







模型压缩概要
目前,将深度学习算法商业落地化,例如在嵌入式平台上运行的更加稳定、具有实时性一直是我们所追求的目标。本文主要讲述以下内容
- 本章主要讲介绍论文中出现的优化网络以减少计算量的方法,以及具有研究性以及可应用性的方法
论文中主要出现的方式如下:(其中带*号的讲具体重点介绍)
- 网络设计优化(卷积核计算优化)*
- 量化模型*
- 剪支和参数共享
- 知识蒸馏
- 权重张量低秩分解
- 将使用tensorflow的keras库介绍方法一和方法二的具体实现(推荐使用keras,原因在于keras设计的网络模型可以直接转换成tensorflow-lite能够直接部署于各种嵌入式平台上,转换过程中,将会自动的对模型进行优化,例如目标检测算法中的mobelnet网络大小仅仅有18M,而fmobilenet网络(参看mxnet中的insightface)仅仅只有4.3M,tensorflow-lite对各种嵌入式平台支持非常好)
模型压缩加速介绍
卷积核优化
卷积核优化算法中较新也较好的方式是shuffleNet网络中卷积核所使用的方式。为减少计算量,最直观的方式便是直接减少卷积层的计算量。如图11所示,常规卷积的卷积核通道数和输入特征图的通道数一致。
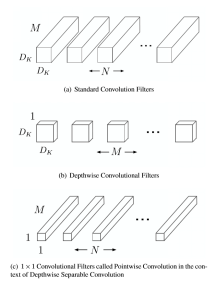
其具体做法是将卷积分为深度卷积和逐点卷积,通过基于深度可分离卷积,将典型的卷积操作图12(a)分解成深度卷积图12(b)和逐点卷积图12©.
相比于经典的卷积维度,深度可分离卷积首先通过卷积核为对特征图平面特征方向过滤(图12 b),然后再通过卷积核对特征图的通道方向进行过滤(图12 b)。两者可以认为是分别对平面维度和通道维度进行降维。然而
由于通道间信息不连通,这种方式会使得通道间充满约束。为了解决这种问题,Face++团队提出了shuffleNet网络。与MobileNet一样,shuffle利用了群卷积和深度可分卷积思想,但优化了核卷积用以解决通道之间的
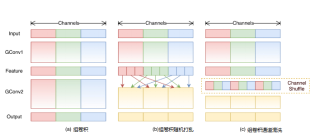
约束。如图12(a)组卷积所示,Shufflenet的方法将特征图通道分组进行卷积,增强了通道内部的信息联通。然而分组卷积仅仅解决了特征图组内信息的流通,组外信息并不能流通,降低了信息的表达能力。当然可以将卷积后的特征图在组内部切割,然后将切割后的部分按顺序排序,如图12(b)组卷积随机打乱所示。而shuffle通过通道混洗操作使得数据的通道维度上进行无序打乱,用以增加信息的表达能力,提升识别效果,如图12(c)所示。
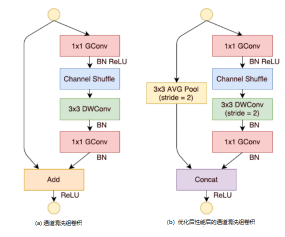
如图13 组卷积通道混洗所示,在Shufflenet经典模块图13(b)中,特征图首先通过组点卷积核操作,分组进行混洗操作,然后利用一般标准的组深度可分离卷积核进行过滤。将过滤后特征图再通过组点卷积过滤,一般而言这种方式虽然能够过滤掉没用的信息,但同时也会过滤掉有用的信息。通过与输入数据加和,以防止有用信息被过滤掉。
为减少计算量,通过将组深度可分离卷积的滑动间隔stride由1修改成图13混洗模块(b)中的2,再利用平均池化层下采样输入特征属性,最终通过将得到的特征图进行通道级联,取代图13(a)混洗模块的特征图求和,虽然通道级联增加了通道的维度,但由于下采样减少了平面维度,导致计算成本并未增加很多。通过实验发现,此方式能够显著降低网络所需的计算性能,而网络的效果并没有显著降低。而第二代ShuffleNet v2[20]网络指出了以往架构过于注重FLOPs的不足,提出了两个基本的原则和四项准则指导网络架构设计,其无论在速度还是精确度上,都超过以往通过压缩卷积核计算要求的算法。
深度可分离卷积的keras实现
由于tensorflow不支持卷积通道的shuffle操作,仅仅支持深度可分离卷积操作,所以介绍MobeilNet中的经典卷积网络如何变成可分离卷积网络的API
- 一个经典网络的keras的api如下所示:
layers.Conv2D(filters=num_filter, kernel_size=kernel_size, strides=stride, padding=padding, use_bias=False, name=conv_name)(x)
将这个网络分解成在通道层面的卷积以及平面上的的卷积方式,一个是直接设置kernel_size为1,代表点卷积,而另一个api,backend.depthwise_conv2d代表深度卷积操作,两者配合使用能够实现一个深度可分离卷积。
outputs = backend.depthwise_conv2d(
inputs,
self.depthwise_kernel,
strides=self.strides,
padding=self.padding,
