







作者前言
本文章为记录使用k8s遇到的问题和解决方法,文章持续更新中...
目录
- 作者前言
- 正常配置ingress,但是访问错误
- 添加工作节点报错
- 安装k8s报错
- 使用kubectl命令报错
- container没有运行
- 安装会出现kubelet异常,无法识别
- 删除k8s集群
- 访问dashboard报错
- k8s服务器重启后kubectl命令使用不了
- k8s手动卸载不干净
- kubectl get pods 失败
- 安装k8s加载内核模块报错
- k8s删除pod失败,一直处于deleted的界面
- k8s1.23集群重启后报错
- kubelet启动不了,通用问题
- 安装k8s后coredns的pod一直处于pending状态
- k8s初始化报错 [ERROR CRI]: container runtime is not running
- 报错couldn't get current server API group list: Get "http://localhost:8080/api?timeout=32s": dial tcp [::1]:8080: connect: connection refused
正常配置ingress,但是访问错误
curl: (7) Failed connect to test.com:8080; Connection refused
在/etc/hosts加下记录
ip 域名
添加工作节点报错
error execution phase kubelet-start: error uploading crisocket: Unauthorized To see the stack trace
rm -rf $HOME/.kube/config
kubeadm reset
安装k8s报错
情况一:
[preflight] Running pre-flight checks
error execution phase preflight: [preflight] Some fatal errors occurred:
[ERROR FileAvailable--etc-kubernetes-kubelet.conf]: /etc/kubernetes/kubelet.conf already exists
[ERROR Port-10250]: Port 10250 is in use
[ERROR FileAvailable--etc-kubernetes-pki-ca.crt]: /etc/kubernetes/pki/ca.crt already exists
[preflight] If you know what you are doing, you can make a check non-fatal with --ignore-preflight-errors=...
To see the stack trace of this error execute with --v=5 or higher
先删除文件
rm -rf /etc/kubernetes/kubelet.conf
rm -rf /etc/kubernetes/pki/ca.crt
lsof -i :10250
kill -9 进程号
情况2:
[ERROR DirAvailable–var-lib-etcd]: /var/lib/etcd is not empty
rm -rf /var/lib/etcd
使用kubectl命令报错
The connection to the server 本机ip:6443 was refused - did you specify the right host or port?
排错思路
1、集群硬件时间和系统时间不同步
hwclock和data查看后修改
2、查看端口是否被占用或被防火墙拦截
netstat -antup | grep 端口号
firewalld --list-zones
iptables -nL
3、更改主机名了、重启服务器了
hostnamectl set-hostname 原名
重启kubelet服务
4、查看服务是否正常,重启服务
kubelet、containerd、docker等
container没有运行
container runtime is not running: output: time="2023-08-11T15:37:57+08:00" l
解决:
vim /etc/containerd/config.toml
#disabled_plugins = ["cri"]
安装会出现kubelet异常,无法识别
--node-labels 字段问题,原因如下。
将 --node-labels=node.kubernetes.io/node='' 替换为 --node-labels=node.kubernetes.io/node= 将 '' 删除
删除k8s集群
先停服
systemctl stop kubelet etcd docker containerd
卸载k8s
kubeadm reset -f
删除k8s相关目录
rm -rf ~/.kube/
rm -rf /etc/kubernetes/
rm -rf /etc/systemd/system/kubelet.service.d
rm -rf /etc/systemd/system/kubelet.service
rm -rf /usr/bin/kube*
rm -rf /etc/cni
rm -rf /opt/cni
rm -rf /var/lib/etcd
rm -rf /var/etcd
卸载k8s软件包
yum -y remove kubeadm-1.xxx kubelet-1.xxx kubectl-1.xxx
更新yum源
yum clean all
yum -y update
yum makecache
访问dashboard报错
网页提示信息Client sent an HTTP request to an HTTPS server.
