







 文章描述了一个使用AFL(AmericanFuzzyLop)进行模糊测试的实验过程,包括AFL的安装、QEMU模式的配置、coreutils程序的插桩编译以及fuzzing实验。实验比较了基于afl-gcc的编译器插桩和AFL-Qemu的动态插桩在fuzzing效率和效果上的差异,强调了输入种子和插桩方法对测试结果的影响。
文章描述了一个使用AFL(AmericanFuzzyLop)进行模糊测试的实验过程,包括AFL的安装、QEMU模式的配置、coreutils程序的插桩编译以及fuzzing实验。实验比较了基于afl-gcc的编译器插桩和AFL-Qemu的动态插桩在fuzzing效率和效果上的差异,强调了输入种子和插桩方法对测试结果的影响。
AFL 模糊测试实验
一、实验环境
Linux ubuntu 5.4.0-148-generic #165~18.04.1
二、实验准备
1.下载AFL并安装
git clone https://github.com/google/AFL
cd AFL
make
sudo make install
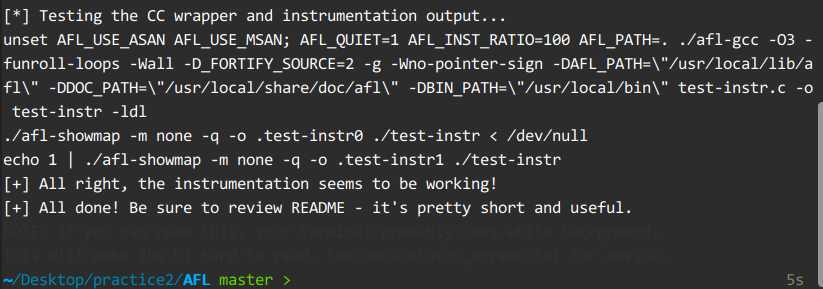
验证安装的程序,可以看见alf-gcc 和 afl-fuzz都安装成功
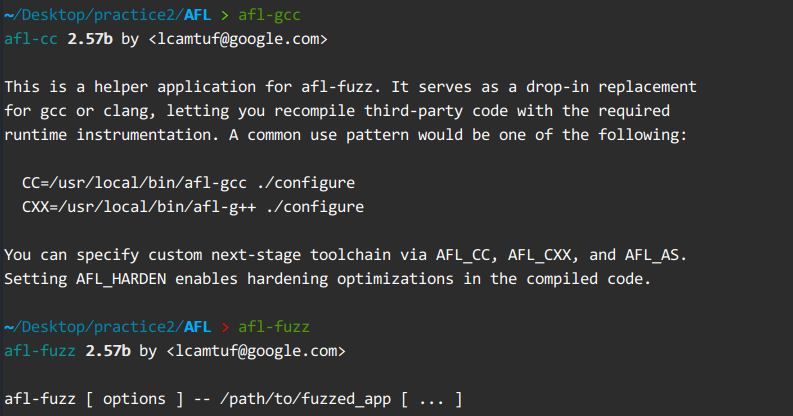
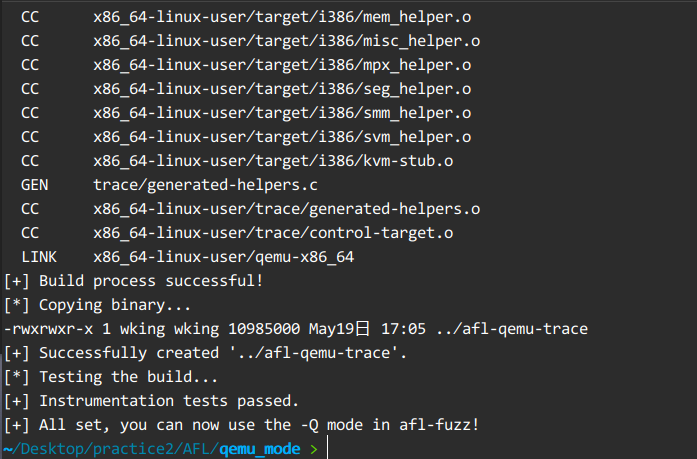
2.进入 qemu_mode 目录,使用build_qemu_support.sh 脚本构建AFL-Qemu。
此处安装不上,显示文件302,看来是地址已经转移了。
