







 本文详细介绍了哈夫曼树的概念,如何通过哈夫曼算法计算带权路径长度,给出了Java代码示例,并通过实例解析了算法步骤。
本文详细介绍了哈夫曼树的概念,如何通过哈夫曼算法计算带权路径长度,给出了Java代码示例,并通过实例解析了算法步骤。
目录
一、概念
1.1 说明
-
1.最优二叉树又称为哈夫曼树,是一类带权路径长度最短的树。
-
2.路径是从树中一个结点到另一个结点之间的通路,路径上的分支数目称为路径长度。
-
3.树的路径长度是从树根到每一个叶子之间的路径长度之和。
-
4.结点的带权路径长度为从该结点到树根之间的路径长度与该结点权值的乘积。
-
5.树的带权路径长度为树中所有叶子结点的带权路径长度之和,记作
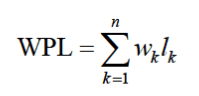
-
6.n为带权叶子结点数目,wk为叶子结点的权值,lk为叶子结点到根的路径长度。
-
7.哈夫曼树是指权值为w1,w2,…,wn的n个叶子结点的二叉树中带权路径长度最小的二叉树。
1.2 二叉树带权路径长度计算
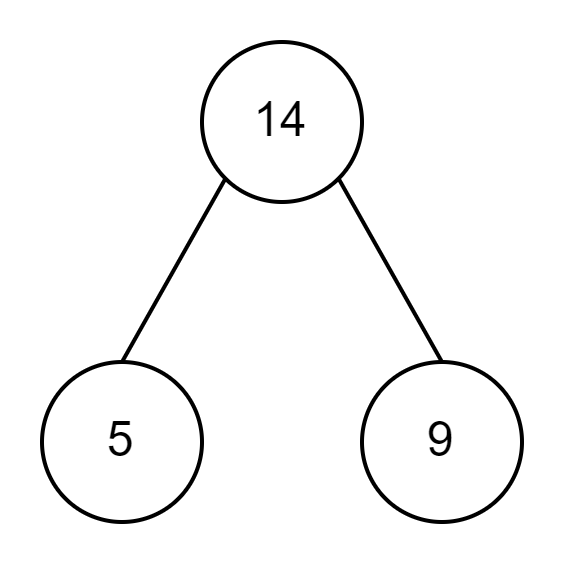
1.2.1 示例1
- 1.二叉树图示

- 2.树的所有叶结点的带权路径长度之和WPL的计算为:2、4、5、7均是叶子结点,到根的路径长度均为2,因此WPL=2×(2+4+5+7)=36
1.2.2 示例2
-
1.二叉树图示

-
2.结点7到根的路径长度为1,结点5到根的路径长度为2,结点2和结点4到根的路径长度为3,因此WPL=7+5×2+(2+4)×3=35
1.2.3 示例3
- 1.二叉树图示

