







在实战篇中,我主要想跟大家一起从几个简单的项目学起,通过我们对深度学习的学习,简单的完成几个模型的训练、预测,并应用在实际场景中,加深知识在脑海中的印象。
项目都是我从公司的项目中扣出来的功能模块,有些涉密的东西我会用其他的表达方式代替。
正文开始
背景
在入门篇中我们讲了一个最最最基本的深度学习框架,不管是目标检测、图像分割、图像分类,都可以往上套,只需要更换模型文件即可。
当然,大家如果是从网上克隆下来的开源代码,里面有训练脚本,改改路径什么的也能直接用,但是对里面的函数调用就要一层层的扒着去看了。这个没有硬性要求,看自己更喜欢哪种方式了,(我一般是用照这开源代码修改自己的训练脚本,这样代码比较熟悉)。
这一篇文章,我们就从图像分类入手,利用自己已有的数据训练一个二分类模型。我从项目中抽出了一个细胞分类的功能模块,并简化成二分类,跟大家分享。
医学专业知识
在做细胞分类之前,我们应该先简单的了解一下我们的目标细胞,不用100%全认识,只求知道个大概。
以下内容是公司前辈整理的专业知识,望珍惜。
我们的目标细胞是造血细胞中的红系和粒系 两类细胞
我们研究的小白鼠骨髓腔中的造血细胞主要由红系、粒系、巨核系组成,(骨髓腔内的造血细胞远不止上述三系细胞,且每系细胞还分为早中晚阶段,但是在HE染色中无法100%区分各系细胞或细胞各阶段,只能大致归为三类(红系/粒系/巨核系))
红系大多呈现岛状或灶状聚集分布特征;
粒系大多呈现片状分布特征。

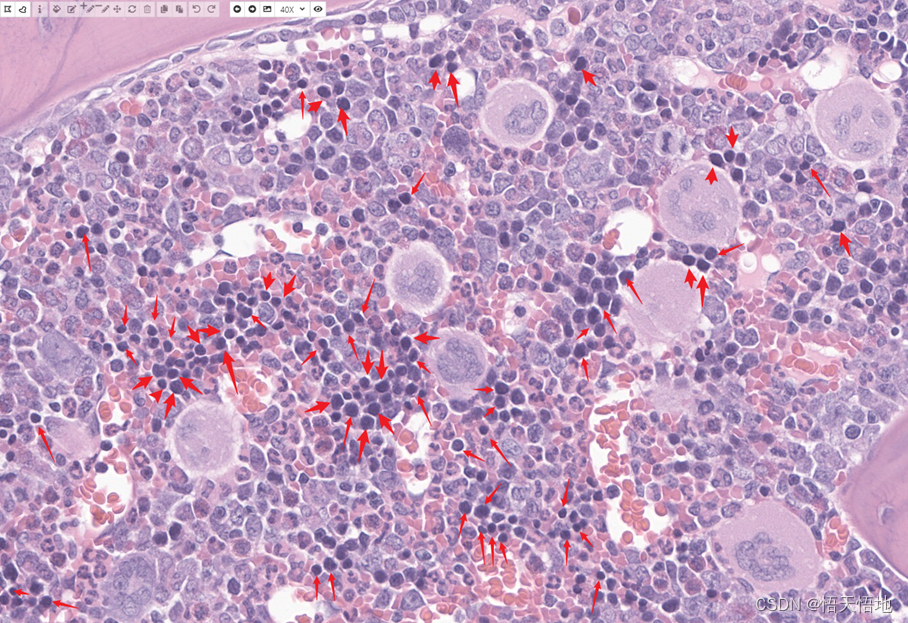
在显微镜40X下,红箭头所指为红系。红系细胞的特征是细胞核染色相对周围细胞较深,核形大多为圆形或多边形,细胞核不存在分叶或甜甜圈形态;细胞胞浆可有可无,可嗜酸性或嗜碱性。(图中为示例,未标记所有红系)
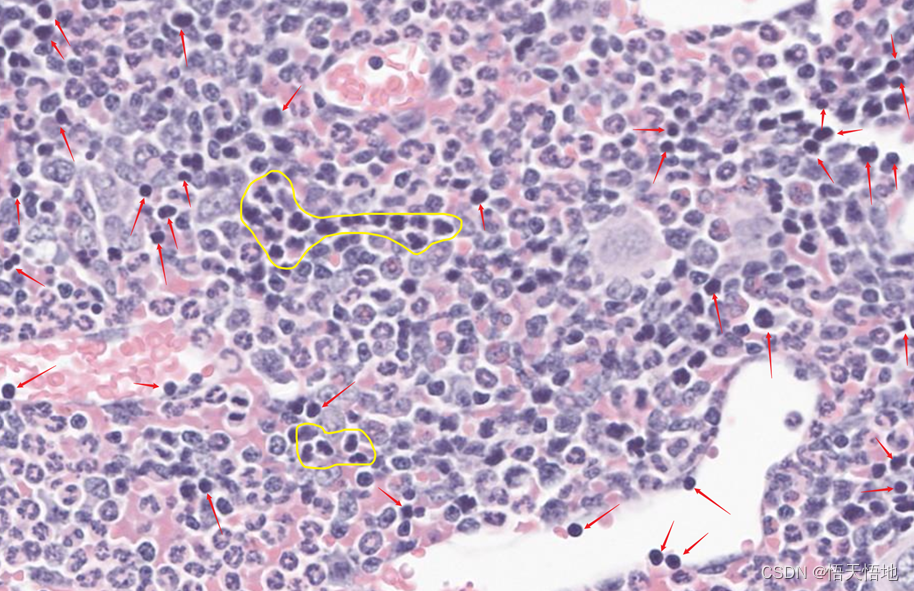
红箭头所指为红系。注意黄圈内的细胞,这些细胞核尽管染色深,但是细胞核存在明显的分叶,属于粒细胞。因此,判断红系/粒系一方面要看“深色”这一特征,还需要依靠核形进行判断,“核形”权重大于“深色”。(图中为示例,未标记所有红系)
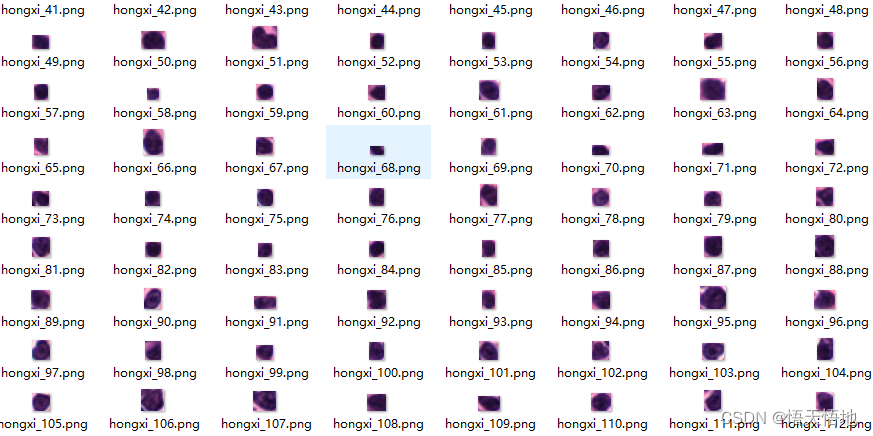
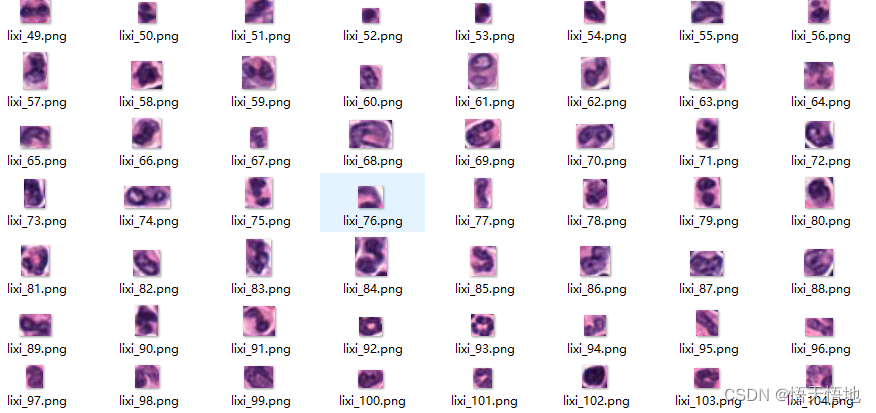
数据集
数据集是公司内部的数据,不能公开。
大家如果没有现成的数据的话,可以从网上下载猫狗二分类的数据集。
模型
模型选型 是inceptionV3
优点:此处省略一万字。
当然也可以使用其他的,我只是比较懒,随便拿了一个手头上顺手的。
模型测试结果
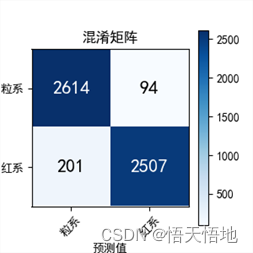
总结:实验结果 总体还算符合预期,毕竟有的细胞人都分不清。
缺点:inceptionV3需要的输入图像大小为320,而一个细胞的大小在20左右,不但会增加冗余数据,还增大计算量
后续有时间了再想其他的办法。
代码
model.py
# 模型文件
# 可以选择是否加载预训练模型
# 将模型的最后一层分类层改成2分类
import torch
import torch.nn as nn
import torchvision.models as models
class INCEPTIONV3(nn.Module):
def __init__(self, out_class, path=None):
super(INCEPTIONV3, self).__init__()
self.model = models.inception_v3(pretrained=False)
if path is not None:
self.model.load_state_dict(torch.load(path))
in_features = self.model.fc.in_features
self.model.fc = nn.Linear(in_features, out_class)
def forward(self, x):
x = self.model(x)
return xmydataset.py
# 自定义dataset
# 可以根据自己的需求对数据进行预处理
import cv2
import os
import torch
from torch.utils.data import Dataset
import torchvision.transforms as transforms
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=(0.5, 0.5, 0.5), std=(0.5, 0.5, 0.5))
])
class Dataset_hongli(Dataset):
def __init__(self, data, path_positive, path_negative, img_size):
self.data = data
self.path_positive = path_positive
self.path_negative = path_negative
