






目录
运算符:
| ** | 幂运算 |
| // | 整除运算,向下取整(-17//4=-5) |
| **= | 幂赋值 |
| not | 非运算 |
| and | 与运算 |
| or | 或运算 |
| None | 空值,填表 |
| in | 成员测试 |
| is | 测试两个对象是否是为同一个对象的引用 |
| |、^、&、<<、>>、~ | 位或、位异或、位与、左位移、右位移、取反 |
python中没有自增(i++)或自减(i--)
函数
| type()、isinstance(‘2’,str) | 判断类型 |
| input() | 从控制台输入 |
| eval() | 转换成数值表达式 |
| abs(x) | 返回x的绝对值 |
| divmod(x,y) | 同时返回商和取余(x//y,x%y) |
| pow(x, y [, z]) | 无z:x**y, 有z:( x** y)% z |
| round( x [,d ]) | 四舍五入,d是保留的小数位数,默认为0 |
| max(x1, x2, x3….)、min(x1, x2, …..) | 返回最大值最小值 |
| range( start, stop, step) | 循环体,包含start不含stop,step为步数 |
| map(function, iterable, ...) | 它用于将一个函数应用于一个可迭代对象(例如列表)的每个元素,生成一个新的可迭代对象(通常是一个迭代器)来存储结果。 |
| enumerate() | 它用于迭代一个可迭代对象(例如列表、元组或字符串)并返回迭代元素的索引及其对应的值。 |
| zip(list1, list2) | 它用于将多个可迭代对象合并成一个元组构成的迭代器 |
| filter(function, iterable) | 用于过滤可迭代对象中的元素,根据指定的函数条件保留或排除元素。filter 函数接受两个参数:一个是函数(用于指定过滤条件),另一个是可迭代对象。它返回一个由满足条件的元素组成的迭代器。 |
| enumerate(iterable, start=0) | 它用于在迭代可迭代对象(如列表、元组、字符串等)时,同时获取元素的索引和值。enumerate 函数返回一个由索引和值组成的元组构成的迭代器。 |
randon库
| seed(a=None) | 随机数种子,相同的种子会产生相同的随机数。默认为系统当前时间 |
| randint(a, b) | 产生[ a, b]之间的随机整数 |
| randrange( a=0, b, step=1) | 产生[ a, b)之间的随机整数,已step为步长 |
| random( ) | 产生[ 0.0, 1.0)之间的随机浮点数 |
| uniform( a, b) | 随机产生[ a, b]之间的随机浮点数 |
| random.sample(population, k) | 从polpulation中随机选择k个不重复的元素 |
math库函数
| math.sqrt() | 平方根 |
| math.sin() | 三角函数 |
| math.log()、math.log10()、log2() | 对数 |
| math.floor() | 向下取整 例如6.7 输出为6 |
| math.ceil() | 向上取整 6.7 输出为7 |
| math.isclose(x, y) | 两个实数是否足够接近 |
| math.factorial(x) | 阶乘 |
collections库
`collections` 模块中的 `Counter` 类是一个非常有用的计数器工具,用于统计可迭代对象中各个元素的出现次数。`Counter` 类是一个字典的子类,它将元素作为字典的键,出现次数作为相应键的值,从而提供了方便的计数和统计功能。
以下是一些 `Counter` 类的常用方法和示例用法:
1. **创建 Counter 对象:**
可以通过传入可迭代对象来创建一个 `Counter` 对象,例如列表、字符串或元组。
```python
from collections import Counter
my_list = [1, 2, 2, 3, 3, 3, 4, 4, 4, 4]
my_counter = Counter(my_list)
```
2. **元素计数:**
使用 `Counter` 对象的键来获取元素的出现次数。
```python
count = my_counter[3] # 获取元素 3 出现的次数
```
3. **most_common 方法:**
`most_common()` 方法返回计数最高的元素和它们的计数,以列表的形式返回。
```python
most_common = my_counter.most_common(2) # 获取前两个最常出现的元素及其计数
```
4. **更新计数:**
使用 `update` 方法可以更新 `Counter` 对象的计数。
```python
