







系统唯一ID是我们在设计一个系统的时候常常会遇见的问题,也常常为这个问题而纠结。生成ID的方法有很多,适应不同的场景、需求以及性能要求。所以有些比较复杂的系统会有多个ID生成的策略。下面就介绍一些常见的ID生成策略。
1. 数据库自增长序列或字段
最常见的方式。利用数据库,全数据库唯一。
优点:
1)简单,代码方便,性能可以接受。
2)数字ID天然排序,对分页或者需要排序的结果很有帮助。
缺点:
1)不同数据库语法和实现不同,数据库迁移的时候或多数据库版本支持的时候需要处理。
2)在单个数据库或读写分离或一主多从的情况下,只有一个主库可以生成。有单点故障的风险。
3)在性能达不到要求的情况下,比较难于扩展。
4)如果遇见多个系统需要合并或者涉及到数据迁移会相当痛苦。
5)分表分库的时候会有麻烦。
优化方案:
1)针对主库单点,如果有多个Master库,则每个Master库设置的起始数字不一样,步长一样,可以是Master的个数。比如:Master1 生成的是 1,4,7,10,Master2生成的是2,5,8,11 Master3生成的是 3,6,9,12。这样就可以有效生成集群中的唯一ID,也可以大大降低ID生成数据库操作的负载。
2. UUID
常见的方式。可以利用数据库也可以利用程序生成,一般来说全球唯一。
优点:
1)简单,代码方便。
2)生成ID性能非常好,基本不会有性能问题。
3)全球唯一,在遇见数据迁移,系统数据合并,或者数据库变更等情况下,可以从容应对。
缺点:
1)没有排序,无法保证趋势递增。
2)UUID往往是使用字符串存储,查询的效率比较低。
3)存储空间比较大,如果是海量数据库,就需要考虑存储量的问题。
4)传输数据量大
5)不可读。
3. UUID的变种
1)为了解决UUID不可读,可以使用UUID to Int64的方法。及
// 根据GUID获取唯一数字序列
public static long GuidToInt64()
{
byte[] bytes = Guid.NewGuid().ToByteArray();
return BitConverter.ToInt64(bytes, 0);
}2)为了解决UUID无序的问题,NHibernate在其主键生成方式中提供了Comb算法(combined guid/timestamp)。保留GUID的10个字节,用另6个字节表示GUID生成的时间(DateTime)
private Guid GenerateComb()
{
byte[] guidArray = Guid.NewGuid().ToByteArray();
DateTime baseDate = new DateTime(1900, 1, 1);
DateTime now = DateTime.Now;
// Get the days and milliseconds which will be used to build
//the byte string
TimeSpan days = new TimeSpan(now.Ticks - baseDate.Ticks);
TimeSpan msecs = now.TimeOfDay;
// Convert to a byte array
// Note that SQL Server is accurate to 1/300th of a
// millisecond so we divide by 3.333333
byte[] daysArray = BitConverter.GetBytes(days.Days);
byte[] msecsArray = BitConverter.GetBytes((long)
(msecs.TotalMilliseconds / 3.333333));
// Reverse the bytes to match SQL Servers ordering
Array.Reverse(daysArray);
Array.Reverse(msecsArray);
// Copy the bytes into the guid
Array.Copy(daysArray, daysArray.Length - 2, guidArray,
guidArray.Length - 6, 2);
Array.Copy(msecsArray, msecsArray.Length - 4, guidArray,
guidArray.Length - 4, 4);
return new Guid(guidArray);
}用上面的算法测试一下,得到如下的结果:作为比较,前面3个是使用COMB算法得出的结果,最后12个字符串是时间序(统一毫秒生成的3个UUID),过段时间如果再次生成,则12个字符串会比图示的要大。后面3个是直接生成的GUID。
C")
如果想把时间序放在前面,可以生成后改变12个字符串的位置,也可以修改算法类的最后两个Array.Copy。
4. Redis生成ID
当使用数据库来生成ID性能不够要求的时候,我们可以尝试使用Redis来生成ID。这主要依赖于Redis是单线程的,所以也可以用生成全局唯一的ID。可以用Redis的原子操作 INCR和INCRBY来实现。
可以使用Redis集群来获取更高的吞吐量。假如一个集群中有5台Redis。可以初始化每台Redis的值分别是1,2,3,4,5,然后步长都是5。各个Redis生成的ID为:
A:1,6,11,16,21
B:2,7,12,17,22
C:3,8,13,18,23
D:4,9,14,19,24
E:5,10,15,20,25
这个,随便负载到哪个机确定好,未来很难做修改。但是3-5台服务器基本能够满足器上,都可以获得不同的ID。但是步长和初始值一定需要事先需要了。使用Redis集群也可以方式单点故障的问题。
另外,比较适合使用Redis来生成每天从0开始的流水号。比如订单号=日期+当日自增长号。可以每天在Redis中生成一个Key,使用INCR进行累加。
优点:
1)不依赖于数据库,灵活方便,且性能优于数据库。
2)数字ID天然排序,对分页或者需要排序的结果很有帮助。
缺点:
1)如果系统中没有Redis,还需要引入新的组件,增加系统复杂度。
2)需要编码和配置的工作量比较大。
5. Twitter的snowflake算法(雪花算法)
snowflake是Twitter开源的分布式ID生成算法,结果是一个long型的ID。其核心思想是:使用41bit作为毫秒数,下图中1010bit作为机器的ID(5个bit是数据中心,5个bit的机器ID),12bit作为毫秒内的流水号(意味着每个节点在每毫秒可以产生 4096 个 ID),最后还有一个符号位,永远是0。

