







1> Redis是单线程还是多线程,为什么Redis会很快?
Redis单线程指的是网络请求模块使用了一个线程(所以不需考虑并发安全性),即一个线程处理所有网络请求,其他模块仍用了多个线程。
很快的原因:
1、完全基于内存,绝大部分请求是纯粹的内存操作,非常快速;
2、采用单线程,避免了不必要的上下文切换和竞争条件;
3、使用多路I/O复用模型,非阻塞IO;(epoll)
4、数据结构简单,对数据操作也简单,Redis中的数据结构是专门进行设计的;
5、使用底层模型不同,它们之间底层实现方式以及与客户端之间通信的应用协议不一样,Redis直接自己构建了VM 机制 ,因为一般的系统调用系统函数的话,会浪费一定的时间去移动和请求;
2> Redis的zset数据结构,描述跳跃表的构造过程,插入删除数据等
跳跃表节点:
typedef struct zskiplistNode {
robj *obj; /*成员对象*/
double score; /*分值*/
struct zskiplistNode *backward; /*后退指针*/
struct zskiplistLevel { /*层*/
struct zskiplistNode *forward; /*前进指针*/
unsigned int span; /*跨度*/
} level[];
} zskiplistNode;
跳跃表:
typedef struct zskiplist {
struct zskiplistNode *header, *tail; //header指向跳跃表的表头节点,tail指向跳跃表的表尾节点
unsigned long length; //记录跳跃表的长度,也即是,跳跃表目前包含节点的数量(表头节点不计算在内)
int level; //记录目前跳跃表内,层数最大的那个节点的层数(表头节点的层数不计算在内)
} zskiplist;示意图:
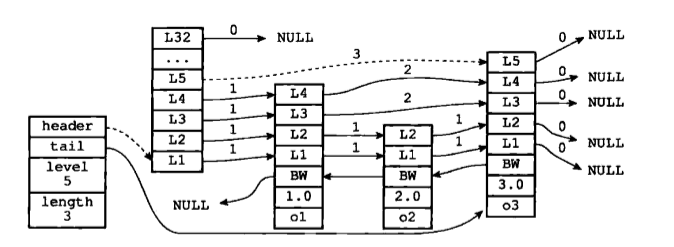
查询:由最高层开始 ,查找90的节点示意图
插入:幂次定律随机生成1~32层高,依次增加L1至LN层
删除:查找节点,然后修改指针,删除节点的过程
3> Redis的热key解决方案(内存 或 多个点备份存储等)
热key发现:业务经验估计、客户端收集,redis自带命令hotkey
解决方案:
1、利用业务服务的JVM缓存,一般Java业务服务会有多个
2、多个redis备份存储,随机选取一台读取
3、使用redis集群,key尽量分配到不同的分片上
4>Redis的回收策略有哪些?
- noeviction:默认策略,当内存不足以容纳新写入数据时,新写入操作会报错。应该没人用吧。
- allkeys-lru:当内存不足以容纳新写入数据时,在键空间中,移除最近最少使用的 Key。推荐使用,目前项目在用这种。
- allkeys-random:当内存不足以容纳新写入数据时,在键空间中,随机移除某个 Key。应该也没人用吧,你不删最少使用 Key,去随机删。
- volatile-lru:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,移除最近最少使用的 Key。这种情况一般是把 Redis 既当缓存,又做持久化存储的时候才用。不推荐。
- volatile-random:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,随机移除某个 Key。依然不推荐。
- volatile-ttl:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,有更早过期时间的 Key 优先移除。不推荐。如果没有对应的键,则回退到noeviction策略。
5>Redis持久化机制有哪些?各有什么优劣?实现过程是什么样的?