self.img_size = img_size
def __len__(self):
return len(self.data)
def __getitem__(self, item):
_data, _label = self.data[item]
if len(_data) > 500:
_data = cv2.imread(_data)
else:
if _label == 0:
_data = cv2.imread(os.path.join(self.path_negative, _data))
if _label == 1:
_data = cv2.imread(os.path.join(self.path_positive, _data))
_data = transform(cv2.resize(_data, (self.img_size, self.img_size)))
_label = torch.tensor(_label, dtype=torch.long)
return _data, _label
train_inception.py
# 训练inception v3
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
import torch
import torch.nn as nn
import torch.optim as optim
from torch.autograd import Variable
from torch.utils.data import DataLoader
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, recall_score
from dataset_hongli import Dataset_hongli
import random
import argparse
import yaml
from model import INCEPTIONV3
import matplotlib.pyplot as plt
import numpy as np
import time
from tqdm import tqdm
import torchvision.transforms as transforms
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
transform = transforms.Compose([
transforms.ToTensor()]
)
random.seed(16)
def shuffle_data(data, label):
"""
打乱数据和标签
:param data:
:param label:
:return:
"""
_dataset = list(zip(data, label))
random.shuffle(_dataset)
return _dataset
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument('--config', default='config.yaml', type=str)
args = parser.parse_args()
# print(args.config)
# 获取参数
with open(args.config, errors='ignore') as f:
config = yaml.safe_load(f)
path_hong = config.get('path_imgs_positive')
path_li = config.get('path_imgs_negative')
batch_size = config.get('batch_size')
epochs = config.get('epochs')
lr = config.get('lr')
out_channel = config.get('out_channel')
image_size = config.get('image_size')
best_recall = config.get('best_recall')
checkpoint = config.get('checkpoint')
warmup_step = config.get('warmup_step')
cha = (lr - 0.000001) / warmup_step
hong_list = os.listdir(path_hong)
li_list = os.listdir(path_li)
data_list = shuffle_data(hong_list+li_list, [1] * len(hong_list)+[0] * len(li_list)) # 0 lixi 1 hongxi
# 划分数据集
train_data, test_data = train_test_split(data_list, test_size=0.2, random_state=16)