java代码如下:
import java.lang.management.ManagementFactory;
import java.net.InetAddress;
import java.net.NetworkInterface;
/**
* <p>名称:IdWorker.java</p>
* <p>描述:分布式自增长ID</p>
* <pre>
* Twitter的 Snowflake JAVA实现方案
* </pre>
* 核心代码为其IdWorker这个类实现,其原理结构如下,分别用一个0表示一位,用—分割开部分的作用:
* 1||0---0000000000 0000000000 0000000000 0000000000 0 --- 00000 ---00000 ---000000000000
* 在上面的字符串中,第一位为未使用(实际上也可作为long的符号位),接下来的41位为毫秒级时间,
* 然后5位datacenter标识位,5位机器ID(并不算标识符,实际是为线程标识),
* 然后12位该毫秒内的当前毫秒内的计数,加起来刚好64位,为一个Long型。
* 这样的好处是,整体上按照时间自增排序,并且整个分布式系统内不会产生ID碰撞(由datacenter和机器ID作区分),
* 并且效率较高,经测试,snowflake每秒能够产生26万ID左右,完全满足需要。
* <p>
* 64位ID (42(毫秒)+5(机器ID)+5(业务编码)+12(重复累加))
*
* @author Polim
*/
public class IdWorker {
// 时间起始标记点,作为基准,一般取系统的最近时间(一旦确定不能变动)
private final static long twepoch = 1288834974657L;
// 机器标识位数
private final static long workerIdBits = 5L;
// 数据中心标识位数
private final static long datacenterIdBits = 5L;
// 机器ID最大值
private final static long maxWorkerId = -1L ^ (-1L << workerIdBits);
// 数据中心ID最大值
private final static long maxDatacenterId = -1L ^ (-1L << datacenterIdBits);
// 毫秒内自增位
private final static long sequenceBits = 12L;
// 机器ID偏左移12位
private final static long workerIdShift = sequenceBits;
// 数据中心ID左移17位
private final static long datacenterIdShift = sequenceBits + workerIdBits;
// 时间毫秒左移22位
private final static long timestampLeftShift = sequenceBits + workerIdBits + datacenterIdBits;
private final static long sequenceMask = -1L ^ (-1L << sequenceBits);
/* 上次生产id时间戳 */
private static long lastTimestamp = -1L;
// 0,并发控制
private long sequence = 0L;
private final long workerId;
// 数据标识id部分
private final long datacenterId;
public IdWorker(){
this.datacenterId = getDatacenterId(maxDatacenterId);
this.workerId = getMaxWorkerId(datacenterId, maxWorkerId);
}
/**
* @param workerId
* 工作机器ID
* @param datacenterId
* 数据中心编号
*/
public IdWorker(long workerId, long datacenterId) {
if (workerId > maxWorkerId || workerId < 0) {
throw new IllegalArgumentException(String.format("worker Id can't be greater than %d or less than 0", maxWorkerId));
}
if (datacenterId > maxDatacenterId || datacenterId < 0) {
throw new IllegalArgumentException(String.format("datacenter Id can't be greater than %d or less than 0", maxDatacenterId));
}
this.workerId = workerId;
this.datacenterId = datacenterId;
}
/**
* 获取下一个ID
*
* @return
*/
public synchronized long nextId() {
long timestamp = timeGen();
if (timestamp < lastTimestamp) {
throw new RuntimeException(String.format("Clock moved backwards. Refusing to generate id for %d milliseconds", lastTimestamp - timestamp));
}
if (lastTimestamp == timestamp) {
// 当前毫秒内,则+1
sequence = (sequence + 1) & sequenceMask;
if (sequence == 0) {
// 当前毫秒内计数满了,则等待下一秒
timestamp = tilNextMillis(lastTimestamp);
}
} else {
sequence = 0L;
}
lastTimestamp = timestamp;
// ID偏移组合生成最终的ID,并返回ID
long nextId = ((timestamp - twepoch) << timestampLeftShift)