my_counter.update([3, 4, 5]) # 更新计数器,增加元素 3、4 和 5 的计数
```
5. **元素删除:**
使用 `del` 关键字可以从 `Counter` 中删除指定元素。
```python
del my_counter[2] # 删除元素 2 的计数
```
6. **计数的总和:**
`Counter` 对象的总计数可以通过 `sum` 函数获得。
```python
total_count = sum(my_counter.values()) # 计算总计数
```
`Counter` 类非常适合用于统计文本中单词、字符或任何其他可迭代对象中元素的出现次数,以及用于制作柱状图和频率分布图等数据可视化任务。这是Python标准库中一个强大而方便的工具,用于处理计数和统计需求。
map
map() 是一个内置的 Python 函数,它用于将一个函数应用到可迭代对象(例如列表、元组等)的每个元素,然后返回一个新的可迭代对象,其中包含了应用函数后的结果。map() 函数的基本语法如下:
map(function, iterable, ...)function:要应用到每个元素的函数。这个函数接受一个参数,并返回一个处理后的值。iterable:一个或多个可迭代对象,例如列表、元组等。
map() 函数返回一个迭代器(iterator),您通常需要将其转换为列表或其他数据结构以查看结果。以下是 map() 函数的示例和详细解释:
# 定义一个函数,将一个整数加倍
def double(x):
return x *
2 # 创建一个列表
numbers = [1, 2, 3, 4, 5]
# 使用 map() 函数将 double 函数应用到列表中的每个元素
doubled_numbers = map(double, numbers)
# 转换为列表以查看结果
doubled_numbers_list = list(doubled_numbers)
print(doubled_numbers_list)在这个示例中,我们首先定义了一个名为 double 的函数,该函数接受一个整数并将其加倍。然后,我们创建了一个包含一组整数的列表 numbers。接下来,我们使用 map() 函数将 double 函数应用到列表中的每个元素,返回一个迭代器 doubled_numbers。最后,我们将迭代器转换为列表 doubled_numbers_list,并打印结果。
输出将是 [2, 4, 6, 8, 10],因为 double 函数将每个元素加倍。
要注意的是,map() 函数通常用于对大量数据进行批处理,以便更高效地应用函数。它可以与匿名 lambda 函数结合使用,以实现更复杂的操作。例如:
numbers = [1, 2, 3, 4, 5]
# 使用 lambda 函数将列表中的每个元素加倍
doubled_numbers = map(lambda x: x * 2, numbers)
doubled_numbers_list = list(doubled_numbers)
print(doubled_numbers_list)
这个示例中,我们使用了 lambda 函数来实现与之前相同的操作。
numpy
| no.array([ ]) | 将猎捕列表转为nunpy数组 |
| np.linspace(a, b, n) | 创建等间隔数字序列(从a到b,n个数) |
| no.zeros((a, b, c....)) | 生成一个指定形状的数组,几个数就几维,元素都初始化为0 |
| np.ones((a, b, c...)) | 与zeros相似,元素初始化为1 |
| np.identity(n) | 返回一个n行n列的单位矩阵 |
| np.tile(row, (x,y) | 复制和铺平数组,第一个是要复制的数组,第二个是元组指定了沿各个轴复制的次数 |
| np.random.randint(x, y, (m, n)) | 生成随机数组,m行n列个[x,y]之间的数字 |
| np.random.rand(m, n) | m行n列[0,1)之间的随机数 |
| np.random.standard_normal(size=(x, y, z)) | 从标准正态分布中随机采样5个数字 |
| np.diag([1, 2, 3, 4]) | 对角矩阵 |
| np.allclose(x, y, rtol(atol)=z) | 判断两个数组的所有元素是否足够接近返回一个True或False,rtol设置相对误差,atol设置绝对误差 |
| np.close(x, y, rtol(atol)=z) | 判断两个数组的所有元素是否足够接近返回一个含有True或False的数组对每个数进行比较,rtol设置相对误差,atol设置绝对误差 |
| a = b、a= b[ : ] | a和b用的同一个地址 |
| a = b.copy() | a和b地址不同 |
| x1 = np.append(x2, z) | 返回新数组,在后面追加z,z可以是数组 |
