







文章目录
前言:本文是自己的阅读《Mysql技术内幕——InnoDB存储引擎》的笔记,主要是为了将阅读和实践结合起来,途中会穿插自己的理解及自己工作中的实践。我理解阅读一本经典的书,无论是技术书籍还是生活数据,带着目的去读,知道书讲得是什么,并且结合自己的理解,输出一定的文字,不求尽善尽美但求不误人子弟。
首先来说一说个人对于锁的理解,为什么需要锁呢?和Java中需要锁的目的是一样的,想要的并发场景下保持数据的安全性,能够使每个用户一致的查询和修改数据库中的数据。只有在存在并发的情况下谈锁才有意义,如果是单线程,肯定是不需要锁的。
1. 什么是锁
本文谈论的所有的锁都是Mysql Innodb存储引擎下的锁,因为不同的存储引擎、不同的数据库锁的机制和实现都是不一样的。比如MyISAM下是直接锁定整张表的,并发情况下,读操作不会存在问题,但是性能会降低很多。但是Innodb提供的是非锁定的一致性读(啥意思呢?也就是说读的情况下在单纯的读的场景中,不需要加额外的锁,就可以保证多次读的数据是一致的),同时提供行级别的锁,可以很好的提供性能。
2. Lock和latch区别
在数据库中这两种都是称为锁,但是两者的应用场景和具体的含义却大不相同。
lock可能是通常意义上开发人员讨论的锁。其主要的作用范围是事务。主要是用来锁定数据库中的对象,比如表、行等。一般锁住的对象在事务commit或者事务rollback之后才会释放,并且数据库是具有检验锁的机制。
latch可能和Java中的锁有点像,算是一种轻量级的锁,其主要所用的范围是线程。主要作用是用于保证并发情况下多个线程操作的共享资源的正确性。本身没有发现死锁的能力,需要靠开发人员自己去发现或者说写出正确的代码。主要类型有mutex(互斥量)、rwlock(读写锁)。
两者主要区别
| lock | latch | |
|---|---|---|
| 作用范围 | 事务 | 线程 |
| 对用对象 | 数据库对象 | 内存中的对象 |
| 持续时间 | 整个事务过程 | 共享资源 |
| 表现形式 | 行锁、表锁等 | 读写锁、互斥锁 |
| 死锁检测 | 通过time out wait-for graph图发现 | 本身无检测机制,需要开发人员自己发现 |
3. Innodb存储引擎中的锁
1. 锁的类型
锁主要分为两种类型
- 共享锁:又称为 S Lock,允许事务读一行数据。多个事务可以对同一行数据进行读取操作。
- 排他锁:又称为X Lock,允许事务删除或者更新一行数据
只有共享锁之间可以互相兼容,其他的都不可以兼容。
| X | S | |
|---|---|---|
| X | 不兼容 | 不兼容 |
| S | 不兼容 | 兼容 |
Innodb存储引擎为了支持多粒度的锁定,这种锁定允许事务在行级别和表级别的锁同时存在。
意向锁:又称为Intention Lock,将锁定的对象分为多个层次,事务希望在多个层级进行同时加锁。
意向共享锁:事务想要获取一张表中的某几行的共享锁(粗粒度)
意向排他锁:事务想要获取一张表中的某几行的排它锁(粗粒度)
2. 如何分析数据库的锁
如果查看当前数据中的锁的情况呢?
