







在上一篇文章中,提到了change buff对于更新的优化,有些小伙伴可能会和WAL机制混淆,redo log 不也是先更新缓存再写日志的吗?这两个不是一回事吗?我个人的理解是,change buff对innodb_buffer_pool是一个补充。首先看图
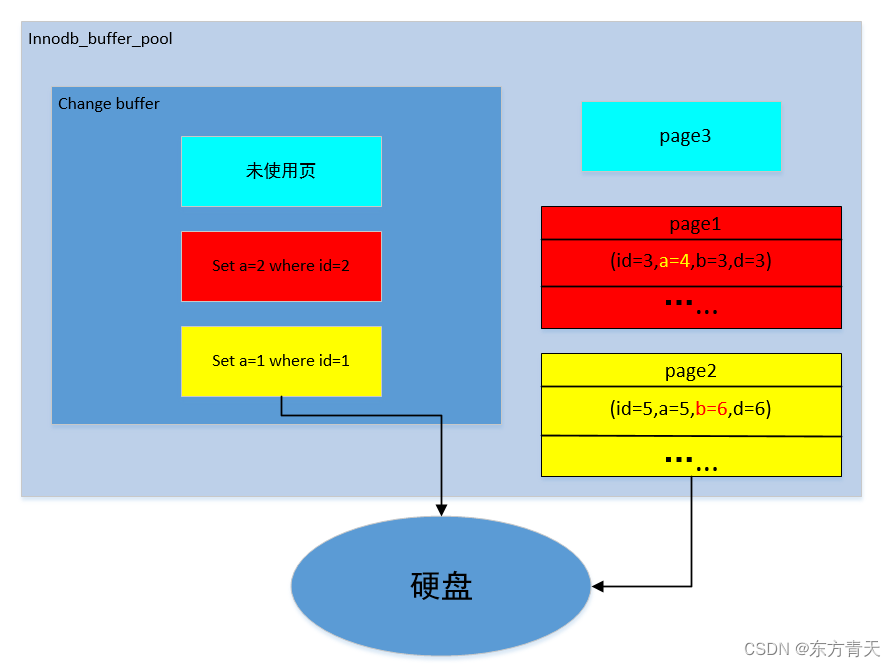
到硬盘前的一些步骤省略,这里着重强调缓冲池发生的事情。
图中不同颜色方块代表不同的页面缓存。天蓝色:没有使用过的页。红色:脏页。黄色:干净页。
省略号表示其他的数据记录。
现在我们从innodb_buffer_pool入手,先说查询。
innodb_buffer_pool查询
mysql刚启动的时候innodb_buffer_pool是空的,执行查询后被查询的数据会缓存到innodb_buffer_pool当中。很显然在第一次查询的时候是没有办法读缓存的,由图中我们不难看出,innodb_buffer_pool中的页缓存是直接存储了数据行,所以在查询时如果能够命中缓存的话,是不需要读硬盘的,那么在没有其他干扰的情况下,两次相同的查询第二次查询的效率应该是高于第一次查询的,并且在缓存够用的情况下,数据量越大差距越明显,现在我们还是用之前的表t来做这个实验,建表语句如下:
CREATE TABLE `t` (
`id` int(11) DEFAULT NULL,
`a` int(11) DEFAULT NULL,
`b` int(11) DEFAULT NULL,
`d` int(11) DEFAULT NULL,
KEY `a` (`a`),
KEY `b` (`b`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8;存储过程如下:
CREATE DEFINER=`root`@`localhost` PROCEDURE `test`()
begin
declare i int;
set i=1;
while(i<=100000)do
insert into t (`id`,`a`,`b`,`d`) values(i,i,i,i);
set i=i+1;
end while;
endCREATE DEFINER=`root`@`localhost` PROCEDURE `ttt`()
begin
declare i int;
set i=1;
while(i<=10000)do
update t set a=a+1 where b=i;
set i=i+1;
end while;
end表建好后往表中插入10万条数据
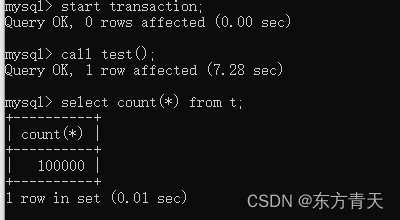
现在我们重启mysql(为了清除缓存,免受影响)
现在我们执行一个大查询看看时间是否与理论一致。语句如下:
select * from t where d>10000 and d<20000; 
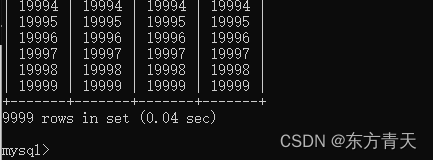
不难看出,同样的查询受缓存影响时间差距几乎是10倍。
innodb_buffer_pool修改
从上面的图可以看出,如果缓存中有数据的话修改会直接改缓存,到了合适的时机才会写硬盘。
如果缓存中没有要修改的数据,就会先读硬盘将数据读到缓存中,再修改缓存。
接下来做修改操作,同样的,我们先重启清空缓存再尝试。使用上面的存储过程进行修改。首先是直接修改

再查询

先查询后修改
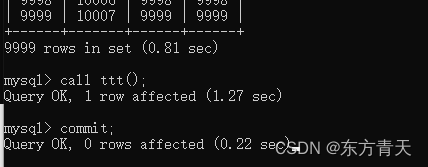
修改完再查询

可以看出由于查询之后缓存中已经有需要修改的数据了,第二次修改的速度明显快很多。并且修改完之后的查询也非常快,明显后面的查询也用上了缓存。
在查询的时候,change buffer是没有办法和innodb_buffer_pool查询一样缓存有数据直接返回的,因为change buffer记录的是修改操作这个动作,并不是修改后的数据,所以即便change buffer中已经有了,在查询时也必须先将硬盘的数据读到缓存区,然后将change buffer中的动作应用到缓存上,才能返回。但是由于change buffer 只记录动作,所以在修改时缓存中没有要修改的数据页也不要紧,直接在change buffer中记下这个动作就可以了,在查询的时候才需要读硬盘。
change buffer的优化在5.x的版本中仅支持插入。这里我没有找到好的测试用例,就不献丑了,如果有大佬知道的话,敬请不吝赐教。















 6439
6439











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