| x1 = np.insert(x2, i, z) | 返回新数组,在数组i处添加z |
| x[i, j] = z | 修改第i行第j列的值 |
| x[i: , j: ] = z | 切片,同时修改多个值,行列下标均大于等于1 |
输出
print()
print ( <拟输出字符串或字符串变量>)
//使用逗号, 隔开多个输出内容,则 print 在输出时会依次打印各个字符串或变量
//会自动在行末加上回车
print(1, 2, 3, sep=" ", end="\t")
// – sep表示分隔符,end表示结尾符,分别默认是空格及换行(\n)
print(“结果是{:6.2f}”.format(a) )
// -f表示实数,i表示整数,s表示字符串,6.2表示宽度及小数位数format()方法的格式控制
{ <参数序号> : <格式控制标记> }
| : | <填充> | <对齐> | <宽度> | <,> | <.> | <类型> |
| 引导符号 | 用于填充的单个字符 | <左对齐 >右对齐 ^居中对齐 | 曹设定的输出宽度 | 数字的千位分隔符 | 浮点数小数精度或字符串最大输出长度 | 整数类型 |
print('beautiful' in text) # 测试字符串中是否包含单词beautiful
print('='*20) # 字符串重复
print('Good '+'Morning') # 字符串连接
分支语句
<表达式1> if <条件> else <表达式2>
// true执行1,flase执行2,不支持=的复制形式,支持作为语句的一部分 
pass 表示空语句,占用一个条件语句。
字符串
可以用双引号
转义字符
| \n | 换行 |
| \t | 制表符 |
| \\ | 表示\ |
相关函数
| s.upper()、s.lower() | 大写、小写 |
| s.strip()、s.lstrip()、s.rstrip() | 去首位空白、去左空白、去右空白 |
| s.replace(“old”, ”new”) | 替换 |
| s.split(“,”) | 分割 |
| s.conut( sub [, start, stop]) | 返回子串sub在str指定位置中出现的次数 |
| s.center(width [,fillchar]) | 根据宽度width居中,fillchar可选填充 |
| str.strip( chars) | 除去左侧和右侧列出的字符 |
| str.join(iter) | 在iter变量除最后元素外每个元素后增加一个str, “,”.join(“12345”)结果为”1,2,3,4,5” |
| s.find( x, start, stop ) | 查找字符串x在s指定范围内中首次出现的位置,不存在返回-1。 |
| s.rfind( x, start, stop ) | 查找在指定范围内最后一次出现的位置 |
| s.index( x, start, stop ) | 查找在指定范围内首次出现的位置,不存在抛异常 |
| s.rindix( x, start, stop ) | 最后出现的位置 |
| s.startswith( x, start, stop) s.endwith( x, start, stop ) | 判断是否事宜指定的字符串开始或者结束 |
| s.isalnum() s.isalpha() s.isdigit() s.isspace() s.isupper() s.islower() | 用来测试字符串是否为数字或字母、是否为字母、是否为数字字符、是否为空格字符、是否为大写字母以及是否为小写字母。 |
| x in y | 判断xs是否在字符串y中 |
| my_string[7:12] | 获取从索引 7 到索引 12 的子串(不包含索引 12) |
正则表达式
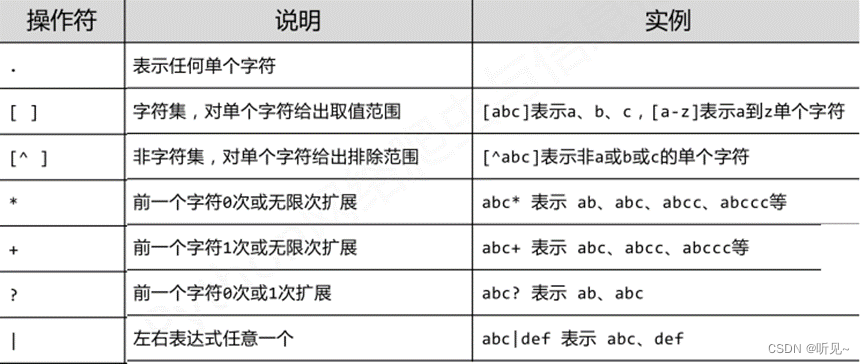

- 字符组表达式 [...] 匹配括号中列出的任一个字符
- [abc] 可以匹配字符 a 或 b 或 c
- 区间形式 [0-9] 是顺序列出的缩写,匹配所有十进制数字
- 字符 [0-9a-zA-Z] 匹配所有字母(英文字母)和数字
-
[^...] 中的 ^ 表示求补,这种模式匹配所有未在括号里列出的字符
-
[^0-9] 匹配所有非十进制数字的字符
-
[^ \t\v\n\f\r] 匹配所有非空白字符(非空格/制表符/换行符)
-
如果需要在字符组里包括 ^,就不能放在第一个位置,以免混淆含义。可以
写\^恢复其本来含义;如 果需要在字符组包括 - ],也必须写 \- 或 \]
-
\d:与十进制数字匹配,等价于 [0-9]
-
\D:与非十进制数字的所有字符匹配,等价于 [^0-9]
-
\s:与所有空白字符匹配,等价于 [ \t\v\n\f\r]
-
\S:与所有非空白字符匹配,等价于 [^ \t\v\n\f\r]
-
\w:与所有字母数字字符匹配,等价于 [0-9a-zA-Z]
-
\W:与所有非字母数字字符匹配,等价于 [^0-9a-zA-Z]
-
