







kafka的基本操作
这里以docker部署的kafka为例
# 如果是使用wurstmeister/kafka镜像
docker exec -it <containerID> /bin/sh
cd /opt/kafka # kafka 安装目录
cd /kafka # topic消息记录文件目录
创建topic
sh kafka-topics.sh --create --zookeeper 192.168.1.40:2181 --replication-factor 3 --partitions 3 --topic test
# Replication-factor 表示该topic需要在不同的broker中保存几份,这里设置成1,表示在两个broker中保存两份
# Partitions 分区数
查看topic
# sh kafka-topics.sh --list --zookeeper 192.168.1.40:2181
LISTEN_IM_STATUS
__consumer_offsets
group_live
group_live_message
test
查看topic属性
# sh kafka-topics.sh --describe --zookeeper 192.168.1.40:2181 --topic group_live_message
Topic: group_live_message PartitionCount: 3(分区数) ReplicationFactor: 1(复制因子) Configs:
Topic: group_live_message Partition: 0 Leader: 1 Replicas: 1 Isr: 1
Topic: group_live_message Partition: 1 Leader: 2 Replicas: 2 Isr: 2
Topic: group_live_message Partition: 2 Leader: 0 Replicas: 0 Isr: 0
(分区) (1个主节点) (1个副本)
修改分区数
# sh kafka-topics.sh --alter --zookeeper 192.168.1.40:2181 --topic group_live_message --partitions 3
WARNING: If partitions are increased for a topic that has a key, the partition logic or ordering of the messages will be affected
Adding partitions succeeded!
修改副本数(复制因子)
# 1.不能通过以下方法实现更改副本数
# sh kafka-topics.sh --alter --zookeeper 192.168.1.40:2181 --topic group_live_message --replication-factor 3
Option "[replication-factor]" can't be used with option "[alter]"
Option Description
------ -----------
--alter Alter the number of partitions,
...
# 2.正确方式:https://kafka.apache.org/documentation/#basic_ops_increase_replication_factor
在/opt/kafka/bin 创建一个文件increase-replication-factor.json
文间内容:
{"version":1,
"partitions":[
{"topic":"group_live_message","partition":0,"replicas":[0,1,2]},
{"topic":"group_live_message","partition":1,"replicas":[0,1,2]},
{"topic":"group_live_message","partition":2,"replicas":[0,1,2]}
]}
# 3.执行脚本
# sh kafka-reassign-partitions.sh -zookeeper 192.168.1.40:2181 --reassignment-json-file increase-replication-factor.json --execute
Current partition replica assignment
{"version":1,"partitions":[{"topic":"group_live_message","partition":2,"replicas":[0],"log_dirs":["any"]},{"topic":"group_live_message","partition":1,"replicas":[2],"log_dirs":["any"]},{"topic":"group_live_message","partition":0,"replicas":[1],"log_dirs":["any"]}]}