进入build_qemu_support.sh, 将url里的http://download.qemu-project.org换成http://download.qemu.org就行了
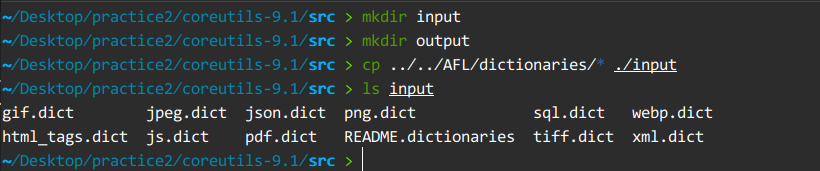
3.下载coreutils-9.1程序集
https://ftp.gnu.org/gnu/coreutils/
三、实验步骤
1.基于编译器的目标程序插桩
(1)使用 afl-gcc,生成 coreutils 的每个二进制程序
./configure CC=afl-gcc查看 coreutils 的 configure 选项,指定 cc=afl-gccmake生成 coreutils 二进制程序集。make 出来的每一个插桩后二进制均在 coreutils-9.1/src 目录下
(2)为 coreutils 的特定程序确定输入种子
直接用随机构造的任意字符串作为输入种子:
(3)在 coreutils-9.1/src 目录下,使用“afl-fuzz -i input -o output ./[程序名] @@”进行 fuzzing,一段时间后终止 fuzzing 并在 coreutils-9.1/src/output 目录下 查看测试结果。
- 执行
afl-fuzz -i input -o output ./cat -x @@出现报错:
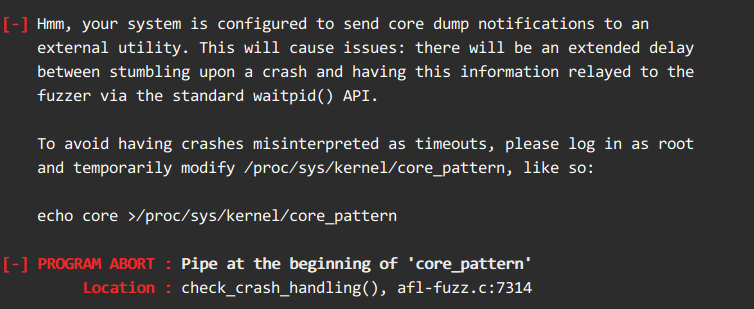
- 解决方式:在root权限下执行
echo core >/proc/sys/kernel/core_pattern
