







Buffer Pool和Change Buffer快速读写解析
1、 前言
之前也写了好几篇文章说明了MySQL的一些内容,但是我感觉在学习MySQL最初疑问仍然没有解释清楚,这篇文章就具体说明下。
我当初学习的时候有这么几个疑问:
- MySQL如何查询数据的?
- MySQL如何插入数据的?
在此,查找了官网和网上的一些资料,总结了些分享下。
说到数据插入就要说之前写的文章,MySQL的体系结构,分为MySQL server 和 存储引擎。
之前也说明了查询的具体流程,如果感兴趣请看:
MySQL文件系统之前也介绍过,如果感兴趣请看:
但是生成执行计划到底怎么查询到数据的?就要说到InnoDB存储引擎的结构。
2、 快速读写解析
说到数据插入就必须说说MySQL是如何高效读写的,直接进行I/O操作肯定是比较慢。
假如想快速读写,就必须在内存中进行,MySQL也是这样实现。
2.1、InnoDB内存结构简介
首先说下MySQL的InnoDB内存结构:
- SGA(系统全局区)和PGA(程序缓存区)
MySQL的内存中和Oracle一样包含了SGA(系统全局区)和PGA(程序缓存区)。
啥叫SGA 和 PGA啊?就是系统全局区和程序缓存区,大白话就是一个是全局有效,一个是会话有效。
这里PGA就不说了,简单说下SGA。
先说下InnoDB的内存结构的模块,看下官方的图,来自官网MySQL5.7文档:
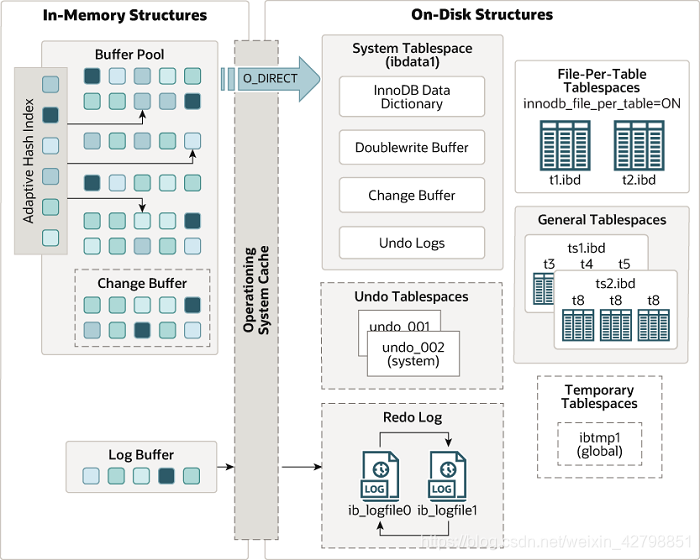
InnoDB的内存结构分为4个部分,即为Buffer Pool 缓冲池,Change Buffer 变更缓冲,Adapter Hash Index 自适应Hash索引和Log buffer 日志缓冲。
当我们要查询数据的时候,首先看buffer pool是有没有,如果有就直接返回了。
2.2、Buffer Pool 缓冲池查询数据解析
Buffer Pool 是 MySQL系统全局区的一部分,数据查询的时候首先会把数据缓存到Buffer Pool 中。
当我们查询数据的时候,首先去Buffer Pool 中去查询,假如Buffer Pool 中数据存在,那么就把数据直接返回。
- 如果Buffer Pool 没有呢?
假如Buffer Pool 中没有具体数据,那么就会查询磁盘。
这个时候是具体的I/O操作,查询的效率就会比较慢。
当我们查询到具体的数据后,会把数据存储到Buffer Pool 中,之后才会返回查询的数据。
这个时候有个问题,假如数据已经缓存在Buffer Pool 中,但是数据发生了update 操作(update/delete),那么如何保证数据是正确的?
这个时候就涉及到写操作:
1、当 update 操作使用了普通的索引,首先去合并Change Buffer 中的操作,然后才会返回合并后的数据。
2、当 update 操作使用了主键索引,那么写操作就会直接更新Buffer Pool 中的查询数据,然后查询的仍然是最新的数据结果。
2.3、change buffer 写入数据解析
上述读操作中涉及到另外一块区域,Change Buffer :
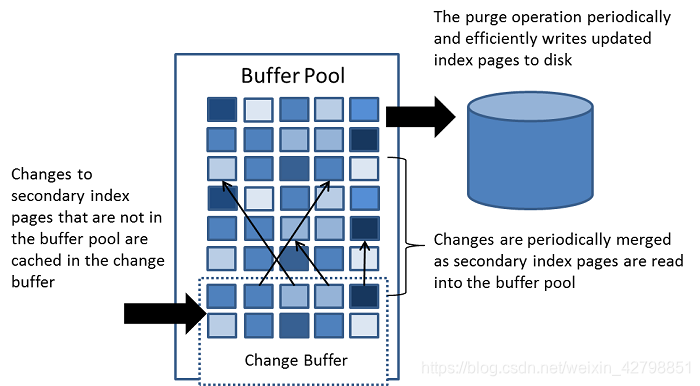
图片来自官方文档,就是普通索引操作数据的时候,假如不在Buffer Pool中,就把这个操作放进来,等到下次查询数据的时候,就merged这些操作执行。
The change buffer is a special data structure that caches changes to secondary index pages when those pages are not in the buffer pool. The buffered changes, which may result from INSERT, UPDATE, or DELETE operations (DML), are merged later when the pages are loaded into the buffer pool by other read operations.
- 为什么Change Buffer 适用于普通索引,而不是唯一索引?
是不是唯一索引,肯定要检验数据的,这个时候就需要查询具体的数据,
假如Buffer Pool中没有,就需要通过I/O操作去缓存数据,之后根据缓存后的数据直接操作就可以,数据的更新操作不需要缓存Change Buffer,直接更新Change Buffer 中的数据即可。
这个时候就能保证是最新的数据了,因为假如没有就去查询,如果之前发生了更改就合并change buffer中的操作,合并之后读取的也是最新的数据,这样就可以保证读取到的肯定是最新的数据版本。
2.4、Change Buffer 缓存数据持久化
MySQL遵循了日志先行的策略,所有的操作在执行之前都会写入redo log日志,这个也是首先写入内存中的 log buffer ,之后由log buffer thread 线程刷新写入磁盘。
redo log 存储的是DDL语句和DML语句。
- 那我也不能只是读取是最新的版本,我肯定是需要持久化到磁盘的,如何持久化呢?
首先要知道buffer 中的脏页组成情况:
这个时候就需要了解Buffer Pool中的内容,分为 free buffer ,clean buffer和dirty buffer。
