







1,搭建Flink集群,在节点node1,node2,node3安装
修改配置文件:
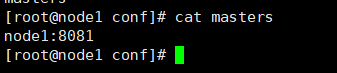
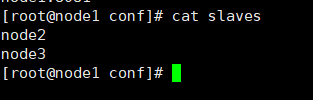
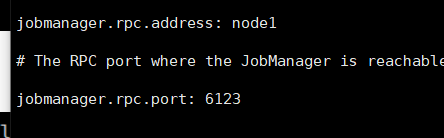
flink-conf.yaml 配置文件
2,启动hadoop集群,保证hive也是正常的:
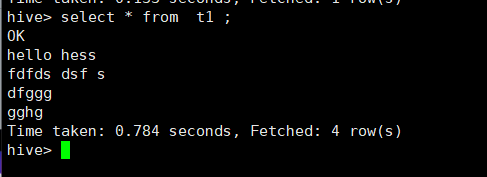
启动Flink,成功如下:

3,Flink1.10与Hive的生产级别集成

内存优化点:使用多少内存就用多少内存。

4,我们需要做的流程:

1)使用flink-sql-benchmark创建Hive测试数仓库表跟数据
工具地址:
https://github.com/ververica/flink-sql-benchmark
按照流程:

实践步骤:1) yum install gcc 同时已经安装maven,否则启动的时候会提醒你missing
2)cd hive-tpcds-setup
./tpcds-build.sh (编译,会去官网拖包,可能会很慢。。 注:在家里真是慢,草鸡慢)

3)生成数据
cd hive-tpcds-setup
./tpcds-setup.sh 1 (这个参数是指定需要产生数据的大小,单位为G)
4)生成的库叫 tpcds_bin_orc_1
会创建24张表,7张事实表,17张维表

5)下载hive对应jar包丢入到flink lib目录下面:

6)启动flink集群,我这里是重启
7)如果是通过sql-client 玩玩的话:
修改配置:
![]()
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 459
459











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









