






本文基于kubernetes源码1.27整理
kubelet介绍
引用官方文档的kubelet的简介。
kubelet 是在每个节点上运行的主要 “节点代理”。
kubelet 是基于 PodSpec 来工作的。每个 PodSpec 是一个描述 Pod 的 YAML 或 JSON 对象。
1 kubelet 接受通过各种机制(主要是通过 apiserver)提供的一组 PodSpec。
2 确保这些 PodSpec 中描述的容器处于运行状态且运行状况良好。
kubelet启动过程分析
笔者主要针对以上两点去阅读kubelet的源码。关于k8s源码的目录结构和cobra命令行框架介绍,本文不介绍。
众所周知k8s组件的启动入口都在cmd目录下,kubelet也是。先分析kubelet的启动过程.
在main方法中进入NewKubeletCommand方法,
func NewKubeletCommand() *cobra.Command {
cmd := &cobra.Command{
Use: componentKubelet,
Long: `The kubelet is the primary "node agent" that runs on each
DisableFlagParsing: true,
SilenceUsage: true,
RunE: func(cmd *cobra.Command, args []string) error {
……
}
……在RunE方法的结尾,进入kubelet的Run方法。忽略掉非主干代码,启动流程如下图。
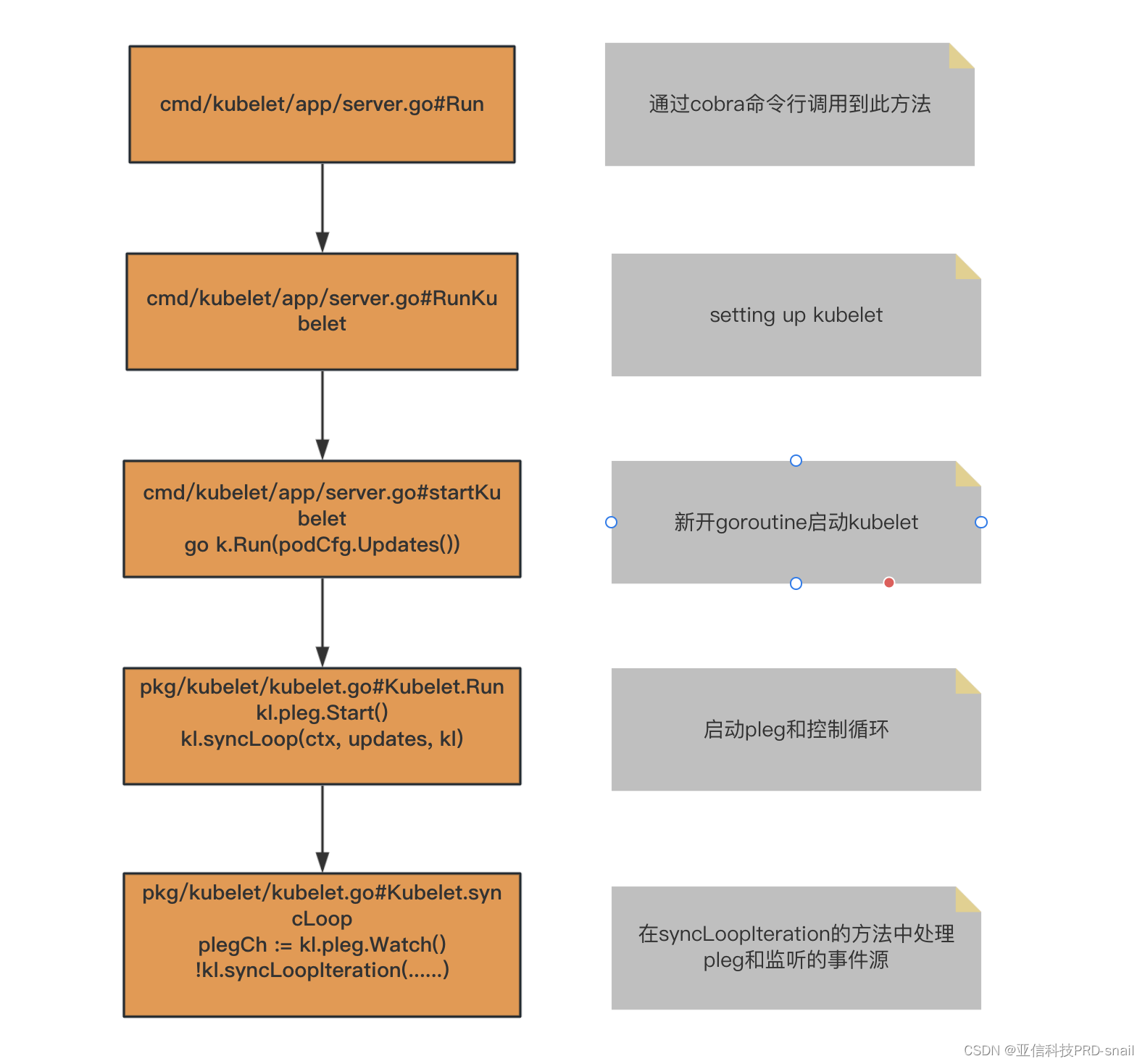
kubelet的pod变更事件来源分析
Kubelet的主要职责接受事件,操作容器。
获取变更事件的所有channel
