




 本文详细介绍了JVM调优的各个方面,包括理解垃圾回收、选择合适的垃圾回收器、调整内存设置、监控CPU和内存使用、分析日志以及使用工具如jstat、jmap和jstack进行问题定位。强调了无测试不调优的原则,并提供了实际场景下的调优案例,如服务器升级后性能下降的问题。此外,还提到了常用工具如jvisualVM和arthas的使用,以及面对CPU100%时的排查步骤。
本文详细介绍了JVM调优的各个方面,包括理解垃圾回收、选择合适的垃圾回收器、调整内存设置、监控CPU和内存使用、分析日志以及使用工具如jstat、jmap和jstack进行问题定位。强调了无测试不调优的原则,并提供了实际场景下的调优案例,如服务器升级后性能下降的问题。此外,还提到了常用工具如jvisualVM和arthas的使用,以及面对CPU100%时的排查步骤。
前言
JVM调优并没有想象的那么可怕,但是也需要你掌握前置必须的知识。比如:垃圾是什么、找到垃圾的方式、常见的垃圾回收器、回收垃圾的算法。
本篇文章以概括的方式说明1、什么是JVM调优,2、有具体场景做什么。
因为线上不同业务各种情况千奇百怪,往往调优是因为出现问题了才进行的,往往难点是定位到具体的问题所在。
什么是JVM调优
- 根据需求进行JVM规划和预调优
- 优化运行JVM运行环境
- 解决JVM运行过程中出现的各种问题(OOM)
记住两点
- 无测试不调优
- 没有实际场景的调优,都是耍流氓
更具体一点说明
1、熟悉业务场景,根据业务场景选择适合的组合
2、计算内存需求
-有时候并不是内存越大越好:
在jdk1.8默认的配置下,原1.5G内存,后升级为16G反而更慢了,为什么?
因为1.5G->16G如果没有其他更改,只会减慢FGC的时间,而当要进行一次FGC时将会损耗更多时间。本来只有一间小屋子要打扫,后面变成一栋楼,装满垃圾的时间变长了,但是打扫一次的时间也变长了。[PS + PO]
3、CPU[核数越高越好]
4、设定年代大小、升级年龄
5、设置日志参数
1. -Xloggc:/opt/xxx/logs/xxx-xxx-gc-%t.log -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=5 -XX:GCLogFileSize=20M -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+PrintGCCause
6、日志分析(每种回收器的日志格式是不同的,下面是PS+PO)

