







背景
背景一:
当我们建立一个表格,其中的一项内容可以有多种选择,可以利用外键的方式绑定一个表。如下图比如我们需要建立一个employee表,其中包含很多信息,其中有一项民族可以以外键的方式绑定。

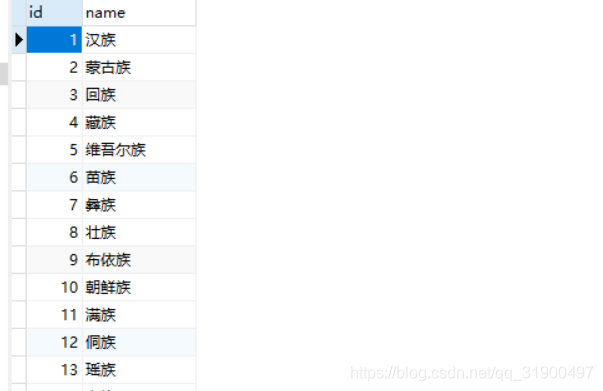
接着来看一看sql语句
CREATE TABLE `employee` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '员工编号',
`name` varchar(10) DEFAULT NULL COMMENT '员工姓名',
`gender` char(4) DEFAULT NULL COMMENT '性别',
`birthday` date DEFAULT NULL COMMENT '出生日期',
`idCard` char(18) DEFAULT NULL COMMENT '身份证号',
`wedlock` enum('已婚','未婚','离异') DEFAULT NULL COMMENT '婚姻状况',
`nationId` int(8) DEFAULT NULL COMMENT '民族',
`nativePlace` varchar(20) DEFAULT NULL COMMENT '籍贯',
`politicId` int(8) DEFAULT NULL COMMENT '政治面貌',
`email` varchar(20) DEFAULT NULL COMMENT '邮箱',
`phone` varchar(11) DEFAULT NULL COMMENT '电话号码',
`address` varchar(64) DEFAULT NULL COMMENT '联系地址',
`departmentId` int(11) DEFAULT NULL COMMENT '所属部门',
`jobLevelId` int(11) DEFAULT NULL COMMENT '职称ID',
`posId` int(11) DEFAULT NULL COMMENT '职位ID',
`engageForm` varchar(8) DEFAULT NULL COMMENT '聘用形式',
`tiptopDegree` enum('博士','硕士','本科','大专','高中','初中','小学','其他') DEFAULT NULL COMMENT '最高学历',
`specialty` varchar(32) DEFAULT NULL COMMENT '所属专业',
`school` varchar(32) DEFAULT NULL COMMENT '毕业院校',
`beginDate` date DEFAULT NULL COMMENT '入职日期',
`workState` enum('在职','离职') DEFAULT '在职' COMMENT '在职状态',
`workID` char(8) DEFAULT NULL COMMENT '工号',
`contractTerm` double DEFAULT NULL COMMENT '合同期限',
`conversionTime` date DEFAULT NULL COMMENT '转正日期',
`notWorkDate` date DEFAULT NULL COMMENT '离职日期',
`beginContract` date DEFAULT NULL COMMENT '合同起始日期',
`endContract` date DEFAULT NULL COMMENT '合同终止日期',
`workAge` int(11) DEFAULT NULL COMMENT '工龄',
PRIMARY KEY (`id`),
KEY `departmentId` (`departmentId`),
KEY `jobId` (`jobLevelId`),
KEY `dutyId` (`posId`),
KEY `nationId` (`nationId`),
KEY `politicId` (`politicId`),
KEY `workID_key` (`workID`),
CONSTRAINT `employee_ibfk_1` FOREIGN KEY (`departmentId`) REFERENCES `department` (`id`),
CONSTRAINT `employee_ibfk_2` FOREIGN KEY (`jobLevelId`) REFERENCES `joblevel` (`id`),
CONSTRAINT `employee_ibfk_3` FOREIGN KEY (`posId`) REFERENCES `position` (`id`),
CONSTRAINT `employee_ibfk_4` FOREIGN KEY (`nationId`) REFERENCES `nation` (`id`),
CONSTRAINT `employee_ibfk_5` FOREIGN KEY (`politicId`) REFERENCES `politicsstatus` (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1942 DEFAULT CHARSET=utf8;
其中较难理解的是:
CONSTRAINT 'employee_ibfk_4' FOREIGN KEY ('departmentId') REFERENCES 'nation' ('id'),
这句代码的意思是对整个employee表进行外键约束,其中employee_ibfk_4是外键的名称(命名方式:表名_ibfk_数字,ibfk(InnoDB Foreign Key))。nationId是employee表的一个属性,department是通过外键链接的新表,并且利用id进行索引。
在mapper层,需要必要的配置:
<resultMap id="AllEmployeeInfo" type="org.javaboy.vhr.model.Employee" extends="BaseResultMap">
<association property="nation" javaType="org.javaboy.vhr.model.Nation">
<id column="nid" property="id"/>
<result column="nname" property="name"/>
</association>
当要进行查找的时候
<select id="getEmployeeById" resultMap="AllEmployeeInfo">
select e.*,p.`id` as pid,p.`name` as pname,n.`id` as nid,n.`name` as nname,d.`id` as did,d.`name` as dname,j.`id` as jid,j.`name` as jname,pos.`id` as posid,pos.`name` as posname from employee e,nation n,politicsstatus p,department d,joblevel j,position pos where e.`nationId`=n.`id` and e.`politicId`=p.`id` and e.`departmentId`=d.`id` and e.`jobLevelId`=j.`id` and e.`posId`=pos.`id` and e.`id`=#{id}
</select>
从select from这个结构中可以知道,里面有多个表:employee, nation, politicsstatus, department, joblevel, position。利用where e.‘nationId’=n.'id’可以实现employee表对nation表的某一项访问。
还遇到其他的语句:
like模糊查找
and e.name like concat('%',#{emp.name},'%')
这个like语句是用于模糊查找,其中‘%’可以匹配任意字符,concat()这个方法是用于字符串拼接的,即'%#{emp.name}%'。最终可以匹配到任何字符串中有#{emp.name}的字符串。
2.COUNT(*)函数返回在给定的选择中被选的行数。
语法:
SELECT COUNT(*) FROM table
3.常见数据库访问语句
1. select * from table
2. delete from table where id = #{id, jdbcType=INTEGER}
3. insert into table (.,.,) values (#{},#{})
背景二
一个网站需要有不同的操作员进行登录,而且需要显示操作员的基本信息和用户角色。
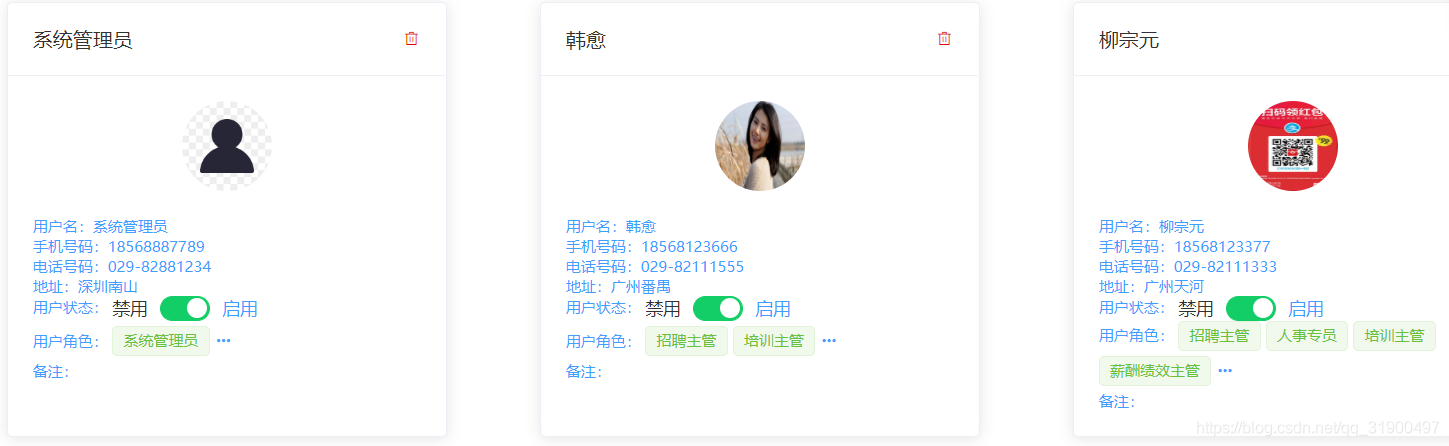
来看一下sql语句
/*Table structure for table `hr` */
DROP TABLE IF EXISTS `hr`;
CREATE TABLE `hr` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT 'hrID',
`name` varchar(32) DEFAULT NULL COMMENT '姓名',
`phone` char(11) DEFAULT NULL COMMENT '手机号码',
`telephone` varchar(16) DEFAULT NULL COMMENT '住宅电话',
`address` varchar(64) DEFAULT NULL COMMENT '联系地址',
`enabled` tinyint(1) DEFAULT '1',
`username` varchar(255) DEFAULT NULL COMMENT '用户名',
`password` varchar(255) DEFAULT NULL COMMENT '密码',
`userface` varchar(255) DEFAULT NULL,
`remark` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=13 DEFAULT CHARSET=utf8;
/*Data for the table `hr` */
insert into `hr`(`id`,`name`,`phone`,`telephone`,`address`,`enabled`,`username`,`password`,`userface`,`remark`) values (3,'系统管理员','18568887789','029-82881234','深圳南山',1,'admin','$2a$10$ySG2lkvjFHY5O0./CPIE1OI8VJsuKYEzOYzqIa7AJR6sEgSzUFOAm','http://bpic.588ku.com/element_pic/01/40/00/64573ce2edc0728.jpg',NULL),(5,'李白','18568123489','029-82123434','海口美兰',1,'libai','$2a$10$oE39aG10kB/rFu2vQeCJTu/V/v4n6DRR0f8WyXRiAYvBpmadoOBE.','https://timgsa.baidu.com/timg?image&quality=80&size=b9999_10000&sec=1514093920321&di=913e88c23f382933ef430024afd9128a&imgtype=0&src=http%3A%2F%2Fp.3761.com%2Fpic%2F9771429316733.jpg',NULL),(10,'韩愈','18568123666','029-82111555','广州番禺',1,'hanyu','$2a$10$oE39aG10kB/rFu2vQeCJTu/V/v