在简介中的第一条-kubelet 接受通过各种机制(主要是通过 apiserver)提供的一组 PodSpec,是通过apiserver/http/file的事件来源。
第二条-确保这些 PodSpec 中描述的容器处于运行状态且运行状况良好,是通过PLEG的事件来源。(PLEG=pod lifecycle event generate)
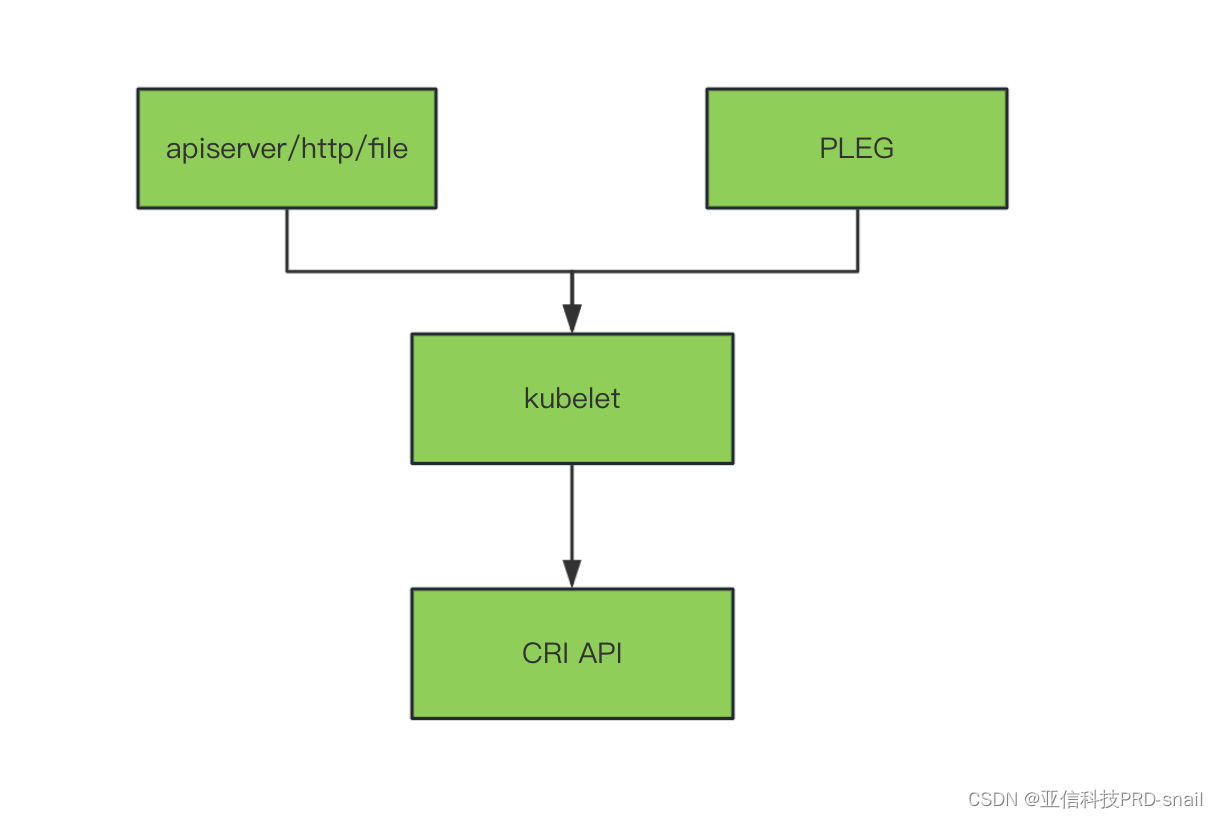
这两方面事件来源是通过两个channel实现的。分析一下两个channel的源码。
在syncLoopIteration方法中可以看到,事件的几个主要来源。(主要分析前两个channel)
func (kl *Kubelet) syncLoopIteration(ctx context.Context, configCh <-chan kubetypes.PodUpdate, handler SyncHandler,syncCh <-chan time.Time, housekeepingCh <-chan time.Time, plegCh <-chan *pleg.PodLifecycleEvent) bool {
select {
case u, open := <-configCh://重点关注对象
case e := <-plegCh://重点关注对象
case <-syncCh:
case update := <-kl.livenessManager.Updates():
case update := <-kl.readinessManager.Updates():
case update := <-kl.startupManager.Updates():
case <-housekeepingCh:
}
return true
}本方法消费channel中数据。
configCh和plegCh两个channel的写入来源总体源码流程如下(后续分析细致的变化来源):
