根号,这样数量级上比较直观,比如RMSE=10,可以认为回归效果相比真实值平均相差10。

范围[0,+∞),当预测值与真实值完全吻合时等于0,即完美模型;误差越大,该值越大。
上面的两个指标是用来描述预测值与真实值的误差情况。它们之间在的区别在于,RMSE先对偏差做了一次平方,
这样,如果误差的离散度高,也就是说,如果最大偏差值大的话,RMSE就放大了。比如真实值是0,对于3次测量值分别是8,3,1,那么

如果3次测量值分别是5,4,3,那么
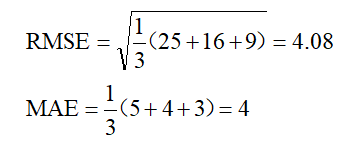
可以看出,两种情况下MAE相同,但是因为前一种情况下有更大的偏离值,所以RMSE就大的多了。
MSE
均方误差(Mean Square Error)
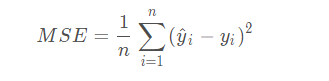
范围[0,+∞],当预测值与真实值完全吻合时等于0,即完美模型;误差越大,该值越大,模型性能越差。
MAPE
平均绝对百分比误差(Mean Absolute Percentage Error)

范围[0,+∞),MAPE 为0%表示完美模型,MAPE 大于 100 %则表示劣质模型。
可以看到,MAPE跟MAE很像,就是多了个分母。
注意点:当真实值有数据等于0时,存在分母0除问题,该公式不可用!
SMAPE
对称平均绝对百分比误差(Symmetric Mean Absolute Percentage Error)

注意点:当真实值有数据等于0,而预测值也等于0时,存在分母0除问题,该公式不可用!
nMSE
归一化均方误差(the normalized Mean Squared Error (nMSE))

yi,y`i是第i个短视频的真实值和预测值。MSE是计算预测值和真实值之差的平方的期望值。VAR是计算真实值的方差。
SRC
斯皮尔曼等级相关性(Spearman’s rank correlation)

yji和y`ji是第j个时间步的第i个真实值序列和预测序列。
Python程序
# coding=utf-8
import numpy as np
from sklearn import metrics
# MAPE和SMAPE需要自己实现
def mape(y_true, y_pred):
return np.mean(np.abs((y_pred - y_true) / y_true)) * 100
def smape(y_true, y_pred):
return 2.0 * np.mean(np.abs(y_pred - y_true) / (np.abs(y_pred) + np.abs(y_true))) * 100
y_true = np.array([1.0, 5.0, 4.0, 3.0, 2.0, 5.0, -3.0])
y_pred = np.array([1.0, 4.5, 3.5, 5.0, 8.0, 4.5, 1.0])
# MSE
print(metrics.mean_squared_error(y_true, y_pred)) # 8.107142857142858
# RMSE
print(np.sqrt(metrics.mean_squared_error(y_true, y_pred))) # 2.847304489713536
# MAE
print(metrics.mean_absolute_error(y_true, y_pred)) # 1.9285714285714286
# MAPE
print(mape(y_true, y_pred)) # 76.07142857142858,即76%
# SMAPE
print(smape(y_true, y_pred)) # 57.76942355889724,即58%
参考:














 2111
2111











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