- 2.结点2到根的路径长度为1,结点7到根的路径长度为2,结点4和结点5到根的路径长度为3,因此WPL=2+7×2+(4+5)×3=43
二、哈夫曼算法
2.1 算法过程
- 1.根据给定的n个权值{w1,w2,…wn},构成n棵二叉树的集合F={T1,T2,…Tn},每棵树Ti中只有一个带权为wi的根结点,其左、右子树均空。
- 2.在F中选取两棵权值最小的树作为左、右子树构造一棵新的二叉树,置新构造二叉树的根结点的权值为其左、右子树根结点的权值之和。
- 3.从F中删除这两棵树,同时将新得到的二叉树加入到F中。
- 4.重复第2点和第3点,直到F中只含一棵树时为止,这棵树便是最优二叉树(哈夫曼树)。
- 5.以选中的两棵子树构成新的二叉树,并没有明确哪个作为左子树,哪个作为右子树。具有n个叶子结点的权值为w1,w2,…wn的最优二叉树不唯一,但其WPL值是唯一确定。
- 6.当给定了n个权值后,构造出的最优二叉树中的结点数目m就确定了,即m=2×n-1。
2.2 java实现
2.2.1 代码示例
package com.learning.algorithm.tree.huffman;
import java.util.Objects;
public class HuffmanNode implements Comparable<HuffmanNode>{
char data;
int weight;
HuffmanNode left;
HuffmanNode right;
public HuffmanNode(char data, int weight) {
this.data = data;
this.weight = weight;
}
@Override
public int compareTo(HuffmanNode o) {
return this.weight - o.weight;
}
@Override
public boolean equals(Object o) {
if (this == o){
return true;
}
if (o == null || getClass() != o.getClass()){
return false;
}
HuffmanNode that = (HuffmanNode) o;
return data == that.data &&
weight == that.weight &&
Objects.equals(left, that.left) &&
Objects.equals(right, that.right);
}
@Override
public int hashCode() {
return Objects.hash(data, weight, left, right);
}
}
package com.learning.algorithm.tree.huffman;
import java.util.PriorityQueue;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
import java.util.HashMap;
public class HuffmanTree {
// 构建哈夫曼树
