







 超级会员免费看
超级会员免费看
 本文介绍了Apache Pulsar,一个云原生的企业级发布订阅消息系统,强调其多租户模式、灵活的消息系统、云原生架构等特性,并与Kafka进行了对比。文章还探讨了Pulsar的组件,如分片流、连接器和轻量级计算框架,并指出Pulsar在性能和扩展性上的优势。
本文介绍了Apache Pulsar,一个云原生的企业级发布订阅消息系统,强调其多租户模式、灵活的消息系统、云原生架构等特性,并与Kafka进行了对比。文章还探讨了Pulsar的组件,如分片流、连接器和轻量级计算框架,并指出Pulsar在性能和扩展性上的优势。
开篇
为什么要学习Apache Pulsar?
一、什么是云原生?
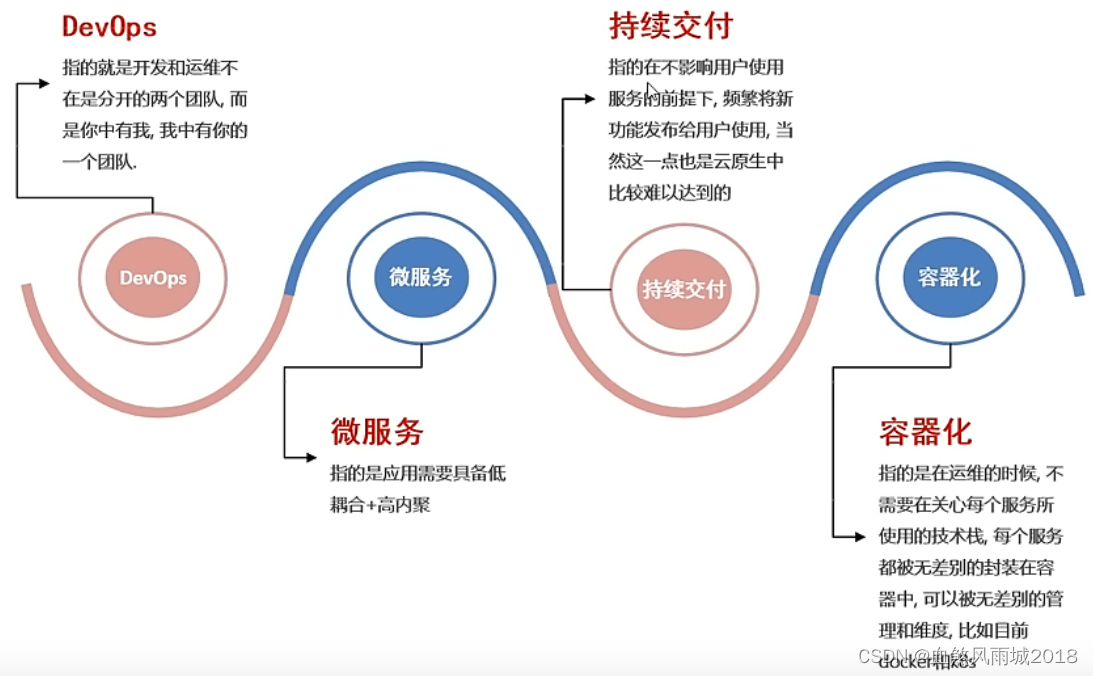
云原生的概念是2013年Matt Stine提出的,到目前为止,云原生的概念发生了多次变更,目前最新对云原生定义为:DevOps+持续交付+微服务+容器
而符合云原生架构的应用程序是:采用开源堆栈(K8S+Docker)进行容器化 ,基于微服务架构提高灵活性和可维护性,借助敏捷方法、DevOps支持持续迭代和运维自动化,利用云平台设施实现弹性伸缩、动态调度、优化资源利用率。
二、Apache Pulsar基本介绍
Apache Pulsar是一个云原生企业级的发布订阅(pub-sub)消息系统,最初由Yahoo开发,并于2016年底开源,现在是Apache软件基金会顶级开源项目。Pulsar在Yahoo的生产环境运行了三年多,助力Yahoo的主要应用,如Yahoo Mail、Yahoo Finance、Yahoo Sports、Flickr、Gemini广告平台和Yahoo分布式键值存储系统Sherpa。