圆点字符 . 可以匹配任意一个字符: a..b 匹配所有以 a 开头 b 结束的四字符串
贪婪匹配
一般程序设计语言中,大多会默认正则表达式进行贪婪匹配,即可匹配的多个
互相有包含关系的时候,只匹配最大的那一个。
取消贪婪匹配模式:在产生贪婪匹配的正则表达式后加?符号。
最小匹配

首尾匹配
^与$代表的一行的开头与结束,而不是整个字符串的开头与结束。如果一个字符串中出现了多个换行符号,则模式或许可能与多个行首、行尾形成匹配。
串首匹配:\A 开头的模式只与被匹配串的前缀匹配
例如'\Acat'即只能与以'for'开头的字符串形成匹配。
串尾匹配:\Z 结束的模式只与被匹配串的后缀匹配
re模块

案列搜索网页中的学院名
import re
s=''
with open('ldu.html', 'r', encoding='utf-8') as f:
s=f.read()
p = '<A class="c259845"(.+?)>(.+?)</A>'
t = re.findall(p, s)
with open('ldu_Liyx.txt', 'w', encoding='utf-8') as f:
for e in t:
f.write(str(e[1])+'\n')
列表元组字典集合比较

列表(list)
使用[ ]创建 a=[ ], 下标从0开始
| len(a ) | 长度 |
| list( ) | 将其他类型的可迭代对象数据转化为列表 |
| a.append( )、a=a+x | 向列表尾添加元素 |
| a.insert( ) | 在指定的索引位置添加元素,越界时向头或尾添加 |
| a.extend() | 可以将另一个迭代对象的所有元素添加至列表对象尾部 |
| a.remove(“xxx”) | 删除列表中首次出现的指定元素 |
| a.pop([insex]) | 删除下表为index(默认为-1)的元素 |
| a.sort( [key, reverse ]) | 排序,默认为升序,key为排序规则, |
| a,count(x ) | x在列表中出现的次数 |
| a.index( x ) | 查找x第一次出现的下标 |
| sorted( aList, key, reucerse) | 内置函数排序,返回新列表。alist元素顺序不变 |
| reversed() | 对列表元素进行逆序排列,并返回迭代对象。 |
| len()、max()、min()、sum() | 长度、最值、求和 |
列表切片
列表名称 [ 其实索引位置 : 最后索引位置 : 步长 ]
未输入步长默认为1
列表推导式
[exp for variable in interable if condition1]
ls2 = [ k**2 k ls1] 计算ls1列表中每个元素的平方,并将结果保存到ls2列表中
ls3 = sum([ k**2 k ls2 k%2 != 0])
计算ls中所有奇数成员的平方和,结果保存到ls3中
二维列表转置
# 定义一个二维列表
matrix = [
[1, 2, 3],
[4, 5, 6],
[7, 8, 9]
]
# 使用zip和列表解析进行转置
transpose_matrix = [list(row) for row in zip(*matrix)]
元组(tuple)
元组不可变,不可用append( )、insert( )、del( )。
一个元素定义的时候加逗号
x_tuple2=(2,) #1个元素的元祖字典(dict)
字典的创建使用大括号 { } 包含键值对,并用冒号 : 分隔键和值,形成 键:值 对。
利用 for循环和zip()函数创建字典
zip()函数用于将多个序列(列表、元组等)中的元素配对。
例如:
for key, value in zip(id, name):
student_dic[key ]= value
| d.get( “ abc”) | 获取键“abc”的值,不存在返回None |
| “abc” in d | 通过in判断是否存在某个键 |
| d.keys( ) | 字典所有键 |
| d.values( ) | 字典所有值 |
| d.items( ) | 返回所有的键值对,保存在一个元组列表中 |
| del( ) | 对单一元素或整个字典删除,参数为删除项的key |
| d,pop(“abc” ) | 按照索引删除元素 |
| d.clear( ) | 清空字典的所有元素 |
| for row in ws.iter_rows(min_row=2, values_only=True) | 允许您在工作表中迭代行数据,同时指定起始行并仅获取单元格的值而不包括其他元数据(例如样式等) |
集合(set)
可以用set( )函数创建,或者用{ }。(空集合创建必须用set( ),{ }表示创建一个空的字典)
集合是一种无序集,它是一组键的组合,不存值,不存在重复的键。
可以进行数学集合运算,如并、交、差等。
可以用于去重。例如len( set( a)) != len( a)说明a中有重复的元素。