public HuffmanNode buildHuffmanTree(Map<Character, Integer> freqMap) {
PriorityQueue<HuffmanNode> priorityQueue = new PriorityQueue<>();
// 将频率放入优先队列
for (Map.Entry<Character, Integer> entry : freqMap.entrySet()) {
priorityQueue.add(new HuffmanNode(entry.getKey(), entry.getValue()));
}
// 构建哈夫曼树
while (priorityQueue.size() > 1) {
HuffmanNode x = priorityQueue.poll();
HuffmanNode y = priorityQueue.poll();
HuffmanNode sum = new HuffmanNode('$', x.weight + y.weight);
sum.left = x;
sum.right = y;
priorityQueue.add(sum);
}
return priorityQueue.poll(); // 返回根节点
}
// 生成哈夫曼编码
public Map<Character, String> generateCodes(HuffmanNode root, String code, Map<Character, String> huffmanCodes) {
if (root == null) {
return huffmanCodes;
}
if (root.data != '$') {
huffmanCodes.put(root.data, code);
}
generateCodes(root.left, code + "0", huffmanCodes);
generateCodes(root.right, code + "1", huffmanCodes);
return huffmanCodes;
}
// 示例方法:从字符频率映射构建哈夫曼树并生成哈夫曼编码
public Map<Character, String> buildHuffmanCodes(Map<Character, Integer> freqMap) {
HuffmanNode root = buildHuffmanTree(freqMap);
Map<Character, String> huffmanCodes = new HashMap<>();
generateCodes(root, "", huffmanCodes);
return huffmanCodes;
}
public static void main(String[] args) {
HuffmanTree huffmanTree = new HuffmanTree();
Map<Character, Integer> freqMap = new HashMap<>();
freqMap.put('a', 5);
freqMap.put('b', 9);
freqMap.put('c', 12);