SHOW ENGINE INNODB STATUS;
- 1
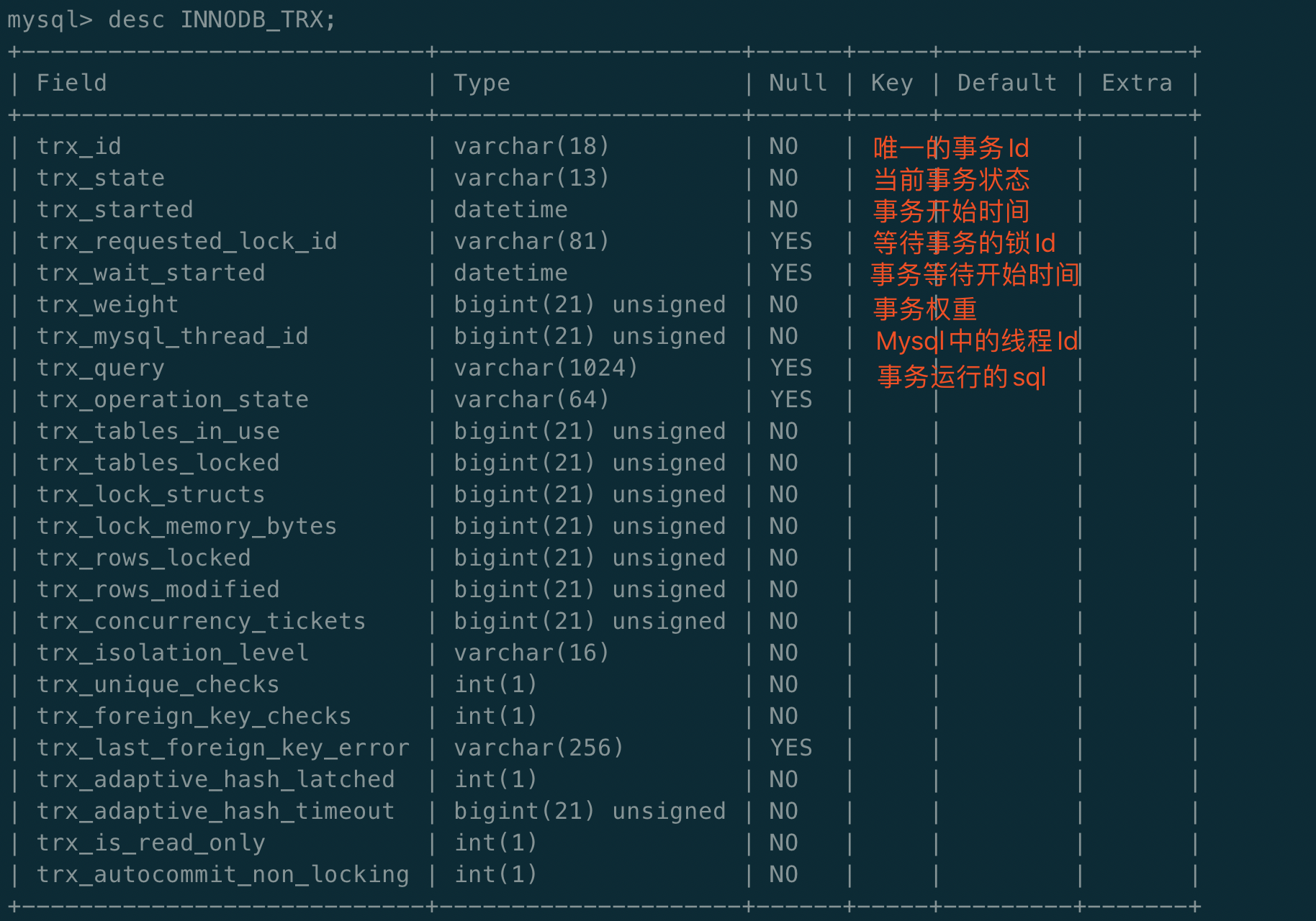
同时Innodb在INFOMATION_SCHEMA架构下添加表INNODB_TRX、INNODB_LOCKS、INNODB_LOCK_WAITS等三张表(注意高版本没有后面两张表哦,笔者初次用的是8.0,没有后面两张表,后面为了演示重新安装了低版本的),用于分析锁的使用情况,我们可以切换到对一个的库下查看表:
-- 可以查看相应的表
use information_schema;
- 1
- 2
利用下面这张表来分析锁的情况
CREATE TABLE `orders` (
`order_num` int(11) NOT NULL AUTO_INCREMENT COMMENT '订单号',
`order_date` datetime NOT NULL COMMENT '订单日期',
`cust_id` int(11) NOT NULL COMMENT '用户Id',
`shop_id` int(11) DEFAULT NULL COMMENT '店铺Id',
PRIMARY KEY (`order_num`),
KEY `ind_orderNum_date` (`order_num`,`order_date`),
KEY `ind_date` (`order_date`)
) ENGINE=InnoDB AUTO_INCREMENT=20059 DEFAULT CHARSET=utf8;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
先向表中插入几条数据
INSERT INTO `orders` (`order_num`, `order_date`, `cust_id`, `shop_id`)
VALUES (20005, '2005-09-01 00:00:00', 10001, 1);
- 1
- 2
开启一个事务插入修改该记录(默认加上排它锁)
BEGIN;
update orders set cust_id = '1000111' where order_num = 20005;
- 1
- 2
开启另外一个事务查询数据(加上共享锁)
begin;
select * from orders lock in share mode;
- 1
- 2
通过INNODB_TRX来分析事务和线程之间的关系
select * from INNODB_TRX\G;
- 1
结果如下:


其中事务Id=281479687086576为共享锁查询的语句(处于阻塞状态),事务Id =16914为排它锁更新的语句(处于运行状态)
但是上面两张图中似乎标记了事务Id、其关联的锁Id、及事务的状态,没有锁的更多信息,那怎么确定锁的信息呢?
