






秋招手里没握ssp,一般不会拒绝字节的薪资诱惑吧~
大家好,我是皇子。
好多大厂秋招开奖都在等字节,把字节跳动的开奖当做了薪资风向标。
今年不知道是咋回事,很多大厂都开了奖,字节却姗姗来迟。是字节反过来了?还是其他大厂觉得也开不过,干脆早点摊牌呢?
有些人手里握着offer,甚至sp offer,还是期待着字节的开奖带来个惊喜。
但是这次有位同学收到字节的offer后,还是硬气的给拒了。
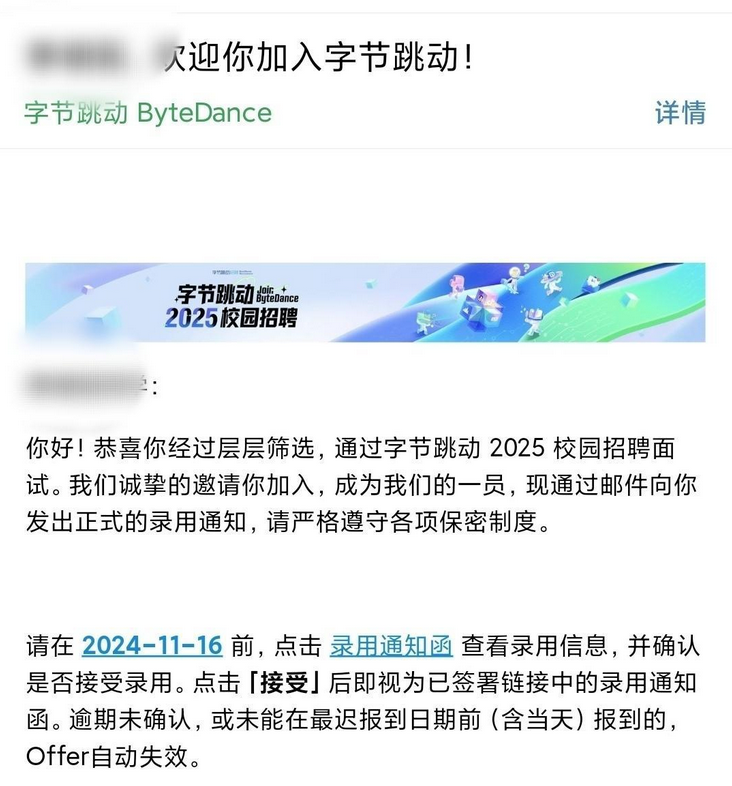
因为他手里握着是美团的的ssp offer,“感谢团子起个高调给我这个牛马定了个好价钱;之后字节被这个包吓的也开始点天灯砸我也算是体验了一把谈薪上位者的感觉。”,后面更是体验了一把能吊着公司的感觉。
而他拒绝去字节的真正原因是:主要是业务和新人培养感觉都是团香点。
ssp offer:super special offer 超级特别offer,可以理解为offer比正常的offer高二级。
这靠着ssp,有底气去向大厂争取更高报酬,不断拉扯的过程,我至今也还没有过,也是羡慕了这些优秀的年轻人。
在拒了字节决定去美团之后,他调侃了自己:团孝子启动!团子秋招情绪价值给的很满,保证此生不用饿了么。额...这个貌似说得有点满,哈哈哈。
那美团在24届和25届中,薪资情况到底如何呢?这里参考的网上资料,整理如下:
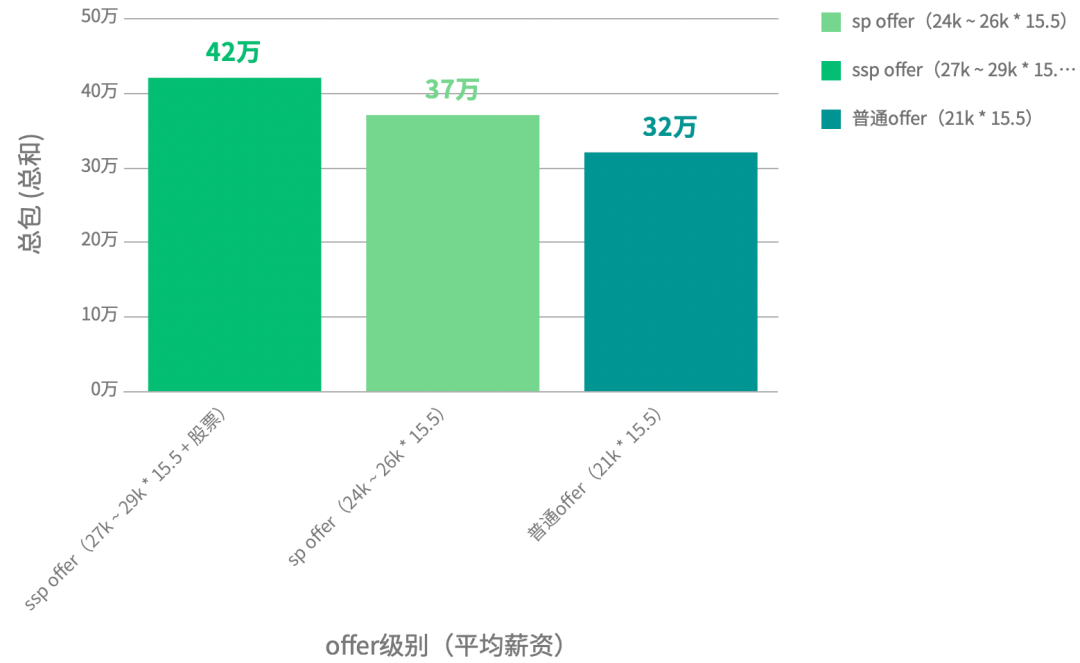
--- 24届
235
-
普通offer(21k * 15.5) 32
-
sp offer(24k ~ 26k * 15.5) 37
-
ssp offer(27k ~ 29k * 15.5 + 股票) 42