freqMap.put('d', 13);
freqMap.put('e', 16);
freqMap.put('f', 45);
Map<Character, String> huffmanCodes = huffmanTree.buildHuffmanCodes(freqMap);
for (Map.Entry<Character, String> entry : huffmanCodes.entrySet()) {
System.out.println(entry.getKey() + ": " + entry.getValue());
}
}
}
2.2.2 代码说明
- 1.哈夫曼树结点自定义了比较方法,即按权值的大小进行排序。
- 2.将哈夫曼树结点都放入优先队列PriorityQueue
- 3.当优先队列中还有元素,poll出2个树结点,该队列保证poll出来的元素是最小的。
- 4.将两个权重最小的树结点重新构建一个新的树结点,并使新的树结点的左右结点指向刚poll出的两个树结点。
- 5.将新的树结点再次添加到优先队列中。
- 6.再从优先队列中poll两个元素,这两个元素会是权值最小的两个,重复操作,直到优先队列中只有最后一个元素为止(所有的权重都加完了)
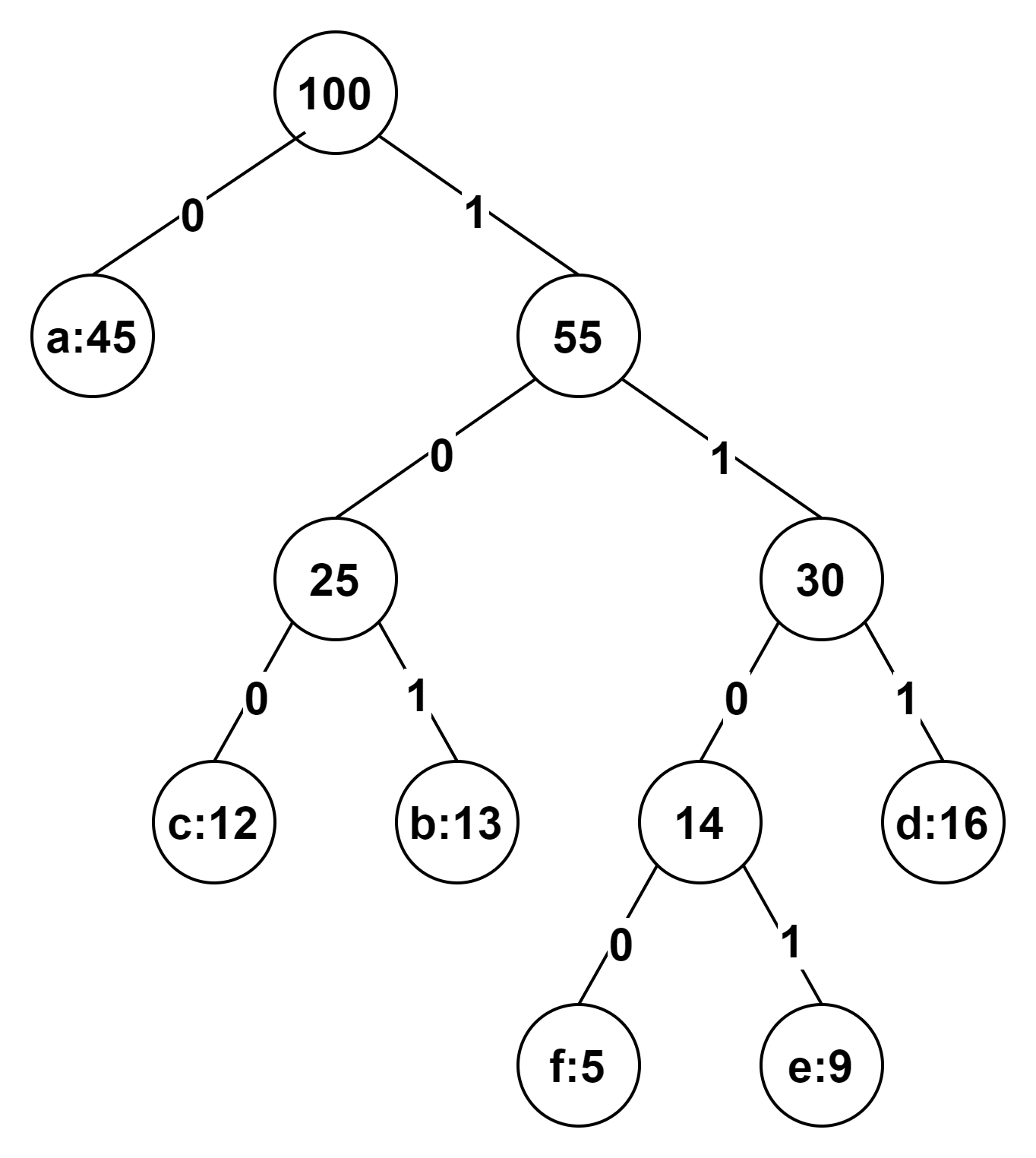
2.2.3 举例说明
- 1.例如权值为5,9,12,13,16,45的结点,将结点都放入优先队列q。此时q的长度为6。
- 2.优先队列长度大于1,取最小权值5结点和最小权值9结点。
- 3.将两个结点权值相加即为14,构造新的结点14,将5结点作为新结点的左结点,将9结点作为新结点的右结点(左右结点可以随意),放入优先队列q。优先队列q中此时有12,13,16,45,14,q的长度为5。
- 4.优先队列长度大于1,取最小权值12结点和最小权值13结点。
- 5.将两个结点权值相加即为25,构造新的结点25,将12结点作为新结点的左结点,将13结点作为新结点的右结点(左右结点可以随意),放入优先队列q。优先队列q中此时有16,45,14,25,q的长度为4。
- 6.优先队列长度大于1,取最小权值14结点和最小权值16结点。
- 7.将两个结点权值相加即为30,构造新的结点30,将14结点作为新结点的左结点,将16结点作为新结点的右结点(左右结点可以随意),放入优先队列q。优先队列q中此时有45,25,30,q的长度为3。
- 8.优先队列长度大于1,取最小权值25结点和最小权值30结点。
- 9.将两个结点权值相加即为55,构造新的结点55,将25结点作为新结点的左结点,将30结点作为新结点的右结点(左右结点可以随意),放入优先队列q。优先队列q中此时有45,55,q的长度为2。
- 10.优先队列长度大于1,取最小权值45结点和最小权值55结点。
- 9.将两个结点权值相加即为100,构造新的结点100,将45结点作为新结点的左结点,将55结点作为新结点的右结点(左右结点可以随意),放入优先队列q。优先队列q中此时有100,q的长度为1。
- 11.优先队列长度等于1,结束循环,此时结点100就是根结点。
2.2.4 图示
- 1.第一步
- 2.第二步