| S | T | S & T | S - T | S ^ T |
| 并集 | 交集 | 差集 | 补集 |
| s.add( x ) | 如果x不在集合s中,将其添加到s(x为不可变类型数据) |
| s.discard( x) | 移除x,若无x不报错 |
| s.remove( x) | 移除x,若无x则产生KeyError异常 |
| s.clear( ) | 移除s中所有的元素 |
| s.pop( ) | 随机移除一个s中的元素若s空报KeyEttot异常 |
| s.copy( ) | 返回集合s的一个副本 |
| len( s) | 返回集合s的元素个数 |
| x in s | 判断s是否在s中,在返回True,否False |
| x not in s | 判断x不在中 |
| set(x) | 将其他类型变量x转化为集合类型 |
函数(def):
关键字传入:
def fac( x, y, z):……可以用print(fac( x=1, z=3, y=2))传入参数,注意如果第一个参数是用关键字传入的,后面的每一个都需要用关键词传入。
默认参数
默认参数必须放到参数列表的末位。
不定长参数
两种形式,在形参名前加1个星号*或两个星号**
*p用于接收多个位置实参并将其放在元组中
**p接收多个关键参数并放在字典中
不定长参数*args
*可以解压带传递到函数中的元组、列表、集合、字符串等类型,并按位置传递到函数入口参数。
def sum1(a,b,c,d,e):
return a+b+c+d+e
t=(1, 2, 3, 4 ,5)
ret=sum1(*t)
同理**可以解压待传入函数中的字典。
lambda函数
<函数名> = lambda <参数> : <表达式>
表达式相当于函数的返回值。
lambda表达式(lambda函数)可以用来声明匿名函数,常用于内置
函数sorted()、max()、min()和列表方法sort()的key参数,内置函数
map()、filter()和标准库函数reduce()的第一个参数,以及其他可使用
函数的地方。
变量的作用域
基本数据类型,无论是否重名,局部变量与全局变量不同
可以通过global保留字在函数内部声明全局变量
组合数据类型,如果局部变量未真实创建,则是全局变量
global
可以保留字在函数内部使用全局变量
| s=10 def fact(n): s=1 | s=10 def fact(n): global s=1 |
| 此时s是局部变量 | 此时s是全局变量 |
序列操作函数
reduce(function(x,y), list) :其获得序列中前两个项,并把它传递给提供的 函数,获得结果后再取序列中的下一项,连同结果再传递给函数,以此 类推,直到处理完所有项为止。
zip(seq[,seq,...]) :调用 zip()时,其可把两个或多个序列中的相应项合并在一起,并以元组的格式返回它们,在处理完最短序列中的所有项后就停止。
filter(function,list):
– 筛选序列
– 调用filter()时,其会把函数function作用于序列list中的每个元素,然后根据函数返
回值是True或False判断保留还是丢弃该元素,保留返回真值的所有项,过滤掉返
回假值的所有项。
– function可以为匿名函数
map(function,list):将传入的函数function作用到序列list中的每个元素, 并将结果组成新的列表返回。
| def is_odd(n): return n%2 == 1 filter(is_odd, [1,2,4,5,6,9,10,15] ) | 结果: [1,5,9,15] |
| def f(x): return x * x map(f,[ [1, 2, 3, 4, 5, 6, 7, 8, 9]) | [1, 4, 9, 16, 25, 36, 49, 64, 81] |
| def add(x, y): return x +y reduce(add, [1, 3, 5, 7, 9]) | 25 |
文件
文件路径(path)、文件名
– "E:\\class\\Draw\\mypic.bmp"
– "E:\class\Draw\mypic.bmp" ( raw字符串,写单斜杠即可)
– 如果看不到文件的扩展名:
• 在文件管理器中,文件夹选项,显示
• 文件路径分隔符 os.sep
– windows中是 \, 在Python中写成\\,但写成/也可以。
– linux、macOS中是 /
a=open( , ) a.close( )
| a.read(size) 读入全部内容,如果给出参数,读入前size长度 a.readline(size) 读入一行内容,如果给出参数,读入该行前size长度 a.readlines(hint) 读入文件所有行,以每行为元素形成列表如果给出参数,读入前hint行 | a.write(s) a.writelines(lines) s.seek(offset) |
文件打开
<变量名> = open( <文件夹名>, <打开模式> )
