






一、zuul和Gateway
zuul:阻塞式的 API,不支持长连接,比如 websockets, Zuul 2.x,基于Netty,也是非阻塞的,支持长连接
Gateway:Netty底层环境,不能和传统的Servlet容器一起使用,也不能打包成一个WAR包,Websockets得到支持,依赖webFlux提供异步非阻塞,Spring webflux 有一个全新的非堵塞的函数式 Reactive Web 框架,可以用来构建异步的、非堵塞的、事件驱动的服务,在伸缩性方面表现非常好(自行选择),优势:异步,非阻塞,Websockets,长连接,性能也会有很大提升
作用:身份+权限认证、路由、负载均衡、限流
二、nacos和eureka
AP-CP(available可用性,consistency一致性) 分区容错性
Nacos 临时实例是AP模式
Nacos 持久实例是CP模式
Zookeeper CP模式
Eureka AP模式
三、分布式事物
避免方案:1、开启事物前检查(提前抛错)
2、前置环节异常必须回滚的事物
3、能保证最终数据一致性的不要参与此次大事物
4、解耦:通过消息/其他方案,达到数据一致性
5、减少事物内的操作时间
6、避免事物产生死锁(比如AC 和CA 交替执行)
四、同步阻塞与异步阻塞(BIO/NIO)
NIO详解(二): BIO 浅谈 同步 异步与阻塞 非阻塞_Master-TJ的个人博客-CSDN博客_同步阻塞和同步非阻塞
阻塞:访问阻塞I/O 应用层被挂起,然后等待系统从磁盘读取完数据返回
非阻塞:访问非阻塞I/O后 系统直接返回(不获取数据,类似命令后不关注结果)
阻塞和非阻塞解决了应用层等待数据返回时的状态问题

