









本文来说下关于微服务跨数据库联合查询的一些解决思路
问题由来

解决思路
下面提供几个思路仅供参考
表字段冗余
想必大家已经很熟悉,几乎每天都会打交道,不用多讲。
需要指出的是冗余字段不能太多,建议控制在2-4个左右。否则会出现数据更新不一致问题,一旦冗余字段有改动,极容易产生脏数据。
解决思路
建立同步机制,必要时采取人工补偿措施。
所以,合理的字段冗余是润滑剂,减少join关联查询,让数据库执行性能更高更快。
聚合服务封装查询
简单来说,就是把不同服务的数据统一组装在一个新的服务里做聚合,对外提供统一入口API接口查询。通俗来说下,就是以前在同一个数据库里面的表之间使用join来关联,现在可能这些表不在同一个数据库上了,怎么办,可以把每一个数据库里面的数据查询出来,最后使用java等语言把最终需要的结果拼装起来。反正是需要最终的结果,没法join了,用java来拼呗。
聚合服务的数据组装是以API接口调用来实现,一般不建议直连数据库连表查询。这样做的好处是减少服务间调用次数以及查询库表压力。
在实际的业务开发中,我们经常碰到类似的需求,而聚合服务不失为一种较彻底的服务解耦实现方式。
表视图查询
如果涉及到不同数据库表之间的join查询,可以在其中某一数据库的表上建立视图(view)关系,这种方式非常高效,只需要开发一个简单接口对外提供服务就可以了,而且省去聚合服务带来调用、查询、聚合的复杂性。
前提条件
- 数据库需要部署在同一台服务器上
- 数据库账户密码必须相同,也就是在同一个schema下
另外表视图查询这种方式,是一种紧耦合的设计方式,不利于程序扩展,除非你很确定将来业务变动不大,可以考虑使用。以笔者经验来看,不适合大规模使用。
多数据源查询
这种方式是一种比较技术化的思路,简单来说就是一个微服务配置多个数据库源(DataSource),进行数据源来回切换进行库表查询,以达到获取不同数据的目的。
实现思路
- 利用DynamicDataSource
- 利用Spring的AOP动态切换数据源
- 利用Spring的依赖注入方式管理Bean数据源对象
分库分表:使用数据库中间件
Sharding-Shpere
想必做过分库分表的同学对他一定不陌生,其出身来至当当开源项目sharding-jdbc。非常有限的跨库查询解决方案,目前在京东内部已经广泛使用。sharding-jdbc创始人张亮已加入京东,sharding-jdbc还在不停的迭代,目前更名为sharding-shpere,已经入Apache顶级项目,进行孵化,非常看好它。

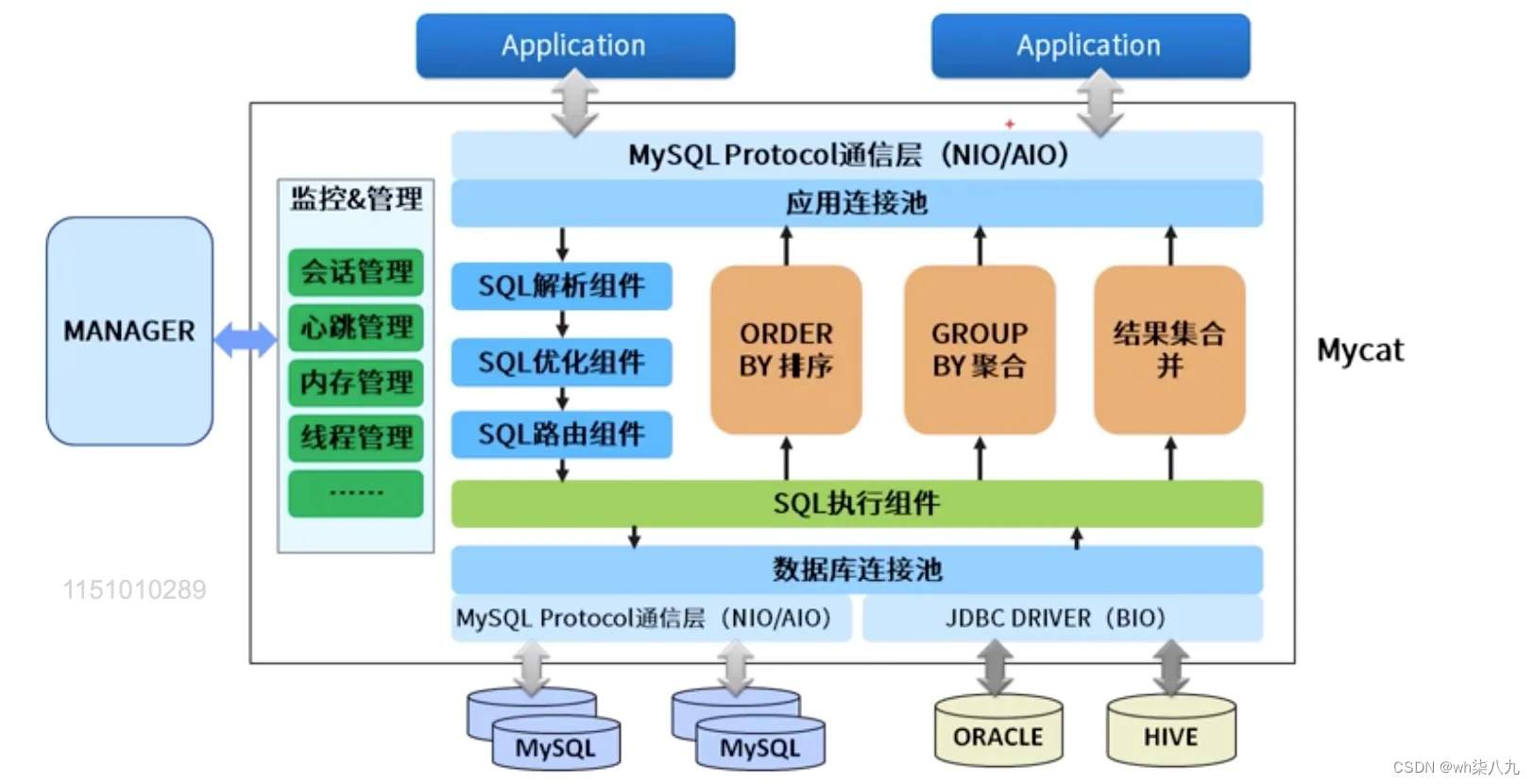
Mycat
一个彻底开源的,面向企业应用开发的大数据库集群,支持事务、ACID、可以替代MySQL的加强版数据库;一个可以视为MySQL集群的企业级数据库,用来替代昂贵的Oracle集群;一个融合内存缓存技术、NoSQL技术、HDFS大数据的新型SQL Server;结合传统数据库和新型分布式数据仓库的新一代企业级数据库产品;一个新颖的数据库中间件产品。
本文小结
本文介绍了一些现在常用的解决微服务跨库的解决方案,所有服务的划分是十分重要的。














 4336
4336











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