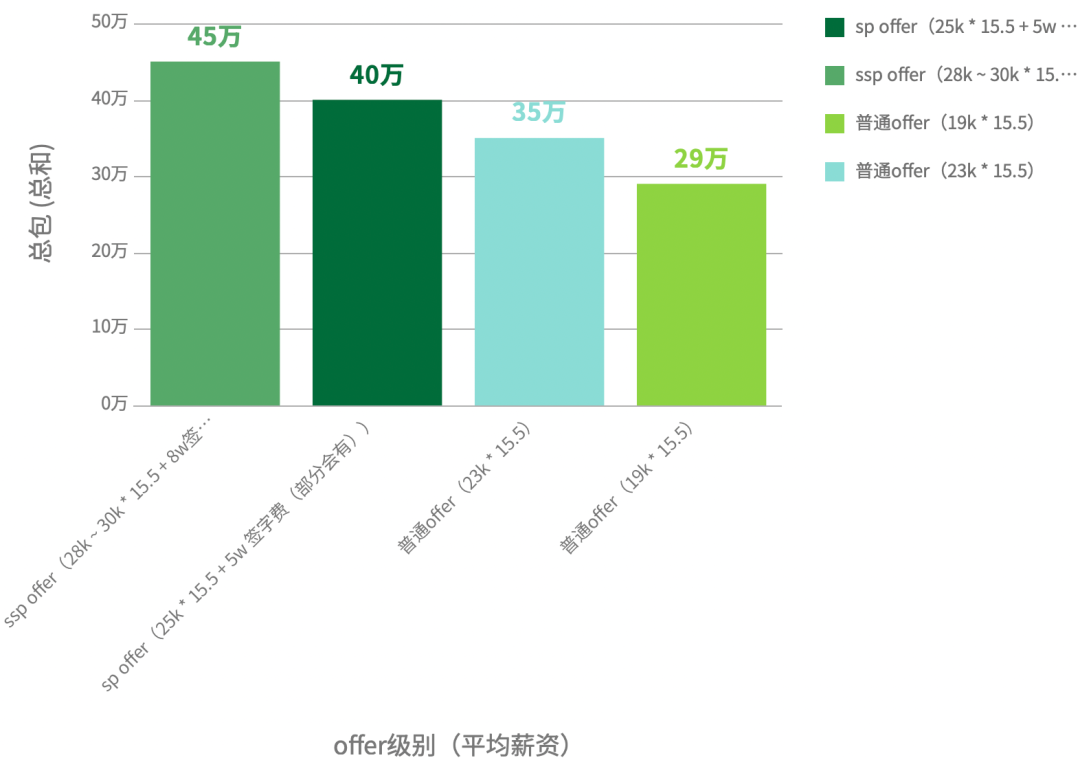
--- 25届
-
成都 普通offer(19k * 15.5) 29
-
北京/上海 普通offer(23k * 15.5) 35
-
北京/上海 sp offer(25k * 15.5 + 5w 签字费(部分会有)) 40
-
北京/上海 ssp offer(28k ~ 30k * 15.5 + 8w签字费 + 30w股票(4年内发完)) 45
然后在说到美团面经前,分享一个关于我与美团的一个有趣的小故事:上周末的时候,我无意打开了美团APP,发现我在22年5月22日有一个订单还未使用的,当时我怀疑系统出错了,结果申请退款后,还真的退款成功了。虽然钱不多,但还是挺开心,感觉像是小时候在地上捡到钱的感觉。完毕~
接着来分享一个美团后端的秋招面经。
网络
iptables的作用是什么?
iptables 是 Linux 系统中一个强大的防火墙工具,用于配置 IPv4 数据包过滤规则。它可以通过设置规则来控制网络流量的流入和流出,从而增强系统的安全性。iptables 主要通过四个表来管理规则:filter、nat、mangle 和 raw。
iptables 的作用
1、包过滤:根据预定义的规则过滤进出的数据包。
2、网络地址转换(NAT):修改数据包的源或目标 IP 地址和端口。
3、数据包修改:修改数据包的特定字段,如 TTL、TOS 等。
4、连接跟踪:跟踪和管理连接状态。
四个表的作用
filter 表:包过滤。
1)INPUT:处理进入本机的数据包。
2)OUTPUT:处理从本机发出的数据包。
3)FORWARD:处理转发的数据包。
4)nat 表:网络地址转换。
nat 表:网络地址转换。