同步:主动询问任务是否完成
异步:等待任务的完成通知(通过类似futrue等锚点或监听拿到最终数据)
关注的是任务完成时消息通知的方式。由调用方盲目主动问询的方式是同步调用,由被调用方主动通知调用方任务已完成的方式是异步调用。(应用与系统 对I/O操作的区别)
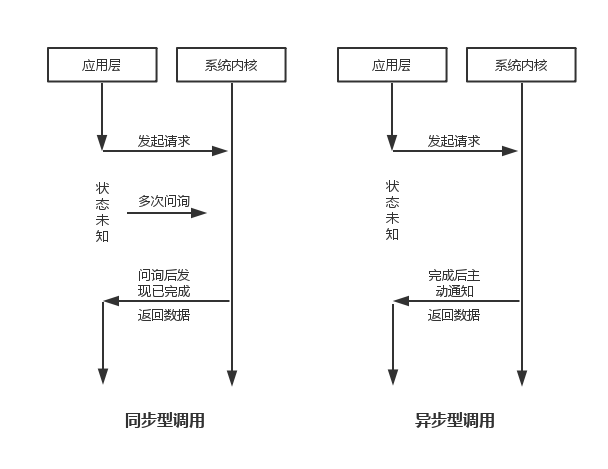
BIO为同步阻塞模式,NIO为同步非阻塞。NIO并没有实现异步,在JDK1.7以后,升级了NIO库包,指出异步非阻塞通信模式NIO 2.0(AIO)。
五、Hash集合的使用及实现
1、Hashtable 同步存储(synchronize同步锁是安全的,效率低)
2、HashMap 数组加链表(不安全),多线程间操作,结果不可预测,jdk8:链表节点大于8时转红黑树(时间复杂度O(n)->O(logn)) resize优化(扩容)
原理:hashCode相同 存储到同一数组下标的链表中(哈希碰撞),扩容:先开辟新存储空间,copy到新地址,原来置为null(引用失效)
不安全:put时多线程可能存在覆盖的问题(线程时间片耗尽导致的桶的索引计算错误)
红黑树: 红黑树是特殊的AVL树(平衡二叉树)提高查询效率,遵循红定理和黑定理 红定理:不能有两个相连的红节点 。黑定理:根节点必须是黑节点,而且所有节点通向NULL的路径上,所经过的黑节点的个数必须相等。
(任何不平衡都会在三次旋转之内解决、保证黑色高度的平衡、所有路径差值在两倍内、黑色高度为 N 的红黑树,从根到叶子节点的最短路径长度为 N-1,最长路径长度为 2 * (N-1))
红黑树并不追求“完全平衡”——它只要求部分地达到平衡要求,降低了对旋转的要求,从而提高了性能。
HashMap 通过 moveRootToFront方法来维持红黑树的根结点就是索引位置的头结点,remove当 movable 为 false 时不会触发
每个红黑树都有prev 和next (根节点prev 指向null)
3、ConcurrentHashMap 分段锁
3、扩容的时候,可以不可以对数组进行读写操作
事实上是可以的。当在进行数组扩容的时候,如果当前节点还没有被处理(也就是说还没有设置为fwd节点),那就可以进行设置操作。
如果该节点已经被处理了,则当前线程也会加入到扩容的操作中去。
4、多个线程又是如何同步处理的
在ConcurrentHashMap中,同步处理主要是通过Synchronized和unsafe两种方式来完成的。
·在取得sizeCtl、某个位置的Node的时候,使用的都是unsafe的方法,来达到并发安全的目的
·当需要在某个位置设置节点的时候,则会通过Synchronized的同步机制来锁定该位置的节点。
·在数组扩容的时候,则通过处理的步长和fwd节点来达到并发安全的目的,通过设置hash值为MOVED
·当把某个位置的节点复制到扩张后的table的时候,也通过Synchronized的同步机制来保证现程安全
从JDK1.7版本的ReentrantLock+Segment+HashEntry,到JDK1.8版本中synchronized+CAS+HashEntry+红黑树,
JDK1.8为什么使用内置锁synchronized来代替重入锁ReentrantLock:
- 低粒度加锁方式,synchronized并不比ReentrantLock差,
粗粒度加锁中ReentrantLock可能通过Condition来控制各个低粒度的边界,更加的灵活,而在低粒度中,Condition的优势就没有了
- JVM的开发团队从来都没有放弃synchronized,而且基于JVM的synchronized优化空间更大,使用内嵌的关键字比使用API更加自然
- 在大量的数据操作下,对于JVM的内存压力,基于API的ReentrantLock会开销更多的内存
synchronized(内置锁):jdk1.5阻塞的是实现, JDK1.6 优化措施,有自适应自旋,锁消除,锁粗化,轻量级锁,偏向锁等等
(synchronized说明)Synchronized原理和jdk1.8后的优化_F_Hello_World的博客-CSDN博客_synchronized1.8优化
ReentrantLock(显式锁)
内置锁这么好用,为什么还需多出一个显式锁呢?因为有些事情内置锁是做不了的,
比如:我们想给锁加个等待时间超时时间,超时还未获得锁就放弃,不至于无限等下去;
ReentrantLock的字面意思是可重入锁,可重入的意思是线程可以同时多次请求同一把锁,而不会自己导致自己死锁。
(两者区别)深入理解java内置锁(synchronized)和显式锁(ReentrantLock) - kaleidoscopic - 博客园
六、信号量和信号区别
1.信号:(signal)是一种处理异步事件的方式。信号时比较复杂的通信方式,用于通知接受进程有某种事件发生,除了用于进程外,还可以发送信号给进程本身。linux除了支持unix早期的信号语义函数,还支持语义符合...
2.信号量:(Semaphore)进程间通信处理同步互斥的机制。是在多线程环境下使用的一种设施, 它负责协调各个线程, 以保证它们能够正确、合理的使用公共资源。
七、布隆过滤器(HyperLogLog基数统计的算法)
一定不存在或者可能存在, 标准误差是 0.81%
应用场景:统计N个网站的UV(量很大)
pfadd pfcount
在 Redis 的 HyperLogLog 实现中用到的是 16384 个桶,也就是 2^14,每个桶的 maxbits 需要 6 个 bits 来存储,最大可以表示 maxbits=63,于是总共占用内存就是2^14 * 6 / 8 = 12k字节。
八、事物传播机制
https://zhuanlan.zhihu.com/p/148504094
XXL es sold 分析方式(条理:从底层讲:最差情况,最优情况,现在情况,趋势)















 569
569











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