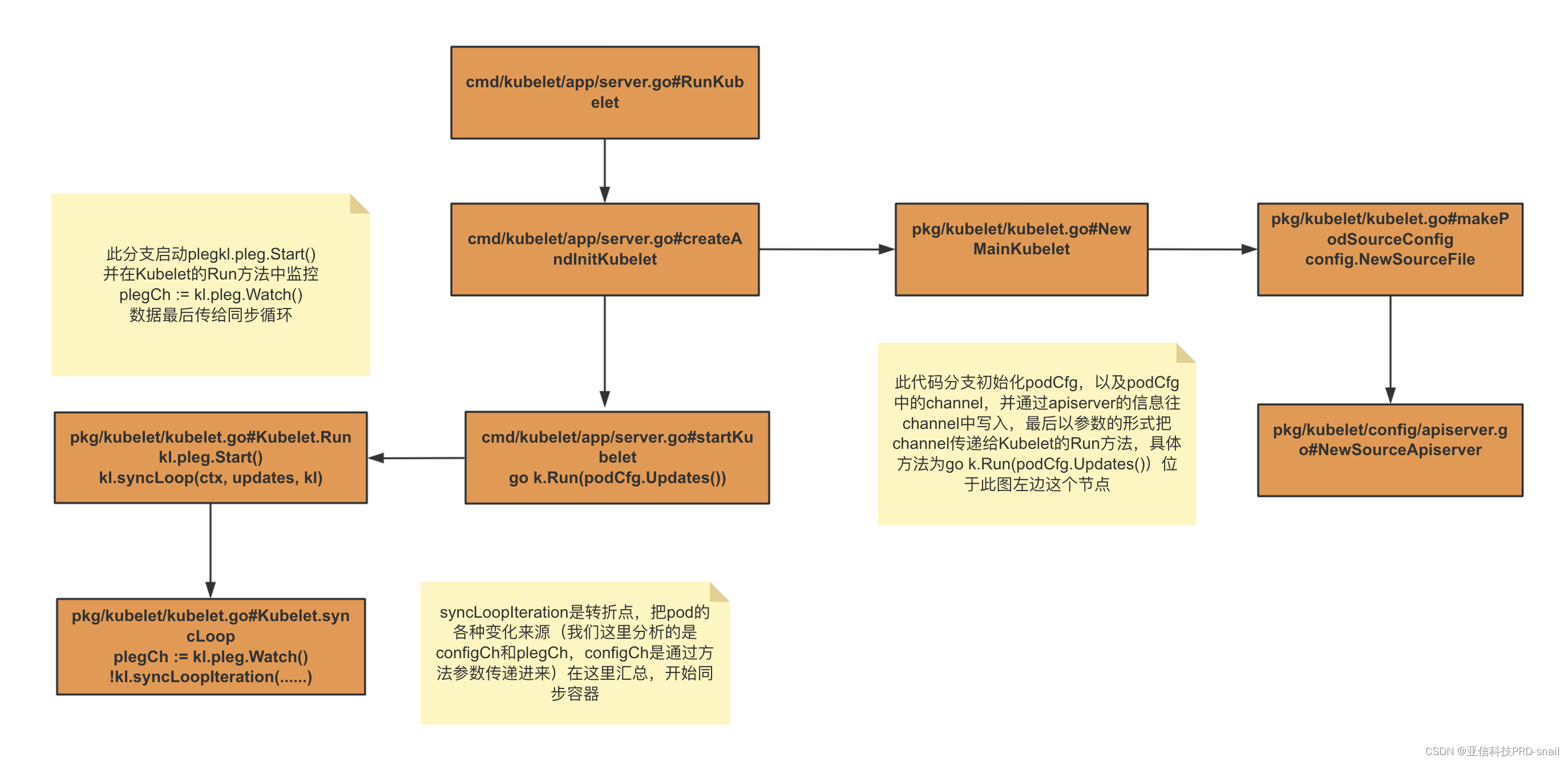
图中configCh的来源以apiserver为例
apiserver/http/file的podspec变更来源的通道configCh
单向configCh的channel产生的位置。根据源码cmd/kubelet/app/server.go startkubelet方法中go k.Run(podCfg.Updates())
寻找podcfg初始化的地方。
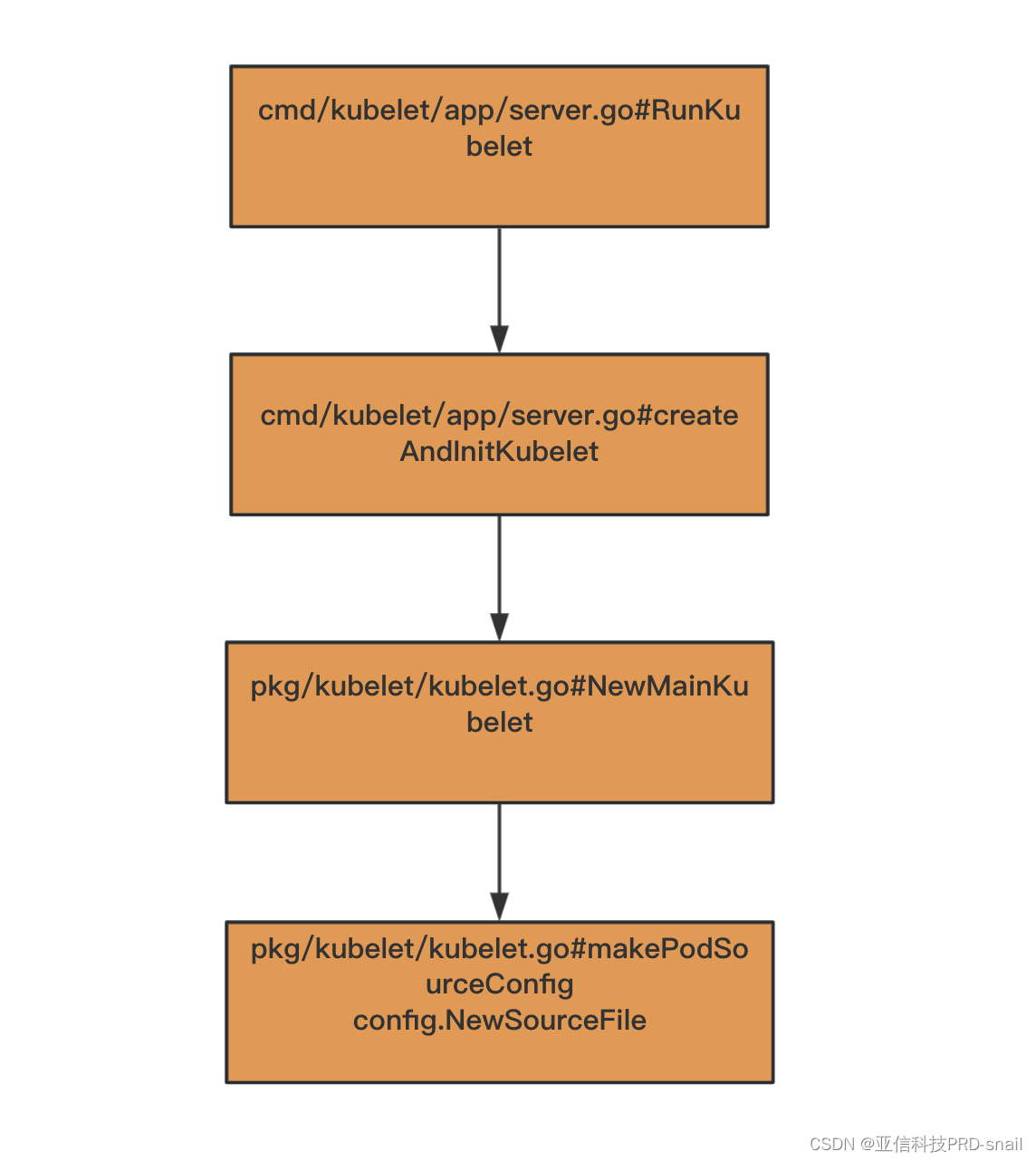
三种configsource的初始化源码如下,最后一个参数就是事件的变化通道。
// define file config source
if kubeCfg.StaticPodPath != "" {
klog.InfoS("Adding static pod path", "path", kubeCfg.StaticPodPath)
config.NewSourceFile(kubeCfg.StaticPodPath, nodeName, kubeCfg.FileCheckFrequency.Duration, cfg.Channel(ctx, kubetypes.FileSource))
}
// define url config source
if kubeCfg.StaticPodURL != "" {
klog.InfoS("Adding pod URL with HTTP header", "URL", kubeCfg.StaticPodURL, "header", manifestURLHeader)
config.NewSourceURL(kubeCfg.StaticPodURL, manifestURLHeader, nodeName, kubeCfg.HTTPCheckFrequency.Duration, cfg.Channel(ctx, kubetypes.HTTPSource))