1)PREROUTING:在路由决策之前修改数据包的目标地址。
2)POSTROUTING:在路由决策之后修改数据包的源地址。
3)OUTPUT:处理从本机发出的数据包的地址转换。
mangle 表:数据包修改。
1)PREROUTING:在路由决策之前修改数据包。
2)INPUT:处理进入本机的数据包。
3)OUTPUT:处理从本机发出的数据包。
4)FORWARD:处理转发的数据包。
5)POSTROUTING:在路由决策之后修改数据包。
raw 表:绕过连接跟踪。
1)PREROUTING:在路由决策之前处理数据包。
2)OUTPUT:处理从本机发出的数据包。
iptables常用的命令有哪些?
查看规则:
sudo iptables -L -v -n
清空规则:
sudo iptables -F
sudo iptables -t nat -F
sudo iptables -t mangle -F
sudo iptables -t raw -F
添加规则:
# 允许所有入站流量
sudo iptables -A INPUT -j ACCEPT
# 允许来自特定 IP 的入站流量
sudo iptables -A INPUT -s 192.168.1.100 -j ACCEPT
# 允许特定端口的入站流量
sudo iptables -A INPUT -p tcp --dport 80 -j ACCEPT
# 拒绝所有其他入站流量
sudo iptables -A INPUT -j DROP
删除规则:
# 删除特定规则
sudo iptables -D INPUT -s 192.168.1.100 -j ACCEPT
# 删除所有规则
sudo iptables -F
Redis
Redis底层,使用的什么协议?