core_pattern是一个内核参数,用于指定生成核心转储文件(core dump)的名称和位置。在这个命令中,将core_pattern设置为"core",这意味着生成的核心转储文件将以"core"作为文件名。核心转储文件是在程序崩溃或异常终止时生成的,它包含了程序崩溃时内存的快照信息,可以用于调试和分析问题。
- 继续执行,查看afl-fuzz的结果
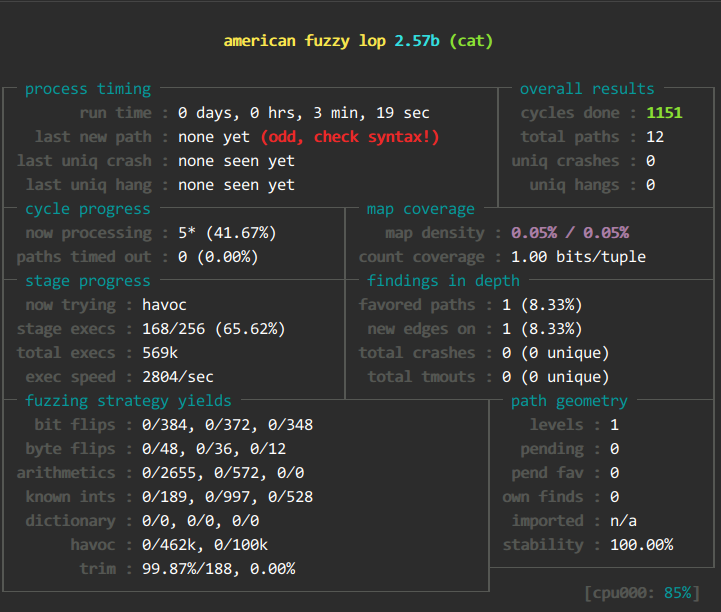
什么时候可以停止fuzzer?其中一个指标可以参考
cycles done的数字颜色,依次会出现洋葱红色,黄色,蓝色,绿色,变成绿色时就很难产生新的crash文件了。
2.基于 AFL-Qemu 的目标程序动态插桩
(1)重新生成 coreutils 的每个二进制程序
(不使用 afl-gcc,而是用默认 gcc 进行 configure/make)
./configure make
(2)使用 afl-fuzz 的-Q 选项,对3 个 coreutils 程序进行 fuzzing。
—用随机构造的任意字符串作为输入种子,参考实验步骤1—
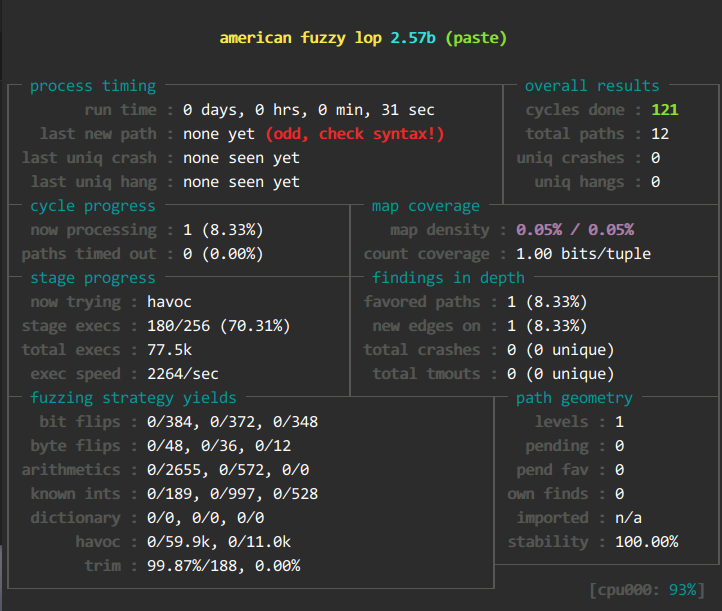
- afl-fuzz -Q -i input -o output ./cat -x @@
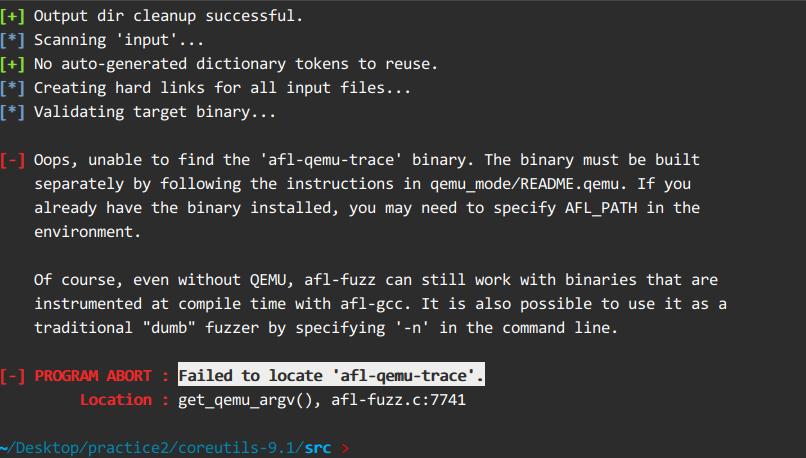
将
export AFL_PATH="/home/wking/Desktop/practice2/AFL"添加到shell的环境变量中,本次实验是 .zshrc
再次尝试:
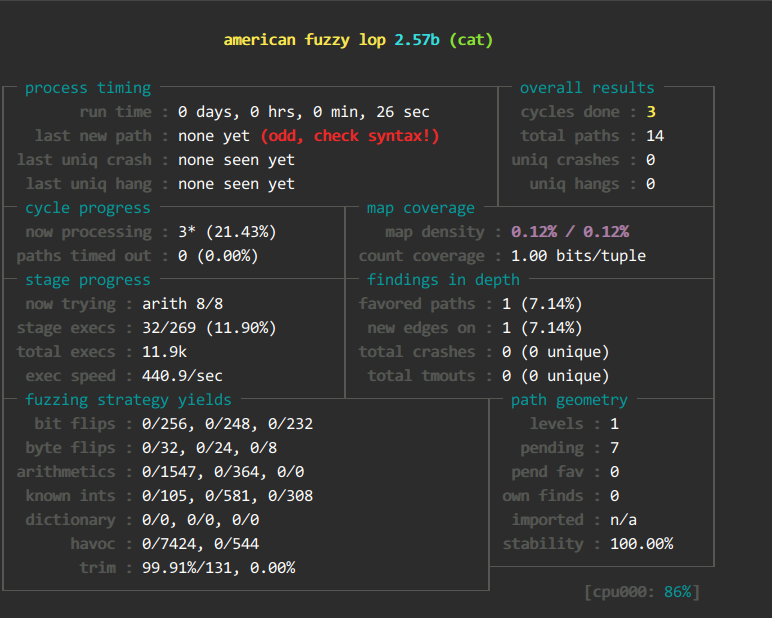
此时cycles done(相比于之前的方法)增加的速度非常缓慢
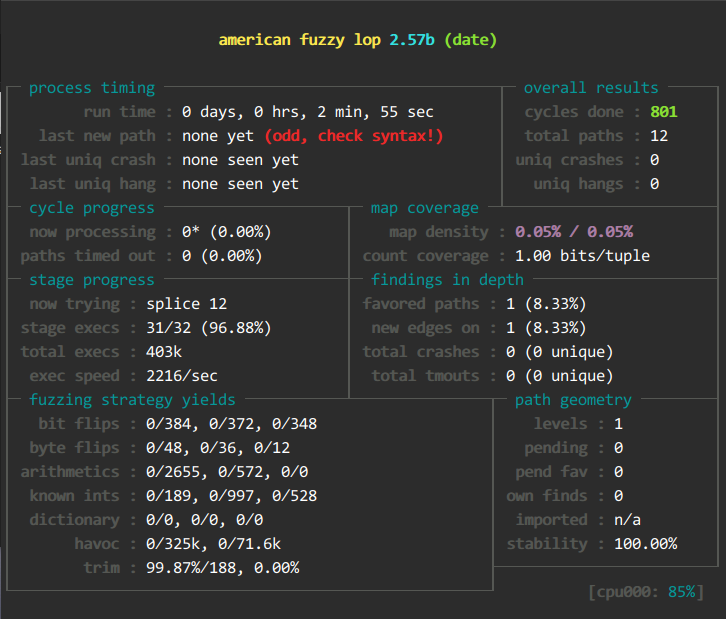
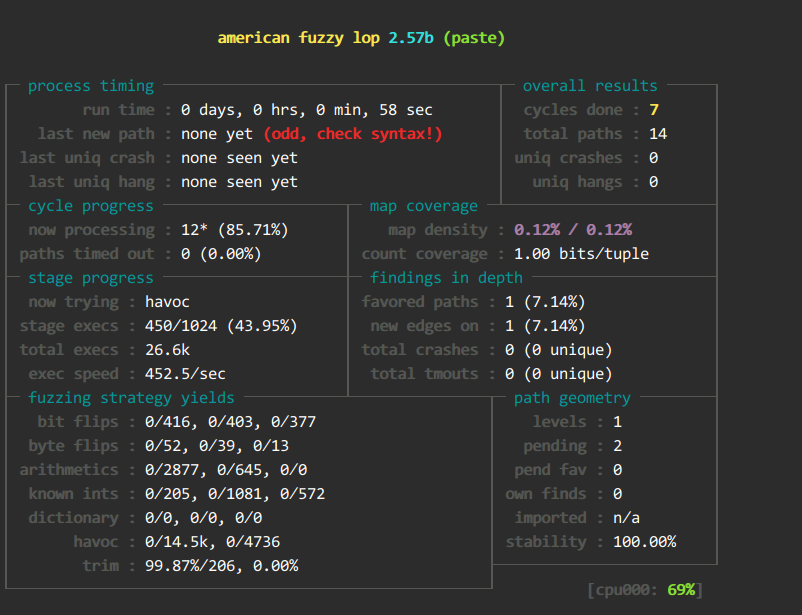
- afl-fuzz -Q -i input -o output ./paste -x @@
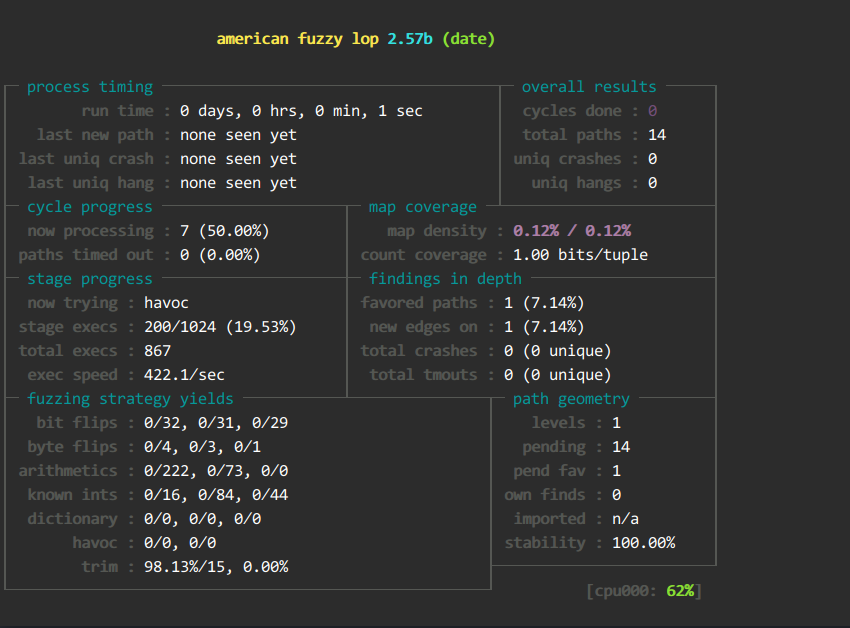
- afl-fuzz -Q -i input -o output ./date -x @@
四、实验总结
1.第“三、1(2)”步骤的两种输入种子构造方法,对于fuzzing结果的影响
(是否有影响?如果有,对最终获得的路径数量、路径数增长的速度等方面的具体影响)
答:
有影响。 AFL通过启发式算法自动确定输入。
使用随机种子可以更广泛地探索程序的不同路径和边界情况,它们可以帮助发现未知的漏洞和未经测试的代码路径,可以生成大量不同的随机数据,以尽可能广泛地覆盖输入空间,但缺乏特定的控制和指导。该方法可能会触发一些不常见的代码路径,也可能会增加路径数量,但由于输入种子的随机性,可能需要更多的时间来触发新的代码路径,所以路径数增长速度慢。
使用已有的输入种子可以更有针对性地测试程序的特定功能或场景,具有不同特征和特殊情况的输入种子可以帮助模糊测试尽可能多地探索程序的不同分支和逻辑,能获得更快的测试速度。该会触发更多的代码路径,因此可能会有更多的路径数量,同时由于输入种子是有效的,因此可能会更快地触发新的代码路径,路径增长速度较快。
