










(ESL最长的一章,也是非常重要的一块内容。关联规则这一块内容真的看得慢,不知道是书到最后看的细了,还是对这类问题的思路以及噪声对比估计的知识陌生)
目录
- 14.1 导言
- 14.2 关联规则
- 14.3 聚类分析
- 14.4 自组织映射Self-Organizing Maps
- 14.5 主成分、表面和曲线Principal Components, Curves and Surfaces
- 14.6 非负矩阵分解Non-negative Matrix Factorization (NMF)
- 14.7 独立成分分析Independent Component Analysis与探索投影追踪Exploratory Projection Pursuit
- 14.8 多维缩放Multidimensional Scaling
- 14.9 非线性降维Nonlinear Dimension Reduction和局部多维缩放Local Multidimensional Scaling
- 14.10 谷歌PageRank算法
14.1 导言
- P486 无监督学习中,直接推断 P ( X ) P(X) P(X)的性质。 X X X的维度有时比监督学习中高很多,我们关心的性质经常比简单的位置估计 μ ( x ) \mu (x) μ(x)复杂得多.不过因素在某种程度上被缓解,原因在于我们不需要在其它变量的值改变的情况下推断 P ( X ) P(X) P(X)的性质怎么改变.(这里应该是说 Y Y Y对 X X X分布的影响)
- P486 降维:主成分、多维缩放、自组织映射、主曲线等尝试识别具有高数据密度的空间中的低维流形manifold,提供了这些变量之间的关联信息,以及它们是否可以看成更小的“潜 (latent)”变量的集合的函数
聚类分析:试图找 X X X空间中包含 P ( X ) P(X) P(X)的多重凸区域,判断 P ( X ) P(X) P(X)是否可以表示成简单密度混合
关联规则:试图构造简单的联合规则描述高维的二值数据特殊情形中的高密度区域 - P487 无监督学习缺乏评价指标。必须诉诸heuristic arguments(翻译成启发式参数?)
14.2 关联规则
- P487 关联规则分析association rule analysis寻找
X
=
(
X
1
,
X
2
,
…
,
X
p
)
X=(X_1, X_2, \dots, X_p)
X=(X1,X2,…,Xp)在数据中最频繁的联合值,其中
X
j
∈
{
0
,
1
}
X_j\in\{0,1\}
Xj∈{0,1}二值数据的应用最多。更一般地,关联分析的目标是寻找高概率的
X
X
X的原型
v
l
,
l
=
1
,
…
,
L
v_l, \ l=1,\dots, L
vl, l=1,…,L,对应概率
P
(
v
l
)
P(v_l)
P(vl). 当
v
l
v_l
vl包含不止一个变量,每个变量不止一个值时,观测数量大幅减少,估计困难。所以需要进行简化。一个简化方法是不寻找高概率
X
X
X的值,而是寻找高概率的区域。令
S
j
\mathcal S_j
Sj表示第
j
j
j个变量的所有可能取值的集合,即支撑集support,并令
s
j
⊆
S
j
s_j\subseteq \mathcal S_j
sj⊆Sj,使联合规则conjuctive rule
∩
j
=
1
p
(
X
j
∈
s
j
)
\cap_{j=1}^p(X_j\in s_j)
∩j=1p(Xj∈sj)概率相对较大
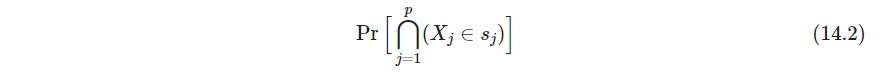
当 s j = S j s_j=\mathcal S_j sj=Sj,称变量 X j X_j Xj没有出现在规则14.2中
14.2.1 购物篮分析Market basket Analysis
- P488 在式14.2中,进一步简化,只考虑
s
j
=
{
v
0
j
}
s_j=\{v_{0j}\}
sj={v0j}或
s
j
=
S
j
s_j=\mathcal S_j
sj=Sj的情况
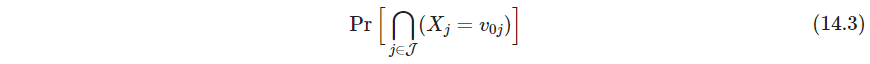
其中 J ⊂ { 1 , … , p } \mathcal J \subset\{1,\dots, p\} J⊂{1,…,p}.
假定支撑集 S j \mathcal S_j Sj都是有限集,那么可以对其全部运用哑变量dummy variables得到 Z k Z_k Zk,从而哑变量数目为
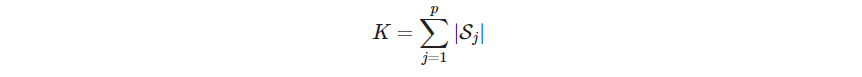
式14.3变为使下式最大
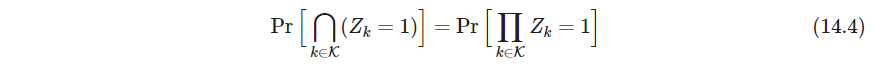
其中
K
⊂
{
1
,
…
,
K
}
\mathcal K\subset\{1,\dots,K\}
K⊂{1,…,K}。这是购物篮问题的标准形式。集合
K
\mathcal K
K称为项集item set,项集中
Z
k
Z_k
Zk的数量称为它的大小size,一定不大于原始变量个数
p
p
p. 式14.4的估计值直接用数据集统计
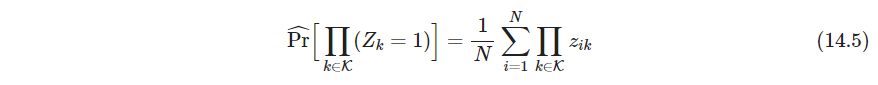
上式称作项集
K
\mathcal K
K的支撑support或流行prevalence
T
(
K
)
T(\mathcal K)
T(K)(注意这是集合
K
\mathcal K
K的函数)
关联规则确定支撑下界
t
t
t,然后寻找所有的项集
K
\mathcal K
K,即
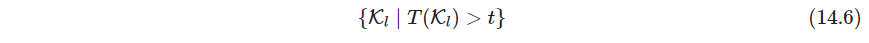
14.2.2 Apriori算法
- P489 从所有
2
K
2^K
2K个可能项集中寻找满足式14.6的一种快速算法
易知 ∣ { K ∣ T ( K ) > t } ∣ |\{\mathcal K|T(\mathcal K)>t\}| ∣{K∣T(K)>t}∣相对不大, L ⊆ K ⇒ T ( L ) ≥ T ( K ) \mathcal L \subseteq K \Rightarrow T(\mathcal L)\geq T(\mathcal K) L⊆K⇒T(L)≥T(K)
所以方法为第一遍扫一项的,然后把筛出来的,扫一边两项的,再筛出来的,扫一遍三项的……Apriori算法对 ∣ K ∣ |\mathcal K| ∣K∣的每个值只需要扫一遍。有一些算法用来加速Apriori。该算法标注数据挖掘技术的主要进步 - P489 每一个高支撑项集
K
\mathcal K
K被放到“关联规则”的集合中,项
Z
k
,
k
∈
K
Z_k, k\in \mathcal K
Zk,k∈K被分成两个不相交子集,
A
∪
B
=
K
A\cup B=\mathcal K
A∪B=K,并写成
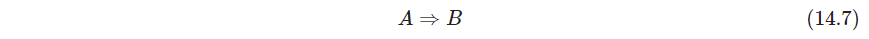
A , B A,B A,B分别被叫做前因antecedent、后果consequent(也许这就是关联规则的“规则”的含义)
关联规则基于在数据库中antecedent和consequent项集的“流行”(有定义,往上翻),来定义一些性质,
规则 T ( A ⇒ B ) T(A\Rightarrow B) T(A⇒B)的支撑support是在前因项集和后果项集的并集中观测占比,也就是项集 K \mathcal K K的支撑. 可以看成随机选择的购物篮中同时观测到 P ( A a n d B ) P(A\ and\ B) P(A and B)的概率.
该规则的置信度confidence或可预测性predictability是支撑比前因的支撑(感觉这个定义很实用啊)
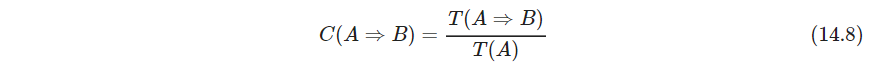
也即 P ( B ∣ A ) P(B|A) P(B∣A),其中 P ( A ) P(A) P(A)是 P ( ∏ k ∈ A Z k = 1 ) P(\prod_{k\in A} Z_k=1) P(∏k∈AZk=1)的缩写
期望置信度expected confidence定义为后果的支撑 T ( B ) T(B) T(B),是无条件概率 P ( B ) P(B) P(B)的估计
规则的lift定义为置信度比期望置信度
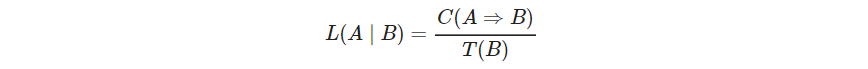
这是 P ( A a n d B ) / P ( A ) P ( B ) P(A\ and\ B)/P(A)P(B) P(A and B)/P(A)P(B)的估计(注意这个lift是有可能大于1的。这个定义的意思可能是 T ( B ) T(B) T(B)越低,lift越高,也即观察到 B B B时, A A A正确的概率越高)
该分析的目的是产生高支撑和置信度的关联规则14.7,高支撑已经讨论过了,高置信度则还需一条筛选条件
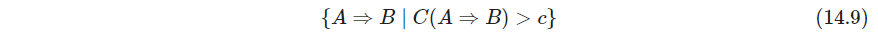
这里 A , B A,B A,B的划分仍然是 ∣ K ∣ |\mathcal K| ∣K∣指数级的情况,Agrawal et al. (1995)提出了一种从项集14.6构造的所有可能规则中快速筛选方法。(机器学习实战也提到过)整个分析的输出是满足下面约束的关联规则14.7的集合
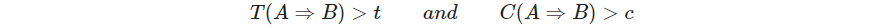
- P491 数据库中可能的查询方式
- P492 Apriori允许分析非常大的数据库
- P492 Apriori的限制包括:应用的数据类型;当支撑阈值降低时,项集个数、大小和数据传递次数指数增长,所以计算可行性成为问题。所以高置信度或高lift、低支撑的规则,很难发现
14.23 例子:购物篮分析
- P493 把带有缺失值的观测删了;有序变量用中位数划分成二值变量;无序变量one-hot
- P492 处理完只有50个二值特征,但是关联规则有6288条,支撑集为10%,涉及 ≤ 5 \leq 5 ≤5个预测变量。这关联规则好多啊
- P492 实际购物篮问题中,我们经常关心相对罕见的关联,关心存在的关联,而非缺失的关联。例如本例中我们可能仅仅关注高收入,而不关心非高收入
14.2.4 无监督作为监督学习Unsupervised as Supervised Learning
-
P495 一个把密度估计问题转为监督函数近似的技术,这是广义关联规则的基础
-
P495 制造负样本。令 g ( x ) g(x) g(x)是待估计概率密度, g 0 ( x ) g_0(x) g0(x)是参考的确定的概率密度,例如定义域上的均匀分布。 x 1 , x 2 , … , x N x_1, x_2,\dots, x_N x1,x2,…,xN从 g ( x ) g(x) g(x)iid采样,大小为 N 0 N_0 N0的样本通过蒙特卡洛法从 g 0 ( x ) g_0(x) g0(x)采样。混合两个数据集,从 g ( x ) g(x) g(x)抽取的样本赋权重 N 0 / ( N + N 0 ) N_0/(N+N_0) N0/(N+N0),从 g 0 ( x ) g_0(x) g0(x)采样的样本赋权重 w 0 = N / ( N + N 0 ) w_0=N/(N+N_0) w0=N/(N+N0),得到从混合密度 ( g ( x ) + g ( x 0 ) ) / 2 (g(x)+g(x_0))/2 (g(x)+g(x0))/2中抽取的随机样本。如果从 g ( x ) g(x) g(x)抽样赋值 Y = 1 Y=1 Y=1,从 g 0 ( x ) g_0(x) g0(x)抽样赋值 Y = 0 Y=0 Y=0,则
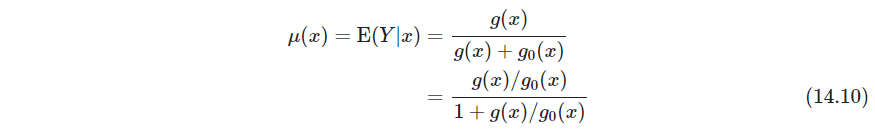
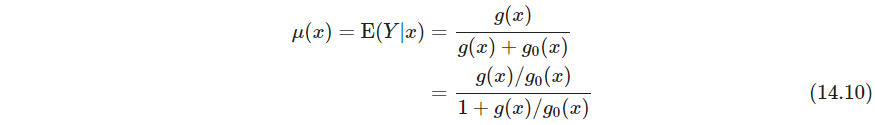
这里 μ ( x ) \mu(x) μ(x)可以当作有监督问题做,用如下带权数据集
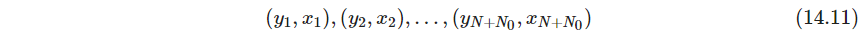
学到的 μ ^ ( x ) \hat \mu(x) μ^(x),可以反解
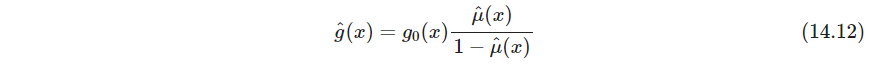
广义logistic回归适合建模这个问题,因为log-odd直接估计更直接
