








系列文章传送门
(1)工业界推荐系统-小红书推荐场景及内部实践【业务指标、链路、ItemCF】
(2)工业界推荐系统-小红书推荐场景及内部实践【UserCF、离线特征处理】
(3)工业界推荐系统-小红书推荐场景及内部实践【矩阵补充、双塔模型】
(4)工业界推荐系统-小红书推荐场景及内部实践【正负样本选择】
(5)工业界推荐系统-小红书推荐场景及内部实践【线上召回和模型更新】
(6)工业界推荐系统-小红书推荐场景及内部实践【其他召回通道】
该系列文章根据小红书搜推算法工程师、团队负责人王树森B站上主讲的《工业界的推荐系统》之小红书业务场景及内部实践整理而得。感谢大佬分享工业界前沿的推荐系统实战技术!
这篇文章讲解工业界推荐系统实践中对于冷启动问题的处理技巧,包括:冷启动评价指标、召回通道、聚类召回、Lookalike人群扩展、流量调控以及冷启动中的AB测试等。
评价指标
为什么要特殊对待新笔记?
- 新笔记缺少与用户的交互,导致推荐的难度大、效果差。
- 扶持新发布、低曝光的笔记,可以增强作者发布意愿。
冷启动优化的目标?
- 精准推荐:克服冷启的困难,把新笔记推荐给合适的用户,不引起用户反感。
- 激励发布:流量向低曝光新笔记倾斜,激励作者发布。
- 挖掘高潜:通过初期小流量的试探,找到高质量的笔记,给与流量倾斜。
作者侧指标
发布渗透率(penetration rate) = 当日发布人数 / 日活人数
人均发布量 = 当日发布笔记数 / 日活人数
发布渗透率、人均发布量反映出作者的发布积极性。
冷启的重要优化目标是促进发布,增大内容池。
新笔记获得的曝光越多,首次曝光和交互出现得越 早,作者发布积极性越高。
用户侧指标
新笔记的消费指标
- 新笔记的点击率、交互率。
- 问题:曝光的基尼系数很大。
- 少数头部新笔记占据了大部分的曝光。
- 分别考察高曝光、低曝光新笔记。
- 高曝光:比如>1000次曝光。
- 低曝光:比如<1000次曝光。
大盘消费指标
- 大盘的消费时长、日活、月活。
- 大力扶持低曝光新笔记会发生什么?
- 作者侧发布指标变好。
- 用户侧大盘消费指标变差。
内容侧指标
高热笔记占比
- 高热笔记:前 30 天获得 1000+ 次点击。
- 高热笔记占比越高,说明冷启阶段挖掘优质笔记的能力越强。
简单的召回通道
召回的依据
✅ 自带图片、文字、地点。
✅ 算法或人工标注的标签。
❎ 没有用户点击、点赞等信息。
❎ 没有笔记 ID embedding。
冷启召回的困难
- 缺少用户交互,还没学好笔记 ID embedding,导致双塔模型效果不好。
- 缺少用户交互,导致 ItemCF 不适用。
改进后的双塔模型
改进方案 1:新笔记使用 default embedding。
- 物品塔做 ID embedding 时,让所有新笔记共享一个 ID,而不是用自己真正的 ID。
- Default embedding:共享的 ID 对应的 embedding 向量。
- 到下次模型训练的时候,新笔记才有自己的 ID embedding 向量。
改进方案 2:利用相似笔记 embedding 向量。
- 查找 top k 内容最相似的高曝笔记。
- 把 k 个高曝笔记的 embedding 向量取平均,作为新 笔记的 embedding。
类目召回



基于类目和关键词召回的缺点?
