







目录
一、ModUnionClosure / ModUnionClosurePar
二、CMSIsAliveClosure / CMSParKeepAliveClosure
四、ConcurrentMarkSweepGeneration
3、 ConcGCThreads / ParallelGCThreads
本篇博客继续上一篇《Hotspot 垃圾回收之ConcurrentMarkSweepGeneration(一) 源码解析》讲解其他相关类的实现和使用。
一、ModUnionClosure / ModUnionClosurePar
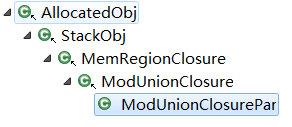
这两个类的定义都在concurrentMarkSweepGeneration.hpp中,用来遍历MemRegion,将其在BitMap对应的内存区域打标,其类继承关系如下:
其核心do_MemRegion方法的实现如下:

_t就是构造方法传入的CMSBitMap指针。
二、CMSIsAliveClosure / CMSParKeepAliveClosure
CMSIsAliveClosure用于判断某个对象是否是存活的,CMSParKeepAliveClosure用于将某个对象标记成存活的,底层都是依赖于BitMap,其实现如下:
CMSIsAliveClosure(MemRegion span,
CMSBitMap* bit_map):
_span(span), //span表示老年代对应的内存区域
_bit_map(bit_map) //CMSBitMap引用
{
assert(!span.is_empty(), "Empty span could spell trouble");
}
bool CMSIsAliveClosure::do_object_b(oop obj) {
HeapWord* addr = (HeapWord*)obj;
//BitMap中打标则认为其是存活的
return addr != NULL &&
(!_span.contains(addr) || _bit_map->isMarked(addr));
}
CMSParKeepAliveClosure::CMSParKeepAliveClosure(CMSCollector* collector,
MemRegion span, CMSBitMap* bit_map, OopTaskQueue* work_queue):
_span(span), //老年代对应的内存区域
_bit_map(bit_map), //老年代的BitMap
_work_queue(work_queue), //执行任务的队列
_mark_and_push(collector, span, bit_map, work_queue), //CMSInnerParMarkAndPushClosure实例
_low_water_mark(MIN2((uint)(work_queue->max_elems()/4),
//CMSWorkQueueDrainThreshold表示CMSWorkQueue的阈值,默认是10
(uint)(CMSWorkQueueDrainThreshold * ParallelGCThreads))) //_work_queue的最大容量
{ }
void CMSKeepAliveClosure::do_oop(oop* p) { CMSKeepAliveClosure::do_oop_work(p); }
void CMSKeepAliveClosure::do_oop(narrowOop* p) { CMSKeepAliveClosure::do_oop_work(p); }
void CMSParKeepAliveClosure::do_oop(oop obj) {
HeapWord* addr = (HeapWord*)obj;
//如果addr在老年代中且没有打标
if (_span.contains(addr) &&
!_bit_map->isMarked(addr)) {
//如果打标成功,因为其他线程可能已经完成打标了,所以可能返回false
if (_bit_map->par_mark(addr)) {
//将obj放入队列中
bool res = _work_queue->push(obj);
assert(res, "Low water mark should be much less than capacity");
//如果_work_queue中的oop超过指定容量了,则处理一部分
trim_queue(_low_water_mark);
} // Else, another thread got there first
}
}
void CMSParKeepAliveClosure::trim_queue(uint max) {
//如果待处理的oop过多
while (_work_queue->size() > max) {
oop new_oop;
//弹出一个待处理的oop
if (_work_queue->pop_local(new_oop)) {
assert(new_oop != NULL && new_oop->is_oop(), "Expected an oop");
assert(_bit_map->isMarked((HeapWord*)new_oop),
"no white objects on this stack!");
assert(_span.contains((HeapWord*)new_oop), "Out of bounds oop");
//遍历该oop所引用的其他oop
new_oop->oop_iterate(&_mark_and_push);
}
}
}
三、CFLS_LAB
CFLS_LAB定义在同目录下的compactibleFreeListSpace.hpp中,是老年代并行GC下本地线程的内存分配缓存,其包含的属性如下:
- CompactibleFreeListSpace* _cfls; //关联的CompactibleFreeListSpace实例
- AdaptiveFreeList<FreeChunk> _indexedFreeList[CompactibleFreeListSpace::IndexSetSize]; //缓存的不同大小的FreeList数组
- static AdaptiveWeightedAverage _blocks_to_claim [CompactibleFreeListSpace::IndexSetSize]; //用来动态调整不同大小的FreeList中包含的FreeChunk内存块的个数
- static size_t _global_num_blocks [CompactibleFreeListSpace::IndexSetSize];//这两个属性用于promote结束后统计不同大小剩余的FreeChunk的个数和曾经获取对应大小的FreeChunk的GC线程数,是_blocks_to_claim用来动态调整填充FreeList时填充的FreeChunk的个数
- static uint _global_num_workers[CompactibleFreeListSpace::IndexSetSize];
- size_t _num_blocks [CompactibleFreeListSpace::IndexSetSize]; //用来记录不同大小的FreeList所包含的FreeChunk内存块的个数
重点关注以下方法的实现。
1、构造方法和modify_initialization
modify_initialization是当命令行显示修改了CMSParPromoteBlocksToClaim或者OldPLABWeight的默认值时才会调用,其调用链如下:

该方法修改的是静态属性_blocks_to_claim,所以可以在启动时执行,Arguments::set_cms_and_parnew_gc_flags方法中的调用如下图:

两者的实现如下:
CFLS_LAB::CFLS_LAB(CompactibleFreeListSpace* cfls) :
_cfls(cfls)
{
assert(CompactibleFreeListSpace::IndexSetSize == 257, "Modify VECTOR_257() macro above");
//CompactibleFreeListSpace::set_cms_values方法把IndexSetStart初始化成MinChunkSize,IndexSetStride初始化成MinObjAlignment
for (size_t i = CompactibleFreeListSpace::IndexSetStart;
i < CompactibleFreeListSpace::IndexSetSize;
i += CompactibleFreeListSpace::IndexSetStride) {
_indexedFreeList[i].set_size(i);
_num_blocks[i] = 0;
}
}
static bool _CFLS_LAB_modified = false;
//实际调用时n传入的是OldPLABSize,wt传入的是OldPLABWeight
//OldPLABSize表示老年代中用于promotion的LAB的大小,默认值是1024
//OldPLABWeight表示重置CMSParPromoteBlocksToClaim时指数衰减的百分比,默认值是50
//CMSParPromoteBlocksToClaimb表示并行GC时重新填充LAB需要声明的内存块的个数
void CFLS_LAB::modify_initialization(size_t n, unsigned wt) {
assert(!_CFLS_LAB_modified, "Call only once");
_CFLS_LAB_modified = true;
for (size_t i = CompactibleFreeListSpace::IndexSetStart;
i < CompactibleFreeListSpace::IndexSetSize;
i += CompactibleFreeListSpace::IndexSetStride) {
_blocks_to_claim[i].modify(n, wt, true /* force */);
}
}
#define VECTOR_257(x) \
/* 1 2 3 4 5 6 7 8 9 1x 11 12 13 14 15 16 17 18 19 2x 21 22 23 24 25 26 27 28 29 3x 31 32 */ \
{ x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, \
x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, \
x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, \
x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, \
x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, \
x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, \
x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, \
x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, \
x }
//初始化
AdaptiveWeightedAverage CFLS_LAB::_blocks_to_claim[] =
VECTOR_257(AdaptiveWeightedAverage(OldPLABWeight, (float)CMSParPromoteBlocksToClaim));
size_t CFLS_LAB::_global_num_blocks[] = VECTOR_257(0);
uint CFLS_LAB::_global_num_workers[] = VECTOR_257(0);
构造方法的调用链如下:

2、alloc
alloc方法用于分配指定大小的内存,如果大于IndexSetSize则尝试从_dictionary中分配,否则从本地的对应大小的FreeList中分配,如果对应FreeList中的空闲内存块的个数为0,则重新填充。其实现如下:
HeapWord* CFLS_LAB::alloc(size_t word_sz) {
FreeChunk* res;
assert(word_sz == _cfls->adjustObjectSize(word_sz), "Error");
if (word_sz >= CompactibleFreeListSpace::IndexSetSize) {
//如果超过IndexSetSize,则获取_parDictionaryAllocLock锁,从_dictionary中分配
MutexLockerEx x(_cfls->parDictionaryAllocLock(),
Mutex::_no_safepoint_check_flag);
res = _cfls->getChunkFromDictionaryExact(word_sz);
//分配失败返回NULL
if (res == NULL) return NULL;
} else {
//获取对应大小的FreeList
AdaptiveFreeList<FreeChunk>* fl = &_indexedFreeList[word_sz];
if (fl->count() == 0) {
//如果fl是空则尝试重新填充
get_from_global_pool(word_sz, fl);
//填充失败返回Null
if (fl->count() == 0) return NULL;
}
//获取链表头的FreeChunk 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 4049
4049











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