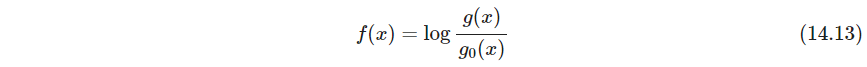
(也就是说预测时逻辑回归的输出值直接就拿来用了,不用再转概率绕一下)从而
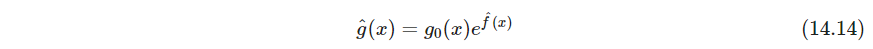
(这个思路和蒲公英书15.5.3.3噪声对比估计NCE类似,NCE也是把概率密度估计转成二分类问题。该方法和NCE还是有一定区别的,NCE直接用交叉熵学建模概率的参数,参数在真是概率上;该方法学一个概率预测器,参数在概率预测器上,然后直接用预测器推断出真实概率。但是这两者可能反应的是同一个东西,但建模的东西不一样。因为根据式14.14,可以建模 g ^ \hat g g^,也可以建模 μ ^ \hat \mu μ^,这两者是单调递增的关系)
原则上任意密度都可以作为 g 0 g_0 g0,但实际中 g ^ \hat g g^的准确性非常依赖于特定选择,好的选择取决于 g ( x ) g(x) g(x)和估计式14.10和14.13的过程。书上具体讨论了 g 0 g_0 g0的选择和问题的目的有关,毕竟 μ \mu μ衡量了 g g g和 g 0 g_0 g0的差异,可以重点关注均匀密度的偏离、联合正太的偏离,甚至独立性的偏离,如
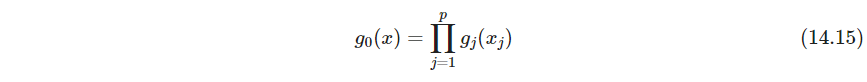
通过对数据集中每个变量重新随机排列,14.15的样本可以很容易的从数据本身产生(妙啊!这种采样方式) -
P497 statistics folklore什么意思
14.2.5 广义关联规则Generalized Association Rules
- P497 在寻找高密度区域的更一般问题式14.2,可以通过上述的监督学习方法来解决.尽管不能想购物篮分析那样应用于大数据库,但可以从适当大小的数据集中得到有用的信息
- 目标14.2可写为使下式最大
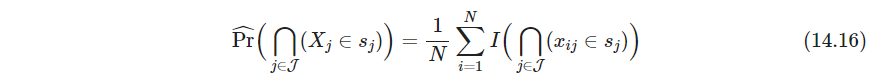
其中 J ⊂ { 1 , 2 , … , p } \mathcal J \subset \{1,2,\dots, p\} J⊂{1,2,…,p}. 根据关联规则的命名方式, { ( X j ∈ s j ) } i ∈ J \{(X_j \in s_j)\}_{i\in \mathcal J} {(Xj∈sj)}i∈J称为“广义"项集generalized item set, s j s_j sj对于定量变量取连续区间,对类别变量可取不止一个单值。所以搜索空间巨大,需要启发式方法
式14.5和14.16都隐式以均匀分布为参考分布,这样倾向于寻找边缘分布 X j ∈ s j X_j\in s_j Xj∈sj是独立频繁individually frequent的(这两句话没读懂)
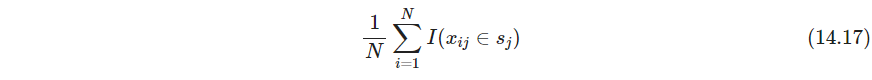
频繁子集14.17的联合倾向于在高支撑的项集中出现,这就是为什么尽管高关联、或者说高lift的规则 v o d k a ⇒ c a v i a r vodka\Rightarrow caviar vodka⇒caviar不可能被发现,因为没有一项有高边缘支撑,所以该子集的支撑也很低(这里应该是想表达选均匀分布作为参考分布的问题在于只能发现高支撑的项集,有可能发现不了高lift的项集。感觉关联规则还是要找高关联,只找高频繁项集并非主要目的)。用均匀分布作为参考只能得出高频率项集,其组成部分之间可能具有低关联性,并在最高支撑项集的集合中占主导
高频子集 s j s_j sj由最频繁的 X j X_j Xj的并组成。把参考分布选为边缘密度的积,式14.15,消除了对单个变量高频的偏好,如果变量完全独立,没有关联,则此时 g ( x ) / g 0 ( x ) g(x)/g_0(x) g(x)/g0(x)是均匀的(应该是说该值恒定,无关于 x x x. 以两个变量 x 1 , x 2 x_1, x_2 x1,x2为例,感觉此时实际上就是在求list g ( x 1 , x 2 ) / g ( x 1 ) g ( x 2 ) g(x_1, x_2)/g(x_1)g(x_2) g(x1,x2)/g(x1)g(x2)),这样 v o d k a ⇒ c a v i a r vodka \Rightarrow caviar vodka⇒caviar的规则有机会出现。
问题在于怎样将参考分布而不是均匀分布纳入Apriori算法中,从14.15采样这倒是没什么难度。所以可以像式14.11采样,转成有监督问题,依据高 μ ( x ) = E ( Y ∣ x ) \mu(x)=E(Y|x) μ(x)=E(Y∣x),找高的 g / g 0 g/g_0 g/g0,也即
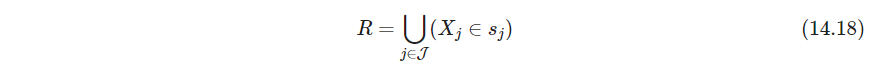
此外,支撑不要太少
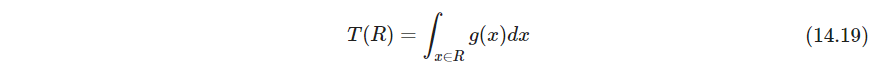
14.2.6 监督学习方法的选择
- P499 14.8的区域由联合规则定义,所以能学习这些规则的方法是最合适的,CART的叶结点就很适合,用它来学式14.11的数据集。最后CART学出来的高的平均概率
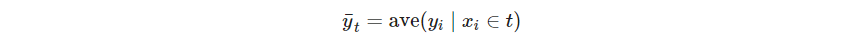
就是具有高支撑广义项集的候选,真正的支撑则由下式给出(这个式子不理解,而且感觉不对)
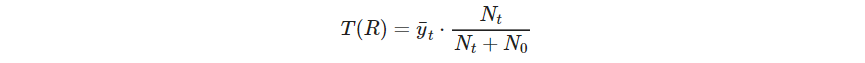
其中 N t N_t Nt是叶结点的观测数
PRMI也是一种很好的学习方法,符合14.18形式,但它特别找高支撑区域来最大化14.10目标的平均值,而不是试图在整个数据空间建模,它也控制了在支撑数和平均目标之间的权衡
习题14.3说CART和PRIM存在一个问题,在通过重新排列边缘分布生成随机数据的情况下。(没做。。)
(总的来说,用CART或PRIM的方式把本来解空间巨大的广义关联规则问题变得可解,找出了有限个叶子结点区域,得到高置信度和支撑的联合规则)
14.2.7 例子:购物篮分析
- P501 广义关联规则和Apriori找出的规则相比:Apriori找到成千上万条规则,很难进行比较。然而,可以对一般的要点进行比较,Apripro算法是穷举,相反,PRIM是贪心的不保证最优解;Apriori只能处理哑变量,例如无法处理 type of home ≠ apartment \text{type of home} \neq \text{apartment} type of home=apartment这样的规则,除非对 apartment \text{apartment} apartment和其他 home \text{home} home的类别变量用哑变量进行编码(但是这么做,哑变量数目就爆炸了)
14.3 聚类分析
- P501 聚类分析cluster analysis,也叫数据分离data segmentation,聚类本身就有许多不同的目标,书上有列
- P502 聚类分析的所有目标的核心是相似性度量,与监督问题中的loss相似
- P503 K-means是自顶向下top-down的过程,而书中描述的其他聚类方式是自下而上bottom-up的
- P503 本节先讲度量,这是所有聚类方法的基础
14.3.1 邻近矩阵Proximity Matrices
- P503 直接用点对之间的邻近proximity来表示数据的相似性或不相似性。这种类型的数据表示成 N × N N\times N N×N的矩阵 D \bf D D,其中 N N N为样本数量, d i i ′ d_{ii'} dii′表示第 i i i个样本和 i ′ i' i′样本之间的邻近proximity,该矩阵就是聚类算法的输入。许多算法假定一个非负的不相似矩阵,对角元素为0. 如果数据是用相似性收集的,可以用单调下降函数转成不相似性
- P503 主观判断的不相似性并不能代表距离,因为不满足三角不等式,所以一些采用距离的算法不能用这些数据
14.3.2 基于属性的不相似性Dissimilarities Based on Attributes
- P504 各种度量
- 定量变量:包括相关系数
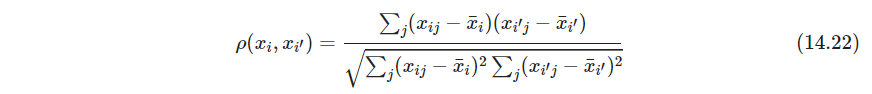
其中 x ˉ i = ∑ j x i j / p \bar x_i=\sum_j x_{ij}/p xˉi=∑jxij/p,这是在变量上平均,而不是在观测上。如果观测已经标准化,那么 ∑ j ( x i j − x i ′ j ) 2 ∝ 2 ( 1 − ρ ( x i , x i ′ ) ) \sum_j(x_{ij}-x_{i'j})^2\propto 2(1-\rho(x_i, x_{i'})) ∑j(xij−xi′j)2∝2(1−ρ(xi,xi′)),因此基于协方差、或者说相似性的聚类和基于平方距离等价 - 有序变量:经常用邻接整数表示,将
M
M
M个原始值表示成下式
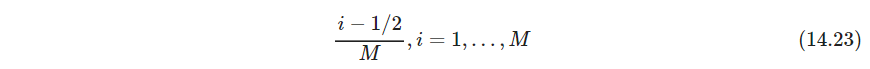
然后当作该尺度下的定量变量处理(这处理也不算是标准化吧,好处是什么) - 类别变量:差异必须明确表示出来,一般假定损失相等,不相等的损失可以突出某些差异
- 定量变量:包括相关系数
14.3.3 样本不相似性Object Dissimilarity
- P505 将
p
p
p个单属性不相似性
d
j
(
x
i
j
,
x
i
′
j
)
,
j
=
1
,
…
,
p
d_j(x_{ij}, x_{i'j}),j=1,\dots, p
dj(xij,xi′j),j=1,…,p结合成一个总的不相似度量
D
(
x
i
,
x
i
′
)
D(x_i, x_{i'})
D(xi,xi′),基本是采用凸结合的方式
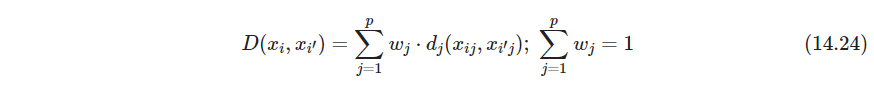
把 w j w_j wj都设置为一样,并不代表每个特征等影响。所有的数据对的平均不相似性为
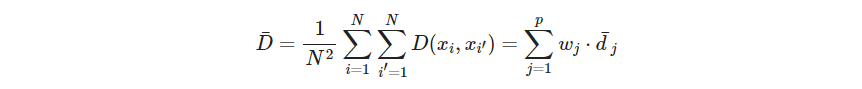
其中
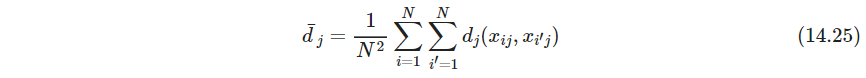
是第 j j j个特征的平均不相似性,设置 w j ∼ 1 / d ˉ j w_j\sim 1/\bar d_j wj∼1/dˉj会让所有特征有相等的影响。 d d d如果是平方距离的话,就变成了2倍方差 - P506 把所有特征给等影响也并不一定合理,要看具体问题的知识。有些特征可能没啥用. 如果目标是发现数据的自然分类,一些特征或许会表现出更多的分类趋势.和分组约有关的变量越应赋予高的权重,此时如果给所有特征相等权重会趋于隐藏掉这个分类现象(说的也对,如果有一维度天然分两段,另一维度不怎么分得开,确实应该多关注第一个维度)
- P506 确定一个合适的不相似度量比选择聚类算法更重要,这也依赖于特定问题
- P507 缺失值。最普遍的方法是不计算有缺失的 x i j , x i ′ j x_{ij},x_{i'j} xij,xi′j对。如果两个观测没有共同测量值,那就没办法了,只能删掉。或者用均值、中位数等填缺失值。对于类别变量,“缺失”本身可以做一类,不过这样做隐含了两个样本都缺失时是相似的
14.3.4 聚类算法
- P507 聚类算法分为三类:
组合算法combinatorial algorithms:直接对观测数据进行处理,不直接引用潜在的概率模型
混合模型mixture modeling:假设数据是从某概率密度函数对应的总体中抽取的iid样本. 密度函数用参数化模型表征,该参数化模型为各组分密度函数的混合;每个组分密度表示其中的一类,接着利用极大似然或者对应的贝叶斯方式来拟合
模式寻找mode seeking, bump hunters:采用非参观点,试图直接估计不同的概率密度函数的模式. 与每个单独的模式最接近的观测定义为单个簇。(PRIM属于这类方法,不过PRMI到底如何做聚类倒是并不清楚)
14.3.5 组合算法Combinatorial Algorithms
- P507 不基于概率模型,类别数
K
<
N
K<N
K<N预先定义,可以形式化为多对一映射,即编码器
k
=
C
(
i
)
,
k
∈
{
1
,
…
,
K
}
k=C(i), k\in \{1,\dots,K\}
k=C(i),k∈{1,…,K},
C
C
C通过给每个观测的类来显式描述,过程的“参数”就是
N
N
N个观测中分类的类,并最小化一个损失函数,表征聚类目标没有达到的程度