- RDB:RDB 持久化机制,是对 redis 中的数据执行周期性的持久化。
- AOF:AOF 机制对每条写入命令作为日志,以 append-only 的模式写入一个日志文件中,在 redis 重启的时候,可以通过回放 AOF 日志中的写入指令来重新构建整个数据集。
RDB优缺点:
RDB 会生成多个数据文件,每个数据文件都代表了某一个时刻中 redis 的数据,这种多个数据文件的方式,非常适合做冷备,可以将这种完整的数据文件发送到一些远程的安全存储上去,比如说 Amazon 的 S3 云服务上去,在国内可以是阿里云的 ODPS 分布式存储上,以预定好的备份策略来定期备份 redis 中的数据。
RDB 对 redis 对外提供的读写服务,影响非常小,可以让 redis 保持高性能,因为 redis 主进程只需要 fork 一个子进程,让子进程执行磁盘 IO 操作来进行 RDB 持久化即可。
相对于 AOF 持久化机制来说,直接基于 RDB 数据文件来重启和恢复 redis 进程,更加快速。
如果想要在 redis 故障时,尽可能少的丢失数据,那么 RDB 没有 AOF 好。一般来说,RDB 数据快照文件,都是每隔 5 分钟,或者更长时间生成一次,这个时候就得接受一旦 redis 进程宕机,那么会丢失最近 5 分钟的数据。
RDB 每次在 fork 子进程来执行 RDB 快照数据文件生成的时候,如果数据文件特别大,可能会导致对客户端提供的服务暂停数毫秒,或者甚至数秒。PS:博主实际应用中曾出现当redis内存占用超过机器内存一半的时候,BGSAVE失败的情况,原因是因为RDB会fork出的子进程会复制主进程的数据,在某一时刻内存占用要足够2倍才能正常进行。
AOF优缺点:
AOF 可以更好的保护数据不丢失,一般 AOF 会每隔 1 秒,通过一个后台线程执行一次fsync操作,最多丢失 1 秒钟的数据。
AOF 日志文件以 append-only 模式写入,所以没有任何磁盘寻址的开销,写入性能非常高,而且文件不容易破损,即使文件尾部破损,也很容易修复。
AOF 日志文件即使过大的时候,出现后台重写操作,也不会影响客户端的读写。因为在 rewrite log 的时候,会对其中的指令进行压缩,创建出一份需要恢复数据的最小日志出来。在创建新日志文件的时候,老的日志文件还是照常写入。当新的 merge 后的日志文件 ready 的时候,再交换新老日志文件即可。
AOF 日志文件的命令通过非常可读的方式进行记录,这个特性非常适合做灾难性的误删除的紧急恢复。比如某人不小心用 flushall 命令清空了所有数据,只要这个时候后台 rewrite 还没有发生,那么就可以立即拷贝 AOF 文件,将最后一条 flushall 命令给删了,然后再将该 AOF 文件放回去,就可以通过恢复机制,自动恢复所有数据。
对于同一份数据来说,AOF 日志文件通常比 RDB 数据快照文件更大。
AOF 开启后,支持的写 QPS 会比 RDB 支持的写 QPS 低,因为 AOF 一般会配置成每秒 fsync 一次日志文件,当然,每秒一次 fsync,性能也还是很高的。(如果实时写入,那么 QPS 会大降,redis 性能会大大降低)
以前 AOF 发生过 bug,就是通过 AOF 记录的日志,进行数据恢复的时候,没有恢复一模一样的数据出来。所以说,类似 AOF 这种较为复杂的基于命令日志 / merge / 回放的方式,比基于 RDB 每次持久化一份完整的数据快照文件的方式,更加脆弱一些,容易有 bug。不过 AOF 就是为了避免 rewrite 过程导致的 bug,因此每次 rewrite 并不是基于旧的指令日志进行 merge 的,而是基于当时内存中的数据进行指令的重新构建,这样健壮性会好很多。
6>Redis支持事务吗?事务是原子性的吗?如何保证原子性?
redis支持事务,但是它提供的事务机制与传统的数据库事务有些不同
1、(A)但不保证原子性:redis中的一个事务中如果存在命令执行失败,那么其他命令依然会被执行,没有回滚机制
2、(C)Redis 舍弃了回滚的设计,基本上也就舍弃对数据一致性的有效保证
3、(I)Redis的事务是通过将一组命令封装到一起执行所以是隔离性的
4、(D)Redis 一般情况下都只进行内存计算和操作,持久性无法保证。
7>Redis主从同步原理
此外,Redis集群环境下master选举机制?Redis主从同步有哪几种方式?也是经常要问的面试题,博主不在赘述,官方文档都有介绍















 12万+
12万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