4n6DRR0f8WyXRiAYvBpmadoOBE.','https://timgsa.baidu.com/timg?image&quality=80&size=b9999_10000&sec=1517070040185&di=be0375e0c3db6c311b837b28c208f318&imgtype=0&src=http%3A%2F%2Fimg2.soyoung.com%2Fpost%2F20150213%2F6%2F20150213141918532.jpg',NULL),(11,'柳宗元','18568123377','029-82111333','广州天河',1,'liuzongyuan','$2a$10$oE39aG10kB/rFu2vQeCJTu/V/v4n6DRR0f8WyXRiAYvBpmadoOBE.','https://timgsa.baidu.com/timg?image&quality=80&size=b9999_10000&sec=1515233756&di=0856d923a0a37a87fd26604a2c871370&imgtype=jpg&er=1&src=http%3A%2F%2Fwww.qqzhi.com%2Fuploadpic%2F2014-09-27%2F041716704.jpg',NULL),(12,'曾巩','18568128888','029-82111222','广州越秀',1,'zenggong','$2a$10$oE39aG10kB/rFu2vQeCJTu/V/v4n6DRR0f8WyXRiAYvBpmadoOBE.','https://timgsa.baidu.com/timg?image&quality=80&size=b9999_10000&sec=1517070040185&di=be0375e0c3db6c311b837b28c208f318&imgtype=0&src=http%3A%2F%2Fimg2.soyoung.com%2Fpost%2F20150213%2F6%2F20150213141918532.jpg',NULL);
/*Table structure for table `hr_role` */
DROP TABLE IF EXISTS `hr_role`;
CREATE TABLE `hr_role` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`hrid` int(11) DEFAULT NULL,
`rid` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `rid` (`rid`),
KEY `hr_role_ibfk_1` (`hrid`),
CONSTRAINT `hr_role_ibfk_1` FOREIGN KEY (`hrid`) REFERENCES `hr` (`id`) ON DELETE CASCADE,
CONSTRAINT `hr_role_ibfk_2` FOREIGN KEY (`rid`) REFERENCES `role` (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=75 DEFAULT CHARSET=utf8;
/*Data for the table `hr_role` */
insert into `hr_role`(`id`,`hrid`,`rid`) values (1,3,6),(35,12,4),(36,12,3),(37,12,2),(43,11,3),(44,11,2),(45,11,4),(46,11,5),(48,10,3),(49,10,4),(72,5,1),(73,5,2),(74,5,3);
/*Table structure for table `role` */
DROP TABLE IF EXISTS `role`;
CREATE TABLE `role` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(64) DEFAULT NULL,
`nameZh` varchar(64) DEFAULT NULL COMMENT '角色名称',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=22 DEFAULT CHARSET=utf8;
/*Data for the table `role` */
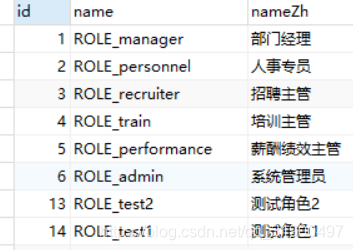
insert into `role`(`id`,`name`,`nameZh`) values (1,'ROLE_manager','部门经理'),(2,'ROLE_personnel','人事专员'),(3,'ROLE_recruiter','招聘主管'),(4,'ROLE_train','培训主管'),(5,'ROLE_performance','薪酬绩效主管'),(6,'ROLE_admin','系统管理员'),(13,'ROLE_test2','测试角色2'),(14,'ROLE_test1','测试角色1'),(17,'ROLE_test3','测试角色3'),(18,'ROLE_test4','测试角色4'),(19,'ROLE_test4','测试角色4'),(20,'ROLE_test5','测试角色5'),(21,'ROLE_test6','测试角色6');
上面可以创建三个表,第一个表hr表示是操作员的基本信息,第三个表role表示角色,即表示该操作员的用户角色。第二个表hr_role使用外键hr_role_ibfk_1和hr_role_ibfk_1来绑定第一表hr和第三个表role。
hr

hr_role
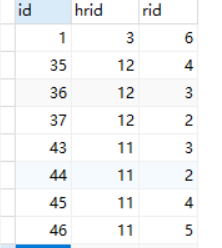
role
其中语句:
ON DELETE CASCADE;