}
if kubeDeps.KubeClient != nil {
klog.InfoS("Adding apiserver pod source")
config.NewSourceApiserver(kubeDeps.KubeClient, nodeName, nodeHasSynced, cfg.Channel(ctx, kubetypes.ApiserverSource))
}通道的写入方代码,以第三个apiserver为例:
NewSourceApiserver方法代码中可以看到熟悉的listAndWatch,并没有使用informer机制。
lw := cache.NewListWatchFromClient(c.CoreV1().RESTClient(), "pods", metav1.NamespaceAll, fields.OneTermEqualSelector("spec.nodeName", string(nodeName)))
klog.InfoS("Watching apiserver")
newSourceApiserverFromLW(lw, updates)
}()
newSourceApiserverFromLW方法代码中可以找到channel的写入。
func newSourceApiserverFromLW(lw cache.ListerWatcher, updates chan<- interface{}) {
send := func(objs []interface{}) {
var pods []*v1.Pod
for _, o := range objs {
pods = append(pods, o.(*v1.Pod))
}
updates <- kubetypes.PodUpdate{Pods: pods, Op: kubetypes.SET, Source: kubetypes.ApiserverSource}
}
r := cache.NewReflector(lw, &v1.Pod{}, cache.NewUndeltaStore(send, cache.MetaNamespaceKeyFunc), 0)
go r.Run(wait.NeverStop)
}
获取到来源还需要处理,从config.NewSourceApiserver(kubeDeps.KubeClient, nodeName, nodeHasSynced, cfg.Channel(ctx, kubetypes.ApiserverSource)) 开始,最后一个参数cfg.Channel(ctx, kubetypes.ApiserverSource),跟踪代码,
func (m *Mux) ChannelWithContext(ctx context.Context, source string) chan interface{} {
newChannel := make(chan interface{})
m.sources[source] = newChannel
go wait.Until(func() { m.listen(source, newChannel) }, 0, ctx.Done())
return newChannel
}进入方法m.listen
func (m *Mux) listen(source string, listenChannel <-chan interface{}) {
for update := range listenChannel {
m.merger.Merge(source, update)
}
}下面就是根据读取的内容,处理后写入channel,找到写入来源。
func (s *podStorage) Merge(source string, change interface{}) error {