| (datacenterId << datacenterIdShift)
| (workerId << workerIdShift) | sequence;
return nextId;
}
private long tilNextMillis(final long lastTimestamp) {
long timestamp = this.timeGen();
while (timestamp <= lastTimestamp) {
timestamp = this.timeGen();
}
return timestamp;
}
private long timeGen() {
return System.currentTimeMillis();
}
/**
* <p>
* 获取 maxWorkerId
* </p>
*/
protected static long getMaxWorkerId(long datacenterId, long maxWorkerId) {
StringBuffer mpid = new StringBuffer();
mpid.append(datacenterId);
String name = ManagementFactory.getRuntimeMXBean().getName();
if (!name.isEmpty()) {
/*
* GET jvmPid
*/
mpid.append(name.split("@")[0]);
}
/*
* MAC + PID 的 hashcode 获取16个低位
*/
return (mpid.toString().hashCode() & 0xffff) % (maxWorkerId + 1);
}
/**
* <p>
* 数据标识id部分
* </p>
*/
protected static long getDatacenterId(long maxDatacenterId) {
long id = 0L;
try {
InetAddress ip = InetAddress.getLocalHost();
NetworkInterface network = NetworkInterface.getByInetAddress(ip);
if (network == null) {
id = 1L;
} else {
byte[] mac = network.getHardwareAddress();//如果这行ide显示错误,请检查编译版本(1.6以上才行)
id = ((0x000000FF & (long) mac[mac.length - 1])
| (0x0000FF00 & (((long) mac[mac.length - 2]) << 8))) >> 6;
id = id % (maxDatacenterId + 1);
}
} catch (Exception e) {
System.out.println(" getDatacenterId: " + e.getMessage());
}
return id;
}
public static void main(String[] args) {
IdWorker idWorker=new IdWorker(0,0);
for(int i=0;i<100;i++){
long nextId = idWorker.nextId();
System.out.println(nextId);
}
}
}数据中心编号以及机器编号:这只是一个逻辑上的划分,并非要真正在机器上打上标签。比如可以把A模块定义为数据中心1,其下集群中的每个服务器实例就为机器编号,你可以按照自然数区分,编号自己定,别重复就行。真正运用的时候,这个编号应该是事先都已经规划好的,并将这两个编号写入项目的配置文件中,在项目中调用snowFlake算法的时候,读取当前项目的数据中心编号以及机器编号
可以看到以上main方法中调用的时候传入了两个参数正式数据中心编号以及机器编号,共计10个bit位,所以可以保证在正确区分服务器编号及所属数据中心的情况下,最多可以满足2的十次方即1024台规模的集群环境,永不重复的id。
优点:
1)不依赖于数据库,灵活方便,且性能优于数据库。
2)ID按照时间在单机上是递增的。
缺点:
1)在单机上是递增的,但是由于涉及到分布式环境,每台机器上的时钟不可能完全同步,也许有时候也会出现不是全局递增的情况,而且集群环境超过1024台,这个算法理论上将不能保证100%不重复。
6. 利用zookeeper生成唯一ID
zookeeper主要通过其znode数据版本来生成序列号,可以生成32位和64位的数据版本号,客户端可以使用这个版本号来作为唯一的序列号。很少会使用zookeeper来生成唯一ID。主要是由于需要依赖zookeeper,并且是多步调用API,如果在竞争较大的情况下,需要考虑使用分布式锁。因此,性能在高并发的分布式环境下,也不甚理想。 7. MongoDB的ObjectIdMongoDB的ObjectId和snowflake算法类似。它设计成轻量型的,不同的机器都能用全局唯一的同种方法方便地生成它。MongoDB 从一开始就设计用来作为分布式数据库,处理多个节点是一个核心要求。使其在分片环境中要容易生成得多。其格式如下:
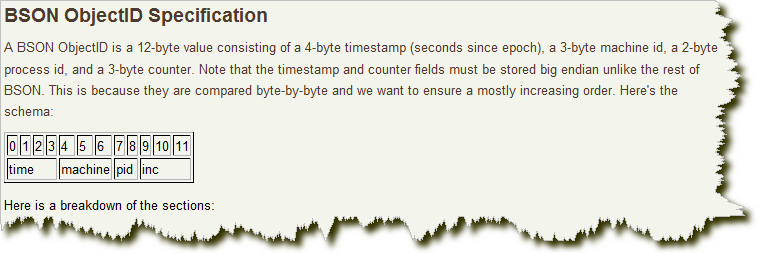
前4 个字节是从标准纪元开始的时间戳,单位为秒。时间戳,与随后的5 个字节组合起来,提供了秒级别的唯一性。由于时间戳在前,这意味着ObjectId 大致会按照插入的顺序排列。这对于某些方面很有用,如将其作为索引提高效率。这4 个字节也隐含了文档创建的时间。绝大多数客户端类库都会公开一个方法从ObjectId 获取这个信息。
接下来的3 字节是所在主机的唯一标识符。通常是机器主机名的散列值。这样就可以确保不同主机生成不同的ObjectId,不产生冲突。
为了确保在同一台机器上并发的多个进程产生的ObjectId 是唯一的,接下来的两字节来自产生ObjectId 的进程标识符(PID)。
前9 字节保证了同一秒钟不同机器不同进程产生的ObjectId 是唯一的。后3 字节就是一个自动增加的计数器,确保相同进程同一秒产生的ObjectId 也是不一样的。同一秒钟最多允许每个进程拥有2563(16 777 216)个不同的ObjectId。
实现的源码可以到MongoDB官方网站下载。
本文转自:nick hao的博客园文章,针对snowFlake算法部分有改动。














 3530
3530











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