train_dataset = Dataset_hongli(train_data, path_hong, path_li, image_size)
test_dataset = Dataset_hongli(test_data, path_hong, path_li, image_size)
train_dataloader = DataLoader(train_dataset, batch_size, shuffle=True, num_workers=0)
test_dataloader = DataLoader(test_dataset, batch_size, shuffle=False, num_workers=0)
# 声明模型
cls_model = INCEPTIONV3(out_channel,'inception_v3_google-1a9a5a14.pth').to(device)
# cls_model.load_state_dict(torch.load(model_path))
output_params = list(map(id, cls_model.model.fc.parameters()))
feature_params = filter(lambda p: id(p) not in output_params, cls_model.model.parameters())
optimizer = optim.Adam([{'params': feature_params},
{'params': cls_model.model.fc.parameters(), 'lr': lr * 10}], lr=lr)
# optimizer = optim.Adam(cls_model.parameters(), lr=lr)
criterion = nn.CrossEntropyLoss().to(device)
train_acc, train_recall, train_loss = [], [], []
test_acc, test_recall, test_loss = [], [], []
lossing = []
for epoch in range(epochs):
start_time = time.time()
# 训练
cls_model.train()
run_loss, acc, recall = 0.0, 0.0, 0.0
# 手动调整学习率
# if epoch <= warmup_step:
# _lr = 0.000001 + epoch * cha
# for param_group in optimizer.param_groups:
# param_group['lr'] = _lr
for i, (data, label) in enumerate(train_dataloader):
data = data.to(device)
label = label.to(device)
optimizer.zero_grad()
pred,_ = cls_model(data)
loss = criterion(pred, label)
loss.backward()
optimizer.step()
run_loss += loss.item()
lossing.append(loss.item())
_, pred = torch.max(pred, 1)
acc += accuracy_score(label.cpu(), pred.cpu())
recall += recall_score(label.cpu(), pred.cpu(), average='micro')
if i % 30 == 29:
print('train: {epoch:%d}: loss=%3.3f, correct=%3.3f, recall=%3.3f'
% (epoch, run_loss / (i + 1), acc / (i + 1), recall / (i + 1)))
train_loss.append(run_loss / len(train_dataloader))
train_acc.append(acc / len(train_dataloader))
train_recall.append(recall / len(train_dataloader))
# 测试
cls_model.eval()
run_loss, acc, recall = 0.0, 0.0, 0.0
for i, (data, label) in enumerate(test_dataloader):
data = data.to(device)
label = label.to(device)
pred = cls_model(data)
loss = criterion(pred, label)
run_loss += loss.item()
_, pred = torch.max(pred, 1)
acc += accuracy_score(label.cpu(), pred.cpu())