一种想法是通过组合优化的方法来优化下式损失、也叫能量函数
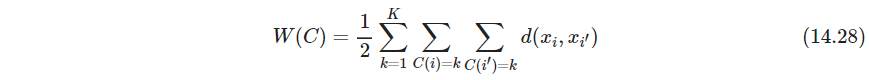
(k-means好像不是这个loss,差一点点)
这也被叫做类内点散“within cluster”point scatter
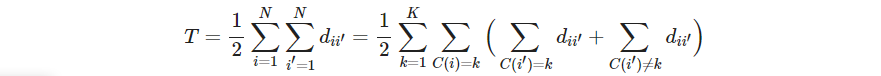
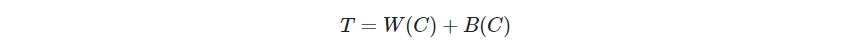
其中 d i i ′ = d ( x i , x i ′ ) d_{ii'}=d(x_i, x_i') dii′=d(xi,xi′), T T T是总点散total pint scatter,是定值
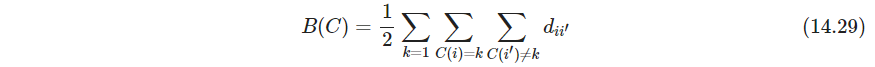
B ( C ) B(C) B(C)是类间点散between-cluster point scatter,最小化 B ( C ) B(C) B(C)等价于最大化 W ( C ) W(C) W(C)
组合优化的聚类分析就是枚举,可能情况非常多,为(似乎是 N N N个有差别的球放入 K K K个无差别的盒子中)
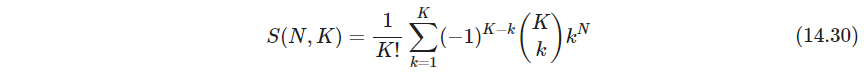
所以只能验证非常少量的情况,所以目标是找到可能包含最优解、或较优解的子集
一种可行策略是迭代贪心下降iterative greedy descent。每一步迭代以某种方式改变划分,贪心找最好的,当这种方式不能再改变时,算法终止。每一步迭代是上一次的扰动。这些算法收敛到局部最优,与全局最优相比可能是高度次优的
14.3.6 K均值聚类
- P509 习题14.1给出把带权特征算距离转为统一权重
- P509 K-means因为使用欧式距离,所以类内点散等价于优化到类重心的距离
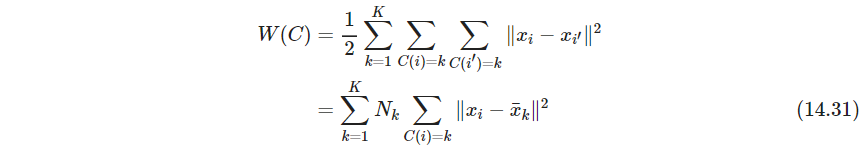
(不对,我觉得Kmeans不是这个Loss,优化均值没问题,但是优化 x i x_i xi的划分时,注意这里有 N k N_k Nk,不一定找离得更近的原型就一定会让 W W W变小,如果离得最近的原型 N N N很大,样本很多,那 W W W反而上升。P510这一页Each of steps…那一段第二行说的可能就不太对) - P510 关于局部极小值,Hartigan and Wong(1979)的算法进一步研究,并且保证了单个从一个类转到另一个类不会降低目标值(好像确实存在这种情况,一个样本点跳到另一类,目标值更低了)
- P510 泰森多边形Voronoi tessellation
14.3.7 高斯混合作为“软”K均值聚类
- P512 高斯部分的方差趋于0时,后验变成硬划分0或1
14.3.8 例子:人类肿瘤微阵列数据
- P513 根据类内平方和的kink(估计是肘点elbow point)来选择聚类数量,毕竟类越多,类内平方和越低
14.3.9 向量量化Vector Quantization
- P514 向量量化vector quantization,VQ这个术语应该是从信号和图像处理那边发展出来的,只不过它借用了kmeans做法,也叫Lloyd’s算法
- P514 对 2 × 2 2\times 2 2×2的小块block当作一个样本点,属于空间 R 4 \mathbb R^4 R4,进行聚类。对于1024×1024的图片,相当于有512×512块
- P515 码字codeword;编码簿codebook:类重心集合;编码encoding:聚类过程;解码decoding:重构图像
- P515 有损压缩lossy compression;失真度distortion或称退化degradation;无损压缩lossless compression
- P515 根据不同类出现的频率,可以进一步压缩信息,例如霍夫曼编码
- P515 VQ有很多推广,例如树结构的VQ,tree-structured VQ用自顶向下、2-均值算法来找重心,如14.3.12节所述,这允许压缩的逐步加细
14.3.10 K中心点K-medoids
- P516 K-means因为采用平方欧式距离,对离群点缺乏鲁棒性,这些问题可以通过以计算为代价消除(其实我不知道这里的鲁棒性是指什么鲁棒性,根据后文猜测,可能是类别中心容易被离群点拉走)
- P516 换度量,类重心 { m 1 , … , m K } \{m_1,\dots,m_K\} {m1,…,mK}也要跟着用其他显式方法优化。在大多数情形中,每个簇的中心限制为当前该簇中的其中一点. 该算法假定数据带属性,但也可以用于仅用邻近矩阵proximity matrices描述的数据(因为簇中心已经被限制为样本点了). K-medoids不需要显式计算簇中心,仅需跟踪它的索引 i k ∗ i_k^* ik∗
- P517 交替优化类中心和样本类归属,就是一种启发式方法来优化下式
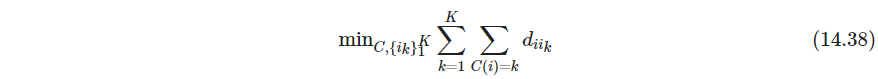
Kaufman and Rousseeuw (1990)提出另一种方法直接求解(14.38),可以暂时交换每个簇中心和当前不是簇中心的观测,所选的交换要使准则(14.38)最大降低,重复这步直至找不到有利交换.Massart et al. (1983)2 导出了寻找(14.38)的全局最小值的分枝定界组合算法branch-and-bound combinatorial method,但只适合非常小型数据集 - P517 例子:国家不相似性。该例子中只有邻近矩阵,没有观测,所以K-means用不了,不过K-medoids可以用。而且可以用MDS可视化
14.3.11 实际问题
- P518 关于类重心的初始化,方法包括从随机选择到向前分段划分的特定策略。具体地,在每一步,选好 i 1 , … , i k − 1 i_1,\dots, i_{k-1} i1,…,ik−1的基础上选择 i k i_k ik来最小化损失函数,重复 K K K次,得到 K K K个初始化中心
- P518 簇数 K K K可能和任务有关,书上举了个销售员的例子。但是更多的,簇的个数未知,需要估计。交叉验证一类的方法不能用,因为簇越多,损失越低几乎是必然。书上介绍的还是用肘点来选择,不过有一段很有道理的分析,甚至还形式化了,书上管这个点叫做kink
- P519 Gap统计量Gap statistic(Tibshirani et al. 2001b)比较曲线 log W k \log W_k logWk和从包含数据的长方形区域中均匀采样得到的曲线。估计最优簇数为两条曲线的差值最大处。本质上,这是一种自动找肘点的方式。当数据落在一个簇时,该方法也趋于估计最优簇数为1,而此时大部分方法都失效
- P519 Gap统计量Gap Statistic选簇数 K K K的例子。这里也要使用一个标准误差原则。(这里标准差不知道怎么算的,是不是20次聚类结果不同,所以能算。而且这个具体的计算过程好像和Gap统计量的找曲线差值最大处也不太一致)
14.3.12 层次聚类
- P520 层次聚类hierarchical clustering不需要指定簇数,但需要指定两个组的不相似性,这基于一堆观测的不相似性
- P520 两种策略范式paradigm:自下而上的合并agglomerative、自顶向下的分裂divisive. 这两者分别选最相似和最不相似的进行
- P521 如何决定哪个层次代表真实的聚类,取决于用户,需要在相同簇内的观测比不同簇内的观测足够地更相似。Gap统计量可以用于此
- P521 大部分合并方法,以及一些分裂方法当从下往上看时,都有单调性.即合并簇间的不相似性随着合并的层次增加而增加(最小、最大、平均距离都可以证。方法是证明其他簇到和新合并簇的距离比到合并前的两簇中距离小者大),因此二叉树中每个结点高度可以画成与两个子结点间的相似性成比例.叶结点画在0高度上.这种图称为谱系图dendrogram. 谱系图给出了层次聚类的高可解释的、完整的描述.这也是该方法流行的主要原因之一。在谱系图上水平切一刀,就能得到不相交的簇,即聚类结果,也即超过某个阈值的不相似度不再认为是一类。另外,不同的阈值具有嵌套性(图14.12中每个分叉点的高度代表了不相似性)
- P521,522 谱系图经常看成数据本身的图示,而非算法的结果描述.然而这样的解释需要谨慎.首先,不同的层次方法,或数据微小变化,都会导致非常不同的谱系图.另外,这样图示只有在成对观测的不相似性具有算法产生的层次结构时,才有用.层次聚类在数据上强加了某层次结构,不管这样的结构在数据中存不存在(细品这句话,有那么点感觉)
谱系图层次结构表示数据的程度可用共表型相关系数cophenetic correlation coefficient来刻画,计算 N / ( N − 1 ) N/(N-1) N/(N−1)对观测的不相似性 d i i ′ d_{ii'} dii′,与从谱系图导出的共表型不相似性cophenetic dissimilarities C i i ′ C_{ii'} Cii′的相关系数,后者是两个观测所在的最小同一簇的两子簇间不相似性. 共表型不相似性有一个局限性, N ( N − 1 ) N(N-1) N(N−1)对数据的取值只有 N − 1 N-1 N−1个非叶节点这么多种,另外,这种不相似性满足超度量不等式ultrametric inequaliy
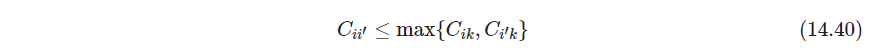
如果放在欧式坐标系中, i , k , i ′ i,k,i' i,k,i′表示三点, C C C表示距离,则只允许腰不小于底边的等腰三角形,所以这三个点不能随便摆。这就意味着这个空间(应该类比成一个内积空间,因为带距离)的表达能力受限,所以谱系图(带上上共表型不相似性?)是应用特定算法的强加的聚类结构
(满足这个超度量不等式,似乎 K K K个点最多只能有 K − 1 K-1 K−1个 C C C取值) - P523-525 合并聚类agglomerative clustering. 单链接Single linkage、简称SL,合并聚类用最小不相似性作为度量;全链接Complete linkage,简称CL、合并聚类用大不相似性;群平均Group Average、简称GA,聚类用平均不相似性。如果每个簇都很紧凑,簇间分的很开,那么这三者返回结果一致
单链接容易产生链chaining,违背了簇的紧致,如果定义簇内直径为最大不相似性,单链接会产生直径非常大的簇;
全链接则完全相反,但是可以构造出违背相近性的簇,即某个簇的观测与其他簇成员比到自己簇成员更近;
群平均聚类则是两者这种,不过群平均据类对数值尺度敏感,例如施加单调函数 h h h作用于 h ( d i i ′ ) h(d_{ii'}) h(dii′),可能改变结果。而单链接和全链接则不改变结果,只和 d d d的序有关,这种不变性被视为单链接或全链接优于群平均的论据。不过群平均是下式的估计
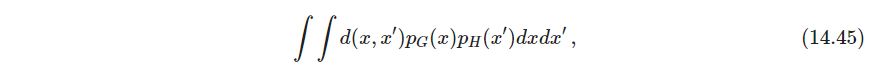
当簇中样本 N → ∞ N\to \infty N→∞,群平均不相似性 d G A ( G , H ) d_{GA}(G,H) dGA(G,H)趋于式14.45. 这也即两个分布之间的某个特征(类似散度). 而对于单链接则趋于0,全链接则趋于无穷,独立于这两个密度。不清楚单链接和全链接在估计总体的哪个量(说明平均链接有一个好的数学意义) - P525 例子:人类癌症微阵列数据。平均链接和全链接给出类似的结果,单链接得到不平衡的簇,其中有长而细的簇。平均链接和K-means类似,但它有更好的特点.通过不同高度横切谱系图,会得到不同的簇,且嵌套.另外,它给出了某些关于样本的偏序信息。谱系图中为了确定叶子的顺序,必须加上约束.使用S-PLUS的默认规则:在每一次合并时,更紧的簇放在左边。也可以按照其他规则,例如14.8节的多维缩放
- P525 分裂聚类divisive clustering. 这类方法没有合并聚类研究得那么透彻,在压缩方面从工程领域进行了一些探索。分裂法优于合并法的一点是当我们关注数据划分成相对少的簇时。分裂范式可以通过递归地应用组合方法,比如在每步分割用
K
=
2
K=2
K=2的K-means或K-medoids,然而这还取决于每一步的初始化,并且不一定能够得到谱系图所需的单调性分割序列.