当我们查询数据的时候,每次缓存数据的时候都是按照页单位进行缓存,默认每页大小16K,可以上下调整为32K、64K、8K、4K,
缓存的这些页buffer 数据会组成双向链表结构。
-
Buffer Pool 中的链表结构有三种:
1、free list 由 free buffer 组成,free list 是空页组成的链表,当需要缓存新数据页的时候,从free list获取
2、LRU list 由 clean buffer 组成,但是数据更改之后不会删除,LRU list遵循LRU 算法淘汰数据页,并把脏数据
3、flush list 由 dirty buffer 组成,都是数据变更后的脏页
我们知道脏页的情况之后,就需要刷新到磁盘了,这个时候我们需要知道MySQL单进程多线程的结构。
所有的脏页都是由线程刷新到磁盘叫做checkpoint:
1、当数据库执行关闭的时候刷新所有内存中的脏页到磁盘。
2、master 线程定时刷新到磁盘,分为1s 和 10s 两种模式。
3、LRU list 空闲页不足的时候刷新脏页到磁盘,采用LRU优化算法,page cleaner thread刷新。
4、redo log 页空间不足的时候刷寻脏页到磁盘,空间不足代表redo log日志到最大值的百分比阈值,page cleaner thread刷新到磁盘。
5、 脏页达到一定的百分比,master 线程刷新脏页到磁盘
同样 change buffer 和redo log 也会刷新到磁盘进行持久化,分别使用的线程为change buffer thread和redo log thread 。
2.5、Redo log 两段提交和Redo log ,binlog 双一操作
我们知道binlog 是可以做备份恢复和主从来使用的,redo log 是防止数据库崩溃做数据恢复。
当我们持久化数据的时候,也会进行redo log 日志进行持久,也会进行 binlog 记录DML操作。
- 我们如何保证redo log 和 binlog 的数据操作一致性?
MySQL在执行两种日志的时候启动了redo log两段提交的方式:
准备阶段: 首先执行的事务SQL写入log buffer ,做一个准备标记,然后刷新到redo log
提交阶段: 将log buffer中的数据写入到binlog ,写入磁盘,然后在redo log 写提交的标记。并把binlog成功的标记写入redo log。
问题场景:
- 假如写入redo log成功,但是写入binlog失败,数据库宕机,重启的时候发现binlog写入失败,redo log发生回滚。
- 假如redo log成功,binlog成功,但是再此写入redo log的时候失败,那么就会发生重新写入的情况。
即为只要binlog写入成功,那么事务就执行成功。
- binlog和redo log 双一操作
当然只要数据操作在缓存中我们就不能保证一定数据安心,只能保证相对性的数据安全,主要在于,假如刚写入redo log 还没有进行持久化,那么也会造成数据操作丢失。
所以我们会把redo log 和 binlog 持久化的策略配置为,每进行一次redo log 写入,就进行一次redo log日志持久化操作,binlog也是执行这种策略。
innodb_flush_log_at_trx_commit和sync_binlog这两个参数是控制MySQL磁盘写入策略以及数据安全性的关键参数。
所谓的双一就是指:
sync_binlog=1;
innodb_flush_log_at_trx_commit=1
2.6、MVCC多版本并发控制
MySQL采用了多版本并发控制,称作MVCC。
说到MVCC就必须说下InnoDB的另外一种日志文件 undo log。
undo log会对数据维护一条 undo log链表,用于事务回滚操作。
InnoDB 在每一行数据后面加上了三个字段:
DB_ROW_ID(行ID)
DB_TRX_ID(事务ID)
DB_ROLL_PTR(回滚指针)。
其中DB_ROW_ID 和MVCC没有什么关系,DB_TRX_ID 记录了当前事务的ID,DB_ROLL_PTR 记录了undo log 上一个版本的指针。
当数据发生insert,update,delete的时候,数据写入数据库并同时写入undo log,同时更新事务ID和回滚指针。
当数据查询的时候 select 操作,分为快照读和当前读。
- 快照读:
- RR 隔离级别再事务开始的时候生成一个快照,之后每次查询都是查询这个快照。
- RC隔离级别事务每次查询都会生成一个快照。
- 当前读:
会查询当前数据的情况。
select … lock in share mode 或者 select … for update。
所以,当我们查询数据的时候,一定可以查询到当前事务执行之前的最新更新记录。
3、总结
当我们使用MySQL或者其他的关系型数据库的时候,我们主要的目的是为了保证业务的数据安全性。
而且在性能,并发和事务之间其实比较难以取舍。
而MySQL 通过上述的缓存内存和MVCC,以及相关的日志操作保障了性能,并发和事务之间的平衡,这也是MySQL被广泛使用的根本原因。
当然最终选择仍然需要看产品或者项目的具体需要,选择合适的数据库才是最重要的。














 2810
2810











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