Redis 使用的是 RESP (REdis Serialization Protocol) 协议。
RESP 是一种二进制安全的协议,用于在客户端和服务器之间进行通信。它支持多种数据类型,包括简单字符串、错误、整数、批量回复和多批量回复。
这个协议其实在redis的1.2版本时就已经出现了,但是到了redis2.0才最终成为redis通讯协议的标准。
RESP 协议的数据类型
-
简单字符串:以
+开头,后跟字符串,以\r\n结束。 -
错误:以
-开头,后跟错误信息,以\r\n结束。 -
整数:以
:开头,后跟数字,以\r\n结束。 -
批量回复:以
$开头,后跟数字表示字符串的长度,然后是字符串内容,以\r\n结束。 -
多批量回复:以
*开头,后跟数字表示批量回复的数量,然后是每个批量回复的内容。
示例:
1、简单字符串
客户端发送:
SET mykey "Hello"
服务器响应:
+OK\r\n
2、错误
客户端发送:
SET mykey
服务器响应:
-ERR wrong number of arguments for 'set' command\r\n
RESP协议主要有:实现简单、解析速度快、可读性好等优点。不过虽然 RESP 是二进制安全的,但它仍然是基于文本的协议,相比二进制协议,文本协议在解析和生成时可能会有更高的开销的缺点。
怎么实现Redis的高可用?
我们在项目中使用Redis,肯定不会是单点部署Redis服务的。因为,单点部署一旦宕机,就不可用了。为了实现高可用,通常的做法是,将数据库复制多个副本以部署在不同的服务器上,其中一台挂了也可以继续提供服务。
Redis 实现高可用有三种部署模式:主从模式,哨兵模式,集群模式。
-
主从模式:通过将主节点的数据同步到从节点,实现读写分离和数据备份。如果主节点宕机,可以通过手动或自动的方式将从节点提升为主节点。主从模式简单易用,但存在单点故障和数据一致性问题。
-
哨兵模式:通过哨兵实例监控主节点和从节点的健康状况,自动进行故障转移。如果主节点宕机,哨兵会自动选举一个从节点提升为主节点,并通知其他客户端新的主节点地址。哨兵模式提高了系统的可用性,但配置较复杂。
-
集群模式:通过将数据分布在多个节点上,每个节点负责一部分数据。集群使用 16384 个哈希槽,自动处理故障转移和数据重分配。集群模式提供了高可用性和水平扩展能力,但配置和管理较为复杂,客户端需要支持集群模式。
MySQL
MySQL有哪些分库分表的方式?
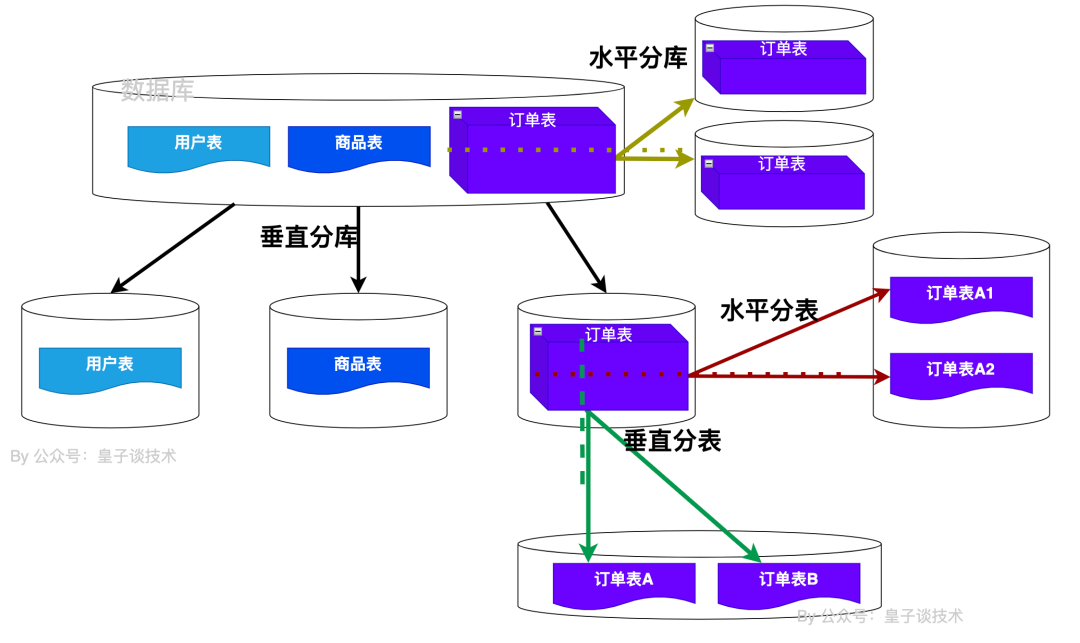
水平分库:水平分库是将同一张表的数据根据某个字段的值拆分到不同的数据库中,每个数据库存储部分数据。