避免该问题的分裂算法由Macnaughton Smith et al. (1965)提出.将所有观测放入单个簇 G G G中,然后选择到其它所有观测的平均不相似性最大的观测,构成第二簇 H H H的第一个成员.然后 G G G中某观测到 H H H中观测的平均距离,减去该观测到 G G G中其它观测的平均距离,差值达到最大的,转移到 H H H中.重复这个步骤,直到差值为负,由此分出两类。随后的嵌套划分都用这个方法,对当前层的其中一个簇进行分类,选哪个呢?可以选直径最大的簇或者簇内平均不相似性最大的
14.4 自组织映射Self-Organizing Maps
- P528 可以看作是K-means聚类的有约束版本,其中原型prototypes被限制在1维或2维流形中。结果是一个约束拓扑图constrained topological map. SOM是在线的,每次处理1个观测,批处理版本后来被提出。这个技巧也与主曲线和主曲面principal curves and surfaces有着密切的联系。考虑
K
=
q
1
⋅
q
2
K=q_1 \cdot q_2
K=q1⋅q2个原型排布在二维长方形网格中,每个原型用整数坐标对
l
j
∈
Q
1
×
Q
2
\mathcal l_j \in \mathcal Q_1 \times \mathcal Q_2
lj∈Q1×Q2进行参数化,其中
Q
1
=
{
1
,
2
,
…
,
q
1
}
,
Q
2
=
{
1
,
2
,
…
q
2
}
\mathcal Q_1=\{1,2,\dots,q_1\},\mathcal Q_2=\{1,2,\dots q_2\}
Q1={1,2,…,q1},Q2={1,2,…q2},可以把原型想象成纽扣,缝在主成分平面上,SOM试图弯曲平面使纽扣尽可能接近数据点。一旦拟合好,观测可以映射到二维网格中
每处理一个观测 x i x_i xi,在 R p \mathbb R^p Rp中寻找 x i x_i xi的欧式距离最近的原型 m j m_j mj,接着对 m j m_j mj的所有邻居 m k m_k mk,通过下式把 m k m_k mk向 x j x_j xj移动
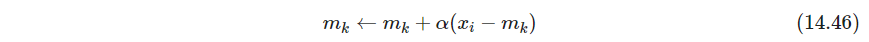
m j m_j mj的邻居定义为使 l j l_j lj和 l k l_k lk距离小的所有 m k m_k mk,可采用欧式距离,设定阈值 r r r,邻居包括 m j m_j mj本身 - P529 该算法性能和学习率
α
\alpha
α、距离阈值
r
r
r有关。一般的,
α
\alpha
α随迭代从1.0下降至0.0,
r
r
r从初始值
R
R
R线性下降到1. 此外,原型更新也可以根据距离用一个软版本
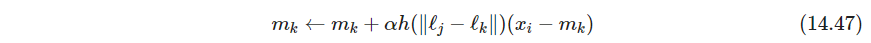
- 如果 r r r足够小,那么只有一个邻居,原型间的空间联系失去,此时SOM就是K-means的在线版本,最终稳定在K-means找到的某个局部极小值上。此外,因为SOM是K-means的约束版本,所以检查约束是否合理很重要,可以计算这两种方法的重构误差 ∥ x − m j ∥ 2 \|x-m_j\|^2 ∥x−mj∥2,对所有观测求和。K-means必然会得到更小的重构误差(为啥,因为SOM是有约束的版本吗?总感觉这么想不够严谨),但不应比SOM小太多
- P531 对于批处理版本,原型直接赋值更新,没有迭代
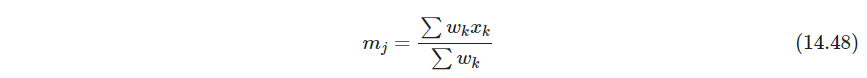
如果邻域足够小,使仅包含 m k m_k mk,在全1即没有衰减的权重下,退化为K均值聚类.这也可以看成是主曲线和主曲面的离散版本 - P532 例子:文件组织与检索。文本特征矩阵稀疏,用SVD降维,Kohonen et al. (2000)采用了SVD的随机版本
14.5 主成分、表面和曲线Principal Components, Curves and Surfaces
14.5.1 主成分Principal Components
- P535 从
p
p
p维降到
q
q
q维
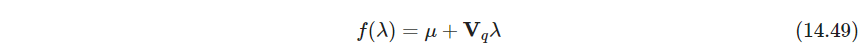
其中 μ ∈ R p \mu \in \mathbb R^p μ∈Rp, V q ∈ R p × q \bm V_q \in \mathbb R^{p \times q} Vq∈Rp×q且正交,(如果不正交可以用QR分解,把 R λ R\lambda Rλ当作坐标), λ ∈ R q \lambda \in \mathbb R^q λ∈Rq是投影后坐标
最小重构误差
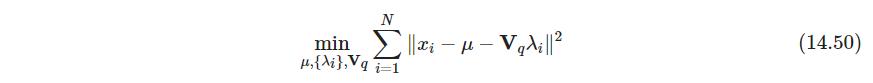
解得
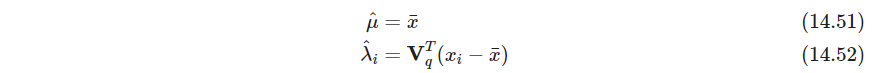
该解不唯一。习题14.7有求解。 μ ^ \hat \mu μ^得解为 V q V q T − I p V_qV_q^T-I_p VqVqT−Ip的零空间加 x ˉ \bar x xˉ - P536 用二维PCA初始化SOM(妙啊)(主成分分析有两种解释,最小重构误差和最大方差。这第三种解释都不对:对于 X X X,寻找一个方向,使其与其他正交超平面内方向的投影,都不想关,则该方向是否一定是主成分方向?我觉得好像不对)
- P536 例子 手写数字. 在找投影平面上离得最近的样本点,一方面考虑了投影平面上的距离,另一方面,正交子空间也给了一定的权重.
- P539 数字图象中的像素点本质上是相关的,小的主成分子集可以看成表示高维数据的极佳低维特征
- P539 例子:Procrustes转换和形状平均
问题描述
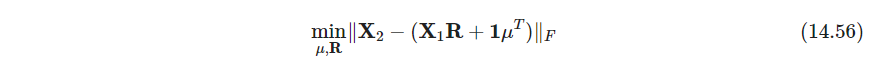
R \bm R R正交矩阵。解为
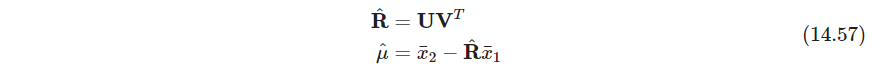
其中 x ˉ 1 , x ˉ 2 \bar x_1, \bar x_2 xˉ1,xˉ2是矩阵的列均值向量, X ~ 1 , X ~ 2 \tilde \bm X_1, \tilde \bm X_2 X~1,X~2是这些矩阵减去均值得到的( x ˉ 1 = X 1 T 1 N N ∈ R 2 , X ~ 1 = X 1 − 1 N x ˉ 1 \bar x_1=\frac{\bm X_1^T \bm 1_N}{N}\in \mathbb R^2, \tilde \bm X_1=\bm X_1- \bm 1_N\bar x_1 xˉ1=NX1T1N∈R2,X~1=X1−1Nxˉ1), X ~ 1 T X ~ 2 = U D V T \tilde \bm X_1^T \tilde \bm X_2=\bm U\bm D\bm V^T X~1TX~2=UDVT. 最小距离称为Procrustes距离Procrustes distance
(注意这里的问题和CVMIL中的写法稍有不同,CVMLI是正交矩阵在左,即 ∥ R X 1 − X 2 ∥ F \|\bm R \bm X_1 - \bm X_2\|_F ∥RX1−X2∥F的形式,不过两者很容易转化,都能把目标转成 t r [ R M 1 M 2 ] tr[\bm R\bm M_1\bm M_2] tr[RM1M2]的形式)
从该解的形式来看,我们可以将每个矩阵进行中心化,接着求出 R ^ \hat \bm R R^,然后写出 μ ^ \hat \mu μ^
带尺度的Procrustes距离解决了更一般问题
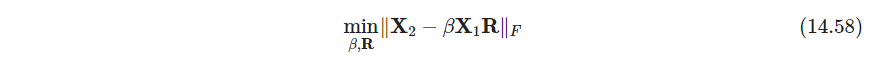
其中 β > 0 \beta>0 β>0
其中 R \bm R R的解不变, β ^ = T r ( D ) / ∥ X 1 ∥ F 2 \hat \beta=Tr(\bm D)/\|\bm X_1\|^2_F β^=Tr(D)/∥X1∥F2( R ^ \hat \bm R R^与 X 1 , X 2 \bm X_1,\bm X_2 X1,X2的尺度无关,尺度只会反应在SVD分解中的 D \bm D D里, U , V \bm U,\bm V U,V不变,尺度无关这个事情感觉还是挺神奇的,想象一下,一个形状向另一个形状靠近,只能通过旋转和翻转,改变尺度居然不会影响结果. 另外 T r ( D ) > 0 Tr(\bm D)>0 Tr(D)>0是一定能保证的,因为奇异值大于0,所以 β ^ > 0 \hat \beta>0 β^>0.另外,如果考虑,平移似乎总是可以在一开始就把 X \bm X X中心化,消去平移的考虑) - P539 形态测量学morphometrics,landmark
- P540 O ( p ) O(p) O(p)群包含反射和旋转的正交矩阵, S O ( p ) SO(p) SO(p)群只允许旋转
- P540 Procrustes平均问题
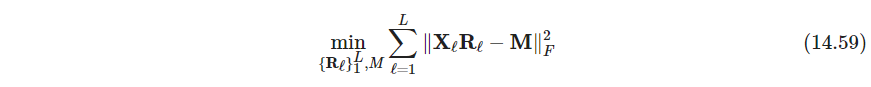
迭代求解
(这一小节和CVMLI一书的17.4.1节中训练样本的对齐可以梦幻联动。那一小节说明了平均模型和变换矩阵的最优化是鸡蛋问题,采用了交替迭代。和这里一模一样)
可以通过施加约束让 M \bm M M是上三角,来强制解唯一。缩放则可以合并到式14.59,见习题14.9 - P541,542 进一步,可以定义一系列形状的具有仿射不变性affine-invariant average的平均(这affine-invariant估计是指
X
l
\bm X_l
Xl就算是经过了仿射变换,也不会影响
M
\bm M
M)
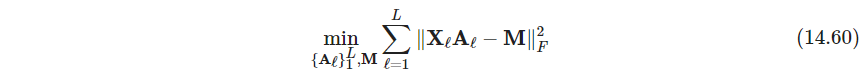
为了防止平凡解,需要施加约束如 M T M = I \bm M^T\bm M=\bm I MTM=I,注意这里 A l ∈ R p × p \bm A_l\in \mathbb R^{p\times p} Al∈Rp×p不要求正交矩阵。这个居然有解析解,参考习题14.10(这题还是挺有技巧的. 另外拉格朗日乘子直接对角,也很奇怪,估计和PCA一样的问题)
令 H l = X l ( X l T X l ) − 1 X l T \bm H_l=\bm X_l(\bm X_l^T \bm X_l)^{-1}\bm X^T_l Hl=Xl(XlTXl)−1XlT, M ∈ R N × p \bm M \in \mathbb R^{N\times p} M∈RN×p由 H ˉ = 1 L ∑ l = 1 L H l \bar \bm H=\frac{1}{L}\sum_{l=1}^L \bm H_l Hˉ=L1∑l=1LHl的最大 p p p个特征向量组成
14.5.2 主曲线和表面Principal Curves and Surfaces
- P541 主曲线推广了主成分直线,用一维光滑曲线来近似
R
p
\mathbb R^p
Rp中的数据点.主曲面更一般化,给出了二维或更高维的流形近似。定义随机变量
X
∈
R
p
\bm X\in \mathbb R^p
X∈Rp的主曲线,讨论有限数据的情况,令
f
(
λ
)
∈
R
p
f(\lambda) \in \mathbb R^p
f(λ)∈Rp为参数化的光滑曲线,每个坐标都是关于
λ
\lambda
λ的光滑函数,
λ
\lambda
λ参数可以被选择成到某一固定点的弧长. 令
λ
f
(
x
)
\lambda_f(x)
λf(x)为曲线上离
x
x
x最近的点,如果满足
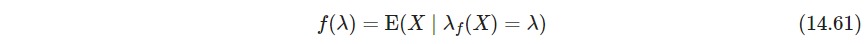
则 f ( λ ) f(\lambda) f(λ)是随机向量 X \bm X X分布的主曲线, f ( λ ) f(\lambda) f(λ)是投影到它的点的平均,也被称为“责任responsible”,这也被称为自洽性self-consistency. 尽管在实际中,多元连续随机变量的分布有无穷多个主曲线(Duchamp and Stuetzle, 1996),但我们主要对光滑的主曲线感兴趣 - P542 主点principal points是类似概念,主曲线是1维,而主点则是 k k k个点的集合,每个点都是自洽的,主点类似K-means类重心的分布。主曲线可以看成是 k = ∞ k=\infty k=∞时的主点,但限制为光滑曲线,用类似的方式,SOM限制 K-means聚类中心的落在一个光滑流形上. (回忆P531,SOM可以看成是主曲线和主曲面的离散版本)