例:f=open(“aa.txt”, “r”, encoding=”utf-8”)
with open(filename, “r”’) as f:
……
| ‘r’ | 只读,默认值,文件不存值返回FileNotFondError |
| ‘w’ | 覆盖写,文件不存在则创建 |
| ‘x’ | 创建写,问价不存值创建,存在返回FileExistsError |
| ‘a’ | 追加写,文件不存在就创建,存在则在后面追加内容 |
| ‘b’ | 二进制文件模式 |
| ‘t’ | 文本文件模式,默认值 |
| ‘+’ | 与r/w/x/a一同使用,在原功能基础上增加同时读写的功能 |
二进制文件操作:
对于给定的图片sea.jpg,编写程序将文件复制10份,复制的文件命名分
别为sea-copy1.jpg到sea-copy10.jpg
f_obj = open("sea.jpg", 'rb')
f_content = f_obj.read()
for i in range(0,11):
fileName = 'sea-copy' + str(i) + '.jpg'
fnew = open(fileName,
'wb')
fnew.write(f_content)
fnew.close()
print('图片已成功拷贝.')
-csv文件:
Csv文件数据处理,通用方法借助于,号对数据进行分割
| wr = writer(file) | 创建csv文件写对象 |
| wr.writerow(list) | list写入csv文件 |
借助于csv模块
with open('white_wine.csv', "r") as f:
x = csv.reader(f)
header = next(x)
for r in x:
lst.append(list(map(eval,r)))import csv
rf = open(‘score.csv','r')
readers = csv.reader(rf) #reader为迭代器对象只能使用next()和for循环
for r in readers:
print(r)
借助于csv模块(写入数据)
import csv
list = ["1", "2", "3", "4"]
out = open(outfile, “w”, newline=“”) #可避免每一行后面会多一个空行
csv_writer = csv.writer(out, dialect="excel")
csv_writer.writerow(list)
import csv
content2 = [["data1", "data2", "data3"], ["value1", "value2", "value3"]] # 假设content2是一个二维列表示例
print("content2处理完成!")
with open("white_wine.csv2", "w", newline='') as f:
writer = csv.writer(f)
for row in content2:
writer.writerow(row)
print("数据写入完成!")
json文件
| json.dump(data, file) | 将data序列化为JSON并写入json文件 |
文件及目录管理
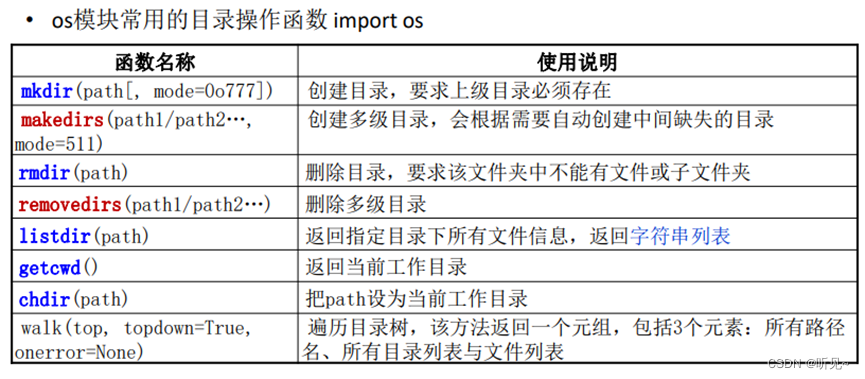

| os.path.dirname(filename) | 获取文件的文件夹路径 |
Word
pip install python-docx| d = Document(fn) | 打开文件 |
| for p in d.paragraphs | 文档中的段落集 |
| p.text | p段落的文本 |
| for t in d.tables | 文档中的单元格 |
| for row in t.rows | 表格中的行 |
| for cell in row.cells | 表格中的列 |
| cell.txt | 单元格中的文本 |
| paragraphs | 返回一个段落对象(Paragraph)的列表,可以通过遍历这些段落来访问文档中的文本和样式。 |
| element | 返回与文档的根XML元素对应的lxml对象,可以用于访问文档的底层XML结构。 |
| core_properties | 返回文档的核心属性(例如标题、作者、创建日期等),可以用于读取或设置文档的元数据。 |
| inline_shapes | 返回文档中的嵌入式图像(内联形状)对象的列表,可以用于处理文档中的图片。 |
| settings | 返回文档的设置,例如页面大小、边距等。 |
| text | 获取段落的文本内容 |
| style | 获取段落的样式,通常是一个docx.shared.Style对象,可用于查看段落的字体、颜色、对齐方式等样式信息 |
| alignment | 获取段落的对齐方式,可以是左对齐、居中对齐、右对齐等 |
