








(1)工业界推荐系统-小红书推荐场景及内部实践【业务指标、链路、ItemCF】
(2)工业界推荐系统-小红书推荐场景及内部实践【UserCF、离线特征处理】
(3)工业界推荐系统-小红书推荐场景及内部实践【矩阵补充、双塔模型】
(4)工业界推荐系统-小红书推荐场景及内部实践【正负样本选择】
(5)工业界推荐系统-小红书推荐场景及内部实践【线上召回和模型更新】
(6)工业界推荐系统-小红书推荐场景及内部实践【其他召回通道】
(7)工业界推荐系统-小红书推荐场景及内部实践【冷启动问题1】
(8)工业界推荐系统-小红书推荐场景及内部实践【冷启动问题2】
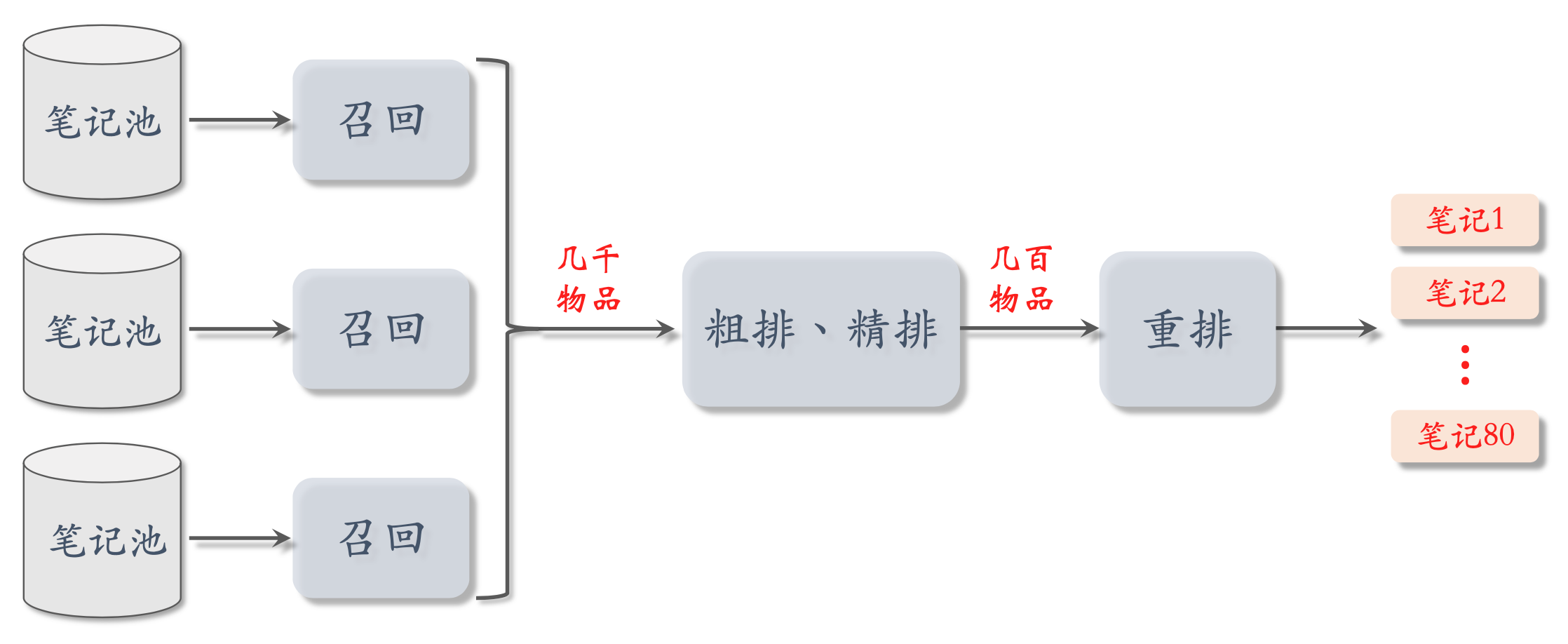
推荐系统链路
- 点击率 = 点击次数 / 曝光次数
- 点赞率 = 点赞次数 / 点击次数
- 收藏率 = 收藏次数 / 点击次数
- 转发率 = 转发次数 / 点击次数
排序依据
- 排序模型预估点击率、点赞率、收藏率、 转发率等多种分数。
- 融合这些预估分数。(比如加权和。)
- 根据融合的分数做排序、截断。
模型结构
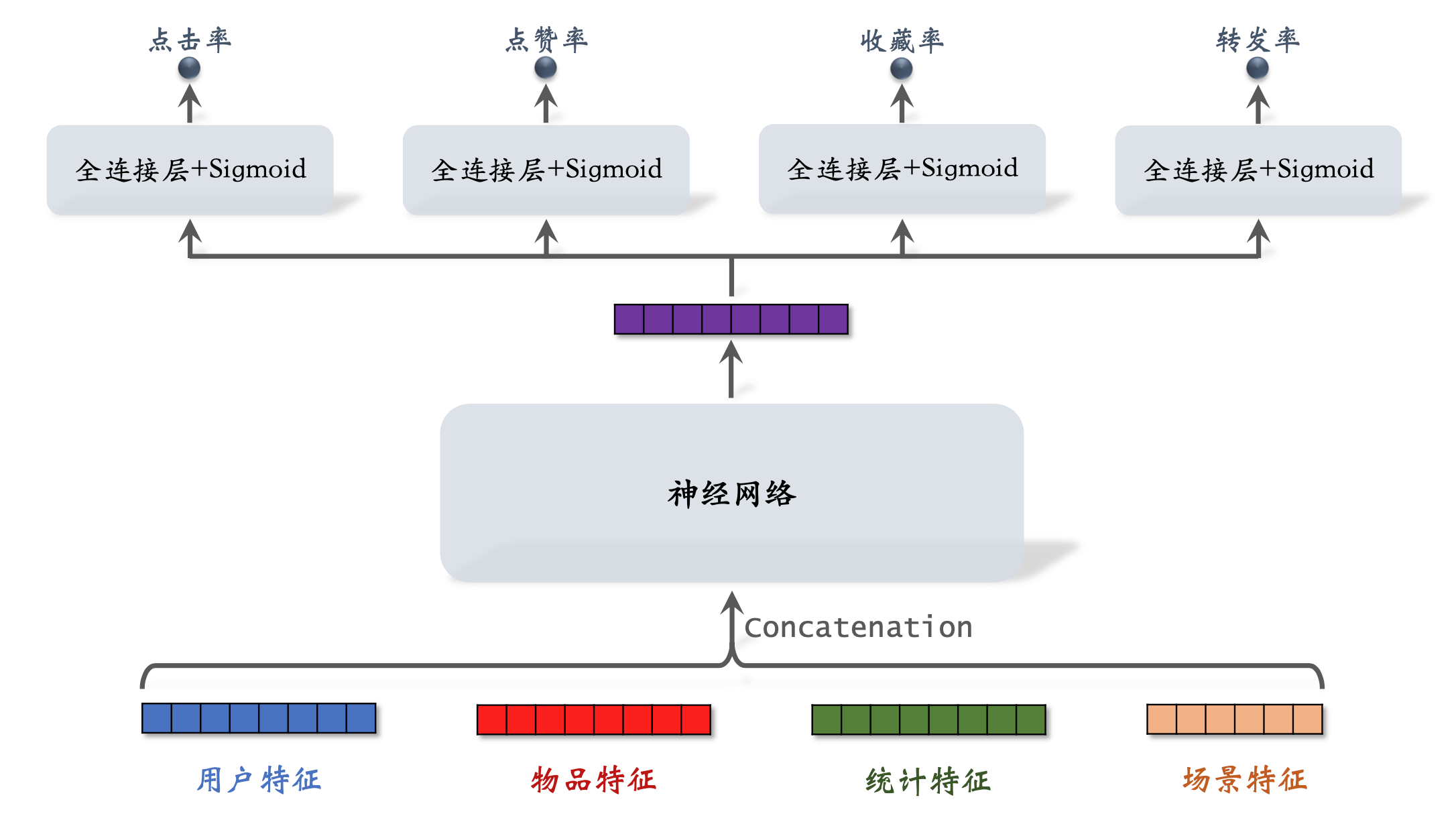
目标函数
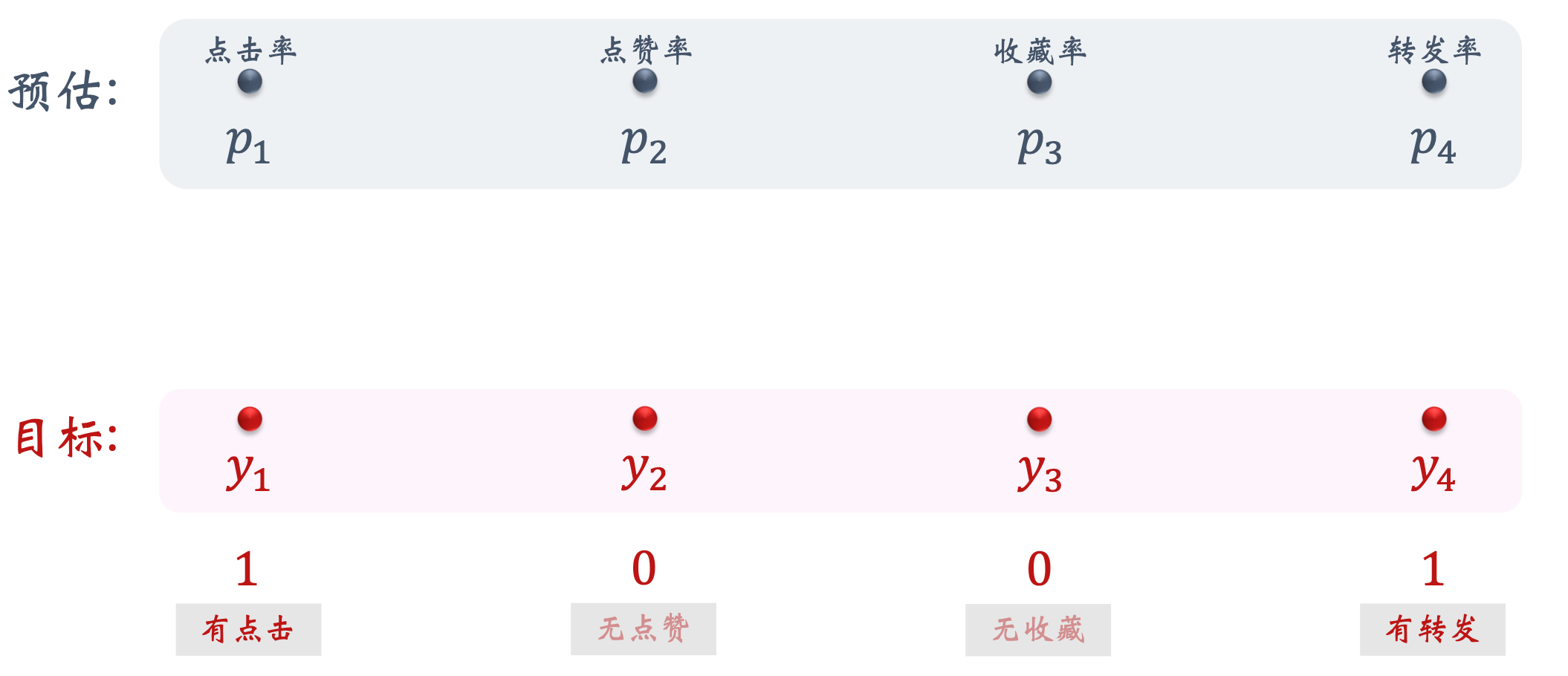

模型训练
样本不均衡
