







 序列模式是数据挖掘的一种,关注用户在不同时间点的交易行为。本文介绍了GSP、SPADE和PrefixSpan三种序列模式挖掘算法,包括它们的基本原理和区别。GSP通过连接和删除操作生成频繁序列,SPADE利用ID_list减少数据库扫描,而PrefixSpan通过前缀递归挖掘频繁序列。实验展示了这些算法如何找出频繁序列,但并未解决序列间时间间隔的问题。
序列模式是数据挖掘的一种,关注用户在不同时间点的交易行为。本文介绍了GSP、SPADE和PrefixSpan三种序列模式挖掘算法,包括它们的基本原理和区别。GSP通过连接和删除操作生成频繁序列,SPADE利用ID_list减少数据库扫描,而PrefixSpan通过前缀递归挖掘频繁序列。实验展示了这些算法如何找出频繁序列,但并未解决序列间时间间隔的问题。
什么是序列模式

Apriori处理的数据没有考虑每个客户在超市多次购物的情况。
序列模式:一个用户在不同时间点的交易记录就构成了一个购买序列,
N个用户的购买序列就组成一个规模为N的序列数据集.。
Apriori目的:挖掘出频繁集,找到其中的关联规则
对于Apriori处理的数据集设置支持度阈值为:2
则(面包机、面包)为频繁集
设置可信度为:0.7
则关联规则:面包机 ——> 面包
这条关联规则的意义:在一次交易中买了面包机,就很可能买面
序列模式目的:挖掘满足最小支持度的频繁序列
对于序列模式处理的数据集设置支持度阈值为:2
则<面包机 面包> 为频繁序列
这条频繁序列的意义:如果一个顾客买了面包机,那么他以后就回来买面包
如果我来经营一家超市,通过Apriori算法,我需要将面包机与面包放在一起,通过序列模式,我知道如果一段时间内面包机卖了很多,我将多进货面包
序列模式三个算法GSP SPADE PrifixSpan
GSP
GSP算法由Srikant&Agrawal于1996年提出

举例:
设置支持度阈值为:3
(1)扫描序列数据库,对每一项进行支持度统计,得到长度为1的频繁序列模式


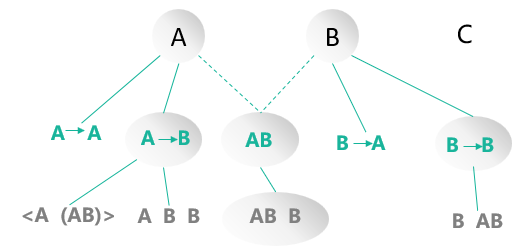
(2)根据长度为1的频繁序列,通过连接操作生成长度为2的候选序列模式,然后扫描序列数据库,计算每个候选序列的支持度,通过删除操作产生长度为2的频繁序列模式
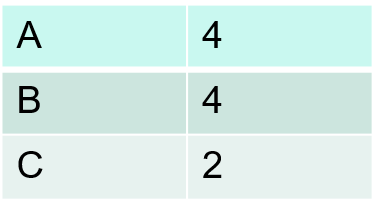

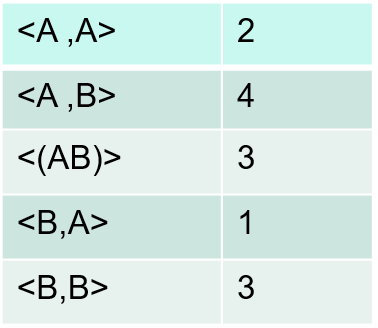
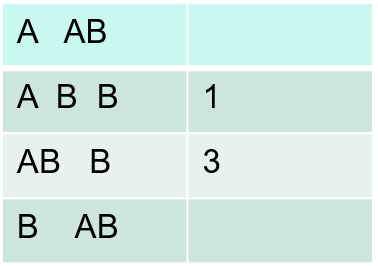
(3)根据长度为2的频繁序列,通过连接操作生成长度为3的候选序列模式,然后扫描序列数据库,计算每个候选序列的支持度,通过删除操作产生长度为3的频繁序列模式
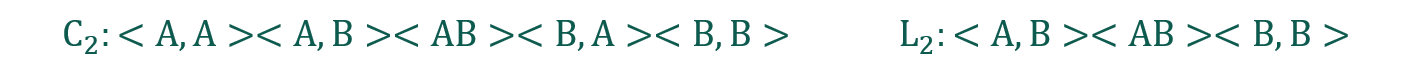
这里没有统计<A,AB>,因为<A,A>是非频繁序列(根据公理:如果一个序列是频繁序列,那么它的子序列也是频繁序列;如果一个序列是非频繁序列,那么包含它的序列也是非频繁序列)
没有统计<B,AB>也是同样的道理。
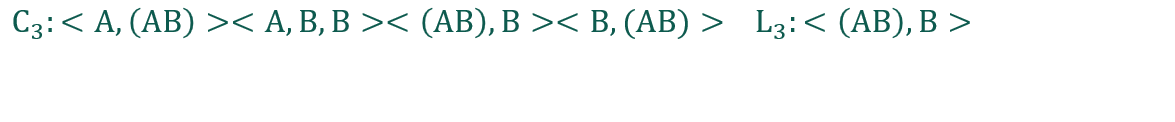
SPADE
SPADE算法是Zaki在2001年发表的《An efficient algorithm for mining frequent sequences》提出的。
SPADE的算法过程和GSP类似,只是在扫描的时候不是扫描整个数据库,而是扫描ID_LIST.
举例:

 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2399
2399

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