| runs | 获取段落中的文本块列表,每个文本块是一个docx.text.run.Run对象,具有字体、颜色等样式信息 |
| clear | 清除段落中的文本内容 |
| text | 获取或设置文本块的文本内容 |
| bold | : 获取或设置文本块是否为粗体。 |
| italic | 获取或设置文本块是否为斜体。 |
| underline | 获取或设置文本块的下划线样式。 |
| font | 获取或设置文本块的字体样式,例如字体名称、大小、颜色等 |
| style | 获取或设置文本块的段落样式(Style) |
| alignment | 获取或设置文本块的对齐方式,可以是左对齐、居中对齐、右对齐等。 |
| strike | 获取或设置文本块是否有删除线。 |
subscript 和 superscript | 获取或设置文本块的下标和上标样式 |
| highlight_color | 获取或设置文本块的文本背景高亮颜色 |
| textbox | 获取文本块是否在文本框中 |
Excel
pip install openpyxl | wb = load_workbook(fn) | 打开xlsx文件 |
| for ws in wb.worksheets | wb中的工作表 |
| for row in ws.rows | ws中的行 |
| for cell in row | row中的列 |
| cell.value | 单元格的值 |
| sheet = workbook.get_sheet_by_name('Sheet1') | 通过工作表的名称选择工作表 |
| sheet = workbook.active | 使用默认的活动工作表 |
| column_A = sheet['A'] | 选择列,例如选择第一列(A列) |
| row_1 = sheet[1] | 选择行,例如选择第一行 |
| cell_A1 = sheet['A1'] | 选择单元格,例如选择A1单元格 |
| for row in sheet2.iter_rows(values_only=True): | 遍历每一行 |
PowerPoint
pip install python-pptx| p = Presentation(fn) | 打开pptx文档 |
| for slide in p.slides | 遍历文档中所有的幻灯片 |
| for shape in slide.shapes | 遍历幻灯片的中的所有形状 |
| if shape.shape_type == 19 | 判断形状的类型,19表示单元格文本,14为文本框 |
| for row in shape.table.rows | 获取表格的行 |
| for cell in row.cells | 获取列 |
类(class)
用class 类名:既可以创建一个类,类名首字母一般大写。
类的方法(函数)分为普通方法和内置方法。
普通方法需要通过类的实例对象根据方法名调用
内置方法是在特点情况下由系统自动执行
普通方法
第一个参数为调用方法时所使用的实例对象(一般为self)
当使用一个实例对象调用类的普通方法时,语法格式为
| 实例对象名. 方法名(实参列表) |
构造方法(__init__)
创建一个类对象时会自动执行
self参数如果在类函数成员中使用,则必须是第一个参数,该参数表示创建的实例
本身。
def __init__(self, name, age):
self.name= name
Magic method (special method)
__init__ 构造方法(当初始化对象时调用)类名(参数)
__del__ 析构方法(当del对象时)
__str__ 转字符串方法(当str(…)时调用)
__add__ 表示加法(+)
__mul__ 表示乘法 (*)
__getitem__ 及 __setitem__ 表示索引(即方括号[ ] )
封装
如果我们希望某些内部属性不被外部访问,我们可以在属性名称前加上两
个下划线“__”(两条下划线),表示将该属性成员私有化,该成员在内部
可以被访问,但是在外部是不能够访问的。
静态函数
态函数可以用来做一些简单独立的任务,其与类对象没有什么关联,
最明显的特征便是,静态函数的第一个参数没有任何特殊性
除了通过类名调用静态成员函数,还需要通过对象名调用静态成员函数
的话,则需要在静态成员函数声明语句的前一行加上 @staticmethod 关
键字,默认只能通过类名调用
类的继承
定义子类时需要指定父类,其语法格式为:
| class 子类名(父类名1, 父类名2.……): … |
在子类中定义了__init__方法,那么在调用父类 __init__方法中
定义的数据成员时,将会产生错误,必须要给出父类构造函数调用
语句来完成对这类数据成员的初始化。
class Student(Person):
def __init__(self ,name,age,sno):
print('Student class inherited from Person init is called.')