还记得我们上面说的三张表吗?INNODB_TRX、INNODB_LOCKS、INNODB_LOCK_WAITS,可以通过这三张表来分析事务、锁、线程之间的关系。
3. MVCC
可能经常会听到多版本控制(Multi Version controll),在有的书中又称为一致性非锁定读,通过字面意思可以知道不需要锁定就可以保证多次读写是一致的。
InnoDB使用基于时间点的快照来获取查询结果,读取时在访问的表上不设置任何锁,因此,在事务T1读取的同一时刻,事务T2可以自由的修改事务T1所读取的数据,事务T1不需要等待某一行上的锁释放。这种读操作被称为一致性非锁定读。
思考一下,什么是快照数据呢?解释1
快照数据指该行的之前版本的数据,主要是通过undo段来实现,而undo是用来在事务中回滚数据,快照本身是没有额外的开销,并且不存在对快照数据上锁,因为没有人会对历史数据上锁的呀
为什么需要MVCC呢?
可以很有效的提高并发情况下的数据库效率,因为读取的时候不需要等待另一个事务提交。那可能有人就会问了,那会不会存在数据不一致呢?这个问题很好,但是也需要根据不同的隔离级别来区分。
隔离级别为READ UNCOMMIT和Serializable时不需要MVCC想想原因,因此,只有READ COMMIT和REPEATABLE READ时,才存在MVCC,才存在一致性非锁定读。但是两者的非锁定一致性读还是不一样的,主要区别在于读取快照不一样。
READ COMMIT时,同一个事务内的每一个一致性读总是设置和读取它自己的最新快照。也就是说,每次读取时,都再重新拍得一个最新的快照(所以,READ COMMIT时总是可以读取到最新提交的数据)。READ UNCOMMIT时,同一个事务内的所有的一致性读 总是读取同一个快照,此快照是执行该事务开始时的行数据版本。
这就是为什么通常所说的REPEATABLE READ是可重复读的,但是READ COMMIT是不可重复读的。
下面来分析一下为什么出现这种情况。
还是以之前的orders表为例:
-- 插入记录
INSERT INTO `orders` (`order_num`, `order_date`, `cust_id`, `shop_id`)
VALUES (20005, '2005-09-01 00:00:00', 10001, 1);
– 先开启事务1,主要目的是查询一条数据
begin;
select * from orders where order_num = 20005;
– 再开启另一个事务2,主要目的是更新2005的那条记录
begin;
update orders set cust_id = ‘1000111’ where order_num = 20005;
– 但是两个事务都没有提交,理论情况下,第一事务的查询无论是在READ COMMIT还是REPEATABLE READ都是可以读取到记录cust_id=1001,
– 因为第二个事务没有提交。
–如果事务2提交事务
commit;
– 等事务2提交之后,如果事务1再读取这行数据时,读到的数据在READ COMMIT和REPEATABLE READ下是完全不一样的。
– 因为在READ COMMIT隔离级别下会读到
– cust_id = '1000111’的这条记录
首先查看一下目前的数据库隔离级别
select @@tx_isolation\G;
1. row
@@tx_isolation: REPEATABLE-READ
– 这种隔离级别下,在事务1再次查询记录
select * from orders where order_num = 20005;
+-----------±--------------------±--------±--------+
| order_num | order_date | cust_id | shop_id |
+-----------±--------------------±--------±--------+