Save this to use as the --reassignment-json-file option during rollback
Successfully started reassignment of partitions.
# 4.查看更新成功
# sh kafka-topics.sh --describe --zookeeper 192.168.1.40:2181 --topic group_live_message
Topic: group_live_message PartitionCount: 3 ReplicationFactor: 3 Configs:
Topic: group_live_message Partition: 0 Leader: 1 Replicas: 0,1,2 Isr: 1,0,2
Topic: group_live_message Partition: 1 Leader: 2 Replicas: 0,1,2 Isr: 2,1,0
Topic: group_live_message Partition: 2 Leader: 0 Replicas: 0,1,2 Isr: 0,2,1
订阅topic(消费信息)
# sh kafka-console-consumer.sh --bootstrap-server 192.168.1.40:9092 --topic group-live-message --from-beginning
生产者(发送消息)
# sh kafka-console-producer.sh --broker-list 192.168.1.40:9092 --topic group-live-message
删除topic
step1:
如果需要被删除topic 此时正在被程序 produce和consume,则这些生产和消费程序需要停止。因为如果有程序正在生产或者消费该topic,则该topic的offset信息一致会在broker更新。调用kafka delete命令则无法删除该topic。同时,需要设置 auto.create.topics.enable = false,默认设置为true。如果设置为true,则produce或者fetch 不存在的topic也会自动创建这个topic。这样会给删除topic带来很多意向不到的问题。所以,这一步很重要,必须设置auto.create.topics.enable = false,并认真把生产和消费程序彻底全部停止。
step2:
server.properties设置delete.topic.enable=true如果没有设置delete.topic.enable=true,则调用kafka 的delete命令无法真正将topic删除,而是显示(marked for deletion)
step3:
调用命令删除topic:
sh kafka-topics.sh --delete --zookeeper 192.168.1.40:9092 --topic group_live_message
step4:
删除kafka存储目录(server.properties文件log.dirs配置,默认为"/data/kafka-logs")相关topic的数据目录。
注意:如果kafka 有多个 broker,且每个broker 配置了多个数据盘(比如/data/kafka-logs,/data1/kafka-logs...),且topic也有多个分区和replica,则需要对所有broker的所有数据盘进行扫描,删除该topic的所有分区数据。一般而言,经过上面4步就可以正常删除掉topic和topic的数据。但是,如果经过上面四步,还是无法正常删除topic,则需要对kafka在zookeeer的存储信息进行删除。具体操作如下:
(注意:以下步骤里面,kafka在zk里面的节点信息是采用默认值,如果你的系统修改过kafka在zk里面的节点信息,则需要根据系统的实际情况找到准确位置进行操作)
step5:
找一台部署了zk的服务器,使用命令:
bin/zkCli.sh -server 192.168.1.40:9092
登录到zk shell,然后找到topic所在的目录:ls /brokers/topics,找到要删除的topic,然后执行命令:
deleteall /brokers/topics/[topic name]
即可,此时topic被彻底删除。如果topic 是被标记为 marked for deletion,则通过命令 ls /admin/delete_topics,找到要删除的topic,然后执行命令:
deleteall /admin/delete_topics/[topic name]
备注:
网络上很多其它文章还说明,需要删除topic在zk上面的消费节点记录、配置节点记录,比如:
deleteall /consumers/[consumer-group]
deleteall /config/topics/[topic name]
其实正常情况是不需要进行这两个操作的,如果需要,那都是由于操作不当导致的。比如step1停止生产和消费程序没有做,step2没有正确配置。也就是说,正常情况下严格按照step1 – step5 的步骤,是一定能够正常删除topic的。
step6:
完成之后,调用命令:
./bin/kafka-topics.sh --list --zookeeper [zookeeper server:port]
查看现在kafka的topic信息。正常情况下删除的topic就不会再显示。但是,如果还能够查询到删除的topic,则重启zk和kafka即可。
kafka消息保留配置
配置在/bin/server.properties文件中
-
log.retention.ms消息时间Kafka通常根据时间决定数据可以保留多久。默认使用log.retention.hours参数配置时间,默认值是168小时,也就是一周。除此之外,还有其他两个参数,
log.retention.minutes和log.retention.ms,这三个参数作用是一样的,都是决定消息多久以会被删除,不过还是推荐使用log.retention.ms,如果指定了不止一个参数,Kafka会优先使用最小值的那个参数。 -
log.retention.bytes消息大小通过保留的消息字节数来判断小是否过期,它的值通过参数
log.retention.bytes来指定,作用在每一个分区上,也就是说如果一个包含8个分区的主题,并且log.retention.bytes被设置为1GB,那么这个主题最多可以保留8GB的数据,所以,当主题的分区个数增加时,整个主题可以保留的数据也随之增加。
注意:如果同时指定了两个参数没只要任意一个参数得到满足,消息就会被删除。例如,假设log.retention.ms为86400000(也就是一天),log.retention.bytes的值设置为1GB,如果消息字节总数在不到一天的时间就超过了1GB,那么堆出来的部分就会被删除,相反,如果消息字节总数小与1GB,那么一天之后这些消息也会被删除,尽管分区的数据总量小于1GB
-
log.segment.bytes日志片段大小当消息来到broker时,它们就会被追加到分区的当前日志片段上,当日志片段大小到达
log.segment.bytes指定的上限(默认是1GB)时,当前日志片段就会被关闭,一个新的日志片段就会被打开。如果一个日志之片段被关闭,就开始等待过期时间。这个参数的值越小们就会越频繁的关闭和分配新文件,从而降低了磁盘写入的整体效率。 -
log.segment.ms日志片段时间指定了多长时间之后日志片段会被关闭,就像
log.retention.bytes和log.retention.ms这两个参数一样。log.segment.bytes和log.segment.ms这两个参数之间也不存在互斥问题。日志片段会在大小或时间达到上限时被关闭,就看哪个条件晓得到满足。默认情况下log.segment.ms没有设定值,所以只根据大小来关闭日志片段 -
message.max.bytes单条消息大小broker通过设置
message.max.bytes参数来限制单个消息的大小,默认值时1000000,也就是1MB。如果生产者尝试发送的消息超过1MB,不仅消息不会被接受,还会受到broker返回的错误信息。跟其他与字节相关的配置参数一样,该参数指的是压缩后的消息大小,也就是说,只要压缩后的消息小于message.max.bytes指定的值,消息的实际大小可以远大于这个值。
kafka集群状态(访问zookeeper查看信息)
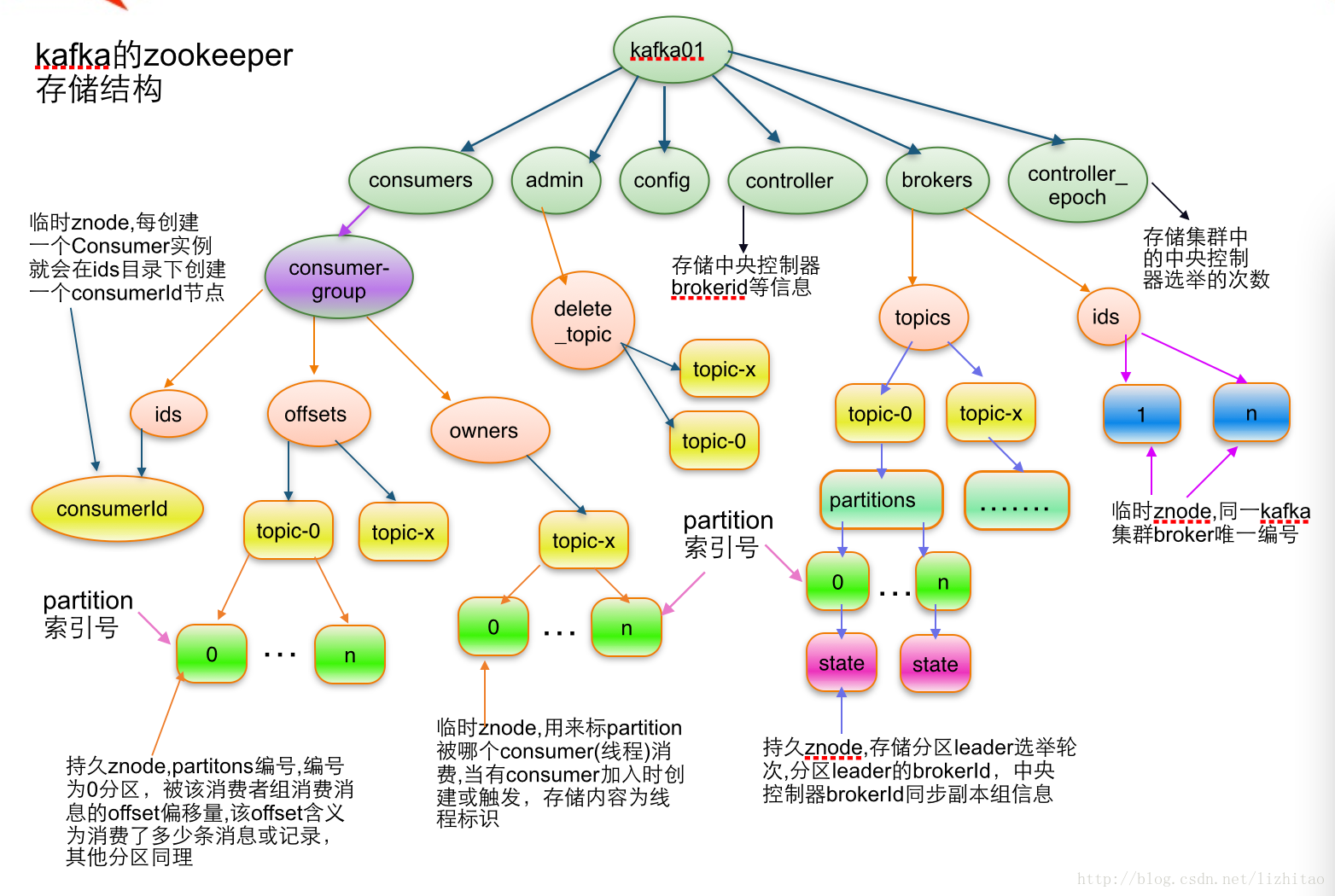
# window连接zookeeper
./zkCli.cmd -server ip:port
# 查看broker存活情况
ls /brokers/ids
Q&A
当kafka集群宕机,或者集群中其中一台机器系统重新安装后部署kafka时,我们就要注意启动kafka时的日志情况。docker logs kafka
- Error while executing topic command : replication factor: 3 larger than available brokers: 0
这个问题是kafka有部分broker实例没有加入到kafka集群中,需要通过连接zookeeper,执行 ls /brokers/ids 查看有几台机器没有被注册上来。
- The Cluster ID xxx doesn’t match stored clusterId Some(xxx) in meta.properties. The broker is trying
意思是集群id跟元数据meta.properties中存储的不一致,导致启动失败。因此去查看meta.properties文件中的元数据信息。这个文件的存储路径是通过/config/server.properties配置文件中的log.dirs属性配置的。所以通过配置文件找到meta.properties,修改里面的cluster.id或者删除meta.properties 即可。如修改cluster.id重新部署也不行,则把meta.properties文件删除。
Kafka使用方法
Java中使用kafka进行通信
依赖
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2271
2271











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