示例:被拆分成两个独立的数据库,分别存放不同部分的订单数据。
order_db1:存储用户ID为奇数的订单数据。
order_db2:存储用户ID为偶数的订单数据。优点:
负载均衡:数据均匀分布在多个数据库中,减轻单个数据库的压力。
扩展性强:可以通过增加新的数据库来扩展存储和处理能力。
缺点:
复杂性增加:需要应用层或中间件来处理数据的路由和聚合。
跨库事务:需要额外的机制来处理跨库的事务。
垂直分库: 垂直分库是将不同的表或表的集合放置在不同的数据库中,每个数据库负责一部分业务数据。
示例:
用户表:被单独放在一个数据库中,例如
user_db。商品表:被单独放在另一个数据库中,例如
product_db。优点:
减少锁争用:不同业务的数据分开存储,减少了锁争用,提高了并发性能。
简化查询:每个数据库专注于特定的业务数据,查询更加高效。
易于管理:每个数据库的规模较小,更容易管理和维护。
缺点:
跨库查询复杂:需要通过应用层或中间件来处理跨库的联合查询。
数据一致性:需要额外的机制来保证跨库事务的一致性。
水平分表: 水平分表是将一张表的数据根据某个字段的值拆分到不同的子表中,每个子表存储部分数据。
示例:订单表被拆分成两个子表,分别是订单表A1和订单表A2,每个子表存放不同部分的订单数据。
订单表A1:存储用户ID为奇数的订单数据。
订单表A2:存储用户ID为偶数的订单数据。
优点:
负载均衡:数据均匀分布在多个子表中,减轻单个表的压力。
提高查询性能:可以并行查询多个子表,提高查询速度。
扩展性强:可以通过增加新的子表来扩展存储和处理能力。
缺点:
复杂性增加:需要应用层或中间件来处理数据的路由和聚合。
跨表事务:需要额外的机制来处理跨表的事务。
垂直分表:垂直分表是将一张表中的某些列拆分到不同的表中,每个表存储部分列的数据。
示例:订单表被拆分成两个子表,形成订单表A和订单表B。
订单表A:存储订单的基本信息,如订单ID、用户ID、订单时间等。
订单表B:存储订单的详细信息,如商品列表、支付信息等。
优点:
减少I/O开销:每次查询只需要读取必要的列,减少了I/O开销。
提高查询性能:减少了表的宽度,提高了查询速度。
简化索引:可以为每个子表创建更有效的索引。
缺点:
复杂性增加:需要应用层或中间件来处理数据的拆分和重组。
数据一致性:需要额外的机制来保证跨表事务的一致性。
以上,点亮【赞与在看】让我们心中充满力量、披荆斩棘、不惧未来!



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











