







卷积神经网络(CNN)介绍
传统CNN的强大之处就在于它的多层结构能自动学习特征,并且可以学习到多个层次的特征:较浅的卷积层感知域较小,学习到一些局部特征;较深的卷积层感知域较大,能够学习到更加抽象的特征。这些抽象特征对物体的方向、大小、位置等敏感性更低,从而有助于识别性能的提高。
缺点:抽象的特征对分类很有帮助,可以判断出一幅图像中的物体属于哪一类。但由于抽象特征丢失了物体的一些细节,不能很好地给出物体的具体轮廓,无法指出每个像素具体属于哪个物体,因此做到精确的分割就很有难度。
全卷积神经网络(FCN)的提出
提出目标:从图像级别的分类进一步延展到像素级别的分类(即:从单目标分类变成多目标分类)
最开始的应用:图像分割
贡献:端到端、像素到像素、输入尺寸与输出尺寸一样大小
- 网络模型设计
网络模型
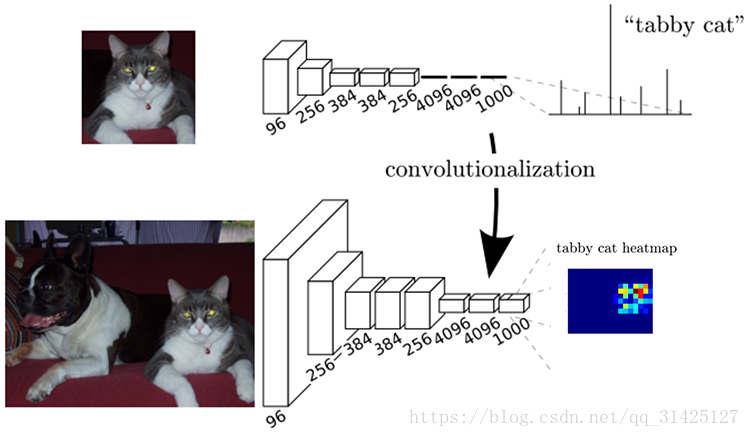
上幅图片中的第一个模型是AlexNet,第一次经过卷积池化后图片尺寸变小为输入的1/2,通道数变成96;第二次卷积池化后图片尺寸再一次变小为输入的1/4,通道数变成256;第三次、第四次……;第六次为全连接层,经过多次卷积后,将特征图的权值展开为1维与全连接的权值实现全连接,变成向量4096x1;最后使用softmax输出类别,因为标签有1000个类别,所以最后输出大小必须为1000x1,与标签相对应,以便做误差损失回传更新网络参数。
第二个模型就是FCN,前面的卷积层与AlexNet一样,区别就在于全连接层,FCN把全连接层全部替换成卷积层:
- 针对第一个连接区域是[7x7x512]的全连接层,令其滤波器尺寸为F=7,这样输出数据体就为[1x1x4096]了。
- 针对第二个全连接层,令其滤波器尺寸为F=1,这样输出数据体为[1x1x4096]。
- 对最后一个全连接层也做类似的,令其F=1,最终输出为[1x1x1000]
最后一层的1000可改,根据不同数据集的类别作相应修改。
二者区别:
(由单一分类到多分类,由粗糙分类到精细分类)
AlexNet的输出是一个1000维的向量,哪个值高代表输入图片属于该值对应的类别,它实现的是单一类别图片分类的功能。
FCN的输出是一个和输入同样大小的图片,FCN能判断输入图片中的物体有哪几类并把他们正确分类,它实现的是多类别图片归类的功能。
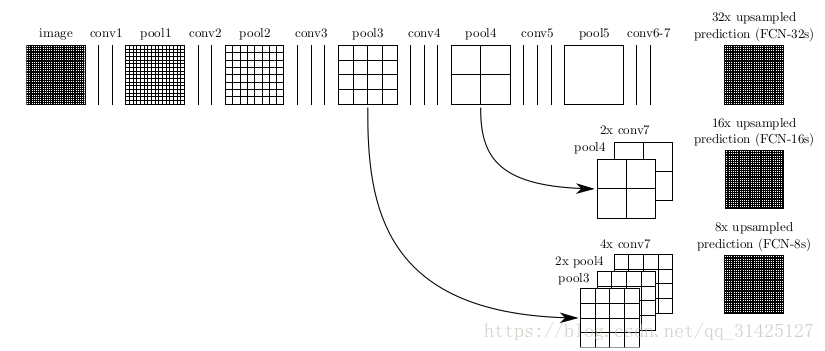
对原图像进行卷积conv1、pool1后原图像缩小为1/2;之后对图像进行第二次conv2、pool2后图像缩小为1/4;接着继续对图像进行第三次卷积操作conv3、pool3缩小为原图像的1/8,此时保留pool3的featureMap;接着继续对图像进行第四次卷积操作conv4、pool4,缩小为原图像的1/16,保留pool4的featureMap;最后对图像进行第五次卷积操作conv5、pool5,缩小为原图像的1/32,然后把原来CNN操作中的全连接变成卷积操作conv6、conv7,图像的featureMap数量改变但是图像大小依然为原图的1/32
那么图1和图2有什么关系呢?
图1结构的代码&#x
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 123
123











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









