









activemq v5.8.0 release
ActiveMQ的集群方式综述
ActiveMQ的集群方式主要由两种:Master-Slave和Broker Cluster
Master-Slave
Master-Slave方式中,只能是Master提供服务,Slave是实时地备份Master的数据,以保证消息的可靠性。当Master失效时,Slave会自动升级为Master,客户端会自动连接到Slave上工作。Master-Slave模式分为四类:Pure Master Slave、Shared File System Master Slave和JDBC Master Slave,以及Replicated LevelDB Store方式 。
Master-Slave方式都不支持负载均衡,但可以解决单点故障的问题,以保证消息服务的可靠性。
Broker Cluster
Broker Cluster主要是通过network of Brokers在多个ActiveMQ实例之间进行消息的路由。Broker Cluster模式支持负载均衡,可以提高消息的消费能力,但不能保证消息的可靠性。所以为了支持负载均衡,同时又保证消息的可靠性,我们往往会采用Msater-Slave+Broker Cluster的模式。
注意: 以下的测试均在一台机器上进行,为避免多个ActiveMQ之间在启动时发生端口冲突,需要修改每个ActiveMQ的配置文件中MQ的服务端口。如果实际部署在不同的机器,端口的修改是不必要的。Pure Master Slave方式
ActiveMQ5.8以前支持,自从Activemq5.8开始,Activemq的集群实现方式取消了传统的Pure Master Slave方式,并从Activemq5.9增加了基于zookeeper+leveldb的实现方式。
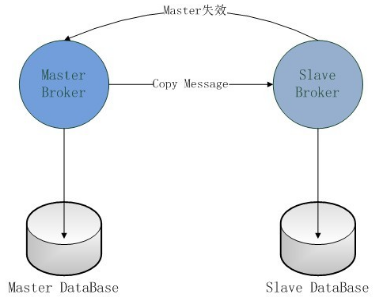
使用两个ActiveMQ服务器,一个作为Master,Master不需要做特殊的配置;另一个作为Slave,配置activemq.xml文件,在 节点中添加连接到Master的URI和设置Master失效后不关闭Slave。具体配置参考页面: http://activemq.apache.org/pure-master-slave.html
Shared File System Master Slave方式
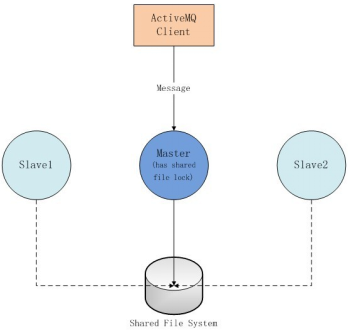
就是利用共享文件系统做ActiveMQ集群,是基于ActiveMQ的默认数据库kahaDB完成的,kahaDB的底层是文件系统。这种方式的集群,Slave的个数没有限制,哪个ActiveMQ实例先获取共享文件的锁,那个实例就是Master,其它的ActiveMQ实例就是Slave,当当前的Master失效,其它的Slave就会去竞争共享文件锁,谁竞争到了谁就是Master。这种模式的好处就是当Master失效时不用手动去配置,只要有足够多的Slave。
如果各个ActiveMQ实例需要运行在不同的机器,就需要用到分布式文件系统了。
Shared JDBC Master Slave
JDBC Master Slave模式和Shared File Sysytem Master Slave模式的原理是一样的,只是把共享文件系统换成了共享数据库。我们只需在所有的ActiveMQ的主配置文件中activemq.xml添加数据源,所有的数据源都指向同一个数据库。
然后修改持久化适配器。这种方式的集群相对Shared File System Master Slave更加简单,更加容易地进行分布式部署,但是如果数据库失效,那么所有的ActiveMQ实例都将失效。
配置修改清单
1、开启网络监控功能(useJmx=”true”)
<broker xmlns="http://activemq.apache.org/schema/core" brokerName="localhost" dataDirectory="${activemq.data}" useJmx="true">
</broker>
2、数据库持久化配置,注释掉之前kahadb消息存储器
<persistenceAdapter>
<jdbcPersistenceAdapter dataDirectory="${activemq.data}" dataSource="#mysql-ds" createTablesOnStartup="false" useDatabaseLock="true"/>