Apache Pulsar的功能与特性:
- 多租户模式
- 灵活的消息系统
- 云原生架构
- segmented Sreams(分片流)
- 支持跨地域复制
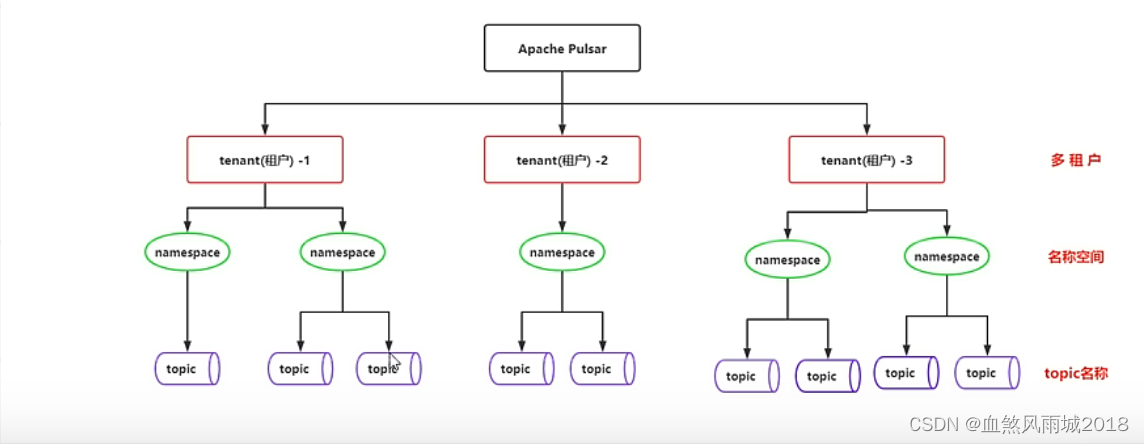
(1)多租户模式
- 租户和命名空间(namespace)是pulsar支持多租户的两个核心概念。
- 在租户级别,pulsar为特定的租户预留合适的存储空间、应用授权与认证机制。
- 在命名空间级别,pulsar有一系列的配置策略(policy),包括存储配额、流控、消息过期策略和命名空间之间的隔离策略。
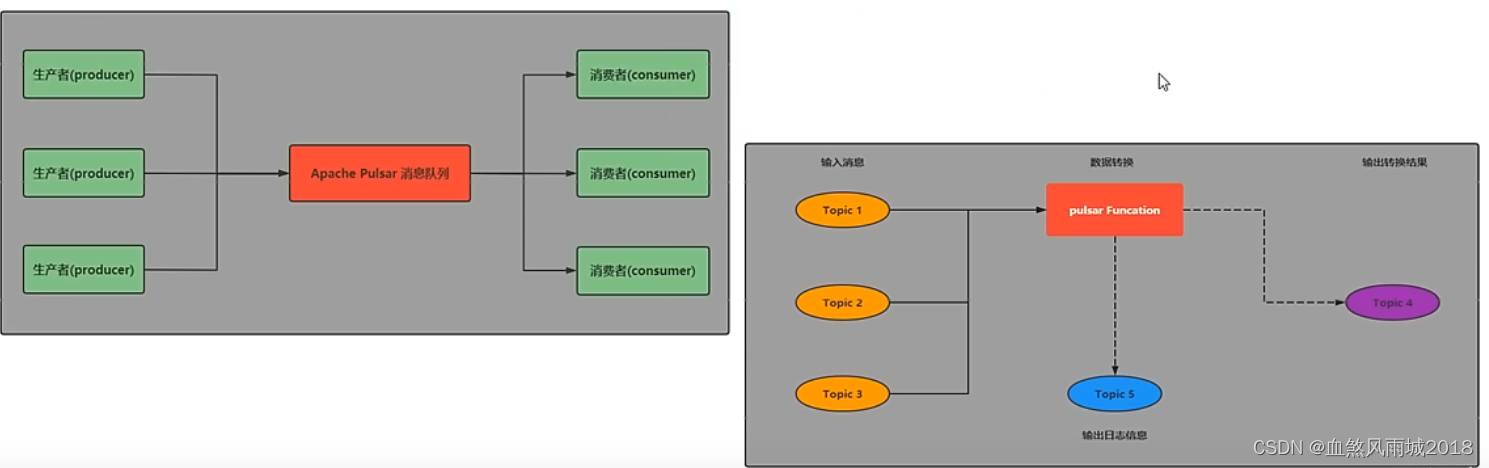
(2)灵活的消息系统
pulsar做了队列模型和流模型的统一,在topic级别只需保存一份数据,同一份数据可多次消费。以流式、队列等方式计算不同的订阅模型大大提升了灵活度。
同时pulsar通过事务采用Exactly-one(精准一次)在进行消息传输过程中,可以确保数据不丢不重。
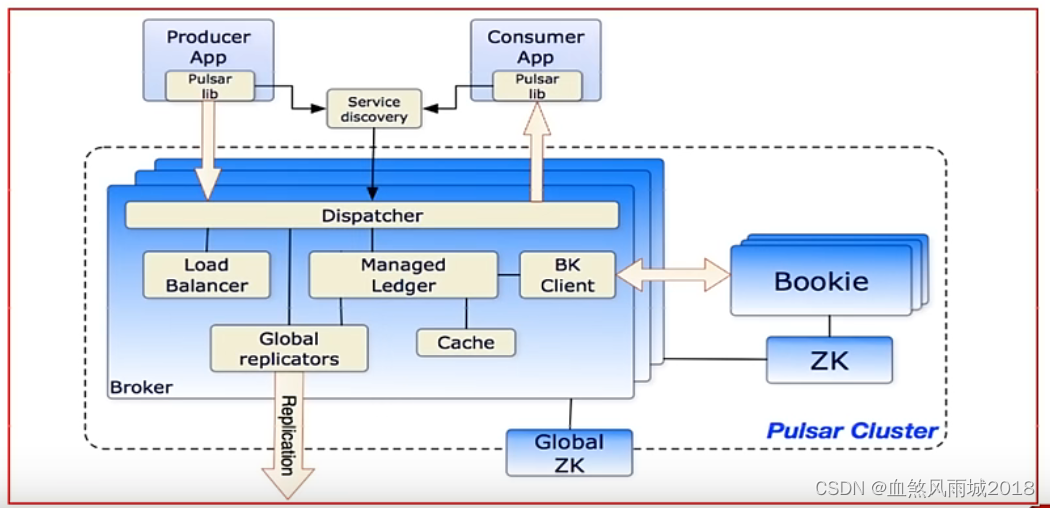
(3)云原生架构
pulsar使用计算和存储分离的云原生架构,数据从Broker搬离,存在共享存储内部。上层是无状态Broker,复制消息分发和服务;下层是持久化的存储层Bookie集群。pulsar存储是分片的,这种架构可以避免扩容时受限制,实现数据的独立扩展和快速回复
(4)segmented Sreams(分片流)
