







昇思25天学习打卡营第15天 | SSD目标检测
目标检测的任务是在图像中找到目标并进行分类,目标检测主流算法可以分为两个类型:
- two-stage方法:RCNN系列,通过算法产生候选框,然后对候选框进行分类和回归;
- one-stage方法:YOLO和SSD,直接通过主干网络给出类别位置信息,不需要区域生成。
SSD模型
SSD(Single Shot MultiBox Detector)是单阶段的额目标检测算法,通过卷积神经网络进行特征提取,取不同的特征层进行检测输出。在需要检测的特征层,直接使用
3
×
3
3\times 3
3×3卷积进行通道变换。
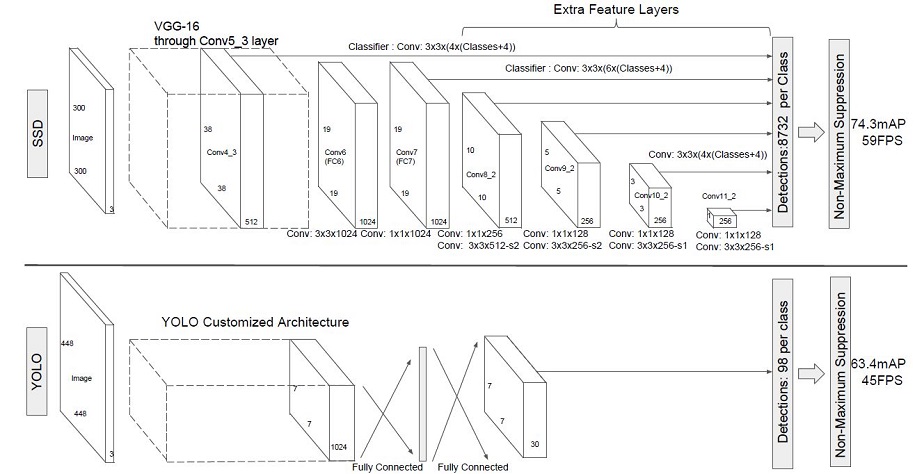
SSD网络结构
SSD网络结构主要分为五个部分:
- Backbone Layer:通常为VGG16,输入图像经过预处理后大小固定为
300
×
300
300\times300
300×300,经过backbone提取特征。

- Extra Feature Layer:在VGG16基础上,进一步增加了4个深度卷积层,同于提取更高层的语义信息。

- Detection Layer:SSD模型共有6和预测图,对与尺寸
m
×
n
m\times n
m×n,通道为
p
p
p的特征图,为每个像素点产生
k
k
k个anchor,每个anchor对应
c
c
c个类别和
4
4
4个回归偏移量,使用
(
4
+
c
)
k
(4+c)k
(4+c)k个尺寸为
3
×
3
3\times3
3×3,通道为
p
p
p的卷积核进行卷积操作,得到尺寸
m
×
n
m\times n
m×n,通道
(
4
+
c
)
m
×
k
(4+c)m\times k
(4+c)m×k的输出特征图,包含了每个anchor的回归便宜和各类别概率分数。
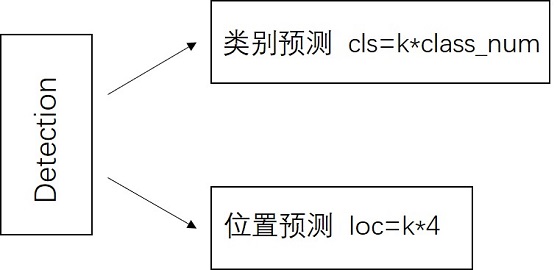
- NMS:对每个类别应用非极大值抑制(NMS),去除重叠的框,并保留告知新都的框。
- Anchor:为每个像素点产生的PriorBox,由中心坐标和宽、高表示。