</persistenceAdapter>
3、增加数据源mysql-ds
4、修改客户端上连接url为类似于failover:(tcp://0.0.0.0:61616,tcp://0.0.0.0:61617,tcp://0.0.0.0:61618)?randomize=false
注:默认情况下,failover机制从URI列表中随机选择出一个URI进行连接,这可以有效地控制客户端在多个broker上的负载均衡,但是,要使客户端首先连接到主节点,并在主节点不可用时只连接到辅助备份代理,需要设置randomize = false。
5、可以看到只有一台MQ成为Master,其余两台成为slave并会尝试成为Master,并不断重试。且两台slave的管理控制台将无法访问。
测试方法
- 先启动生产者,发送几条消息
- 启动消费者,可看到接收到的消息
- 关闭消费者
- 生产者继续发送几条消息-消息A
- 停止broker01(可看到生产者端显示连接到broker02(tcp://0.0.0.0:61617)了,同时运行broker02的Shell也显示其成为了Master)
- 生产者继续发送几条消息-消息B
- 启动消费者
- 消费者接收了消息A和消息B,可见broker02接替了broker01的工作,而且储存了之前生产者经过broker01发送的消息
- 关闭消费者
- 生产者继续发送几条消息-消息C
- 停止broker02(可看到生产者端显示连接到broker03(tcp://0.0.0.0:61618)了,同时运行broker03的Shell也显示其成为了Master)
- 生产者继续发送几条消息-消息D
- 启动消费者
- 消费者接收了消息C和消息D,可见broker03接替了broker02的工作,而且储存了之前生产者经过broker02发送的消息
- 再次启动broker01,生产者或消费者均未显示连接到broker01(tcp://0.0.0.0:61616),表明broker01此时只是个Slave
Replicated LevelDB Store
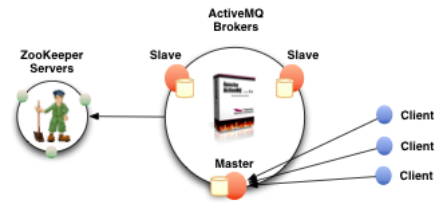
ActiveMQ5.9以后才新增的特性,使用ZooKeeper协调选择一个node作为master。被选择的master broker node开启并接受客户端连接。 其他node转入slave模式,连接master并同步他们的存储状态。slave不接受客户端连接。所有的存储操作都将被复制到连接至Master的slaves。
如果master死了,得到了最新更新的slave被允许成为master。推荐运行至少3个replica nodes。
配置修改清单
1、使用性能比较好的LevelDB替换掉默认的KahaDB
<persistenceAdapter>
<replicatedLevelDB
directory="${activemq.data}/leveldb"
replicas="3"
bind="tcp://0.0.0.0:62623"
zkAddress="127.0.0.1:2181"
hostname="localhost"
zkPath="/activemq/leveldb-stores"/>
</persistenceAdapter>
配置项说明:
- directory:持久化数据存放地址
- replicas:集群中节点的个数
- bind:集群通信端口
- zkAddress:ZooKeeper集群地址
- hostname:当前服务器的IP地址,如果集群启动的时候报未知主机名错误,那么就需要配置主机名到IP地址的映射关系。
- zkPath:ZooKeeper数据挂载点
2、修改客户端上连接url为failover:(tcp://0.0.0.0:61616,tcp://0.0.0.0:61617,tcp://0.0.0.0:61618)?randomize=false
3、可以看到只有一台MQ成为Master,其余两台成为slave。且两台slave的管理控制台将无法访问。
LevelDB解释