2.第“三、1”基于编译插桩的 fuzzing 与第“三、2”的基于Qemu动态插桩的fuzzing,基本原理和实验效果两方面的差异
答:
实验原理:
- 基于编译插桩的fuzzing:该方法在源代码级别进行插桩,通过修改编译后的程序代码,将额外的监测和记录代码注入到程序中。这样可以在运行时捕获关键信息(如输入处理、分支覆盖等),以便对测试输入进行监控和评估。
- 基于Qemu动态插桩的fuzzing:这种方法使用Qemu模拟器来动态执行目标程序。在执行过程中,Qemu会在关键点(例如内存操作、系统调用等)插入监控代码,以收集关于程序行为和执行路径的信息。这样可以实时监控程序的运行情况,捕获输入的效果并提供覆盖率反馈。
实验效果:
- 基于编译插桩的fuzzing:这种方法通常可以提供更高的执行速度,因为代码插桩发生在编译阶段,生成的可执行文件已经被修改。它可以实现更精确的代码覆盖率分析,并能够更早地检测到一些编译时的错误和异常情况。
- 基于Qemu动态插桩的fuzzing:这种方法对于不可修改的二进制程序或者需要在运行时动态修改的情况更加适用。虽然它的执行速度通常较慢,但它可以提供更全面的监控和分析功能,包括内存访问、系统调用等方面的行为。动态插桩还可以帮助发现一些难以通过静态分析揭示的漏洞。
基于编译插桩的方法提供更高的执行速度和精确的代码覆盖率分析,适用于可修改的源代码。而基于Qemu动态插桩的方法可以应用于不可修改的二进制程序,并提供更全面的运行时监控和行为分析,但速度相对较慢。

















 2518
2518

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