模型构建
backbone layer
from mindspore import nn
def _make_layer(channels):
in_channels = channels[0]
layers = []
for out_channels in channels[1:]:
layers.append(nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=3))
layers.append(nn.ReLU())
in_channels = out_channels
return nn.SequentialCell(layers)
class Vgg16(nn.Cell):
"""VGG16 module."""
def __init__(self):
super(Vgg16, self).__init__()
self.b1 = _make_layer([3, 64, 64])
self.b2 = _make_layer([64, 128, 128])
self.b3 = _make_layer([128, 256, 256, 256])
self.b4 = _make_layer([256, 512, 512, 512])
self.b5 = _make_layer([512, 512, 512, 512])
self.m1 = nn.MaxPool2d(kernel_size=2, stride=2, pad_mode='SAME')
self.m2 = nn.MaxPool2d(kernel_size=2, stride=2, pad_mode='SAME')
self.m3 = nn.MaxPool2d(kernel_size=2, stride=2, pad_mode='SAME')
self.m4 = nn.MaxPool2d(kernel_size=2, stride=2, pad_mode='SAME')
self.m5 = nn.MaxPool2d(kernel_size=3, stride=1, pad_mode='SAME')
def construct(self, x):
# block1
x = self.b1(x)
x = self.m1(x)
# block2
x = self.b2(x)
x = self.m2(x)
# block3
x = self.b3(x)
x = self.m3(x)
# block4
x = self.b4(x)
block4 = x
x = self.m4(x)
# block5
x = self.b5(x)
x = self.m5(x)
return block4, x
SSD
import mindspore as ms
import mindspore.nn as nn
import mindspore.ops as ops
def _last_conv2d(in_channel, out_channel, kernel_size=3, stride=1, pad_mod='same', pad=0):
in_channels = in_channel
out_channels = in_channel
depthwise_conv = nn.Conv2d(in_channels, out_channels, kernel_size, stride, pad_mode='same',
padding=pad, group=in_channels)
conv = nn.Conv2d(in_channel, out_channel, kernel_size=1, stride=1, padding=0, pad_mode='same', has_bias=True)
bn = nn.BatchNorm2d(in_channel, eps=1e-3, momentum=0.97,
gamma_init=1, beta_init=0, moving_mean_init=0, moving_var_init=1)
return nn.SequentialCell([depthwise_conv, bn, nn.ReLU6(), conv])
class FlattenConcat(nn.Cell):
"""FlattenConcat module."""
def __init__(self):
super(FlattenConcat, self).__init__()
self.num_ssd_boxes = 8732
def construct(self, inputs):
output = ()
batch_size = ops.shape(inputs[0])[0]
for x in inputs:
x = ops.transpose(x, (0, 2, 3, 1))
output += (ops.reshape(x, (batch_size, -1)),)
res = ops.concat(output, axis=1)
return ops.reshape(res, (batch_size, self.num_ssd_boxes, -1))
class MultiBox(nn.Cell):
"""
Multibox conv layers. Each multibox layer contains class conf scores and localization predictions.
"""
def __init__(self):
super(MultiBox, self).__init__()
num_classes = 81
out_channels = [512, 1024, 512, 256, 256, 256]
num_default = [4, 6, 6, 6, 4, 4]
loc_layers = []
cls_layers = []
for k, out_channel in enumerate(out_channels):
loc_layers += [_last_conv2d(out_channel, 4 * num_default[k],
kernel_size=3, stride=1, pad_mod='same', pad=0)]
cls_layers += [_last_conv2d(out_channel, num_classes * num_default[k],
kernel_size=3, stride=1, pad_mod='same', pad=0)]
self.multi_loc_layers = nn.CellList(loc_layers)
self.multi_cls_layers = nn.CellList(cls_layers)
self.flatten_concat = FlattenConcat()
def construct(self, inputs):
loc_outputs = ()
cls_outputs = ()
for i in range(len(self.multi_loc_layers)):
loc_outputs += (self.multi_loc_layers[i](inputs[i]),)
cls_outputs += (self.multi_cls_layers[i](inputs[i]),)
return self.flatten_concat(loc_outputs), self.flatten_concat(cls_outputs)
class SSD300Vgg16(nn.Cell):
"""SSD300Vgg16 module."""
def __init__(self):
super(SSD300Vgg16, self).__init__()
# VGG16 backbone: block1~5
self.backbone = Vgg16()
# SSD blocks: block6~7
self.b6_1 = nn.Conv2d(in_channels=512, out_channels=1024, kernel_size=3, padding=6, dilation=6, pad_mode='pad')
self.b6_2 = nn.Dropout(p=0.5)