- 缺点1: 只对刚刚发布的新笔记有效。
- 取回某类目/关键词下最新的 k 篇笔记。
- 发布几小时之后,就再没有机会被召回。
- 缺点2: 弱个性化,不够精准。
聚类召回
基本思想
- 如果用户喜欢一篇笔记,那么他会喜欢内容相似的笔记。
- 事先训练一个神经网络,基于笔记的类目和图文内容,把笔记映射到向量。
- 对笔记向量做聚类,划分为 1000 cluster,记录每个 cluster 的中心方向。(k-means 聚类,用余弦相似度。)
聚类索引
- 一篇新笔记发布之后,用神经网络把它映射到一个 特征向量。
- 从 1000 个向量(对应 1000 个 cluster)中找到最相似的向量,作为新笔记的 cluster。
- 索引: cluster --> 笔记ID列表(按时间倒排)
线上召回
- 给定用户ID,找到他的 last-n 交互的笔记列表,把这些笔记作为种子笔记。
- 把每篇种子笔记映射到向量,寻找最相似的cluster。 (知道了用户对哪些 cluster 感兴趣。)
- 从每个 cluster 的笔记列表中,取回最新的 𝑚 篇笔 记。
- 最多取回 𝑚𝑛 篇新笔记。
内容相似度模型
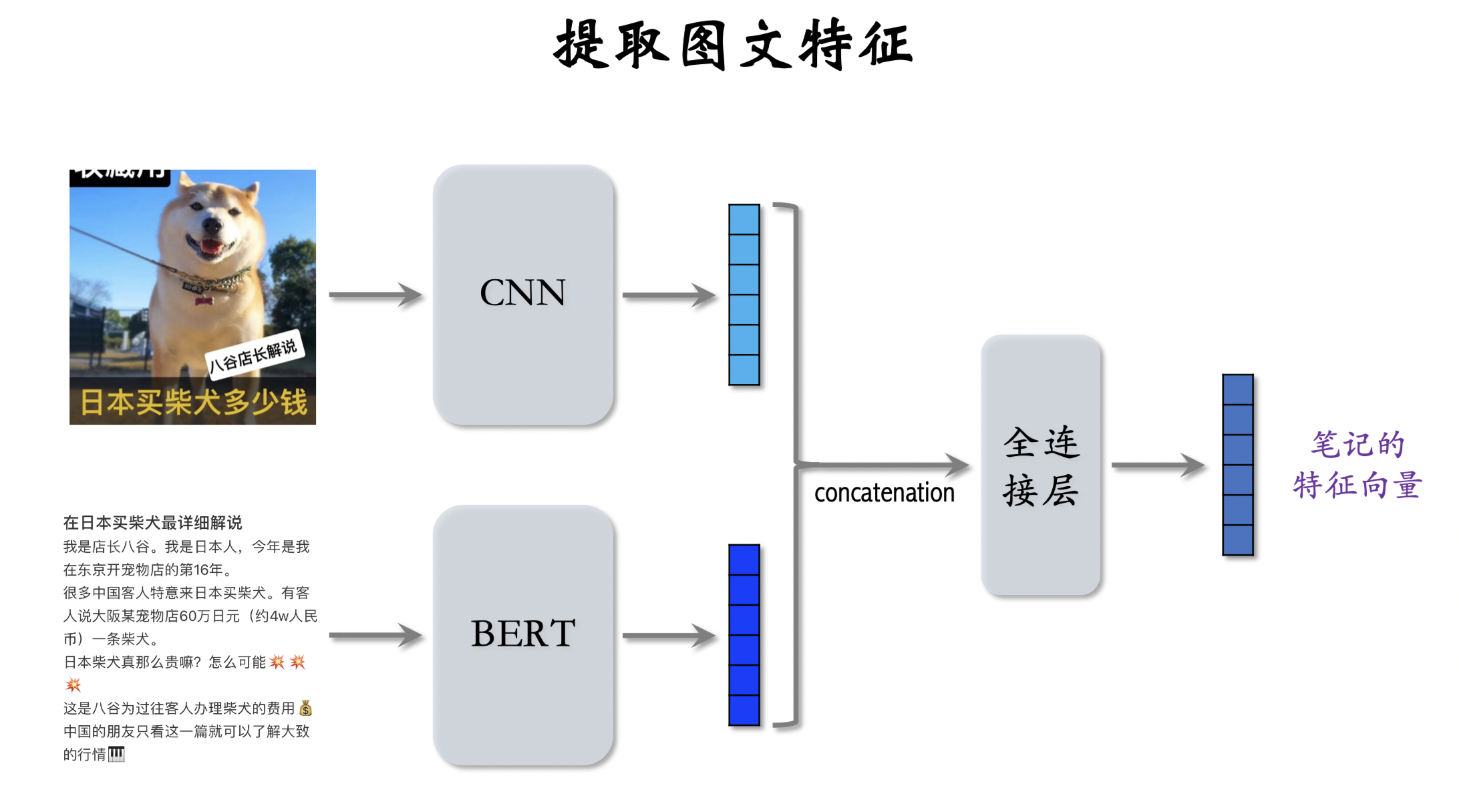
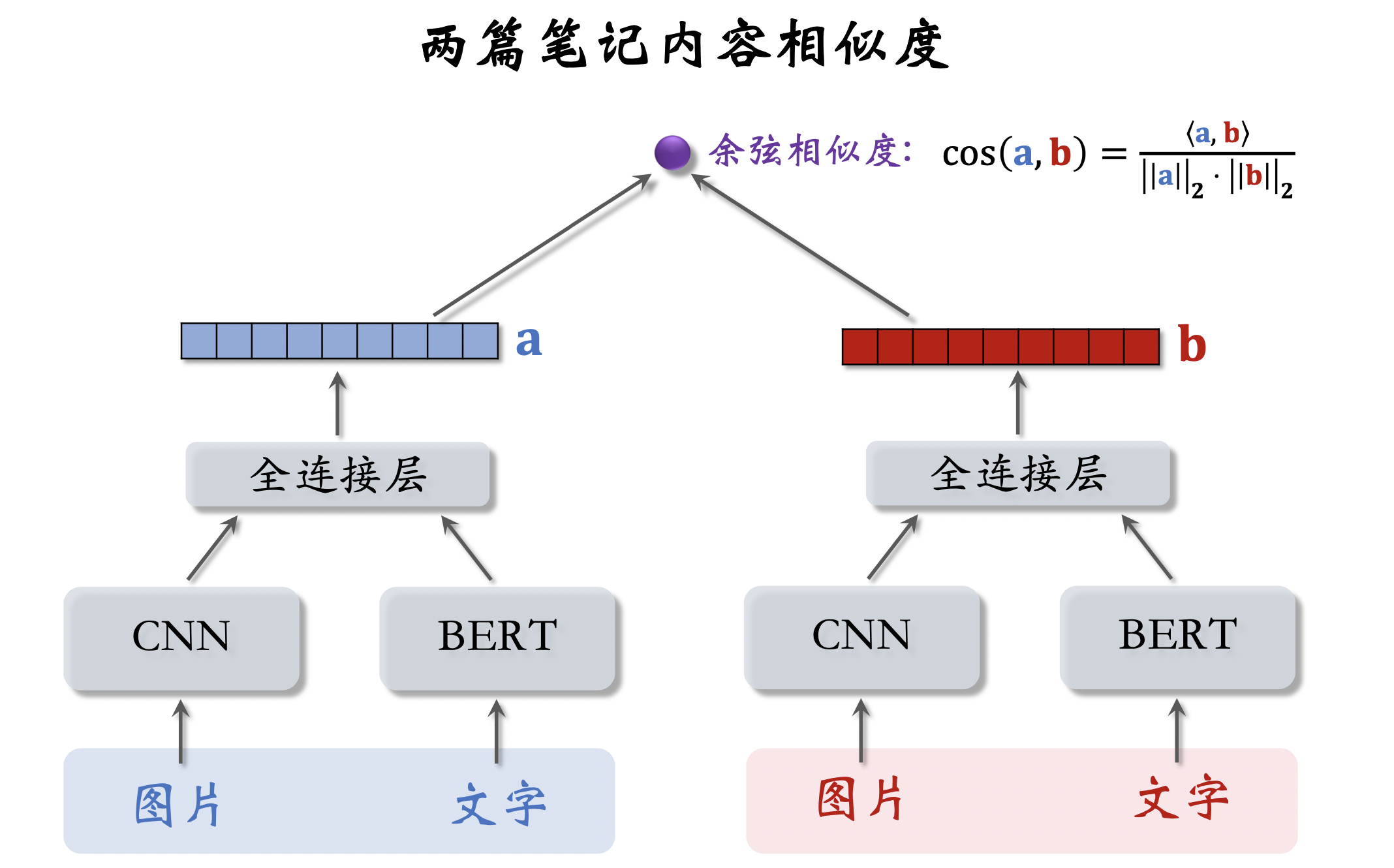
训练内容相似度模型