recall += recall_score(label.cpu(), pred.cpu(), average='micro')
if i % 30 == 29:
print('test: {epoch:%d}: loss=%3.3f, correct=%3.3f, recall=%3.3f'
% (epoch, run_loss / (i + 1), acc / (i + 1), recall / (i + 1)))
test_loss.append(run_loss / len(test_dataloader))
test_acc.append(acc / len(test_dataloader))
test_recall.append(recall / len(test_dataloader))
# 保存模型
if test_recall[-1] > best_recall:
torch.save(cls_model.state_dict(), r'inception_v3_hong_li.pth')
best_recall = test_recall[-1]
end_time = time.time()
print("one epoch used time:", end_time - start_time)
if epoch % 20 == 19:
print('best recall:', best_recall)
x = np.arange(epoch + 1)
p1 = plt.subplot(131)
plt.title('loss')
plt.plot(x, train_loss, 'b')
plt.plot(x, test_loss, 'r')
p2 = plt.subplot(132)
plt.title('acc')
plt.plot(x, train_acc, 'b')
plt.plot(x, test_acc, 'r')
p3 = plt.subplot(133)
plt.title('recall')
plt.plot(x, train_recall, 'b')
plt.plot(x, test_recall, 'r')
plt.savefig('result.png')
print('best recall:', best_recall)
x = np.arange(epochs)
p1 = plt.subplot(131)
plt.title('loss')
plt.plot(x, train_loss, 'b')
plt.plot(x, test_loss, 'r')
p2 = plt.subplot(132)
plt.title('acc')
plt.plot(x, train_acc, 'b')
plt.plot(x, test_acc, 'r')
p3 = plt.subplot(133)
plt.title('recall')
plt.plot(x, train_recall, 'b')
plt.plot(x, test_recall, 'r')
plt.savefig('result.png')
# plt.show()
pred_inception.py
# 预测inceptionv3 输出混淆矩阵
from torch.utils.data import DataLoader
from dataset_hongli import Dataset_hongli
from model import INCEPTIONV3
import torch
import matplotlib.pyplot as plt
import os
from tqdm import tqdm
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 返回混淆矩阵
def ConfusionMatrix(numClass, imgPredict, Label):
mask = (Label >= 0) & (Label < numClass)
label = numClass * Label[mask] + imgPredict[mask]
count = torch.bincount(label.int(), minlength=numClass ** 2)
confusionMatrix = count.reshape(numClass, numClass)
return confusionMatrix
# 可视化混淆矩阵
def Visual_ConfusionMatrix(confusion, classes, save_path):
n = confusion.shape[0]
plt.figure(figsize=(n+1, n+1)) # 设置图片大小
# 1.热度图,后面是指定的颜色块,cmap可设置其他的不同颜色
plt.imshow(confusion, cmap=plt.cm.Blues)
plt.colorbar() # 右边的colorbar
# 2.设置坐标轴显示列表
indices = range(n)