原因:
因为直接使用ip:端口的方式是http协议
解决方法:
访问需要加上https
https://ip:端口
如果还是无法访问提示此报错
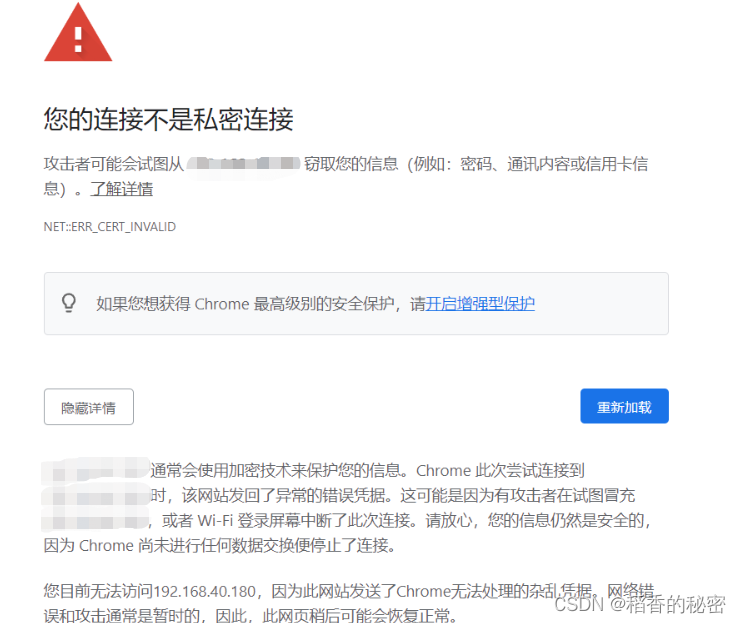
原因:被浏览器安全阻拦了
点击页面空白处,键盘输入thisunsafe就可以正常连接了
k8s服务器重启后kubectl命令使用不了
重启前需要配置自启动
systemctl enable docker &&systemctl start docker
systemctl enable kubelet && sytemctl start kubelet
systemctl enable containerd && sytemctl start containerd
systemctl daemon-reload
重启后kubectl命令不了,一般重启器kubelet服务就可以了
sytemctl restart kubelet
k8s手动卸载不干净
使用以下命令进行操作
kubeadm reset -f
kubectl get pods 失败
E0816 23:01:08.370695 3256 memcache.go:265] couldn't get current server API group list: Get "https://ip/api?timeout=32s": dial tcp ip:6443: connect: connection refused
查看kubelet服务状态
systemctl status kubelet
$KUBELET_KUBECONFIG_ARGS $KUBELET_CONFIG_ARGS $KUBELET_KUBEADM_ARGS $KUBELET_EXTRA_ARGS
网上查阅后是k8s集群的版本问题,因为不小心升级了yum update
kubelet --version查看版本是1.28的,之前安装是1.25的
#解决方法,降级
查看包
rpm -qa | grep kube
删除包
yum remove -y kubeadm-1.28.0-0.x86_64 kubernetes-cni-1.2.0-0.x86_64 kubectl-1.28.0-0.x86_64 kubelet-1.28.0-0.x86_64
yum install -y kubelet-1.25.0 kubeadm-1.25.0 kubectl-1.25.0
systemctl enable kubelet
再次kubectl get pods显示正常了
安装k8s加载内核模块报错
加载内核参数net.bridge.bridge-nf-call-ip6tables和net.bridge.bridge-nf-call-iptables
报错cannot stat /proc/sys/net/bridge/bridge-nf-call-ip6tables: No such file or directoryfcannot stat /proc/sys/net/bridge/bridge-nf-call-iptables: No such file or directory
#解决方法
modeprobe br_netfilter
k8s删除pod失败,一直处于deleted的界面
我们在删除pod的时候出现以下情况:
#删除pod
[root@master1 yaml]# kubectl delete pod tomcat
pod "tomcat-test" deleted
#使用kubectl delete -f通过yaml的方式删除也不行
[root@master1 yaml]# kubectl delete -f test.yaml
pod "tomcat-test" deleted
#添加上--force就可以删除了
[root@master1 yaml]# kubectl delete -f test.yaml --force
Warning: Immediate deletion does not wait for confirmation that the running resource has been terminated. The resource may continue to run on the cluster indefinitely.
pod "tomcat-test" force deleted
k8s1.23集群重启后报错
The connection to the server ip:6443 was refused - did you specify the right host or port?
环境k8s1.23
1、检查服务是否正常:kubelet和docker
2、检查配置文件
vim /etc/docker/daemon.conf
{
"exec-opts": ["native.cgroupdriver=systemd"],
"log-driver": "json-file",
"log-opts": {
"max-size": "100m"
},
"storage-driver": "overlay2"
}
vim /etc/systemd/system/kubelet.service.d/10-kubeadm.conf
# Note: This dropin only works with kubeadm and kubelet v1.11+
[Service]
Environment="KUBELET_KUBECONFIG_ARGS=--bootstrap-kubeconfig=/etc/kubernetes/bootstrap-kubelet.conf --kubeconfig=/etc/kubernetes/kubelet.conf"
Environment="KUBELET_CONFIG_ARGS=--config=/var/lib/kubelet/config.yaml"
# This is a file that "kubeadm init" and "kubeadm join" generates at runtime, populating the KUBELET_KUBEADM_ARGS variable dynamically
EnvironmentFile=-/var/lib/kubelet/kubeadm-flags.env
# This is a file that the user can use for overrides of the kubelet args as a last resort. Preferably, the user should use
# the .NodeRegistration.KubeletExtraArgs object in the configuration files instead. KUBELET_EXTRA_ARGS should be sourced from this file.