pulsar将无界的数据看作是分片的流,分片分散存储在分层存储(tiered storage)、BookKeeper集群和Broker节点上,而对外提供一个统一的、无界数据的视图。其次,不需要用户显式迁移数据,减少存储成本并保持近似无限的存储。
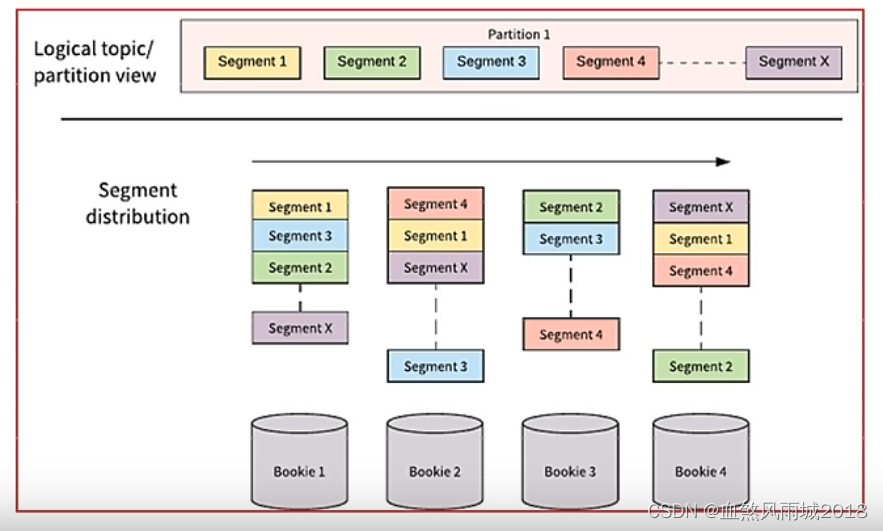
(5)支持跨地域复制
pulsar中的跨地域复制是将pulsar中持久化的消息在多个集群间备份。在pulsar2.4.0中新增了复制订阅模式(Replicated-subscriptions),在某个集群失效情况下,该功能可以在其他集群恢复消费者的消费状态,从而达到热备模式下消息服务的高可用。
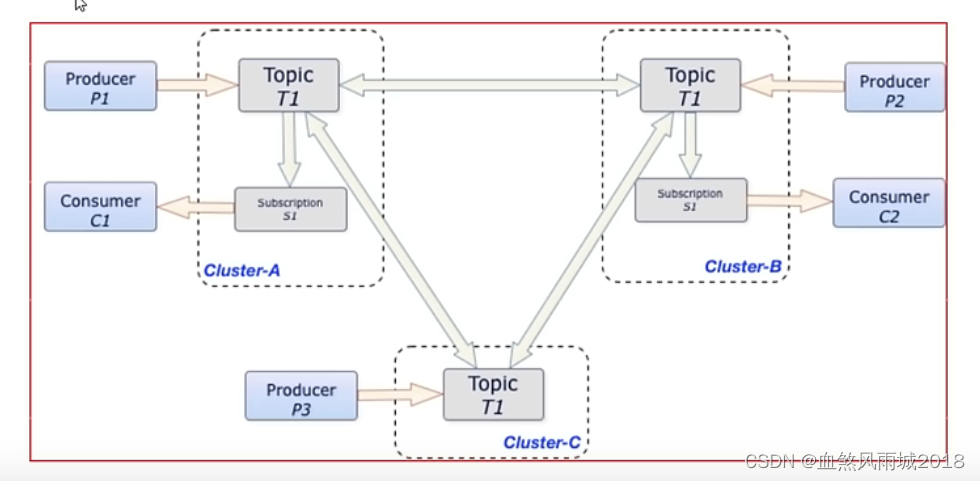
三、Apache Pulsar组件介绍
(1)层级存储
- Infinite Stream :以流的方式永久保存原始数据
- 分区的容量不再受限制
- 充分利用云存储或现有的廉价存储(例如:HDFS)
- 数据统一表征:客户端无需关心数据究竟存储在哪里
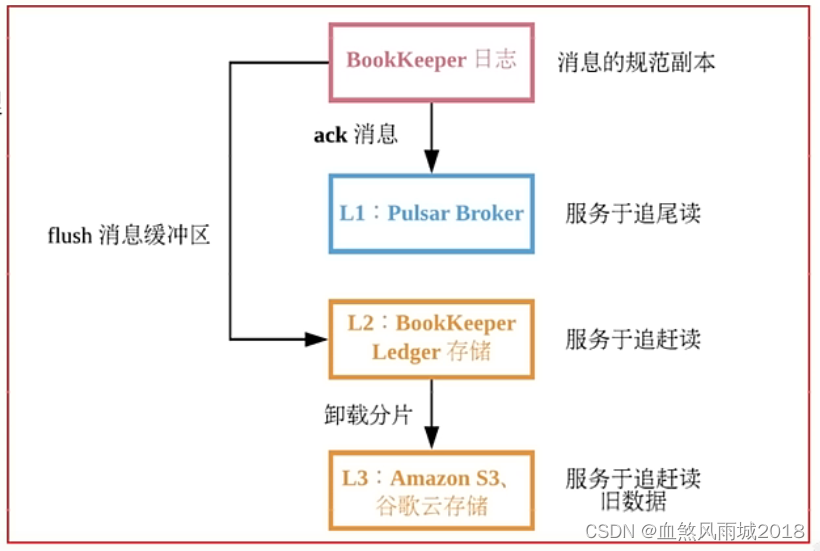
(2)pulsar IO(Connector) 连接器
pulsar IO分为输入(Input)和输出(Output)两个模块,输入代表数据从哪里来,通过Source实现数据输入。输出代表数据要往哪里去,通过Sink实现数据输出。
pulsar 提出了Connector(也称为pulsar IO),用于解决pulsar 与周边系统的集成问题,帮助用户高效完成工作。
目前pulsar IO支持非常多的连接集成操作:例如HDFS、Spark、Flink、Flume、ES、HBase等