| 20005 | 2005-09-01 00:00:00 | 10001 | 1 |
+-----------±--------------------±--------±--------+
在事务的隔离级别为REPEATABLE-READ时,同一个事务中可以重复读,两次读取到的记录一样的。这种又称为可重复读取。
如果将数据库事务隔离级别调整为READ COMMIT,在查看两次读取的记录是否一致
-- 修改数据库事务隔离级别
set session transaction isolation level read committed;
-- 再查看事务隔离级别
select @@tx_isolation\G;
– 重复刚才测试的步骤
– 先开启事务1,主要目的是查询一条数据
begin;
select * from orders where order_num = 20005;
+-----------±--------------------±--------±--------+
| order_num | order_date | cust_id | shop_id |
+-----------±--------------------±--------±--------+
| 20005 | 2005-09-01 00:00:00 | 10001 | 1 |
+-----------±--------------------±--------±--------+
– 再开启另一个事务2,主要目的是更新2005的那条记录
begin;
update orders set cust_id = ‘1000111’ where order_num = 20005;
– 再继续在事务1中查询记录
select * from orders where order_num = 20005;
+-----------±--------------------±---------±--------+
| order_num | order_date | cust_id | shop_id |
+-----------±--------------------±---------±--------+
| 20005 | 2005-09-01 00:00:00 | 10001112 | 1 |
+-----------±--------------------±---------±--------+
大致的测试流程如下:

在隔离级别为READ COMMIT,同一个事务中的多次读取竟然读到的记录时不一样的。这就是不可重复读。
4. 一致性锁定读
一致性锁定读从题目中可以看出读取的时候会加上一把锁,区别在于加什么锁。
InnoDB有两种不同的SELECT,即普通SELECT 和 锁定读SELECT。
锁定读SELECT 又有两种,
- SELECT … FOR IN SHARE MODE | FOR SHARE 对读取该行的记录加S锁,其他事务可以向被锁定的行加S锁,但是不能加X锁。
- SELECT … FOR UPDATE 对读取的某行会加上X锁,其他事务不能对已加锁的记录做任何操作
注意:所有讨论的范围都是在事务中,否则加锁也是没有意义的,当事务提交了,锁也就释放了,因此在上述两个语句时,必须加上BEGIN、START TRANSACTION 、SET AUTOCOMMIT=0
4. 锁的算法
对于行锁有三种算法
- Record Lock:单个行记录的锁
- Gap Lock:间隙锁,锁定的是一个范围,但是不包括记录本身。
- Next-key Lock:Record Lock + Gap Lock,锁定的是范围+记录本身(Innodb默认采用的是该种方式)
比如针对于一个索引有1,2,3,5,则Next-key Lock可能的范围有
(-∞, 1],
(1,2],
(2,3],
(3,5]
为什么需要通过这种方式呢,主要是为了避免(Phantom Problem)幻读问题。
什么是幻读问题呢?