- P542 主曲线的求解,考虑
f
(
λ
)
=
[
f
1
(
λ
)
,
f
2
(
λ
)
,
…
,
f
p
(
λ
)
]
,
X
T
=
(
X
1
,
X
2
,
…
,
X
p
)
f(\lambda)=[f_1(\lambda), f_2(\lambda), \dots,f_p(\lambda)], X^T=(X_1, X_2, \dots, X_p)
f(λ)=[f1(λ),f2(λ),…,fp(λ)],XT=(X1,X2,…,Xp). 可以用类似K-means的迭代方式,
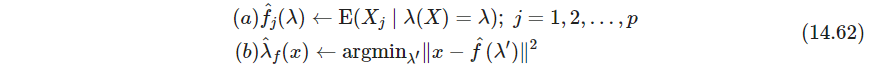
先用线性主成分开始。散点图光滑器(应该是三次光滑、局部核光滑之类的)用于估计步骤 (a) 中的条件期望,这通过将每个维度 X j X_j Xj看成关于弧长 λ ^ ( X ) \hat \lambda(X) λ^(X)的函数来光滑. (b)中的投影通过每个观测数据点实现,(相当于步骤(b)提供了每个数据点的 λ ^ ( X ) \hat \lambda(X) λ^(X),步骤(a)把这些 λ \lambda λ当输入特征, X j X_j Xj当label进行光滑拟合,每个维度都要拟合。有EM那味)
证明一般情况下的收敛很困难,但可证如果光滑中采用线性最小二乘拟合,则该过程将会收敛至第一线性主成分,这等价寻找矩阵最大特征值的幂法power method.(和PRML的P577好像讲的是一个东西,EM方法求解PCA) - P543 主曲面的求解完全相同,不过是在更高维度下。高于2维的主曲面很少用,因为在高维光滑的可视化很少关注
如果用核曲面光滑器来估计 f j ( λ 1 , λ 2 ) f_j(\lambda_1, \lambda_2) fj(λ1,λ2),这与SOM的batch版本式14.48形式相同,SOM的权重 w k w_k wk就是核权重。不过,SOM的数据会共享一部分原型点,SOM和主曲面仅仅当 SOM 原型的个数非常大时两者才一致(可以认为和主曲面的一个区别在于SOM的 λ f ( x ) \lambda_f(x) λf(x)认为是离散的,而主曲面的 λ f ( x ) \lambda_f(x) λf(x)则是连续的)
两者还有一个概念上的区别.主曲面给出了关于坐标函数的整个流形的光滑参量化,而 SOMs是离散的并且仅仅产生近似数据的估计原型.主曲面的光滑参量化保持局部的距离,所以图14.28中,红色聚类点比绿色或蓝色聚类点更紧凑(对于SOM, 因为没有使用二维的距离,没有迹象能表明 SOM 投射中关于红色簇比其它的簇更紧。SOM的核距离是算在原型坐标之间的,主表面则是算在 λ \lambda λ上,我这两者的效果不知道有多大差距)
14.5.3 谱聚类Spectral Clustering
- P544 K-means采用了球形或椭球形度量,从而对非凸的簇不友好. 谱聚类是一个扩展,和局部多维缩放local multidimensional-scaling有关联
- P544 谱聚类中,所有观测点的成对相似性
s
i
i
′
≥
0
s_{ii'}\geq 0
sii′≥0构成
N
×
N
N\times N
N×N的相似性矩阵,用无向图
G
=
⟨
V
,
E
⟩
G=\left \langle V,E \right \rangle
G=⟨V,E⟩表示. 聚类变成图划分问题graph-partition problem
关于相似性,书中采用了径向基核函数 s i i ′ = exp ( − d i i ′ 2 / c ) s_{ii'}=\exp(-d_{ii'}^2/c) sii′=exp(−dii′2/c),其中 c > 0 c>0 c>0是尺度函数, d d d是欧式距离。有许多方法定义相似性矩阵,例如mutual K-nearest neighbor graph,定义 N K \mathcal N_K NK为K近邻中的对称子集,连接所有的对称最近邻,然后给出权重(注意这里KNN本身不一定对称,但是图的邻接矩阵adjacency matrix W = { w i i ′ } \bm W=\{w_{ii'}\} W={wii′}是一定需要对称的),对不属于 N K \mathcal N_K NK的点对相关性赋0;另外,也可以包含所有成对边
定义顶点 i i i的度为 g i = ∑ i ′ w i i ′ g_i=\sum_{i'}w_{ii'} gi=∑i′wii′, G \bm G G是对角元为 g i g_i gi的对角矩阵,最后图的拉普拉斯矩阵graph Laplacian定义为
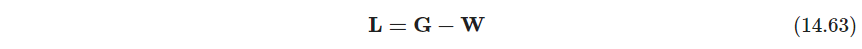
也称为未归一化的unnormalized,,有一系列归一化版本,对拉普拉斯矩阵的度进行,例如 L ~ = I − G − 1 W \tilde \bm L=\bm I-\bm G^{-1}\bm W L~=I−G−1W(这样的变换好像使得 L ~ \tilde \bm L L~不对称了) - P545 谱聚类中,对拉普拉斯矩阵进行特征分解,也叫谱分解,把特征值低的 m m m个特征向量留下来(注意拉普拉斯矩阵一定半正定,有一个特征值为0,把它删去),形成 Z N × m \bm Z_{N\times m} ZN×m,对 Z \bm Z Z的行进行聚类,对应到原始的数据点中。书上用了10-NN构图,用第2、3小的特征向量
- P545 谱聚类的原理:
对任意向量 f \bm f f
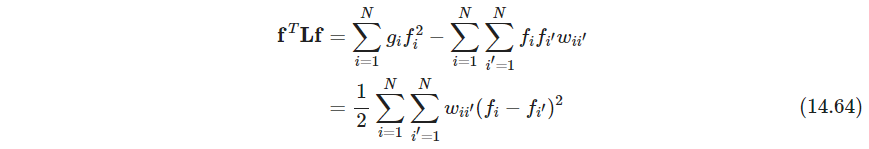
根据习题14.21,由公式14.64知0特征值对应的特征向量在同一个部分中一定为常数,所以只有一个部分的图的0特征值只有1重根. 对于非负边的无向图,如果有 m m m个相连的成分,可以对顶点重排,得到分块对角的 W \bm W W,进而分块对角的 L \bm L L,有 m m m个特征向量对应0特征值,这个零特征向量张成的空间为相连部分的指示向量 I A 1 , … , I A m I_{A_1}, \dots, I_{A_m} IA1,…,IAm. 实际上,连接有强有弱,则零特征值也可以用较小的特征值代替.(这个逻辑就是说如果有多个成分,那么拿0特征值对应的指示向量进行聚类就是最棒的。我的想法是弱连接可以看作是对本来不相连的部分施加的一点点连接,导致原先为0的特征值现在抬升一点点,原先分开的指示向量倍扰动了一点点,所以谱聚类中选特征值最小的那几个,但这里总觉得太不严谨了,还是理解的不透彻不明白) - P547 谱聚类是寻找非凸簇的一种有趣方法,当归一化后,有另一种解释方法,定义 P = G − 1 W \bm P=\bm G^{-1}\bm W P=G−1W,考虑图上的转移概率矩阵 P \bm P P进行随机游走,谱聚类得到簇,对应簇间很少发生转移(这是马尔可夫矩阵吧)
- P547 谱聚类有一些调的,比如全链接或最近邻?最近邻参数个数 k k k,核缩放参数 c c c,特征向量个数,簇的个数. 图14.29的右上图,看到最小的三个特征值与剩余部分没有大区分.所以选多少个特征向量不清楚.(所以特征值分离是选特征值数量的一个原则吗)
14.5.4 核主成分Kernel Principal Components
-
P547 谱聚类与核主成分KPCA有关联,KPCA就是在变换后的空间用PCA
-
P547 X \bm X X的主成分 Z \bm Z Z可通过内积矩阵 K = X X T \bm K=\bm X\bm X^T K=XXT计算,先对 X \bm X X中心化得到 ( I N − 1 N 1 N T N ) X (\bm I_N - \frac{\bm 1_N\bm 1_N^T}{N})\bm X (IN−N1N1NT)X,记 M = 1 N 1 N T / N \bm M = \bm 1_N \bm 1_N^T / N M=1N1NT/N,则通过中心化后的内积矩阵
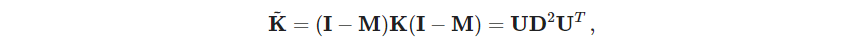
得到 Z = U D \bm Z=\bm U \bm D Z=UD. 习题18.15展示了怎么计算这个空间中新观测的投影
进一步 Z = K ~ U D − 1 \bm Z = \tilde \bm K \bm U \bm D^{-1} Z=K~UD−1,从而对于第 m m m个主成分作坐标 z i m = ∑ j = 1 N α j m ⋅ K ~ ( x i , x j ) z_{im}=\sum_{j=1}^N \alpha_{jm} \cdot \tilde K(x_i, x_j) zim=∑j=1Nαjm⋅K~(xi,xj),其中 α j m = u j m / d m \alpha_{jm}=u_{jm}/d_m αjm=ujm/dm,新的数据点也有类似的算法,见习题14.16
(对比PRML12.3节) -
P548 将 z m \bm z_m zm看作主成分函数 g m ∈ H K g_m\in \mathcal H_K gm∈HK在样本处的取值,其中 H K \mathcal H_K HK是由 K K K生成的RKHS空间,则第一主成分 g 1 g_1 g1求解
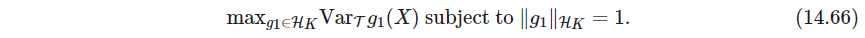
这里 V a r T Var_{\mathcal T} VarT表示训练数据 T \mathcal T T上的样本方差,可以证明 g 1 ( ⋅ ) = ∑ j = 1 N c j K ( ⋅ , x j ) g_1(\cdot)=\sum_{j=1}^N c_j K(\cdot, x_j) g1(⋅)=∑j=1NcjK(⋅,xj),解为 c ^ j = α j 1 , j = 1 , … , N \hat c_j = \alpha_{j1},\quad j=1,\dots, N c^j=αj1,j=1,…,N. 第二个主成分函数也类似定义,但多了限制 ⟨ g 1 , g 2 ⟩ H K = 0 \left \langle g_1,g_2 \right \rangle_{\mathcal H_K}=0 ⟨g1,g2⟩HK=0(这一段理解不能,RKHS我基本上都理解得不好. 仔细读还是能读懂的) -
P548 如果采用径向基核函数
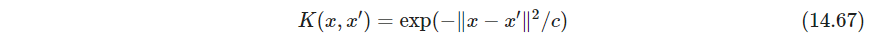
则核矩阵 K \bm K K与谱聚类得相似性矩阵 S \bm S S形式相同,边的权重矩阵 W \bm W W是 K \bm K K的局部化版本,将不是最近邻的成对点相似性给0. 找 K \bm K K的最大特征值,等价于找 I − K ~ \bm I-\tilde \bm K I−K~的最小特征值,这与式14.63的拉普拉斯矩阵很像。区别在于对角矩阵 G \bm G G是顶点的度,和 K ~ \tilde \bm K K~要求特征空间中心化
(注意 K K K的内积不是定义在 x x x上的,而是定义在希尔伯特空间里的,该空间里的元素是函数,所以 K ( 2 x , x ′ ) ≠ 2 K ( x , x ′ ) K(2x,x')\neq 2K(x,x') K(2x,x′)=2K(x,x′)这不违反内积定义,内积定义只规定了 ⟨ 2 K ( ⋅ , x ) , K ( ⋅ , x ′ ) ⟩ = 2 ⟨ K ( ⋅ , x ) , K ( ⋅ , x ′ ) ⟩ \left \langle 2K(\cdot, x), K(\cdot, x') \right \rangle=2\left \langle K(\cdot, x), K(\cdot, x') \right \rangle ⟨2K(⋅,x),K(⋅,x′)⟩=2⟨K(⋅,x),K(⋅,x′)⟩. 所以也没有 K ( x , y ) + K ( z , y ) = K ( x + z , y ) K(x,y)+K(z,y)=K(x+z, y) K(x,y)+K(z,y)=K(x+z,y),不要瞎弄.)