(3)pulsar funcations(轻量级计算框架)
pulsar funcations是一个轻量级计算框架,可以给用户提供一个部署简单、运维简单、API简单的fass(funcation as a service)平台。pulsar funcations提供基于事件的服务,支持有状态和无状态的多语言计算,是对复杂的大数据处理框架的有力补充。
pulsar funcations的设计灵感来自于Heron这样的流处理引擎,pulsar funcations将会拓展pulsar 和整个消息领域的未来。使用pulsar funcations,用户可以轻松的部署和管理funcation,通过funcation从pulsar topic读取数据或者生产新数据到pulsar topic。
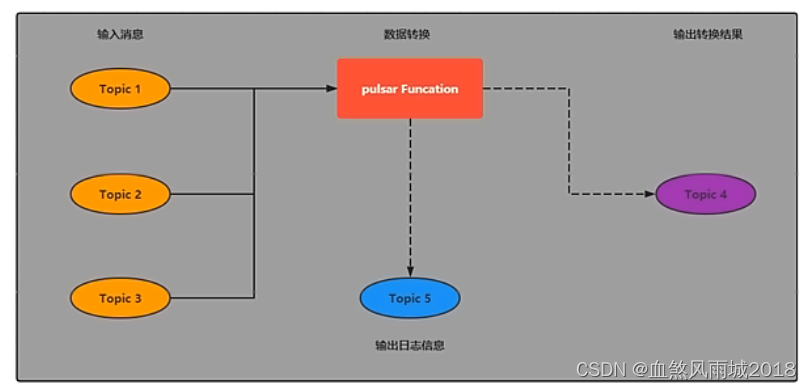
四、pulsar和kafka的对比介绍说明
(1)模型概念
kafka:producer - topic - consumer group - consumer
pulsar: producer - topic - subsciption - consumer
(2)消息消费模式
kafka:主要集中在流模式,对单个partition是独占消费,没有共享的消费模式
pulsar:提供了统一的消息模型和API,流模式-独占和故障切换订阅方式;队列模式-共享订阅的方式
(3)消息确认(ack)
kafka:使用偏移量offset
pulsar:使用专门的cursor管理,累计确认和kafka效果一样,提供单条或选择性确认
(4)消息保留