- 3.第三步

- 4.第四步

- 5.第五步

三、例题
3.1 例题1
- 1.题目
1.由权值为 29、12、15、6、23 的五个叶子结点构造的哈夫曼树为(A),其带权路径长度为(B)。
A.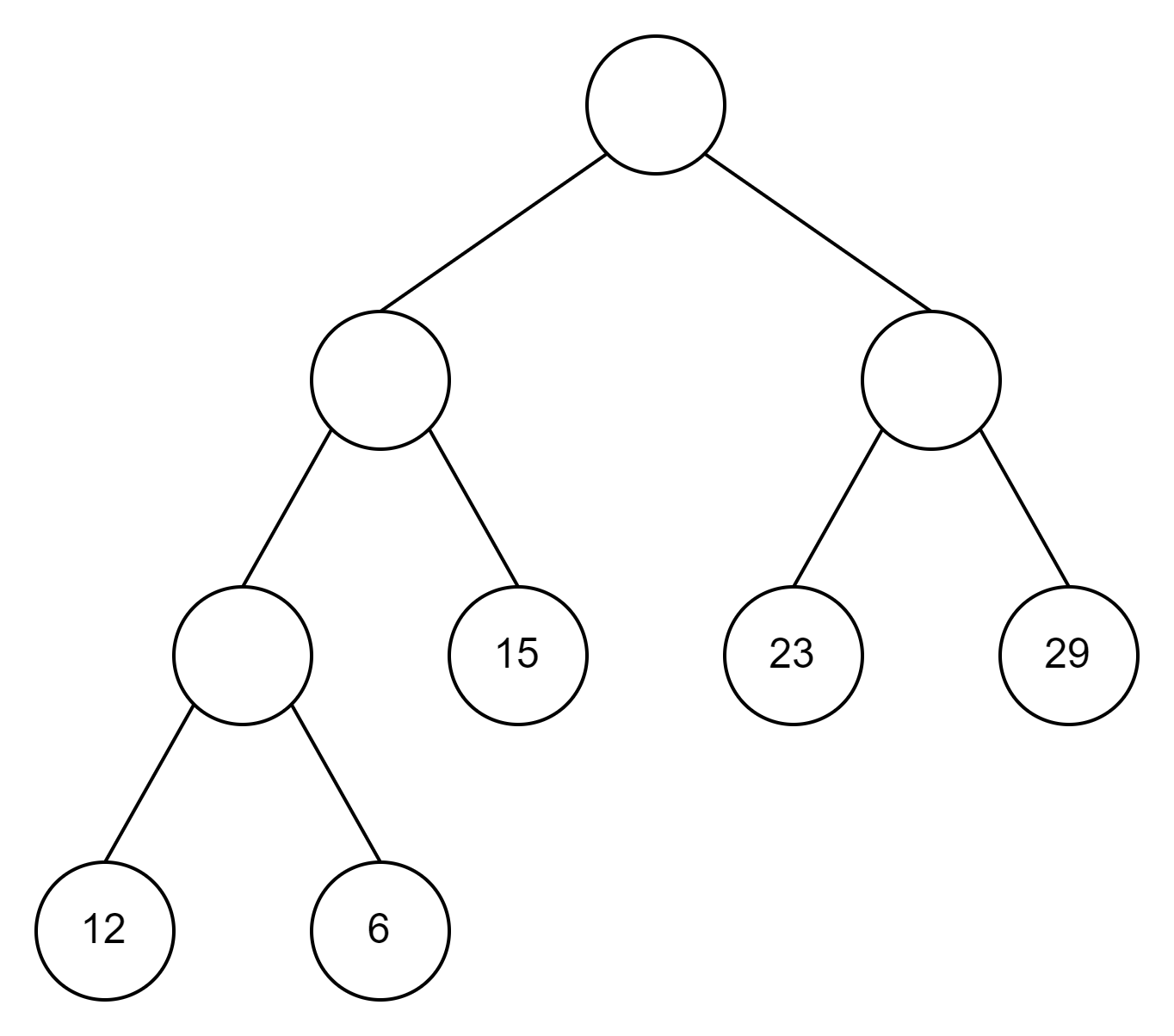
B.
C.
D.
A.85
B.188
C.192
D.222
- 2.解析
1.取最小权值的两个结点12和6,两者加起来是18,即29,15,23,18
2.取最小权值的两个结点15和18,两者加起来是33,即29,23,33
3.取最小权值的两个结点23和29,两者加起来是52,即33,52
4.取最小权值的两个结点33和52,两者加起来是85,所以答案是A
带权路径长度为:结点12和结点6距离根结点的路径长度为3,
结点15、结点23和结点29距离根结点的路径长度为2,
因此WPL=(12+6)×3+(15+23+29)×2=188,所以答案为B
3.2 例题2
- 1.题目
2.已知一个文件中出现的各字符及其对应的频率如下表所示。若采用定长编码,则该文件中字符的码长应为()。若采用Hufiman编码,则字符序列“face”的编码应为()
A.2
B.3
C.4
D.5
A.110001001101
B.001110110011
C.101000010100
D.010111101011

- 2.解析
1.字符在计算机中是用二进制表示的,每个字符用不同的二进制编码来表示。
2.码的长度影响存储空间和传输效率。
3.若是定长编码方法,用2位码长,只能表示4个字符,即00、01、10 和 11。
4.若用3位码长,则可以表示8个字符,即 000、001、010、011、100、101、110、111。
5.题目中一共有6 个字符,因此采用3位码长的编码可以表示这些字符。因此答案为B
6.Huffman编码是一种最优的不定长编码方法,可以有效的压缩数据。
7.要使用 Hufman编码,除了知道文件中出现的字符之外,还需要知道每个字符出现的频率。
8.如果某个字符出现的频率比较高,应该用最少的编码来表示。
9.f为:1100,a为0,c为100,e为1101,因此答案为A
















 7928
7928











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











