







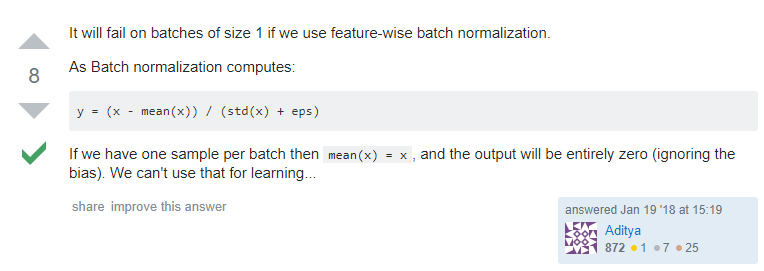
(1) ValueError: Expected more than 1 value per channel when training, got input size [1, 512, 1, 1]
原因:如果使用了 BatchNorm ,则不能把 batchsize 设置为1。
解决:更改 bath size 不为 1 即可。
(2) raise batch.exc_type(batch.exc_msg)
原因:torch 在训练一个 batch 的数据时,组织形式为 N*C*H*W,也就是说需要这一个 batch 的图像同样大小。
解决:我的解决方案是在数据做 transform 时将它们均 crop 到同一个大小。

(3) RuntimeError: unexpected EOF. The file might be corrupted.
原因:这是由于模型损坏或不完整。
(4) RuntimeError: Expected object of type torch.FloatTensor but found type torch.cuda.FloatTensor for argument #3 'other'
原因:这是说需要将数据放在 GPU 上而你的数据仍然在 CPU,只需要给报错的数据转换一下位置,.cuda() 就可以了。
解决:x.cuda()
在数据类型转换 x= torch.FloatTensor(x) 时报错:
(5) TypeError: can't convert np.ndarray of type numpy.float128. The only supported types are: double, float, float16, int64, int32, and uint8.
原因:torch.FloatTensor() 不支持对 np.float128 类型进行转换。
解决:按照错误提示,先使用 numpy.ndarray.astype 将 Numpy 数组转换为 double,float,float16,int64,int32 或 uint8 类型,然后再转换即可。
错误信息:
(6) RuntimeError: cuda runtime error (11) : invalid argument at /pytorch/aten/src/THC/THCGeneral.cpp:405
参考:
https://discuss.pytorch.org/t/a-error-when-using-gpu/32761
原因:
- 多GPU测试
- PyTorch版本与显卡不兼容
在这里我的报错是由于后者,我的显卡是 RTX2080(Ti),PyTorch 1.0,如果换成 RTX1080(Ti)就没有问题,比较简单的解决方案是,将 python 文件中的 torch.backends.cudnn.benchmark = True 设置成 False,即可得到一个静态 CUDA error,此时虽然报错但并不影响后面的运行。















 392
392











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