kafka:根据设置的保留期来删除消息,有可能消息没被消费,过期后被删除,不支持TTL
pulsar:消息只有被所有订阅消费后才会删除,不会丢失数据,也运行设置保留期,保留被消费的数据,支持TTL
kafka和pulsar都有类似的消息概念,客户端通过主题和消息系统进行交互。每个主题都可以分为多个分区。然而,pulsar和kafka之间的根本区别在于kafka是以分区为存储中心,而pulsar是以segment为存储中心。

对比总结:
pulsar将高性能的流(kafka所追求的)和灵活的传统队列(rabbitmq所追求的)结合到一个统一的消息模型和api中,pulsar使用统一的api为用户提供一个支持流和队列的系统,且具有同样的高性能。
性能对比:
pulsar表现最出色的就是性能,pulsar的速度比kafka快得多,美国德克萨斯州一家名为GigaOm的技术研究和分析公司对kafka和pulsar的性能做了比较,并证实了这一点。
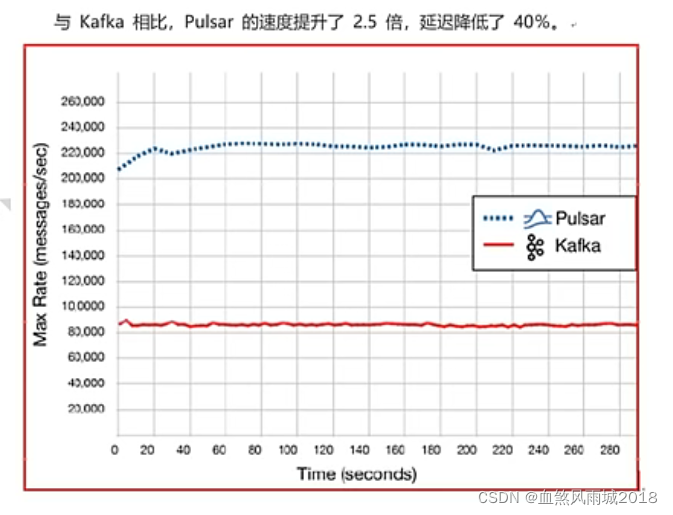
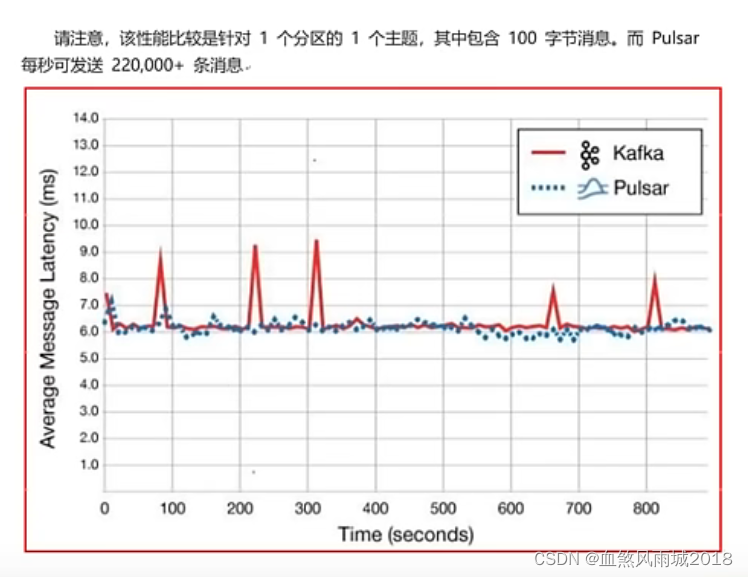
扩展说明:kafka目前存在的痛点
- kafka很难进行扩展,因为kafka把消息持久化在broker中,迁移主题分区时,需要把分区的数据完全复制到其他broker中,这个操作非常耗时。
- 当需要通过更改分区大小以获得更多的存储空间时,会与消息索引产生冲突,打乱消息顺序。因此,如果用户需要保证消息的顺序,kafka就变得非常棘手了。