- 困难:类别不平衡。
- 每100次曝光,约有10次点击、90次无点击。
- 每100次点击,约有10次收藏、90次无收藏。
- 解决方案:负样本降采样(down-sampling)【类似于Ohem Loss】。
- 保留一小部分负样本。
- 让正负样本数量平衡,节约计算。
预估值校准
- 正样本、负样本数量为 n + n_+ n+ 和 n − n_- n− 。
- 对负样本做降采样,抛弃一部分负样本。
- 使用 α ∗ n − \alpha * n_- α∗n− 个负样本, α ∈ ( 0 , 1 ) \alpha \in (0,1) α∈(0,1) 是采样率。
- 由于负样本变少,预估点击率大于真实点击率。

参考文献:Practical lessons from predicting clicks on ads at Facebook
MMOE结构【Multi-gate Mixture-of-Experts】
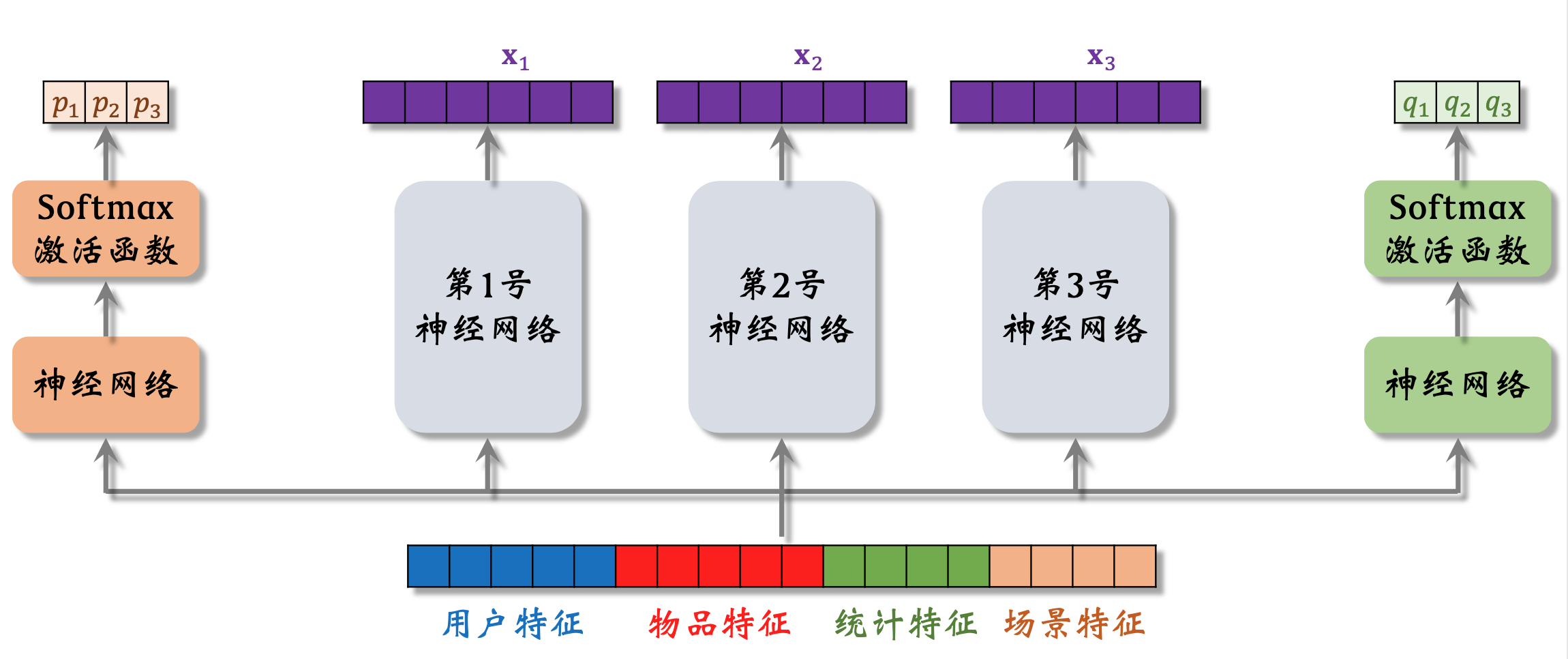
其中 第1号、2号、3号神经网络分别为三个“专家”(Experts)模型
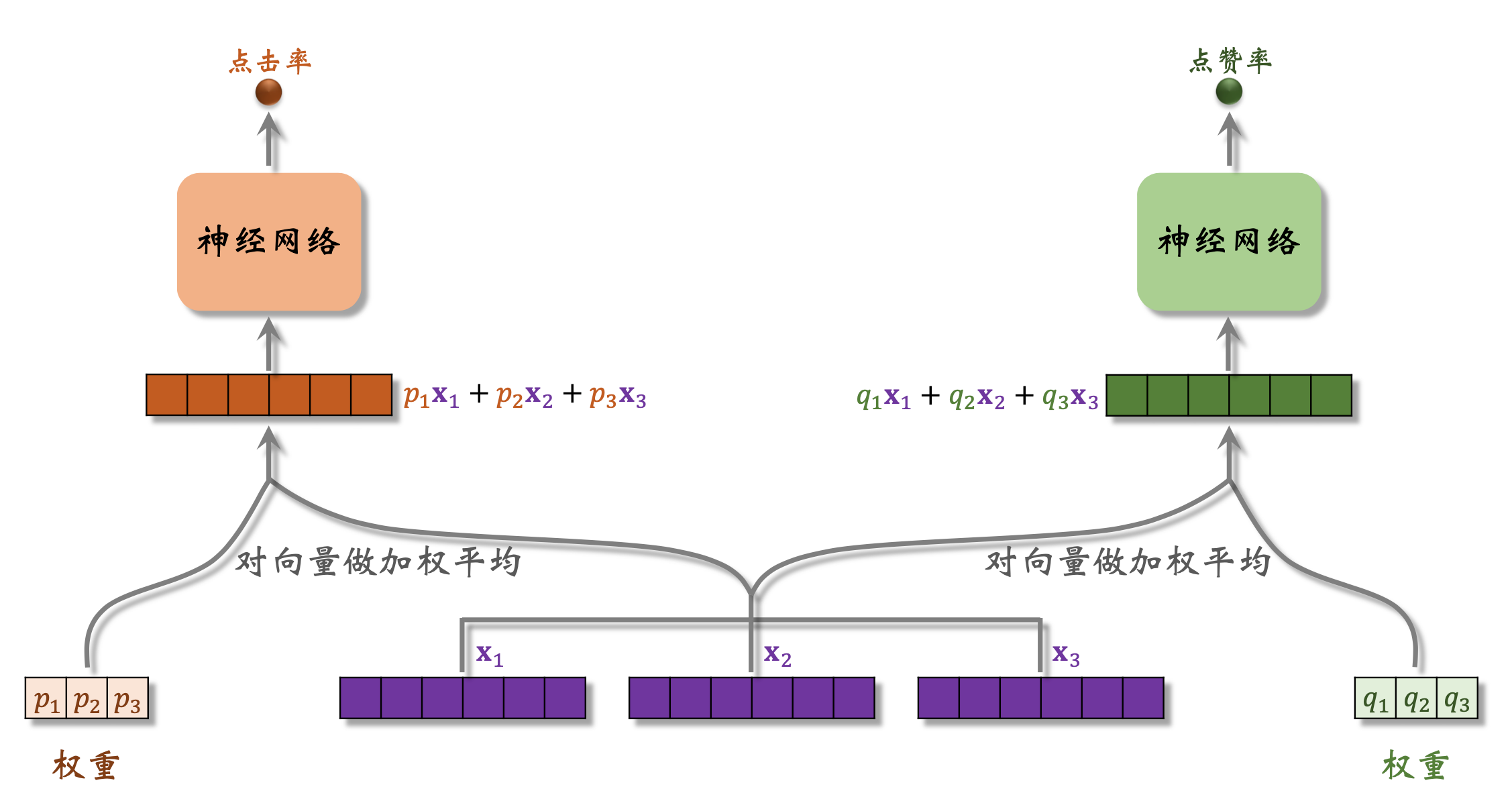
有几个学习目标,就需要几个专家模型,不同的专家网络学习不同的目标。
极化现象(Polarization)