[GC (Allocation Failure) [PSYoungGen: 5551K->288K(6144K)] 10671K->10528K(19968K), 0.0037589 secs] [Times: user=0.00 sys=0.01, real=0.00 secs]
PSYoungGen 年轻代收集器
5551K->288K(6144K) 收集前后对比
10671K->10528K(19968K)整个堆的情况
19968K整个堆大小
垃圾回收器的组合
吞吐量:用户代码执行时间/(用户代码执行时间+垃圾回收时间)
响应时间:STW越短越好(一般指的是PS+PO(Parallel Scavenge + parallel Old,jdk8默认的垃圾回收)
1、Parallel new + CMS【停顿时间短】
2、Parallel Scavenge + Parallel Old【吞吐量好】
3、G1
4、ZGC…
常用参数
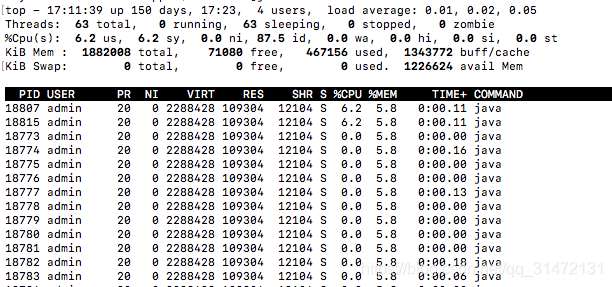
top
top -Hp pid
查看该进程下的所有线程,看哪个线程异常
jmap
1、jmap -histo pid | head -20
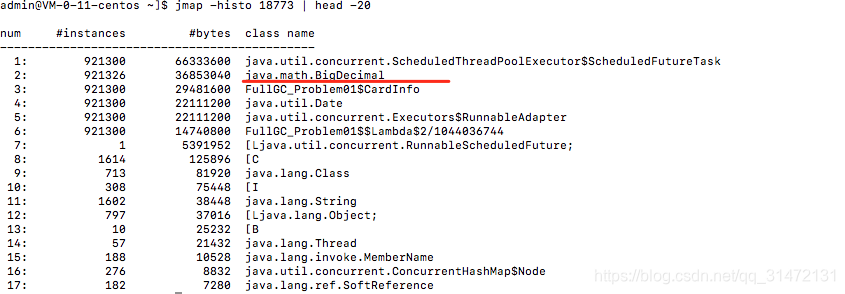
打印出对象产生top20,发现BigDecimal有异常
2、【⚠️线上慎用】
jmap -dump:format
jstack
jstack -l pid
打印堆栈信息[注意⚠️:这里执行命令的用户要和进程用户一致]
重点看WAITING BLOCKED
找到是哪个线程占有锁
这就是为什么阿里规范里规定,线程的名称(尤其是线程池)都要写有意义的名称
怎么样自定义线程池里的线程名称?(自定义ThreadFactory)
常用工具
jstat、top、jvisualVM、jprofiler、arthas
一段代码
[图]
递归导致不停的FGC,主要说明如何定位问题,通过命令发现数量异常的对象
案例说明
- 有一个资料类型网站(从磁盘提取文件当到内存)原服务器32位,1.5G的堆,用户反馈说网站反应比较缓慢,公司决定升级配置。新服务器为64位,16G的堆,结果非但没有优化,反而更加卡顿,效率更低。
原因分析:
1、原服务器为什么慢,数据要dump到内存,内存太小,访问量多的情况下导致频繁GC,STW长自然就感觉响应慢。
2、新服务器为什么不好使?内存越大。FGC一次的时间就越久。
3、看一下项目配置的JVM垃圾回收器是PS+PO,于是我们可以更变为parNew + CMS或者G1。
ps:因为内存已经到了16G这时候PS+PO他都避免不了FGC带来的超长时停。 - 系统动不动就cpu100%,怎么办?
首先可以确认cpu100%一定有线程在占用系统资源,那这时候上面的组合拳就用得上了:
1、查看是哪个进程异常(top)
2、查看进程下的哪个线程异常(top -Hp pid)
3、导出线程的堆栈(jstack)
4、查找是哪个栈帧在耗时(jstack)
5、工作线程占比高||垃圾回收线程占比高
如果发现没有什么死锁之类的,那就需要dump下来堆内存分析(jmap)
这里推荐使用jvisualvm、arthas,下一章会说明具体的分析、使用方式。
参考资料
- https://blogs.oracle.com/jonthecollector/our-collectors
- https://docs.oracle.com/javase/8/docs/technotes/tools/unix/java.html
- http://java.sun.com/javase/technologies/hotspot/vmoptions.jsp
- JVM调优参考文档:https://docs.oracle.com/en/java/javase/13/gctuning/introduction-garbage-collection-tuning.html#GUID-8A443184-7E07-4B71-9777-4F12947C8184
- https://www.cnblogs.com/nxlhero/p/11660854.html 在线排查工具
- https://www.jianshu.com/p/507f7e0cc3a3 arthas常用命令
- Arthas手册:
- 启动arthas java -jar arthas-boot.jar
- 绑定java进程
- dashboard命令观察系统整体情况
- help 查看帮助
- help xx 查看具体命令帮助
- 参考文章 https://www.jianshu.com/p/507f7e0cc3a3
- jmap命令参考:
- jmap -heap pid
- jmap -histo pid
- jmap -clstats pid

















 1196
1196

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