adds, updates, deletes, removes, reconciles := s.merge(source, change)
s.updates <- *removes
return nil
}
PLEG的变更事件来源channel
从syncLoopIteration方法追踪plegCh的channel写入
在启动过程的第四步看到看到方法kl.pleg.Start(),在此方法中运行重要线程Relist。
func (g *GenericPLEG) Start() {
g.runningMu.Lock()
defer g.runningMu.Unlock()
if !g.isRunning {
g.isRunning = true
g.stopCh = make(chan struct{})
go wait.Until(g.Relist, g.relistDuration.RelistPeriod, g.stopCh)
}
}Relist的作用是获取所有的Pod列表,并将其转换为kubecontainer.Pods类型,更新podRecords中的当前Pod列表,比较旧的Pod和当前Pod,并生成相应的事件,并写入通道。以下代码是relist方法中的一部分。
select {
case g.eventChannel <- events[i]:
default:
metrics.PLEGDiscardEvents.Inc()
klog.ErrorS(nil, "Event channel is full, discard this relist() cycle event")
}
可以看到PLEG事件的写入来源源码g.eventChannel <- events[i],也已经找到。
kubelet和容器交互处理变更
我们分析了主要的事件来源,其他存活探针、就绪探针等产生的事件,有兴趣的同学可以自己摸索。
