







1、“软batch”、梯度累计
我是用mask rcnn做分割,模型比较庞大,1080显卡最多也就能跑batch size=2,但又想起到batch size=64的效果,那可以怎么办呢?一种可以考虑的方案是,每次算batch size=2,然后把梯度缓存起来,32个batch后才更新参数。也就是说,每个小batch都算梯度,但每32个batch才更新一次参数。
我的需求是,SGD+Momentum实现梯度累加功能,借鉴了keras的optimizier的定义,可以看出每个优化器SGD、Adam等都是重载了Optimizer类,主要是需要重写get_updates方法。
2、思路:
学习速率 ϵ, 初始参数 θ, 初始速率v, 动量衰减参数α,每次迭代得到的梯度是g
计算梯度和误差,并更新速度v和参数θ:
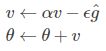
使用SGD+momentum进行梯度下降,计算参数v和θ(new_p)的值:
v = self.momentum * sg / float(self.steps_per_update) - lr * g # velocity
new_p = p + v
假设每steps_per_update批次更新一次梯度,先判断当前迭代是否足够steps_per_update次,也就是条件:
cond = K.equal(self.iterations % self.steps_per_update, 0)
如果满足条件,更新参数v和θ,如下:
self.updates.append(K.switch(cond, K.update(sg, v), p))
self.updates.append(K.switch(cond, K.update(p, new_p), p))
并且重新累计梯度,若不满足条件,则直接累计梯度:
self.updates.append(K.switch(cond, K.update(sg, g), K.update(sg, sg + g)))
3、我的完整实现如下:
class MySGD(Optimizer):
"""
Keras中简单自定义SGD优化器每隔一定的batch才更新一次参数
Includes support for momentum,
learning rate decay, and Nesterov momentum.
# Arguments
lr: float >= 0. Learning rate.
momentum: float >= 0. Parameter that accelerates SGD in the relevant direction and dampens oscillations.
decay: float >= 0. Learning rate decay over each update.
nesterov: boolean. Whether to apply Nesterov momentum.
steps_per_update: how many batch to update gradient
"""
def __init__(self, lr=0.01, momentum=0., decay=0.,
nesterov=False, steps_per_update=2, **kwargs):
super(MySGD, self).__init__(**kwargs)
with K.name_scope(self.__class__.__name__):
self.iterations = K 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