super( ).__init__(name,age) #调用父类构造函数
self.school = school
self. sno = sn
图形用户界面
Tkinter是Python内置的图形用户界面框架
win = Tk() #创建窗口
button = Button(win, text="进行转换", command=calculate, width=20)
button. (x=100, y=100)
win.mainloop()


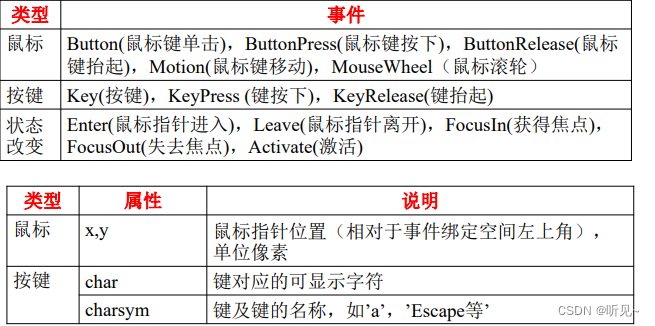
事件及其绑定
bind函数可用于绑定控件事件和相应的处理函数
bind函数的调用规则: 窗体对象.bind(事件类型,回调函数)
<Button-1> 表示⿏标左键单击,其中1 换成 3 表示右 键被单击,2 表示⿏标中键。
<KeyPress-A> 表示 A 键被按下,其中的 A 可以换成其他 的键位。
<Control-V> 表示按下的是 Ctrl 和 V 键,V 可以换成其他 键位。
<F1> 表示按下的是 F1 键,对于 Fn 系列的,都可以随便 换。
案例1:
import tkinter
win=tkinter.Tk()
win.geometry('500x300')
def mouse_pressed(event):
l.config(text=f'鼠标按下:{event.num}')
def mouse_moved(event):
l.config(text=f'鼠标移动:{event.x},{event.y}')
def key_pressed(event):
l.config(text='按键:'+event.keysym)
if __name__ == '__main__':
l=tkinter.Label(win,width=30)
l.pack()
win.bind('<Button>',mouse_pressed)
win.bind('<Motion>',mouse_moved)
win.bind('<Key>',key_pressed)
win.mainloop()案例2:
from tkinter import *
root=Tk()
root.title("摄氏度转华氏度计算器")
root.geometry("300x200")
Label(root,text=" ").grid(row=1)
Label(root,text=" ",width=3).grid(row=2,column=0)
Label(root,text="请输入温度:").grid(row=2,column=1)
e=Entry()
e.grid(row=2,column=2)
def f():
z=e.get()
s="计算结果为"+str(z)+"℃="+str(float(z)*1.8+32)+"℉"
Label(root, text=" ").grid(row=5)
Label(root,text=s,width=30).grid(row=6,column=1,columnspan=2)
Label(root,text=" ").grid(row=3)
Label(root,text=" ",width=3).grid(row=4,column=0)
Button(root,text="进行转换",command=f,width=30).grid(row=4,column=1,columnspan=2)
root.mainloop()模块和库
安装第三方库
方法1(主要方法): 使用pip命令
– pip install <第三方库名>
方法2: pycharm安装
– File – Settings – Project – Python Interpreter
方法3: 文件安装方法
– 下载对应版本的文件
– 使用pip install <文件名>安装
jieba库
| jieba.lcut(s) | 精确模式,返回一个列表类型的分词结果 >>jieba.lcut("中国是一个伟大的国家”) ['中国',"是'"一个,伟大","的", 国家'] |
| jieba.lcut(s, cut_all=true) | 全模式,返回一个列表类型的分词结果,存在几余 >>>jieba.lcut("中国是一个伟大的国家”,cut_all=True) ["中国’,中国是","一个","伟大’,"的’,"国家'] |
| jieba.lcut_for_search(s) | 搜索引擎模式,返回一个列表类型的分词结果,存在冗余 >>>jieba.lcut_for_search(“中华人民共和国是伟大的" [‘中华’,”华人”,”人民’,”共和’,”共和国’,”中华人民共和国”,”是”,”伟大”,”的”] |
| jieba.add_word(w) | 向分词词典增加新词w >>>jieba.add_word("蟒蛇语言”) |
woedcloud
















 5153
5153











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