dilation_rate=self.dilation_rate,
data_format=self.data_format)
需要注意的是,如果使用caffe实现一个深度可分离卷积,官方版本的深度可分离卷积使用for循环代表在通道维度上分别进行卷积,将造成大量的时间损耗,性能往往比不用深度可分离卷积还慢,为了放着这种情况,最好使用第三方重实现的深度可分离卷积。
量化模型
神经网络发展到现在,已经证明了越深越宽的模型拥有越高的精确度,但所对应的计算资源要求也越高,近年来,边缘计算兴起,降低模型的计算资源也是我们需要做的
模型量化具体是以较低的精确度损失将通常精度(float32)转换为较低精度(float16、int8)以减少模型大小、计算资源消耗等。具体介绍可以知乎上搜索模型量化,比百度所搜更加全面。本文仅仅介绍tensorflow的量化实现。
tensorflow训练后量化
使用tensorflow的keras的api能够直接将训练好的模型进行量化。tensorflow量化有集中选择(float16,int8)。介绍比较全面及其keras的实现细节可以参考https://zhuanlan.zhihu.com/p/79744430。
keras的用法具体操作可以查看https://github.com/wangrui1996/tensorflow_insightface,是一个人脸识别keras的实现,目前精确度lfw上达到了%98.7,将keras模型装换成tensorflow-lite的脚本在https://github.com/wangrui1996/tensorflow_insightface/blob/master/tools/tf2_convert.py下,安卓机上能够直接调用,相关安卓机上使用的方法将预计最近更新到项目中。
以下了解即可
剪支和参数共享
- 参数共享在卷积网络上用于降低计算量和减少参数,最开始的剪枝应用便是dropout,它通过随机剪枝防止过拟合并加速训练,当然也可以用来降低参数量。
早期的剪枝方式通过权重的重要性剪枝方法进行分结构化剪枝[21],删除不重要的权重参数重新进行训练,直到达到满意的模型大小,并且模型效果没发生显著改变。随后提出的基于偏差权重衰减的最优脑损伤和最优脑手术方法,是通过减少损失函数的海森矩阵来减少连接数量。研究表明剪枝方式的精确度比重要性剪枝方式好。然而此方式的剪枝并不能应用于实际卷积网络层上,因为此类方法导致剪枝后的权值矩阵是无规则稀疏的,其仅仅将剪枝后的权重设置成0,输入和0相乘也是消耗计算量的,因此实际加速效果较低。只有剪掉的枝叶从搭建的网络中消失,才算完成剪枝。通过结构化剪枝可以使剪枝后的模型能够运行于实际场景中。与非结构化剪枝不相同的是,结构化剪枝设置了一系列的剪枝约束条件。根据细粒度的程度,结构化剪枝可以分为向量机剪枝、核级剪枝、组级剪枝和通道级剪枝四种类型。通过结构化剪枝能够直接降低模型的计算FLOPS。
知识蒸馏
正如Hinto提出来的一个例子[22],幼小的昆虫擅长从环境中汲取能量,而成年后则擅长迁徙繁殖等方面。与这个例子相同的是,在训练阶段,神经网络能够从大量数据中训练模型网络;使用阶段,则能够应用于更加严格的包括计算资源及计算速度的限制。一般首先在大数据集上训练一个复杂网络模型,一旦网络模型训练完成,便可以通过“蒸馏”方式,从大型模型中将所需要的应用模型提取出来。知识蒸馏中,软目标是通过复杂模型预测得到的概率分布,硬目标则是真实样本的概率。参考复杂模型的结构、深度等信息重新设计一个小模型,再将小模型的预测值分别与软目标和硬目标做交叉熵的损失,并将两部分损失进行联合训练。软目标与硬目标的综合训练损失所占的比重不断地由9:1通过迭代训练慢慢变成1:0。对于卷积网络,一般通过类别的shot-hot码进行训练,相当于使用硬目标进行训练。总而言之,将复杂模型预测得到的数据作为小模型的样本标签,对网络加以训练,以增加网络的泛化能力。
权值张量低秩分解
卷积网络核的参数权重W可以看作是一个四维张量,他们分别对应于卷积核的长、宽、通道数以及输出通道数。通过合并某些维度,四维张量能够转变成更小维度的张量。基于权值张量低秩分解方法,其实质是找到与张量W近似、但计算量更小的张量。现阶段已经有很多低秩分解算法被提出,例如优必选悉尼AI研究院入选CVPR的基于低秩稀疏分解的深度压缩模型。
3.5轻量级网络模型设计
在卷积网络模型中,合并网络层不改变网络输出是重要模型的优化方式。例如,BatchNorm层(简称BN层)在深度学习中归一化网络模型加速训练,放置于卷积层或全连接层之后。测试时,通过将BN层合并到卷积层或全连接层中以减少计算量。















 11万+
11万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