Leveldb是一个google实现的非常高效的kv数据库,目前的版本1.2能够支持billion级别的数据量了。 在这个数量级别下还有着非常高的性能,采用单进程的服务,性能非常之高,在一台4核Q6600的CPU机器上,每秒钟写数据超过40w,而随机读的性能每秒钟超过10w。由此可以看出,具有很高的随机写,顺序读/写性能,但是随机读的性能很一般,也就是说,LevelDB很适合应用在查询较少,而写很多的场景。LevelDB应用了LSM (Log Structured Merge) 策略,通过一种类似于归并排序的方式高效地将更新迁移到磁盘,降低索引插入开销。
限制:1、非关系型数据模型(NoSQL),不支持sql语句,也不支持索引;2、一次只允许一个进程访问一个特定的数据库;3、没有内置的C/S架构,但开发者可以使用LevelDB库自己封装一个server;
测试方法
同Shared JDBC Master Slave 测试方法
Broker Cluster
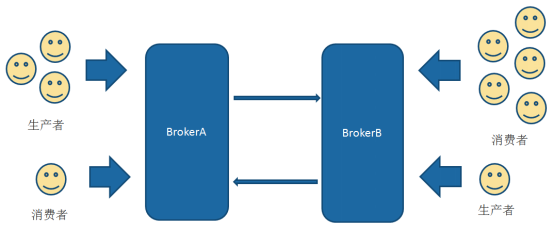
Broker-Cluster部署方式中,各个broker通过网络互相连接,并共享queue。当broker-A上面指定的queue-A中接收到一个message处于pending状态,而此时没有consumer连接broker-A时。如果cluster中的broker-B上面由一个consumer在消费queue-A的消息,那么broker-B会先通过内部网络获取到broker-A上面的message,并通知自己的consumer来消费。
Broker的集群分为Static Discovery和Dynamic Discovery两种。
Static Discovery集群
Static Discovery集群就是通过硬编码的方式使用所有已知ActiveMQ实例节点的URI地址。如:消息生产者应用连接一个ActiveMQ实例,我们暂时称为MQ1,所有的消息都由该实例提供;两个消息消费者应用分别连接另外两个ActiveMQ实例,分别为MQ2和MQ3,两个消息消费者需要消费MQ1上的消息,但它们连接的都不是MQ1,可以通过Static Discovery方式把MQ1上的消息路由到MQ2和MQ3,为了保证消费者不因某个节点的失效而导致不能消费消息,在消费者应用中需要配置所有节点的URI。
在构成集群的ActiveMQ实例的配置文件中添加networkConnectors节点,连接到生产者MQ实例。
比如集群中有四台服务器,分别在端口 61616,61617,61618,61619提供服务,,在我们的设计中,61618,61619专为消费者服务,则端口为61618和61619的服务器应该在配置文件的broker节点中增加
<networkConnectors>
<networkConnector uri="static:(tcp://localhost:61616,tcp://0.0.0.0:61617)" duplex="true"/>
</networkConnectors>
默认NetworkConnector在需要转发消息时是单向连接的。当duplex=true时,就变成了双向连接,这时配置在broker2端的指向broker1的duplex networkConnector,相当于即配置了
broker2到broker1的网络连接,也配置了broker1到broker2的网络连接。
Dynamic Discovery
Dynamic Discovery集群方式在配置ActiveMQ实例时,不需要知道所有其它实例的URI地址,只需在所有实例的activemq.xml文件中添加以下内容:
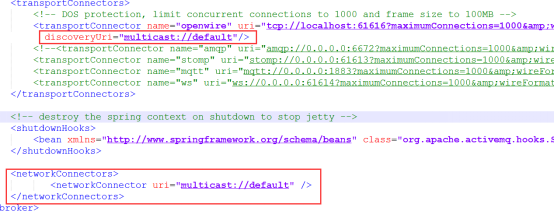
即可
可疑的ActiveMQ高可用+负载均衡集群
Master-Slave的部署方式虽然解决了高可用的问题,但不支持负载均衡,Broker-Cluster解决了负载均衡,但当其中一个Broker突然宕掉的话,那么存在于该Broker上处于Pending状态的message将会丢失,无法达到高可用的目的。
所以为了支持负载均衡,同时又保证消息的可靠性,有这么一种做法使用了Msater-Slave+Broker Cluster的模式,来同时达到这两个目的。但是在官方的文档中并未提到这种模式,而且在我的实际测试中,表现很不稳定。所以,需要慎用并严格测试。



















 1867
1867

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