# 第一个是迭代对象,表示坐标的显示顺序,第二个参数是坐标轴显示列表
plt.xticks(indices, classes, rotation=45) # 设置横坐标方向,rotation=45为45度倾斜
plt.yticks(indices, classes)
# 3.设置全局字体
# 在本例中,坐标轴刻度和图例均用新罗马字体['TimesNewRoman']来表示
# ['SimSun']宋体;['SimHei']黑体,有很多自己都可以设置
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 4.设置坐标轴标题、字体
plt.xlabel('预测值')
plt.ylabel('真实值')
plt.title('混淆矩阵', fontsize=12, fontfamily="SimHei") # 可设置标题大小、字体
# 5.显示数据
normalize = False
fmt = '.2f' if normalize else 'd'
thresh = confusion.max() / 2.
for i in range(n): # 第几行
for j in range(len(confusion[i])): # 第几列
plt.text(j, i, format(confusion[i][j], fmt),
fontsize=16, # 矩阵字体大小
horizontalalignment="center", # 水平居中。
verticalalignment="center", # 垂直居中。
color="white" if confusion[i, j] > thresh else "black")
plt.savefig(save_path)
if __name__ == '__main__':
save_path='confusion_matrix.png'
path_h = r'D:\gzz\data\hongli\dataset\dataset08_c2\hongxi'
path_l = r'D:\gzz\data\hongli\dataset\dataset08_c2\lixi'
# path_h = r'D:\gzz\data\hongli\dataset\testset05_c1\hongxi'
# path_l = r'D:\gzz\data\hongli\dataset\testset05_c1\lixi'
out_channel = 2
image_size = 320
batch_size=16
class_name=['粒系','红系']
hong_list = os.listdir(path_h)
li_list = os.listdir(path_l)
_dataset = list(zip(hong_list + li_list, [1] * len(hong_list) + [0] * len(li_list))) # 0 lixi 1 hongxi
test_dataset = Dataset_hongli(_dataset, path_h, path_l, image_size)
test_dataloader = DataLoader(test_dataset, batch_size, shuffle=False, num_workers=0)
cls_model = INCEPTIONV3(out_channel).to(device)
model_path = 'inception_v3_hong_li.pth'
cls_model.load_state_dict(torch.load(model_path))
all_pred = []
all_label = []
cls_model.eval()
with torch.no_grad():
for (data,label) in tqdm(test_dataloader):
data = data.to(device)
label = label
pred = cls_model(data)
_, pred = torch.max(pred, 1)
all_pred.extend(pred.data.cpu())
all_label.extend(label)
# print(all_pred)
# print(all_label)
a = ConfusionMatrix(out_channel, torch.tensor(all_pred), torch.tensor(all_label))
Visual_ConfusionMatrix(a, class_name, save_path)
补更:
后来我又试了其他几种模型,有监督的、无监督的都试了,结果都差不多,但跟预期有些差距。
补更+1:
偶然间的想法,因为我有庞大的细胞数据,可以利用特征匹配、特征检索做,kd树或faiss库。
















 978
978











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