(图14.30,采用了NN + 径向基作为核函数,问题是这个一定半正定吗) -
P550 核主成分对于核的尺度以及核形式本身很敏感.也看到谱聚类中最近邻截断对于能否成功很重要
14.5.5 稀疏主成分Sparse Principal Components
- P550 通过查看方向向量 v j v_j vj,或称载荷loadings来判断哪个变量在起作用,进而对主成分进行解释.如果方向方向本身稀疏,那么解释会很容易. 这一节简要讨论能导出具有稀疏载荷的主成分方法,都是基于lasso
- P550 给定
X
∈
R
N
×
p
\bm X\in \mathbb R^{N\times p}
X∈RN×p,并且已经中心化. Joliffe et al. (2003)的SCoTLASS过程采用了最大方差

进一步,限制第 k k k主成分与前 k − 1 k-1 k−1个垂直,来找稀疏主成分. 该问题非凸,求解困难 - P550 Zou et al. (2006)采用了最小化重构误差,令
x
i
x_i
xi为
X
\bm X
X的第
i
i
i行
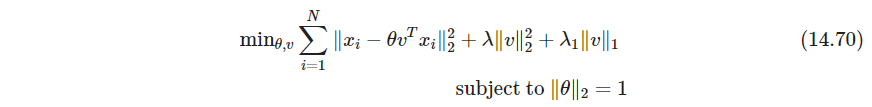
有如下结论:- 若 λ = 0 , λ 1 = 0 , N > p \lambda=0,\lambda_1=0,N>p λ=0,λ1=0,N>p,易证 v = θ v=\theta v=θ且是最大主成分方向
- 当 p ≫ N p\gg N p≫N,解不一定唯一,除非 λ > 0 \lambda>0 λ>0. 对任意 λ > 0 , λ 1 = 0 \lambda>0, \lambda_1=0 λ>0,λ1=0, v v v的解与最大主成分方向成比例(我没解出来,不想解了)
- λ 1 \lambda_1 λ1鼓励稀疏性
- P551 对于多重主成分,最小化
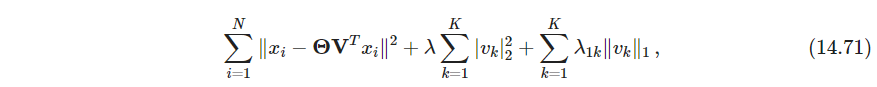
其中 Θ T Θ = I K , V = ( v 1 , … , v K ) ∈ R p × K , Θ ∈ R p × K \bm \Theta^T\bm \Theta= \bm I_K, \bm V=(v_1,\dots, v_K)\in \mathbb R^{p\times K},\bm \Theta\in \mathbb R^{p\times K} ΘTΘ=IK,V=(v1,…,vK)∈Rp×K,Θ∈Rp×K,该目标关于 V , Θ \bm V,\bm \Theta V,Θ不是联合凸的,但是固定某一个后,另一个是凸的,固定 Θ \bm \Theta Θ,然后对 V \bm V V最小化等价于 K \bm K K个elastic net问题,可以高效求解. 固定 V \bm V V,求解 Θ \bm \Theta Θ则是procrustes问题的一个低秩版本,习题14.12。所以两步交替优化至收敛 - P551 胼胝体的例子,这里数据预处理是用了Procrustes(CVMLI 17章好像也是这么预处理的). 稀疏PCA产生只某几个特征变换,PCA则所有特征都变化。这个分析中,稀疏主成分过程提供了一个更简洁,并且可能更有信息量的描绘
14.6 非负矩阵分解Non-negative Matrix Factorization (NMF)
- P553 非负矩阵分解中数据以及成分假定为非负的,对非负数据的建模有用,比如图像
X ∈ R N × p \bm X\in \mathbb R^{N\times p} X∈RN×p
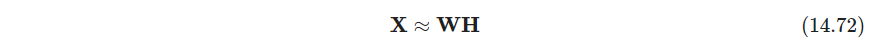
其中 W ∈ R N × r , H ∈ R r × p , r ≤ max ( N , p ) \bm W\in \mathbb R^{N\times r}, \bm H\in \mathbb R^{r\times p},r\leq \max(N,p) W∈RN×r,H∈Rr×p,r≤max(N,p),假设 x i j , w i k , h k j ≥ 0 x_{ij}, w_{ik},h_{kj}\geq 0 xij,wik,hkj≥0
通过最大化下式来找 W , H \bm W,\bm H W,H
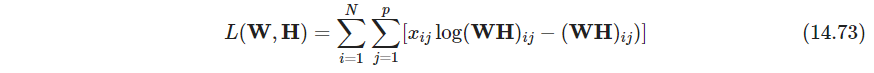
这是模型对数似然,其中 x i j x_{ij} xij服从均值为 ( W H ) i j (\bm W\bm H)_{ij} (WH)ij的泊松分布,这对于正数数据十分适合
(逻辑可能是这样的,先认为 X \bm X X中的每一个位置都服从一个隐含的泊松分布,但是不知道分布的参数,所以用最大似然把参数估计出来。参数有了之后,想找 X \bm X X的点估计,如果用均方误差,那么就用均值也即泊松分布的参数,当作 X \bm X X的估计值)(统计学习方法第2版给出了一个优化均方误差的写法)
优化过程可以通过迭代求解下式,使 L ( W , H ) L(\bm W, \bm H) L(W,H)收敛到局部最大值(Lee and Seung, 2001)
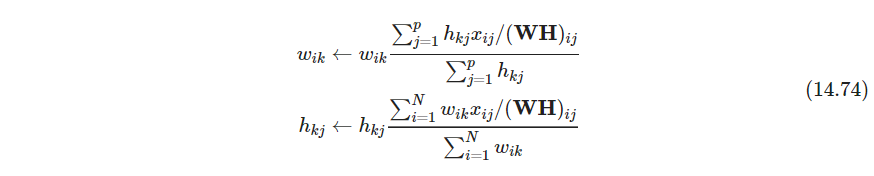
该算法可以由 L ( W , H ) L(\bm W,\bm H) L(W,H)的minorization过程导出(EM也是由这个过程导出,参考习题8.7和14.23,14.23太复杂了,我没有推) - P553 NMF的图像降维例子,和PCA、K-means的比较
- P554 Donoho and Stodden (2004)指出NMF的一个问题,即时 X = W H \bm X=\bm W\bm H X=WH严格成立,分解可能不唯一,看图14.34. 这表明上述算法得到的解依赖初始值,并似乎阻碍分解的解释性.尽管解释性方面的不足,非负矩阵分解及其应用依然很有吸引力
14.6.1 原型分析Archetypal Analysis
- P554 原型分析通过原型的线性组合来近似数据点,和K-means有相似之处。原型分析通过一系列原型的凸组合来近似每个数据点,这强制原型位于数据云的凸包convex hull上.
和NMF类似, X ∈ R N × p \bm X \in \mathbb R^{N\times p} X∈RN×p建模为
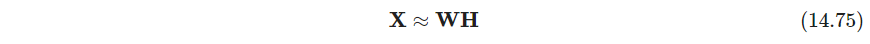
W ∈ R N × r , H ∈ R r × p , w i k ≥ 0 , ∑ k = 1 r w i k = 1 ∀ i \bm W\in \mathbb R^{N \times r},\ \bm H\in \mathbb R^{r\times p},\ w_{ik}\geq 0,\ \sum_{k=1}^r w_{ik}=1\ \forall i W∈RN×r, H∈Rr×p, wik≥0, ∑k=1rwik=1 ∀i,相当于 r r r个原型. 此外还假设
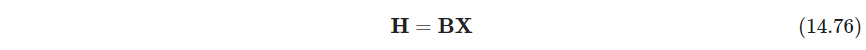
B ∈ R r × N , b k i ≥ 0 , ∑ i = 1 N b k i = 1 ∀ k \bm B\in \mathbb R^{r\times N},\ b_{ki}\geq 0,\ \sum_{i=1}^N b_{ki}=1\ \forall k B∈Rr×N, bki≥0, ∑i=1Nbki=1 ∀k,即原型是数据点本身的凸组合
优化目标为
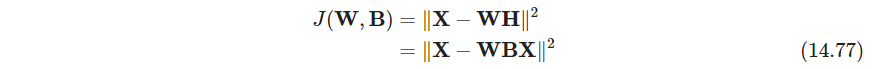
迭代优化,每一个参数自身是一步凸优化,但是联合非凸
(这和PCA的loss有几分像啊,也是一个重构的形式,这里优化 W B \bm W\bm B WB是不是相当于优化秩为 r r r的 N × N N\times N N×N矩阵,好像还不是,因为 W , B \bm W,\bm B W,B本身要求非负) - P556 Cutler and Breiman (1995)证明,需要在数据的凸包上定位原型(我估计这句话的意思是原型取到了凸包边界). K-means可看作原型分析的特例,当 W \bm W W限制为one-hot时
- P556 非负矩阵和原型分析的区别:
- 非负矩阵分解目的是近似数据矩阵 X \bm X X的列,并且主要感兴趣的是 W \bm W W的列,它表示了数据中主要的非负组分(总觉得这句话不合理,图14.33不是也关注的是 X \bm X X的一行嘛,我觉得具体关注的是 X \bm X X的行还是列,要看 X \bm X X的定义,如果是《统计学习方法》那样,那就是关注的列)
- 原型分析只要求 r ≤ N r \leq N r≤N,可以允许 r > p r > p r>p,式14.76使得即使 r > p r>p r>p也不能完美重构 X \bm X X(原型分析看起来就像是从数据集中找一个边数有限的最大的凸包,使均方误差最小)(感觉NMF像是降维方法,原型分析像是聚类方法。如果用原型分析做降维,感觉意义不大,像是一种带约束的PCA。不过从图14.36该方法能得到极端原型,而不是PCA那种特征向量)
14.7 独立成分分析Independent Component Analysis与探索投影追踪Exploratory Projection Pursuit
- P557 多元数据经常被看成是从未知的不能直接测量的来源多次间接测量的数据
14.7.1 隐变量与因子分析Factor Analysis
- P558 书中的SVD是这么写的,
X
=
U
D
V
T
\bm X=\bm U\bm D\bm V^T
X=UDVT,其中
X
,
U
∈
R
N
×
p
\bm X, \bm U\in \mathbb R^{N\times p}
X,U∈RN×p,
D
,
V
∈
R
p
×
p
\bm D,\bm V\in \mathbb R^{p\times p}
D,V∈Rp×p,如果
X
\bm X
X中心化过,即
1
1
×
N
X
=
0
1
×
p
\bm 1_{1\times N} \bm X=\bm 0_{1\times p}
11×NX=01×p,可得
1
1
×
N
U
=
0
1
×
p
\bm 1_{1\times N}\bm U=\bm 0_{1\times p}
11×NU=01×p,即PCA之后的坐标矩阵
U
\bm U
U也是中心化的.