EnvironmentFile=-/etc/default/kubelet
ExecStart=
ExecStart=/usr/bin/kubelet $KUBELET_KUBECONFIG_ARGS $KUBELET_CONFIG_ARGS $KUBELET_KUBEADM_ARGS $KUBELET_EXTRA_ARGS
3、swap没有关闭/没在配置文件/etc/fstab里面注释掉
关闭swap
swapoff -a
&
vim /etc/fstab 将swap的记录注释
4、查看端口是否正常启动
ss -aultp | grep 6443
5、查看时间有没有同步保持一致
#查看各节点的系统时间
data
#不一致安装ntpdate命令
apt-get install ntpdate -y
#配置周期性任务自动同步
crontab -e
* */1 * * * /usr/sbin/ntpdate cn.pool.ntp.org
kubelet启动不了,通用问题
大部分kubelet启动不了是因为配置文件写错了
先查看kubelet服务
systemctl status kubelet
● kubelet.service - kubelet: The Kubernetes Node Agent
Loaded: loaded (/lib/systemd/system/kubelet.service; enabled; vendor preset: enabled)
Drop-In: /etc/systemd/system/kubelet.service.d
└─10-kubeadm.conf
Active: active (running) since Thu 2023-11-02 11:32:41 CST; 1 weeks 3 days ago
Docs: https://kubernetes.io/docs/home/
Main PID: 983 (kubelet)
Tasks: 40 (limit: 3429)
Memory: 102.4M
CGroup: /system.slice/kubelet.service
在drop-in这里有个文件地址
通过查询这个配置文件
cat /etc/systemd/system/kubelet.service.d/10-kubeadm.conf
#看到这个参数下的文件路径
Environment="KUBELET_CONFIG_ARGS=--config=/var/lib/kubelet/config.yaml"
#编辑这个文件,找到下面这个参数
vim /var/lib/kubelet/config.yaml
staticPodPath: /etc/kubernetes/manifests
#很多人会在这里把这个参数写错
正确的:manifests
错误的: mainfests
安装k8s后coredns的pod一直处于pending状态
原因:

官方文档参考链接:
https://kubernetes.io/zh-cn/docs/setup/production-environment/tools/kubeadm/troubleshooting-kubeadm/
解决方法:
安装网络插件,例如calico就可以了
配置网络插件Calico
1、下载calico.yaml文件
#官网链接
https://www.tigera.io/project-calico
#github链接
https://github.com/projectcalico/calico
#下载calico配置文件
wget https://docs.tigera.io/archive/v3.25/manifests/calico.yaml
2 修改calico配置文件
vim calico.yaml
修改1:将默认pod网络修改为pod网络
- name: CALICO_IPV4POOL_CIDR
value: "192.168.0.0/16"
修改后的配置
- name: CALICO_IPV4POOL_CIDR
value: "10.1.0.0/16"
修改2:找到CLUSTER_TYPE那行,在后面添加两行,ens33处填写主机的网卡名称
- name: IP_AUTODETECTION_METHOD
value: "interface=ens33"
3 安装calico
kubectl apply -f calico.yaml
#资源状态一直有问题,查看发现calico pod状态一直为Init:ImagePullBackOff
kubectl get pod -A
#查看calico.yaml文件查看镜像,然后使用科学服务器pull完save下来
docker pull docker.io/calico/cni:v3.25.0
docker pull docker.io/calico/kube-controllers:v3.25.0
docker pull docker.io/calico/node:v3.25.0
#保存镜像
docker save calico/kube-controllers calico/kube-controllers calico/cni calico/node -o calico.war
#上传到服务器后,载入镜像
docker load -i calico.war
ctr -n k8s.io image import calico.war
#删除calico再次执行
kubectl delete -f calico.yaml
kubectl apply -f calico.yaml
#检查是否正常,calico pod状态为Running就可以了
kubectl get pod -A
k8s初始化报错 [ERROR CRI]: container runtime is not running
kubeadm init命令时报错
原因
用安装包的方式安装containerd,默认会禁用containerd作为容器运行时。
这时候没有容器运行时可用初始化就会报错,开启的方法就是将disabled_plugins的值删掉
1、先查看contianerd的状态是否正常
systemctl status containerd
2、编辑/etc/containerd/config.toml文件,大概率问题是这个
找到这个值
disabled_plugins = ["cri"]
改为
disabled_plugins = []
#改完重启contaienrd才会生效
systemctl restart containerd
报错couldn’t get current server API group list: Get “http://localhost:8080/api?timeout=32s”: dial tcp [::1]:8080: connect: connection refused
原因:安装后设置 kubectl 访问集群的配置,简单讲,没有配置config文件
#安装完会生成这个命令
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
或者这个命令
cat <<EOF >> /root/.bashrc
export KUBECONFIG=/etc/kubernetes/admin.conf
EOF
source /root/.bashrc
















 8593
8593

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