其中,DELETE是指在主键表中删除一条记录。CASCADE表示级联操作,如果主键表的记录被删除,外键表中该行也相应被删除。
同理,
on update cascade;
在update和delete后面可以添加:no action,set null,set default。
no action:表示不做任何操作
set null:表示外键中将相应字段设置为null
set default:表示设置为默认值
在HrMapper.xml中:
<resultMap id="BaseResultMap" type="org.javaboy.vhr.model.Hr">
<id column="id" property="id" jdbcType="INTEGER"/>
<result column="name" property="name" jdbcType="VARCHAR"/>
<result column="phone" property="phone" jdbcType="CHAR"/>
<result column="telephone" property="telephone" jdbcType="VARCHAR"/>
<result column="address" property="address" jdbcType="VARCHAR"/>
<result column="enabled" property="enabled" jdbcType="BIT"/>
<result column="username" property="username" jdbcType="VARCHAR"/>
<result column="password" property="password" jdbcType="VARCHAR"/>
<result column="userface" property="userface" jdbcType="VARCHAR"/>
<result column="remark" property="remark" jdbcType="VARCHAR"/>
</resultMap>
<resultMap id="HrWithRoles" type="org.javaboy.vhr.model.Hr" extends="BaseResultMap">
<collection property="roles" ofType="org.javaboy.vhr.model.Role">
<id column="rid" property="id"/>
<result column="rname" property="name"/>
<result column="rnameZh" property="nameZh"/>
</collection>
</resultMap>
通过:以下的方式将role的属性添加进来。
<resultMap id="HrWithRoles" type="org.javaboy.vhr.model.Hr" extends="BaseResultMap">
<collection property="roles" ofType="org.javaboy.vhr.model.Role">
<id column="rid" property="id"/>
<result column="rname" property="name"/>
<result column="rnameZh" property="nameZh"/>
</collection>
</resultMap>
查询所有的操作员:
<select id="getAllHrs" resultMap="HrWithRoles">
select hr.id, hr.name, hr.phone, hr.telephone, hr.address, hr.enabled, hr.username, hr.userface,
hr.remark,r.`id` as rid,r.`name` as rname,r.`nameZh` as rnameZh from hr left join hr_role hrr on
hr.`id`=hrr.`hrid` left join role r on hrr.`rid`=r.`id` where hr.`id`!=#{hrid}
<if test="keywords!=null">
and hr.name like concat('%',#{keywords},'%')
</if>
order by hr.id
</select>
其中有三个表hr,hr_role,role,采用left join的方式组合在一起。
通过如下的方式对操作员的角色进行查询:
<select id="getHrRolesById" resultType="org.javaboy.vhr.model.Role">
select r.* from role r,hr_role hrr where hrr.`rid`=r.`id` and hrr.`hrid`=#{id}
</select>
其中有role和hr_role两个表。
在hr_role数据表中:
可以实现一个操作员绑定多个角色。
其mapper层的实现方式:
Integer addRole(@Param("hrid") Integer hrid, @Param("rids") Integer[] rids);
<insert id="addRole">
insert into hr_role (hrid,rid) values
<foreach collection="rids" item="rid" separator=",">
(#{hrid},#{rid})
</foreach>
</insert>
从Mapper层知道传入两个参数,一个是hrid,一个是一个数组rids,又从xml配置文件中可以知道实现了一对多。hrid对应rids。
参考















 243
243











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