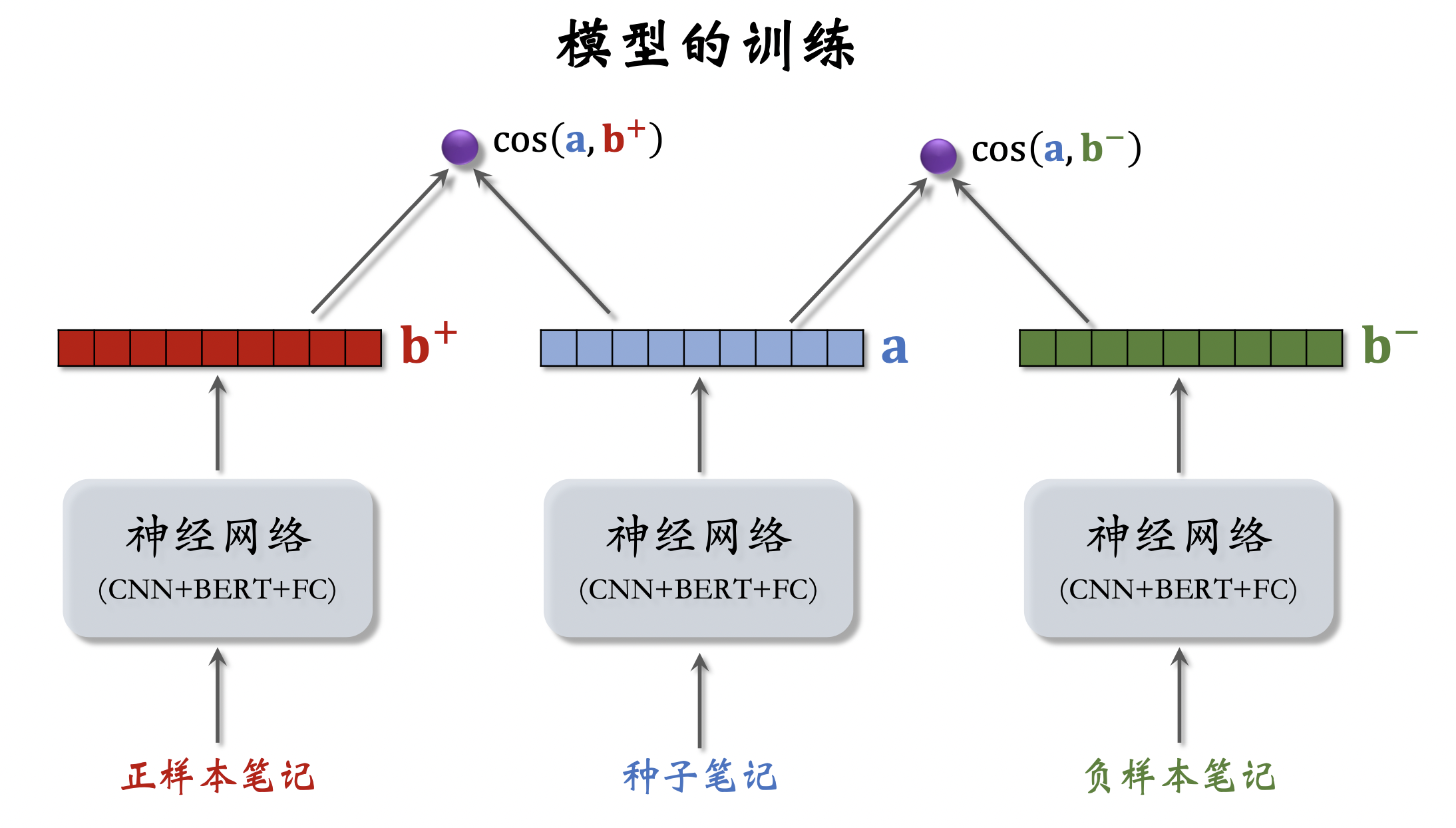

样本选择
<种子笔记,正样本>
方法一:人工标注二元组的相似度
方法二:算法自动选正样本
- 筛选条件:
- 只用高曝光笔记作为二元组(因为有充足的用户交互信息)。
- 两篇笔记有相同的二级类目,比如都是“菜谱教程”。
- 用 ItemCF 的物品相似度选正样本。
<种子笔记,负样本>
- 从全体笔记中随机选出满足条件的:
- 字数较多(神经网络提取的文本信息有效)。
- 笔记质量高,避免图文无关。
聚类召回总结

下一篇继续讲解冷启动问题。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











