





【论文阅读】利用论文内容和用户行为对论文进行个性化重排名
XINYI LI and YIFAN CHEN, University of Amsterdam, The Netherlands and National University of Defense Technology, China
BENJAMIN PETTIT, Elsevier, United Kingdom
MAARTEN DE RIJKE, University of Amsterdam, The Netherlands
Abstract
在本文中,研究了一个学术论文推荐系统,它根据用户在学术搜索引擎上的浏览历史,在电子邮件通讯中发送论文推荐给用户。
挑战:我们关注的用户以前没有与推荐系统进行过交互,这是每个推荐系统在新用户注册时都会遇到的常见情况。
方法:提出了一种利用论文内容和用户行为对候选推荐进行重新排序的方法。由于我们关注的用户没有预先与推荐系统进行交互,我们提出了一个模型来学习从用户浏览的文章(users’ browsed articles)到用户点击推荐文章(user clicks on the recommendations.)的一个映射。
Introduction
各种在线学术服务提供商允许用户通过其搜索引擎访问论文,如谷歌学术[20]、Aminer[66]和ScienceDirect[59],用户可以在这些搜索引擎中输入查询,在数据库中查找相关论文。
虽然这类学术搜索引擎通常可以满足用户的要求,通过满足特定的信息需求表示为查询,但也有用户的信息需求没有明确指定的情况。
在这种情况下,论文推荐系统可以介入并推荐相关论文,而不需要用户进行查询。论文推荐系统的作用是对搜索引擎进行补充。基于推荐时机,可能的推荐场景分为三类:
- 在用户开始一个新的搜索会话之前,根据他们的论文库或以前访问过的论文显示论文推荐
- 在搜索过程中,在用户当前浏览的内容旁边显示相关推荐
- 搜索环节结束后,以新闻信函的形式发送推荐论文的电子邮件给用户
在本文中,关注第三种情况。
Contribution
- 学术设置的“任务转移(task transfer)”:一个任务收集到的数据(搜索)用于帮助优化另一个任务的性能(推荐)
- 如何结合内容和用户行为生成高质量的学术推荐
- 该框架捕获了用户对不同论文方面的兴趣,并缓解了点击数据的稀疏性问题,该框架依赖于两种输入:论文属性(paper properties)和用户交互(user interactions)。
Model
Production Baseline
在本研究中,我们将重新排序模型(reranking model)应用于生产系统(production system)中排名前五的候选对象,并将该模型的排名与生产基准进行比较。之所以选择前五名的候选人,是因为对于这些推荐,电子邮件点击反馈可以进行离线评估;如果成功,该模型可以应用于更长的候选列表。
(production system:将用户的论文浏览历史作为输入,并生成一个列有5条论文建议的列表。)
Proposed Model
- Model architecture overview :混合重新链接模型(HRM)的体系结构,它显示了如何为用户的候选论文推荐评分。

其中Srecent和Shistory是推荐候选者和用户浏览的论文之间的相似性。它们分别通过将候选论文与最近论文和历史论文进行比较,得出每个论文方面的平均相似度分数。然后使用与浏览历史中的论文相比较的每个论文推荐候选的平均和最大相似度分数。以及根据用户的行为特征描述的行为模型所得出的预测点击得分。这些特性共同决定了混合重新链接模型(HRM)的输入。
训练是通过对每个用户u的被点击文件Ru+与未点击文件Ru-的偏好进行合叶损失函数的优化来完成的,具体如下:

- Paper Representations 每一篇论文p都可以用如下一些变量的集合来表示:
| 论文元数据 | 公式表示 |
|---|---|
| 作者A | A( p ) = [ a1, a2 ,…, an], |
| 地点V | V( p ) = vi |
| 新鲜度F |  |
| 词空间W | W( p ) ,使用tf-idf向量 |
| 实体空间E | E( p ),提供额外的信息,类似W( p ) |
| 用户交互元数据 | 公式表示 |
| 影响因子E |  |
| 流行指数P |  |
根据以上表格内容,每篇论文可表示为 p = ⟨ A( p ),V( p ),F( p ),W( p ),E( p ),I( p ),P( p ) ⟩:
我们首先利用论文的关键字、作者和地点等重要方面来构建知识图,然后,我们使用TransE模型[3]来推导基于知识图的嵌入,模型以图中的三个一组作为输入;它们的形式是( h, r, t ),有一个头实体 h,一个关系(谓词) r,和一个尾实体 t。模型通过最小化合叶损失函数来学习嵌入:
 其中 T 表示三元组的训练集。
其中 T 表示三元组的训练集。
-
User Representations 用户表示很简单:每个用户u在其浏览历史中被表示为一个论文集合:

把用户浏览过的文件分成两组。做了这个细分,这样它可以帮助我们比较用户最近的兴趣和他们的历史兴趣,看看是否有偏差,以及在什么程度上有偏差。 -
Content Similarities. 我们将根据用户和论文的表示形式,描述相似度函数来度量不同类型的内容相似度。具体来说,内容部分使用来自论文元数据的信息来度量候选推荐和用户浏览的论文之间的相似性。由相似度评分组成的输出,输入到重新排名模型。
对于单词空间和实体空间,我们使用表示每篇文章的向量的余弦相似性。两个向量v和v '之间的余弦相似度定义为:

词空间和实体空间的相似性是:

然后,基于地点和作者的相似度度量,SimV(· ·)和SimA(· ·)定义如下:

对于新鲜度、影响力和流行度,这三个指标是单一的价值特征。我们使用调整权重的L1范数来获得它们的相似性:

Field Level Attention: field的注意力特征是其成对相似性的总和除以论文对的数量(以百分比表示):

Recent and History Attention:更多用户的近期兴趣偏离历史兴趣,αrecent的价值越高,因此提供一个偏置特征用来考虑最近的用户活动。计算方法如下:

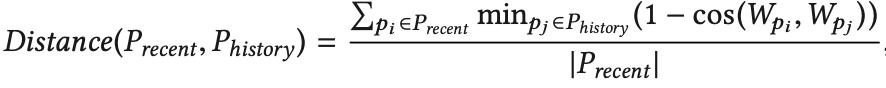
-
Behavior. 我们设计了一个行为模型,它利用了交互日志中的浏览和点击行为。
-
我们尝试使用监督学习从其他用户的映射中推断新用户的点击 -
由于论文推荐是在一个相对紧凑的电子邮件中显示的,我们假设用户已经注意到了所有的论文。 -
基于用户浏览历史的论文相似度是可用的。它可能比电子邮件中用户点击的相似度更准确,因此,我们的模型保持这种相似性是很重要的。我们建议从用户浏览的论文到用户点击的邮件,学习一个映射函数,记为

B∈Rn×n是用户浏览矩阵,M∈Rn×n是一个用户点击映射矩阵。在实践中,n通常是非常大的,因此它可能会造成很大的学习负担
因此,我们建议将M分解成一个低维因子的乘法:

根据上面的两个公式的条件下,我们可以通过以下公式来预测用户u在纸pi上的点击量
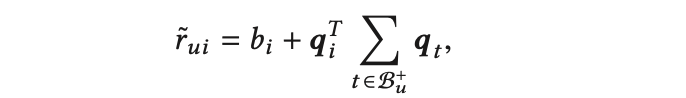
通过贝叶斯个性化排序,优化一个两两配对的损失函数:

我们然后可以定义如下的相似度正则化公式:

将以上两个公式结合起来,我们可以得到这个模型的最终形式:

接下来的实验部分请读者自行看论文














 775
775











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