下面可以进入到和容器交互的源码上了。回到syncLoopIteration方法;
select {
case u, open := <-configCh:
switch u.Op {
case kubetypes.ADD:
klog.V(2).InfoS("SyncLoop ADD", "source", u.Source, "pods", klog.KObjSlice(u.Pods))
handler.HandlePodAdditions(u.Pods)
case kubetypes.UPDATE:
case kubetypes.REMOVE:
case kubetypes.RECONCILE:
case kubetypes.DELETE:
case kubetypes.SET:
}追踪ADD事件代码,从HandlePodAdditions往下的流程如下:
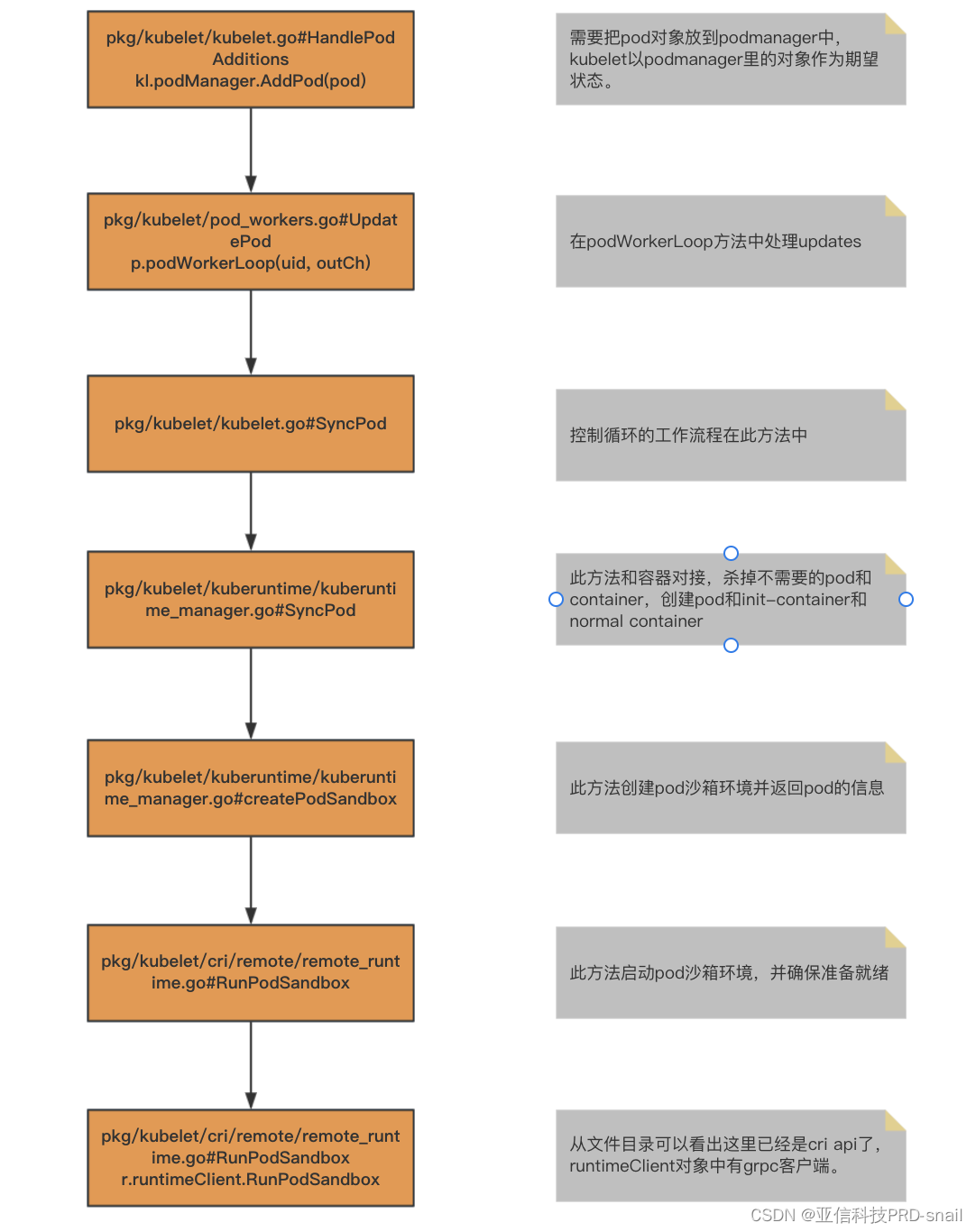 由于kubernetes已经把docker代码移除,管理pod的主干代码就分析到这里、后续是grpc调用cri api的流程,不在分析范围。
由于kubernetes已经把docker代码移除,管理pod的主干代码就分析到这里、后续是grpc调用cri api的流程,不在分析范围。
总结
简单阅读了kubelet的启动源码后,我们从重点方法syncLoopIteration开始,按照kubelet的定义,忽略了存活探针和就绪探针等产生的事件。分析了configCh和plegCh两个channel的写入源头,最后搞清kubelet如何同步变化到容器,理清kubelet的主逻辑。















 462
462











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









