







 Kafka Broker 存储原理1.文件的存储结构1.1 partition分区为了实现横向扩展,把不同数据存放在不同的Broker上,同时降低单台服务器的访问压力,我们把一个topic中的数据分隔成多个partition。一个partition中的消息是有序的,顺序写入,但是全局不一定有序。在服务器上,每个partition都有一个物理目录,topic名字后面的数字标号即代表分区。1.2 replica副本为了提高分区的可靠性,kafka又设计了副本机制。创建topic的时候,通过指定
Kafka Broker 存储原理1.文件的存储结构1.1 partition分区为了实现横向扩展,把不同数据存放在不同的Broker上,同时降低单台服务器的访问压力,我们把一个topic中的数据分隔成多个partition。一个partition中的消息是有序的,顺序写入,但是全局不一定有序。在服务器上,每个partition都有一个物理目录,topic名字后面的数字标号即代表分区。1.2 replica副本为了提高分区的可靠性,kafka又设计了副本机制。创建topic的时候,通过指定
Kafka Broker 存储原理
1.文件的存储结构
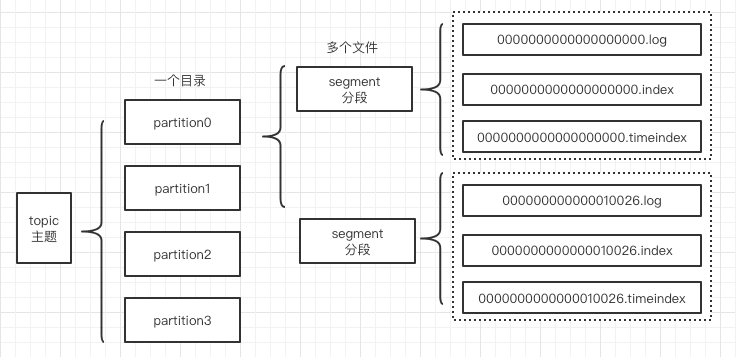
1.1 partition分区
为了实现横向扩展,把不同数据存放在不同的Broker上,同时降低单台服务器的访问压力,我们把一个topic中的数据分隔成多个partition。
一个partition中的消息是有序的,顺序写入,但是全局不一定有序。
在服务器上,每个partition都有一个物理目录,topic名字后面的数字标号即代表分区。
1.2 replica副本
为了提高分区的可靠性,kafka又设计了副本机制。
创建topic的时候,通过指定replication-factor确定topic的副本数。
注意:副本数必须小于等于节点数,而不能大于Broker的数量,否则会报错。
./kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 4 --partitions 1 --topic overrep
这样就可以保证,绝对不会有一个分区的两个副本分布在同一个节点上,不然副本机制也失去了备份的意义了。
这些所有的副本分为两种角色,leader对外提供读写服务。follower唯一的任务就是从leader异步拉取数据。
思考:为什么不能像MySQL一样实现读写分离?写操作都在leader上,读操作都在follower上。
这个是设计思想的不同。读写都发生在leader节点,就不存在读写分离带来的一致性问题了,这个叫做单调读一致性。
1.3 如何区分leader
问题来了,如果分区有多个副本,哪一个节点上的副本是leader呢?
怎么查看所有副本中谁是leader?
sh ./kafka-topics.sh --topic businessMessage --describe --zookeeper localhost:2181
Topic: businessMessage PartitionCount: 3 ReplicationFactor: 3 Configs:
Topic: businessMessage Partition: 0 Leader: 1 Replicas: 1,2,0 Isr: 1,0,2
Topic: businessMessage Partition: 1 Leader: 2 Replicas: 2,0,1 Isr: 0,1,2
Topic: businessMessage Partition: 2 Leader: 0 Replicas: 0,1,2 Isr: 0,1,2
解释:这个topic有3个分区3个副本。
第一个分区的3个副本编号0,1,2(代表Broker的序号),同步中的是0,1,2。第二个副本是leader。
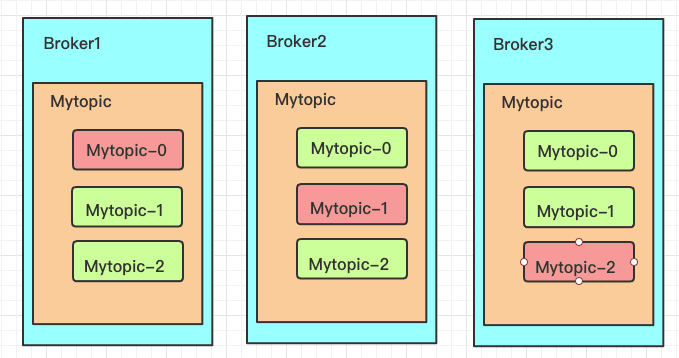
1.4 副本在Broker的分布
实际上,分配策略是由Admin Utils.scala的assign Replicas To Brokers函数决定的。
规则如下:
-
fir to fall,副本因子不能大于Broker的个数;
-
第一个分区(编号为0的分区) 的第一个副本放置位置是随机从broker List选择的;
-
其他分区的第一个副本放置位置相对于第0个分区依次往后移。
也就是说:如果我们有5个Broker,5个分区,假设第1个分区的第1个副本放在第四个Broker上,那么第2个分区的第1个副本将会放在第五个Broker上; 第三个分区的第1个副本将会放在第一个Broker上; 第四个分区的第1个副本将会放在第二
个Broker上,依次类推; -
每个分区剩余的副本相对于第1个副本放置位置其实是由next Replica Shift决定的,而这个数也是随机产生的。

这样设计可以提高容灾能力。怎么讲?
在每个分区的第一个副本错开之后,一般第一个分区的第一个副本(按Broker编号排序) 都是leader。leader是错开的,不至于一挂影响太大。
bin目录下的kafka-reassign-partitions.
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