记 S = N U \bm S=\sqrt N \bm U S=NU, A T = D V T / N \bm A^T=\bm D \bm V^T/\sqrt N AT=DVT/N,则 S \bm S S的列正交零均值,且有单位方差(难道说 U \bm U U的一列内方差为 1 / N 1/N 1/N?迷。可能SVD的版本不一样吧)(总之 X = S A T \bm X = \bm S\bm A^T X=SAT, S \bm S S是列正交,且可以看作PCA变换后的坐标),则 X = A S X=\bm A S X=AS,或写作
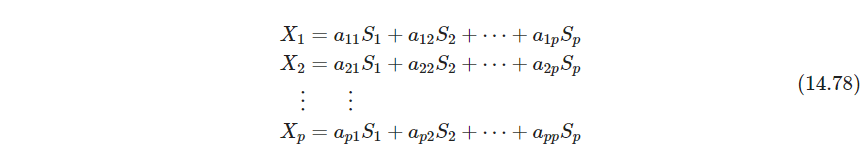
这样就把 X X X拆成了不相关的 S S S个独立变量来解释, A \bm A A是基的集合。不过这种表示不令人满意,因为可以施加旋转矩阵,得到新解(这里的逻辑应该是想找隐变量来解释 X X X,不过如果截断的话,就能选出最优了吧。不对,也选不出来, A \bm A A仍然可以在主成分的子空间里旋转)
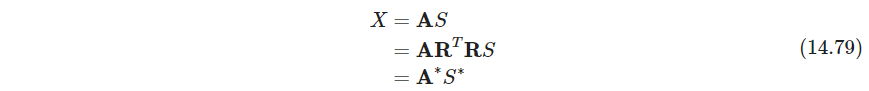
并满足 C o v ( S ∗ ) = R C o v ( S ) R T = I Cov(S^*)=\bm R Cov(S) \bm R^T=\bm I Cov(S∗)=RCov(S)RT=I - P559 因子分析的建模方式为
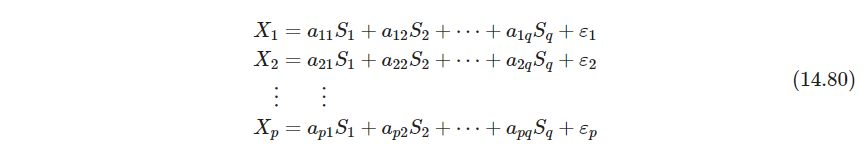
或写成 X = A S + ϵ X=\bm A S+\epsilon X=AS+ϵ,其中 A ∈ R p × q \bm A\in \mathbb R^{p\times q} A∈Rp×q, A \bm A A是因子载荷factor loadings的矩阵(关于载荷这个词《统计学习方法》也提到了,载荷指的是因子和观测之间的相关系数,也即观测能被因子解释多少。这里的 A i j A_{ij} Aij似乎是反映了 X i X_i Xi和 S j S_j Sj的相关性)
S l S_l Sl是 X j X_j Xj方差的公共来源,而 ϵ \epsilon ϵ则独立。 X X X的协方差矩阵为
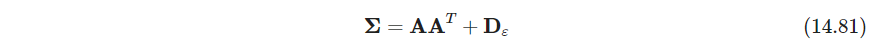
其中 D e p s i l o n \bm D_{epsilon} Depsilon对角, S j S_j Sj来自标准高斯(这和PRML,CVMLI写的是基本一致的), A \bm A A的列称为因子载荷,一列描述一个因子的作用
因子分析中,式14.79的唯一性问题仍然存在
如果所有的噪声方差一样,那么该问题的解仍然是SVD分解中的前 q q q个成分确定了 A A A张成的列空间(这应该就是概率PCA了,如果是因子分析本身,是用EM求解的) - P560 因为 X j X_j Xj是独立扰动的,(总的噪声一定是和坐标轴对齐的椭球,不能斜着)因子分析是对 X j X_j Xj的相关性结构进行建模,而非对协方差结构进行建模(PCA找最大协方差,因子分析找用剩下噪声拟合的最大似然),习题14.14表明因子分析实际上是对相关矩阵的分解(这一句话理解不好。这题为什么要标准化),习题14.15用实际例子说明因子分析与PCA的第一主成分完全不同(仔细想,其实能理解,因为因子分析只去拟合该题中的 X 3 X_3 X3,那么 X 1 , X 2 X_1,X_2 X1,X2就需要用两个很大方差的噪声来解释,而如果拟合了 X 1 , X 2 X_1, X_2 X1,X2方向,只需要在 X 3 X_3 X3一个方向上用噪声解释。但是如果 X 3 X_3 X3的方差足够大,应该还是会先拟合 X 3 X_3 X3方向)
14.7.2 独立成分分析Independent Component Analysisi
(ICA的目的不是降维,而是解混)
- P560 和14.78形式一样,不过假设 S i S_i Si独立代替不相关。直观上, 不相关确定了多元变量分布的二阶交叉矩,即协方差,而独立确定了所有的交叉矩,这些额外的矩条件唯一确定 A \bm A A,不过高斯分布是个特例,可能找出来的不唯一,因为高斯分布只要不相关就独立了。如果假设 S l S_l Sl独立,且非高斯,则能避免式14.78和14.80中的旋转唯一性问题
- P560 假定
X
\bm X
X已经白化whitened,
C
o
v
(
X
)
=
I
Cov(X)=\bm I
Cov(X)=I,可通过SVD实现。ICA即找
A
\bm A
A使
S
=
A
T
X
S=\bm A^T X
S=ATX独立且非高斯
ICA可以进行盲信号分离blind source separation - P561 ICA从熵出发。互信息mutual information
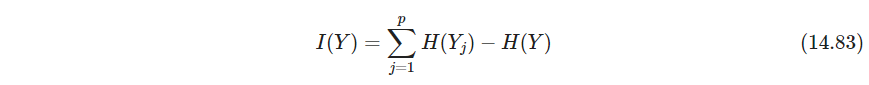
也就是 K L [ g ( Y ) ∥ ∏ j = 1 p g j ( y j ) ] KL[g(\bm Y)\|\prod_{j=1}^p g_j(y_j)] KL[g(Y)∥∏j=1pgj(yj)]. 如果 X X X有协方差 I \bm I I, Y = A T X Y=\bm A^T X Y=ATX其中 A \bm A A正交,则
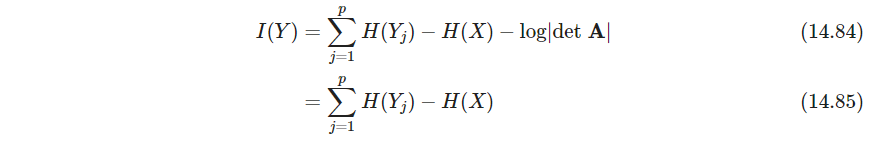
所以,最小化 I ( Y ) I(Y) I(Y)就是最小化各组分的熵和,也即最远离高斯分布(因为这里 Y i Y_i Yi的均值方差都知道了,熵最大是高斯分布)
为了方便,Hyvärinen and Oja (2000)采用负熵negentropy
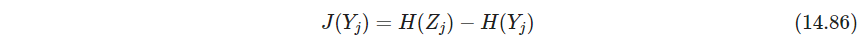
其中 Z j \bm Z_j Zj是与 Y j Y_j Yj同方差的高斯随机变量,负熵非负,度量 Y j Y_j Yj与高斯分布之间的距离,并提出了一个简单近似优化数据
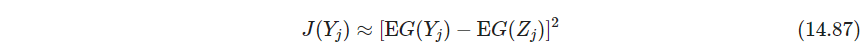
其中 G ( u ) = 1 a log cosh ( a u ) , 1 ≤ a ≤ 2 G(u)=\frac{1}{a} \log \cosh (au), 1\leq a \leq 2 G(u)=a1logcosh(au),1≤a≤2(这近似了高斯分布的log pdf?PRML公式12.90和这个似乎一致),实际应用时期望用平均值代替。R语言中这个方法叫FastICA。更经典但不鲁棒的度量是基于四阶矩峰度kurtosis,来衡量和高斯分布的距离
(P561 图14.37是只有两个样本在训练吗?不是的!可以看作是2个特征,正交变换矩阵是 2 × 2 2\times 2 2×2的,样本数量为采样数量,也就是列数,注意source signals中两个特征独立,正好对应ICA的假设,突然发现ICA真牛逼,所以这里行的时序信息其实没啥用)
(我的理解:如果真实分布是联合高斯,白化完之后,再怎么投影,正交的方向也一定独立。但是如果真实分布不是高斯,那么单个分量 Y i Y_i Yi也不一定是高斯,在最远离高斯的时候是最好的) - P562 ICA来寻找一系列的正交投影,使得投影数据尽可能远离高斯分布,采用白化后的数据,意味着寻找尽可能独立的成分. ICA从基础的因子分析出发,寻找一个旋转得到独立成分。从这一点上看,ICA仅仅是因子旋转的一种方式
(所以ICA本身似乎不降维,只是找独立分量) - P564 例子:手写数字。ICA看起来都是长尾分布,因为ICA降熵的操作特地寻找非高斯分布。(图14.39真能看出ICA更独立嘛)(ICA似乎对style disentangle有一定启发性啊)
- P564 例子:时序脑电图数据. 把脑电图的一堆时序电信号解开了,对每个独立成分进行解释
14.7.3 探索投影追踪exploratory projection pursuit
- P565 探索投影追踪是可视化高维数据的图像技巧。其观点是高维数据的一维或二维投影看起来是高斯分布的。通过非高斯投影,能得到有趣的长尾或聚簇的分布(这里想表达的应该是,通过一些特殊的投影,但仍是线性投影)。他们提出一系列投影指标projection indices来优化,每个都关注与高斯分布的不同的偏离。随后又发展出了各种指标包括熵。这些指标与ICA中的
J
(
Y
i
)
J(Y_i)
J(Yi)一致,其中
Y
j
=
a
j
T
X
Y_j=a_j^T X
Yj=ajTX。
实际上,交叉熵的一些近似和替代与投影寻踪中提出的指标重合(为什么要代替交叉熵?用在哪里的交叉熵?)
一般投影追踪问题中, a j a_j aj不需要正交限制(不清楚这里的投影追踪和11章的投影追踪回归有什么联系)
14.7.4 独立成分分析的一种直接方法
- P567 R语言中这个方法叫ProDenICA,用广义加性模型GAM去估计独立成分分析的密度
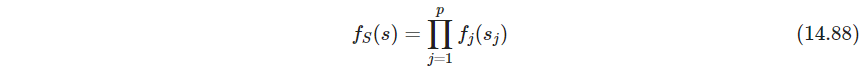
受距离高斯分布的启发,将每个分量写成
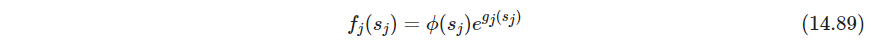
这是倾斜的高斯分布tilted gaussian density,其中 ϕ \phi ϕ是标准高斯, g j g_j gj则满足密度函数的标准化条件. 假定 X X X已经白化,对数似然为
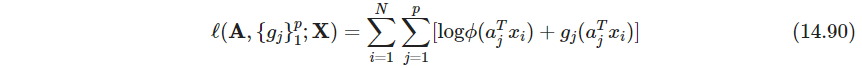
该式中 g j g_j gj过参数化了,所以优化一个带正则版本
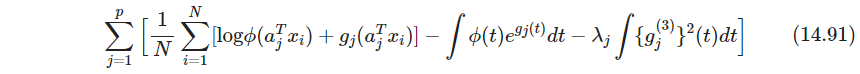
第一项约束了概率密度函数 ∫ ϕ ( t ) e g ^ j ( t ) d t = 1 \int \phi(t)e^{\hat g_j(t)}dt=1 ∫ϕ(t)eg^j(t)dt=1,第二项保证了 g ^ j \hat g_j g^j是结点在观测值 s i j = a j T x i s_{ij}=a^T_j x_i sij=ajTxi的四次样条(关于第一条可以参考ESL CN的注。虽然我还是感觉他证的很不严谨)。习题14.18说明每一维解 f ^ j = ϕ e g ^ j \hat f_j = \phi e^{\hat g_j} f^j=ϕeg^j有0均值1方差。其中 λ j \lambda_j λj越大,越接近高斯 ϕ \phi ϕ
(这里的逻辑应该是先假定线性投影之后的 a j T X a_j^T X ajTX服从倾斜的高斯分布,然后去优化 a j a_j aj和 g j g_j gj. 这样的分布远离高斯,所以熵小,所以独立性很好。严格来说,可能是,当数据 X X X分布已知,投影后各维方差已知,在这种条件下,各维度熵和越小,越独立) - P567 算法14.3指出
A
\bm A
A和
g
j
g_j
gj交替迭代优化。
- 优化
g
j
g_j
gj时是一个半参数密度估计semi-parametric density estimation,,可以用GAM优化,以一个维度为例
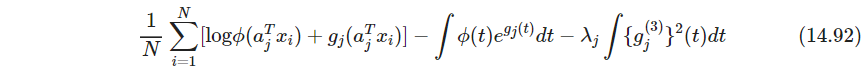
上式第二项的概率密度积分不好处理,需要近似,构造 L L L个值维 s l ∗ s_l^* sl∗的细网络,这些值间距为 Δ \Delta Δ,覆盖观测 s i s_i si的取值范围,并且统计得到小块个数
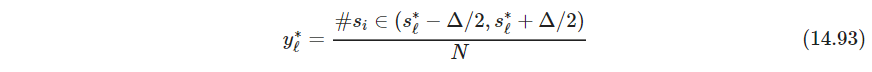
一般取 L = 1000 L=1000 L=1000足够,接着用下式得到近似
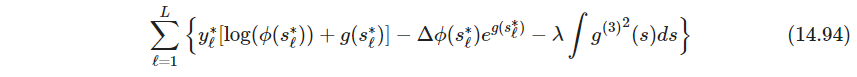
这式子可以看作正比于带惩罚的泊松分布对数似然,其中响应变量为 y l ∗ / Δ y_l^*/\Delta yl∗/Δ,惩罚参数为 λ / Δ \lambda/\Delta λ/Δ,泊松分布的均值为 μ ( s ) = ϕ ( s ) e g ( s ) \mu(s)=\phi(s)e^{g(s)} μ(s)=ϕ(s)eg(s)(但是这里均值也和 l l l有关啊,真的一样吗)
这是一个广义加性样条模型generalized additive spline model,其中offset项为 log ϕ ( s ) \log \phi(s) logϕ(s),可以以 O ( L ) \mathcal O(L) O(L)的复杂度用牛顿法拟合。尽管要求四次样条,但是实际中我们发现三次样条就足够了,此外令 p p p个 λ i \lambda_i λi相等,通过有效自由度 d f ( λ ) df(\lambda) df(λ)来确定光滑程度(这一块省略很多细节,理解不好) - 优化
A
\bm A
A时,
g
^
j
\hat g_j
g^j不变,只有第一项受影响,因为
A
\bm A
A正交,所以涉及
ϕ
\phi
ϕ的所有项的集合不受
A
\bm A
A影响,见习题14.19. 所以只需最大化
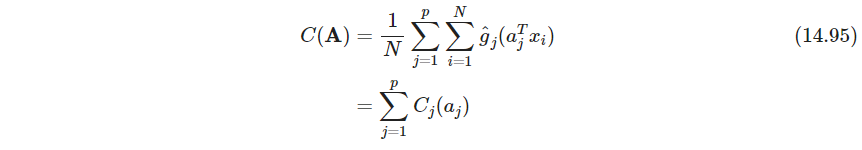
C ( A ) C(\bm A) C(A)是拟合密度与高斯密度的似然比的对数之和,可以看作是负熵14.86的一个估计(这里是不是太凭感觉了,毕竟 g g g有正有负,不过也有可能求和真就只能为正,待思考)。采用修改后的拟牛顿法得到固定点更新fixed point update,参考习题14.20,对每个 j j j进行如下更新