- 如果分区副本不处于ISR(同步)状态,那么leader选取可能会紊乱。一般的,当原始主分区出现故障时,应该有一个ISR副本被征用,但是这点并不能完全保证。若在设置中并未规定只有ISR副本可被选为leader时,选出一个处于非同步状态的副本做leader,这比没有broker服务该partition的情况更糟糕
- 使用kafka时,你需要根据现有的情况并充分考虑未来的增量计划,规划broker、主题、分区和副本的数量,才能避免kafka扩展导致的问题,这是理想状况,实际情况很难规划,不可避免会出现扩展需求
- kafka集群的分区再均衡会影响相关生产者和消费者的性能
- 发生故障时,kafka主题无法保证消息的完整性
- 使用kafka需要和offset打交道,这点让人很头痛,因为broker并不维护consumer的消费状态
- 使用使用率很高,则必须尽快删除旧消息,否则就会出现磁盘空间不够用的问题
- 众所周知,kafka原生的跨地域复制机制(MirrorMarker)有问题,即使只在两个数据中心也无法正常使用跨地域复制,因此,甚至uber都不能不创建另一套解决方案来解决这个问题,并将其称为uReplicator
- 要想进行实时数据分析,就不得不选用第三方工具,如strom,heron,spark,同时,你需要确保这些第三方工具足以支撑传入的流量
- kafka没有原生的多租户功能来实现租户的完全隔离,它是通过使用主题授权等安全功能来完成的。
文末福利
关注公众号:程序工厂充电宝 点击关于我,加博主微信,3折解锁付费专栏哦!!!


















 1330
1330

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