self.b7_1 = nn.Conv2d(in_channels=1024, out_channels=1024, kernel_size=1)
self.b7_2 = nn.Dropout(p=0.5)
# Extra Feature Layers: block8~11
self.b8_1 = nn.Conv2d(in_channels=1024, out_channels=256, kernel_size=1, padding=1, pad_mode='pad')
self.b8_2 = nn.Conv2d(in_channels=256, out_channels=512, kernel_size=3, stride=2, pad_mode='valid')
self.b9_1 = nn.Conv2d(in_channels=512, out_channels=128, kernel_size=1, padding=1, pad_mode='pad')
self.b9_2 = nn.Conv2d(in_channels=128, out_channels=256, kernel_size=3, stride=2, pad_mode='valid')
self.b10_1 = nn.Conv2d(in_channels=256, out_channels=128, kernel_size=1)
self.b10_2 = nn.Conv2d(in_channels=128, out_channels=256, kernel_size=3, pad_mode='valid')
self.b11_1 = nn.Conv2d(in_channels=256, out_channels=128, kernel_size=1)
self.b11_2 = nn.Conv2d(in_channels=128, out_channels=256, kernel_size=3, pad_mode='valid')
# boxes
self.multi_box = MultiBox()
def construct(self, x):
# VGG16 backbone: block1~5
block4, x = self.backbone(x)
# SSD blocks: block6~7
x = self.b6_1(x) # 1024
x = self.b6_2(x)
x = self.b7_1(x) # 1024
x = self.b7_2(x)
block7 = x
# Extra Feature Layers: block8~11
x = self.b8_1(x) # 256
x = self.b8_2(x) # 512
block8 = x
x = self.b9_1(x) # 128
x = self.b9_2(x) # 256
block9 = x
x = self.b10_1(x) # 128
x = self.b10_2(x) # 256
block10 = x
x = self.b11_1(x) # 128
x = self.b11_2(x) # 256
block11 = x
# boxes
multi_feature = (block4, block7, block8, block9, block10, block11)
pred_loc, pred_label = self.multi_box(multi_feature)
if not self.training:
pred_label = ops.sigmoid(pred_label)
pred_loc = pred_loc.astype(ms.float32)
pred_label = pred_label.astype(ms.float32)
return pred_loc, pred_label
损失函数
SSD算法的目标函数分为两个部分:置信度误差(confidence loss, conf)以及位置误差(localization loss,loc):
L
(
x
,
c
,
l
,
g
)
=
1
N
(
L
c
o
n
f
(
x
,
c
)
+
α
L
l
o
c
(
x
,
l
,
g
)
)
L(x,c,l,g)=\frac1N(L_{conf}(x,c)+\alpha L_{loc}(x,l,g))
L(x,c,l,g)=N1(Lconf(x,c)+αLloc(x,l,g))
- N N N:先验框的正样本数量;
- c c c:类别置信度预测值;
- l l l:先验框位置预测值;
- g g g:ground truth的位置参数;
- α \alpha α:调整两个loss的比例,默认为1。
位置损失函数
针对所有正样本,采用Smooth L1 Loss:
s
m
o
o
t
h
L
1
(
x
)
=
{
0.5
x
2
if
∣
x
∣
<
1
∣
x
∣
−
0.5
otherwise
smooth_{L_1}(x)=\begin{cases} \begin{aligned} &0.5x^2 &\text{if}\ |x|<1 \\ &|x|-0.5 &\text{otherwise} \end{aligned} \end{cases}
smoothL1(x)={0.5x2∣x∣−0.5if ∣x∣<1otherwise
置信度损失函数
置信度损失是多类置信度上的softmax损失:
L
c
o
n
f
(
x
,
c
)
=
−
∑
i
∈
P
o
s
N
x
i
j
p
log
(
c
^
i
p
)
−
∑
i
∈
N
e
g
log
(
c
^
i
0
)
where
c
^
i
p
=
exp
(
c
i
p
)
∑
p
exp
(
c
i
p
)
L_{conf}(x,c)=-\sum_{i\in Pos}^Nx_{ij}^p\log(\hat{c}_i^p)-\sum_{i\in Neg}\log(\hat{c}_i^0)\quad \text{where} \quad \hat{c}_i^p=\frac{\exp{(c_i^p)}}{\sum_p\exp(c_i^p)}
Lconf(x,c)=−i∈Pos∑Nxijplog(c^ip)−i∈Neg∑log(c^i0)wherec^ip=∑pexp(cip)exp(cip)
def class_loss(logits, label):
"""Calculate category losses."""
label = ops.one_hot(label, ops.shape(logits)[-1], Tensor(1.0, ms.float32), Tensor(0.0, ms.float32))
weight = ops.ones_like(logits)
pos_weight = ops.ones_like(logits)
sigmiod_cross_entropy = ops.binary_cross_entropy_with_logits(logits, label, weight.astype(ms.float32), pos_weight.astype(ms.float32))
sigmoid = ops.sigmoid(logits)
label = label.astype(ms.float32)
p_t = label * sigmoid + (1 - label) * (1 - sigmoid)
modulating_factor = ops.pow(1 - p_t, 2.0)
alpha_weight_factor = label * 0.75 + (1 - label) * (1 - 0.75)
focal_loss = modulating_factor * alpha_weight_factor * sigmiod_cross_entropy
return focal_loss
总结
这一节对对单阶段目标检测算法SSD进行了详细介绍,这个模型以VGG16为backbone提取特征,额外添加了4个深度卷积层,用以提取更高层的语义信息。该模型并不是通过网络来生成边界框,而是对大量预先生成的边界框进行分类和回归。SSD通过在多个层次的特征上进行检测,使得大小物体都能被检测到。
打卡


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