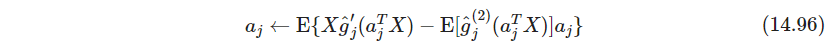
其中 E E E是关于 x i x_i xi的期望,
(这和11.1节P390投影追踪回归的求解有没有相似之处)
因为 A \bm A A要正交,所以采用对称平方根变换symmetric square-root transformation,得到 ( A A T ) − 1 / 2 A (\bm A\bm A^T)^{-1/2}\bm A (AAT)−1/2A,根据SVD分解 A = U D V \bm A=\bm U\bm D\bm V A=UDV。易得 A ← U V T \bm A \leftarrow \bm U\bm V^T A←UVT
- 优化
g
j
g_j
gj时是一个半参数密度估计semi-parametric density estimation,,可以用GAM优化,以一个维度为例
- P569 例子:模拟。比较ProDenICA、FastICA和另一个半参方法KernelICA
- P569 矩阵的条件数condition number
- P570 Amari距离度量两个矩阵相似程度
14.8 多维缩放Multidimensional Scaling
- P570 SOM、主曲线、表面这些方法需要数据点,多维缩放不需要,只需要不相似矩阵(K-medoid也不需要,但注意K-medoid是聚类的,不是降维的)
- P570 多维缩放寻找
z
1
,
z
2
,
…
,
z
N
∈
R
k
z_1, z_2, \dots, z_N\in \mathbb R^k
z1,z2,…,zN∈Rk,最小化应力函数streess function
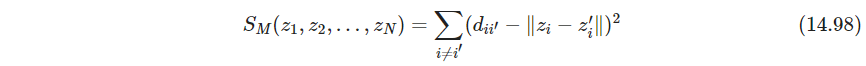
有些作者将压力定义为 S M S_M SM平方根;因为不影响优化,所以本书保留平方,以便跟其它准则进行比较
这称为最小二乘缩放least squares scaling或Kruskal-Shephard缩放
注意到近似是对距离而言,而不是平方距离,这会导致计算有点复杂。可用梯度下降优化 S M S_M SM - P571 最小二乘缩放的一个变种Sammon mapping,最小化
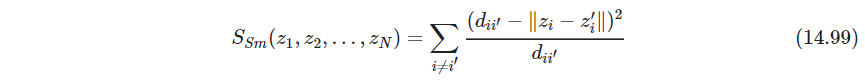
- P571 在经典缩放classical scaling中,我们从相似性开始,用中心化的内积作为相似性
s
i
i
′
=
⟨
x
i
−
x
ˉ
,
x
i
′
−
x
ˉ
⟩
s_{ii'}=\left \langle x_i-\bar x, x_{i'}-\bar x \right \rangle
sii′=⟨xi−xˉ,xi′−xˉ⟩,最小化下式
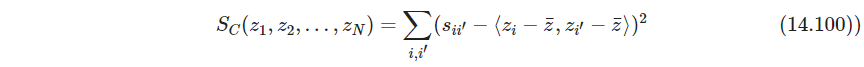
该式有用特征向量表示的显式解,见习题14.11(这题的证明可以用Eckart-Young定理。另外这种找最近似Gram矩阵的方法,也可参考西瓜书P228). 如果我们有距离数据,而不是内积数据,并且是欧式距离,则可以将它们转换为中心化的内积. (西瓜书也有),参考式18.31
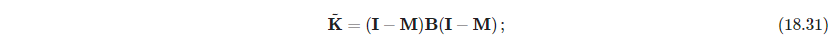
如果相似性为中心化的内积,则经典缩放正好与主成分等价(不过两个一个是在协方差矩阵找特征值,一个是在内积矩阵找特征值,注意Sylvester定理表明两个矩阵特征值一样)
经典缩放不等价于最小二乘缩放;它们的损失函数不同,并且映射可以是非线性的. - P571 最小二乘缩放和经典缩放都被称作度量缩放方法metric scaling methods,通过近似实际的相似性或非相似性。
而Shephard-Kruskal非度量缩放只用秩,非度量缩放在 z i z_i zi和任意递增函数 θ \theta θ上最小化应力函数
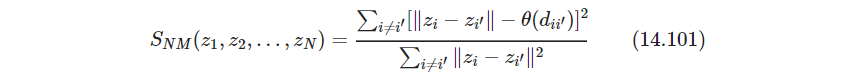
θ \theta θ固定时,通过梯度下降最小化KaTeX parse error: Undefined control sequence: \z at position 1: \̲z̲_i; z i z_i zi固定时,保序回归isotonic regressino来寻找对 ∥ z i − z i ′ ∥ \|z_i-z_{i'}\| ∥zi−zi′∥的最好单调近似 θ ( d i i ′ ) \theta(d_{ii'}) θ(dii′). 两步不断迭代。(这 θ \theta θ也要优化就很神奇) - P572 在主曲面和SOM中,原特征空间距离远的点也可能映射到一起,(我怎么觉得是原特征空间近的点也可能映射的比较远?比如SOM那个红点例子。哦他的想法可能是因为降维了,原先某些方向离得远,现在体现不出来了)MDS中则不大可能,因为明确保持所有成对距离
14.9 非线性降维Nonlinear Dimension Reduction和局部多维缩放Local Multidimensional Scaling
- P572 本节的非线性降维类似主曲面的思想,把数据看成固有低维非线性流行,在信噪比非常高的问题中有用,而对信噪比低的数据不太有用。本节给出三种局部多维缩放方法,在不知道流形信息的情况下
- P573 等度量映射Isometric Mapping, ISOMAP,测地线距离geodesic distance
- P573 局部线性嵌入Local linear embedding, LLE.
第一步:对每个 p p p维数据点 x i x_i xi,找欧式距离的K近邻点集 N ( i ) \mathcal N(i) N(i)。
第二步:对每个点用邻近点的仿射混合来近似
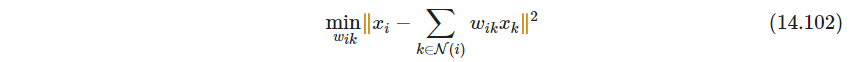
其中 w i k = 0 , k ∉ N ( i ) , ∑ k = 1 N w i k = 1 w_{ik}=0,k\notin \mathcal N(i),\ \sum_{k=1}^N w_{ik}=1 wik=0,k∈/N(i), ∑k=1Nwik=1. 为了得到唯一解,必须要求 K < p K < p K<p(等于是不是也可以)
第三步:固定 w i k w_{ik} wik,在 d < p d<p d<p维空间中找 y i y_i yi,最小化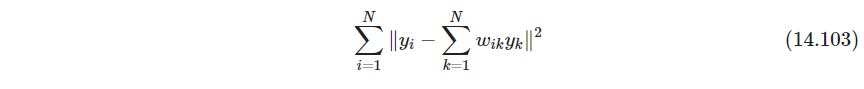
即
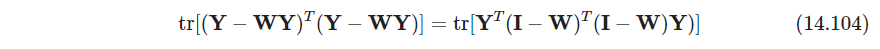
s.t. Y T Y = I d 否则会有 Y = 0 \text{s.t.}\quad \bm Y^T\bm Y=\bm I_d\qquad \text{ 否则会有}\bm Y=\bm 0 s.t.YTY=Id 否则会有Y=0
其中 W ∈ R N × N , Y ∈ R N × d , d < p \bm W\in \mathbb R^{N\times N},\bm Y \in \mathbb R^{N\times d}, \ d<p W∈RN×N,Y∈RN×d, d<p
(PRML和西瓜书都有关于LLE特性上的很多直觉描述)
Y ^ \hat\bm Y Y^的解为 M = ( I − W ) T ( I − W ) \bm M=(I-\bm W)^T(\bm I-\bm W) M=(I−W)T(I−W)的尾特征向量,注意到 1 d \bm 1_d 1d是平凡特征向量,对应 0 0 0特征值,所以丢弃,留下剩下 d d d个最小的,这导致 1 N T Y = 0 \bm 1_N ^T \bm Y=0 1NTY=0,所以嵌入坐标的均值为0 - P574 局部多维缩放Local MDS,采用最简单最直接的方式。定义
N
\mathcal N
N为邻居点的对称集,即如果
i
i
i在
i
′
i'
i′的K近邻或过来,则
(
i
,
i
′
)
∈
N
(i,i')\in \mathcal N
(i,i′)∈N中(谱聚类中也是这么用的)
构造应力函数
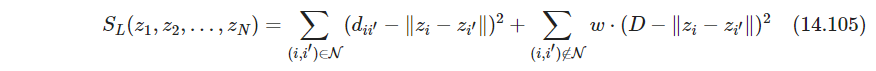
其中 D D D是某个大常数, w w w是权重,想法是让不是邻居的点对离得非常远. w w w不应太大,取 w ∼ 1 / D w\sim 1/D w∼1/D,并令 D → ∞ D\to \infty D→∞,得到
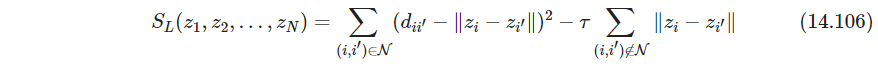
其中 τ = 2 w D \tau=2wD τ=2wD(这里把 w ∥ z i − z i ′ ∥ 2 w\|z_i-z_{i'}\|^2 w∥zi−zi′∥2消掉了,估计是考虑到 ∥ z i − z i ′ ∥ 2 \|z_i -z_{i'}\|^2 ∥zi−zi′∥2不会趋于无穷,从优化角度看,这一项权重非常低,不起作用. 这么做的意思就是 ∥ z i − z i ′ ∥ \|z_i-z_{i'}\| ∥zi−zi′∥越大越好,好像也说得过去)
局部多维缩放在固定 K K K,调整 τ \tau τ的情况下,在 z i z_i zi上最小化应力函数(所以 τ \tau τ还是会调整的,并不是 w = 1 / D w=1/D w=1/D,而是 w ∼ 1 / D w\sim 1/D w∼1/D
图14.44采用了 τ = 0.01 \tau=0.01 τ=0.01,采用多个起始值的坐标下降coordinate descent来寻找非凸损失函数的最小值.沿曲线的点的顺序大部分都被保持
(这里不相邻的结点之间能不能不施加约束,好像不能,否则会本应远离的点重叠在一起) - P576 谱聚类、核主成分,与本节描述方法有紧密联系
14.10 谷歌PageRank算法
- P576 假设有
N
N
N个网页,并且希望对它们进行重要性排序,例如都匹配到字符串
statistical learning,希望按照对浏览者的可能相关程度进行排序,PageRank考虑如果有很多其他的页面指向一个页面,则该页面重要。算法考虑链接页面的重要性PageRank,以及向外链接的个数.高PageRank值的网页被赋予更大权重,而有更多的向外链接outlinks的页面则赋予较小的权重. - P577 如果页面
j
j
j指向
j
j
j,则
L
i
j
=
1
L_{ij}=1
Lij=1,否则为0. 令向外链接数
c
j
=
∑
i
=
1
N
L
i
j
c_j=\sum_{i=1}^N L_{ij}
cj=∑i=1NLij,则PageRank值
p
i
p_i
pi递归定义为
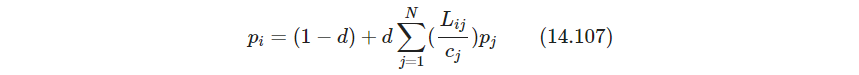
其中 d d d是正常数,设为0.85,保证每个页面至少有 1 − d 1-d 1−d的PageRank值. 写成矩阵为
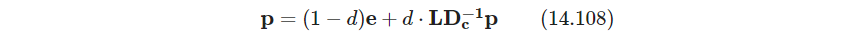
e \bm e e是全1列向量, D c = d i a g ( c ) \bm D_c=diag(\bm c) Dc=diag(c),引入标准化 e T p = N \bm e^T \bm p=N eTp=N(式14.108两边左乘 e T \bm e^T eT,得到 e T p n e x t : = ( 1 − d ) N + d e T p = N \bm e^T\bm p^{next}:=(1-d)N+d\bm e^T\bm p=N eTpnext:=(1−d)N+deTp=N,可证 e T p = N \bm e^T \bm p=N eTp=N是数列的收敛极限),从而
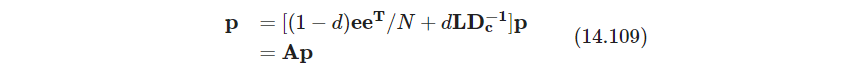
A \bm A A是马尔科夫矩阵,从而1是最大的实特征值,可用幂法power method求 p ^ \hat \bm p p^,初始值为 p 0 \bm p_0 p0,进行迭代(注意这里 p p p求和是 N N N,不是概率分布)
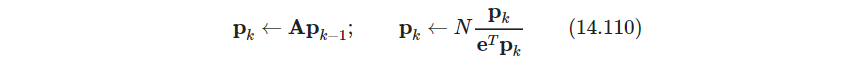
在Page et. al(1998)的原始论文中,作者将PageRank考虑成用户行为的模型,用户随机点击页面,而不去考虑内容.用户在网络上随机游走,随机选择向外链接.因子 1 − d 1−d 1−d是跳到随即页面的概率. 有些PageRank的描述将 ( 1 − d ) / N (1-d)/N (1−d)/N为式14.107中的第一项,这更符合随机浏览的解释,此时pagerank的解是不可约的irreducible、非周期的aperiodic马尔可夫链的在 N N N个网页上的平稳分布(这才是概率分布。注意此时算出来 A \bm A A不变,特征值1的特征向量会成比例缩小 N N N倍)
因为 A \bm A A元素都为正,列和为1,所以特征值为1的特征向量唯一
参考文献:
[1] Trevor Hastie, Robert Tibshirani, Jerome Friedman. The Elements of Statistical Learning, Second Edition
[2] ESL CN


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









