







笔记
1.基本流程

2.划分选择
- 信息增益
假定当前样本集合D中第K类样本所占的比例为 Pk (k = 1, 2,. . . , IYI) ,则D的信息熵定义为
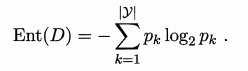
信息增益为:
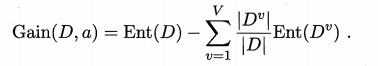
信息增益准则对可取值数目较多的属性有所偏好。 - 增益率
为减少这种偏好可能带来的不利影响,使用"增益率",表达式如下:
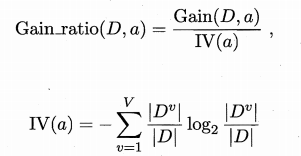
需注意的是,增益率准则对可取值数目较少的属性有所偏好?因此 C4.5 算法并不是直接选择增益率最大的候选划分属性,而是使用了一个启发式: 先从候选划分属性中找出信息增益高于平均水平的属性,再从中选择增益率最高的. - 基尼指数
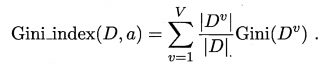
3.剪枝处理
决策树剪枝的基本策略有"预剪枝" (prepruning) 和"后剪枝"(post"pruning) [Quinlan, 1993]. 预剪枝是指在决策树生成过程中,对每个结点在划分前先进行估计,若当前结点的划分不能带来决策树泛化性能提升,则停止划分并将当前结点标记为叶结点;后剪枝则是先从训练集生成一棵完整的决策树,然后自底向上地对非叶结点进行考察,若将该结点对应的子树替换为叶结点能带来决策树泛化性能提升,则将该子树替换为叶结点.
4.连续与缺失值
采用2分法(bi partition) 对连续属性进行处理;
若样本 在划分属性 上的取值未知,则将 同时划入所有子结点;















 4278
4278











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