幻读:Phantom Problem指的是同一事务中,连续执行两次同样的sql可能导致不一样的结果,第二次的sql可能会返回之前不存在的行。
可能熟悉的人会疑惑,不是说REPEATABLE-READ解决不了幻读吗,这不矛盾了嘛。(这里吐槽一下,国内很多文章瞎抄袭,以讹传讹)这里标记一下,主要是采用Next-key Lock来避免幻读问题。
而且直接锁定一个范围不是很影响性能吗,Innodb为了更可能的降低性能的影响,不断地的缩短锁的范围,如果是查询的索引含有唯一的属性,Innodb会降级锁,将其降为行锁,也就是说只锁定一行记录。但是这种情况仅限于查询所有的唯一索引列,如果唯一索引列是由多列组成,而查询仅是多个唯一索引列中的一个,那么还是采用的是next-key Lock。
-- id作为主键
-- age作为索引
create table users(
id int comment '用户Id',
age int comment '年龄',
primary key(id),
key(age)
);
– 插入四条纪录
insert into users values(1,1);
insert into users values(3,2);
insert into users values(5,3);
insert into users values(7,5);
– 通过如下命令观察唯一索引锁定和普通索引锁定的区别
– 开启事务T1
begin;
select * from users where age = 3 for update;
– 对于这个语句,由于有两个索引,需要分别锁定
对于主键 : 锁定的是id = 5这一行,而对于辅助索引,利用的是</span><span class="token keyword">Next</span><span class="token operator">-</span><span class="token keyword">key</span> <span class="token keyword">Lock</span><span class="token punctuation">锁定的范围是(1,3],
同时还会对辅助索引的下一个键值加上</span>gap <span class="token keyword">lock</span><span class="token punctuation">, 因此综合锁定的范围为(1,5]
– 开启事务2
begin;
select * from users where id = 5 lock in share mode;
– 这句话无法执行,因为事务T1已经对该行加上了X锁
insert into users values (4,2);
– 这句话同样无法执行,因为辅助索引 2 在锁定的范围之内
insert into users values (9,4);
根据以上的分析,如果没有Gap Lock锁定范围,那么用户可以插入age=2的记录,这会导致事务T1再次执行同样的查询时会返回不同的记录,这就是导致(Phantom Problem)幻读问题。
如何显示的关闭Gap Lock呢?
1、将事务的隔离级别设置为READ COMMITED(在生产实践中,有的公司会将隔离级别设置为READ COMMITED这样可以很好的避免插入数据的时候出现死锁情况。)
2、将参数innodb_locks_unsafe_for_binlog设置为1
2. 如何解决Phantom Problem(本质上等同于不同重复读问题)
在Mysql默认的事务隔离级别(REPEATABLE-READ)下,Innodb存储引擎采用Next-key Locking机制就可以避免不同重复读问题。
先来描述一下幻读的情况,如果想要重现幻读的情况,需要将数据库的隔离级别调整为READ COMMITED
-- 先设置数据库的隔离级别,将其设置为'READ-COMMITTED'
set session tx_isolation='READ-COMMITTED';
-- 创建一个新的表t
CREATE TABLE `t` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
– 向里面插入三条记录
1,2,5
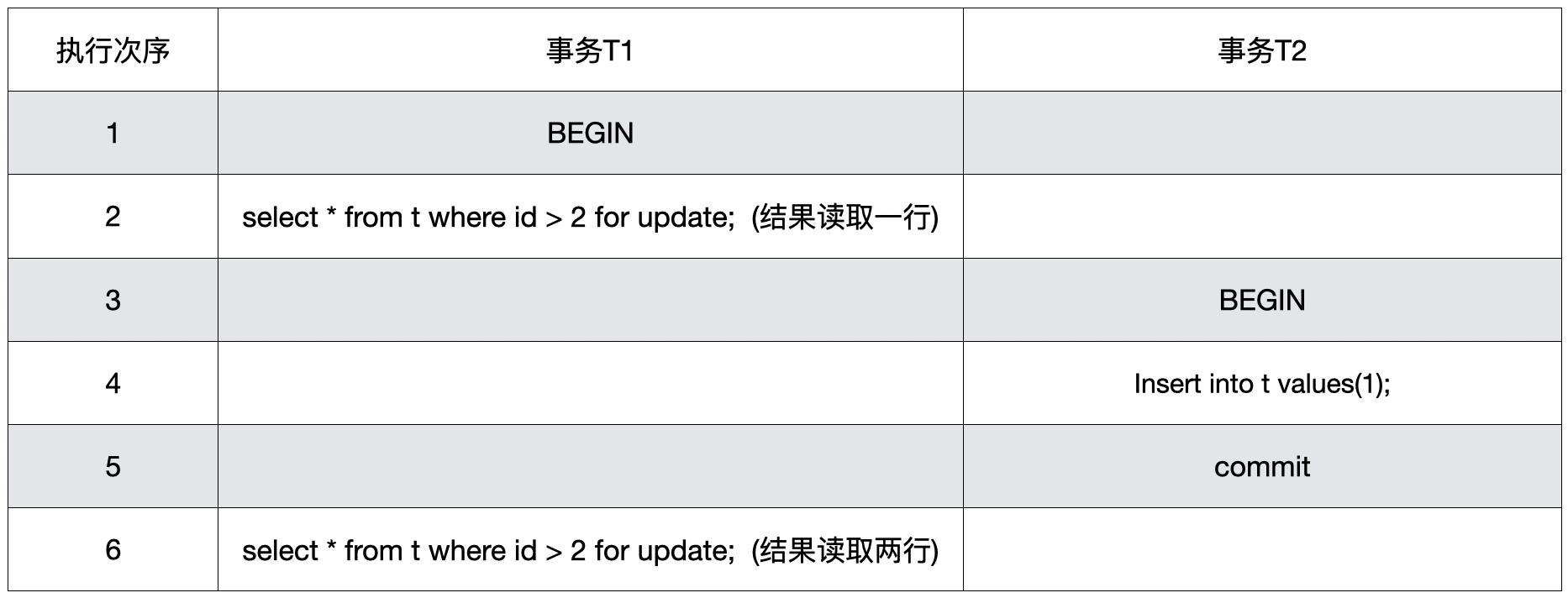
– 1. 开启事务T1
begin;
select * from t where id > 2 for update; –这个sql只会查出一条记录 id = 5
– 2. 开启事务T2
begin;
insert into t values(4);
commit;
– 3. 此时事务T1又一次查询了同样的语句
select * from t where id > 2 for update; – 同样的语句在同一个事务中却得到了不同的记录。id = 4 , id = 5
上面整个过程用表格描绘如下
但是在数据库隔离级别为REPEATABLE-READ时则不可能出现这种情况,为什么呢?
因为隔离级别为REPEATABLE-READ时select * from t where id > 2 for update;这条查询语句锁住的不只是id=5这一行记录,而是对于(2,+∞)进行了锁定,对于整个范围内的插入都是不允许的。
5. 锁的问题(不同隔离级别的问题)
1. 脏读
含义:一个事务可以读到另一个事务未提交的数据,这违反了数据库的隔离性。这种一般是数据库隔离级别设置为READ UNCOMITTED导致的。
2. 不可重复读
含义:在同一个事务中两次读取到的数据不一致。这种主要是由于事务T1在执行过程中,事务T2对同样的数据进行了修改导致的,或者是增加数据导致的。这种违反了数据库的一致性。
Innodb主要是通过next-key Lock来避免不可重复读问题。
实际的例子如下:
在Mysql中,官方文档将不可重复度问题定义为 Phantom Problem,这种不是严格意义上的幻想问题。所以说如果说如何解决幻读,需要区分一下什么问题定义为幻读。
6. 死锁问题
1. 什么是死锁
死锁:两个或者两个以上的事务在执行过程中,由于争夺资源而造成的一种互相等待的现象。
和多线程死锁差不多。
比如事务T1,先获取资源A,在等着获取资源B
事务T2,先获取资源B,在获取资源A
两个事务有可能相互等待,造成了死锁情况。
这种情况下,两个事务啥都干不了,空消耗系统的资源,因此尽可能的避免死锁。
那应该如何避免死锁呢?
- 要么采用粗鲁的方法只要等待就回滚
- 要么则通过超时回滚,但是不是两个事务都回滚。当两个事务互相等待时,当一个等待时间超过设置的某一个阈值,则超时的事务回滚,另一个事务继续执行。
可以通过参数innodb_lock_wait_timeout来设置超时时间,默认是50s
show variables like "innodb_lock_wait_timeout";
+--------------------------+-------+
| Variable_name | Value |
+--------------------------+-------+
| innodb_lock_wait_timeout | 50 |
+--------------------------+-------+
- 通过等待图(
wait-for graph)来检查死锁,可以主动的寻找死锁。主要是通过检测图中是否有环,如果有环,则说明有死锁。
等待图主要有两个基本信息
1、锁的信息链表
2、事务等待链表
下面来举一个死锁的例子

总结
对于锁,无论是数据库中的锁还是并发编程中的锁,其原理其实都是差不多的。数据库中整体的目的都是为了尽可能降低直接锁定数据,采用MVCC等手段,更可能提高性能。















 472
472











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