MMOE可能存在的一个突出问题就是 极化现象(Polarization),如下图所示:
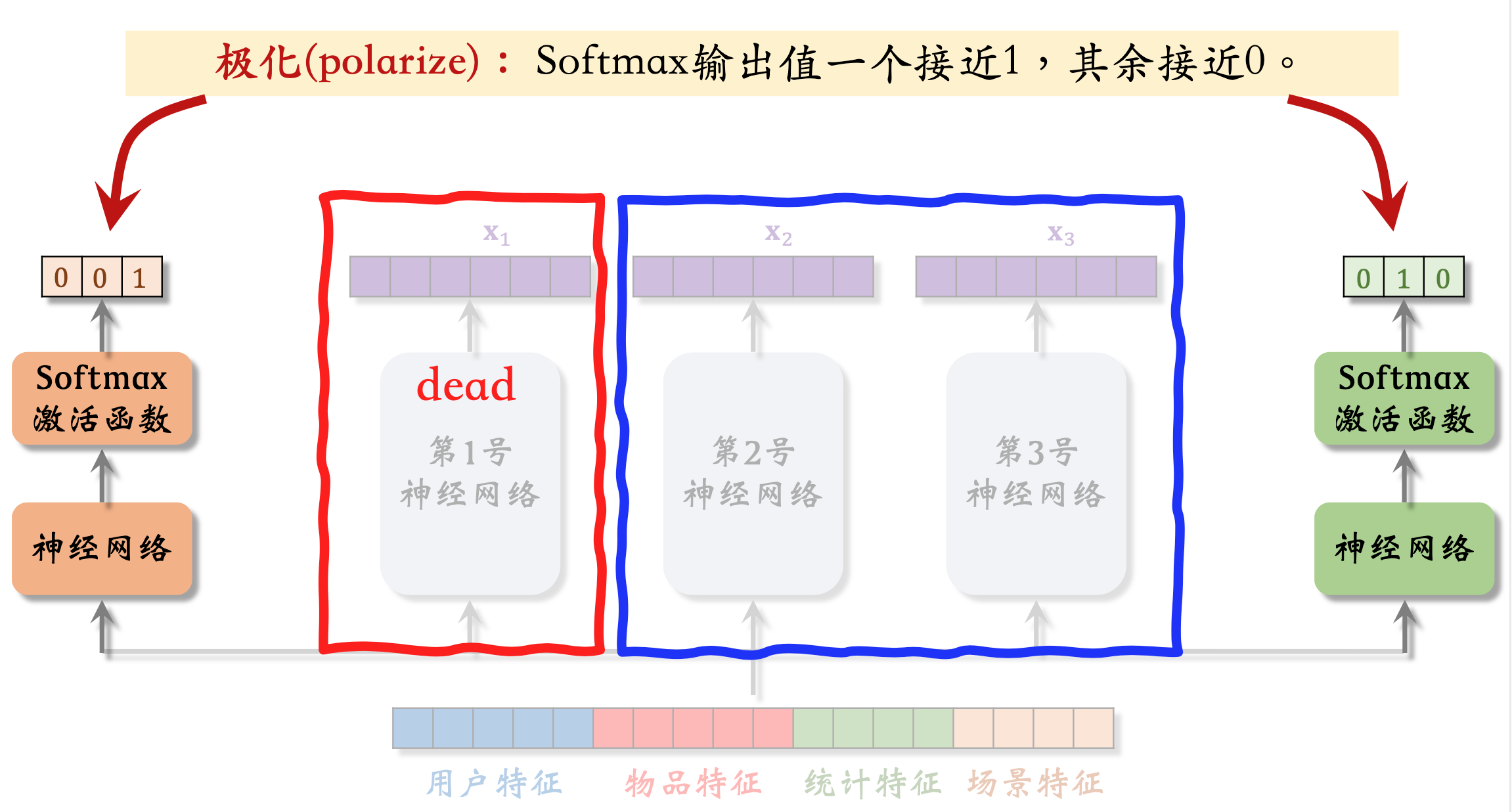
解决极化问题
- 如果有 𝑛 个“专家”,那么每个 softmax 的输入和输出都是 𝑛 维向量。
- 在训练时,对 softmax 的输出使用 dropout。
- Softmax 输出的 𝑛 个数值被 mask 的概率都是 10%。
- 每个“专家”被随机丢弃的概率都是 10%。
参考文献:
1、MMOE模型 Modeling Task Relationships in Multi-taskLearning with Multi-gate Mixture-of-Experts.
2、极化问题解决方案:Recommending What Video to Watch Next: A Multitask Ranking System.
预估分数融合

海外某短视频APP的融合公式
( 1 + w 1 ⋅ p t i m e ) α 1 ⋅ ( 1 + w 2 ⋅ p l i k e ) α 2 … (1+w_1\cdot p_{time})^{\alpha_1}\cdot (1+w_2\cdot p_{like})^{\alpha_2}… (1+w1⋅ptime)α1⋅(1+w2⋅plike)α2…
国内某短视频APP的融分公式
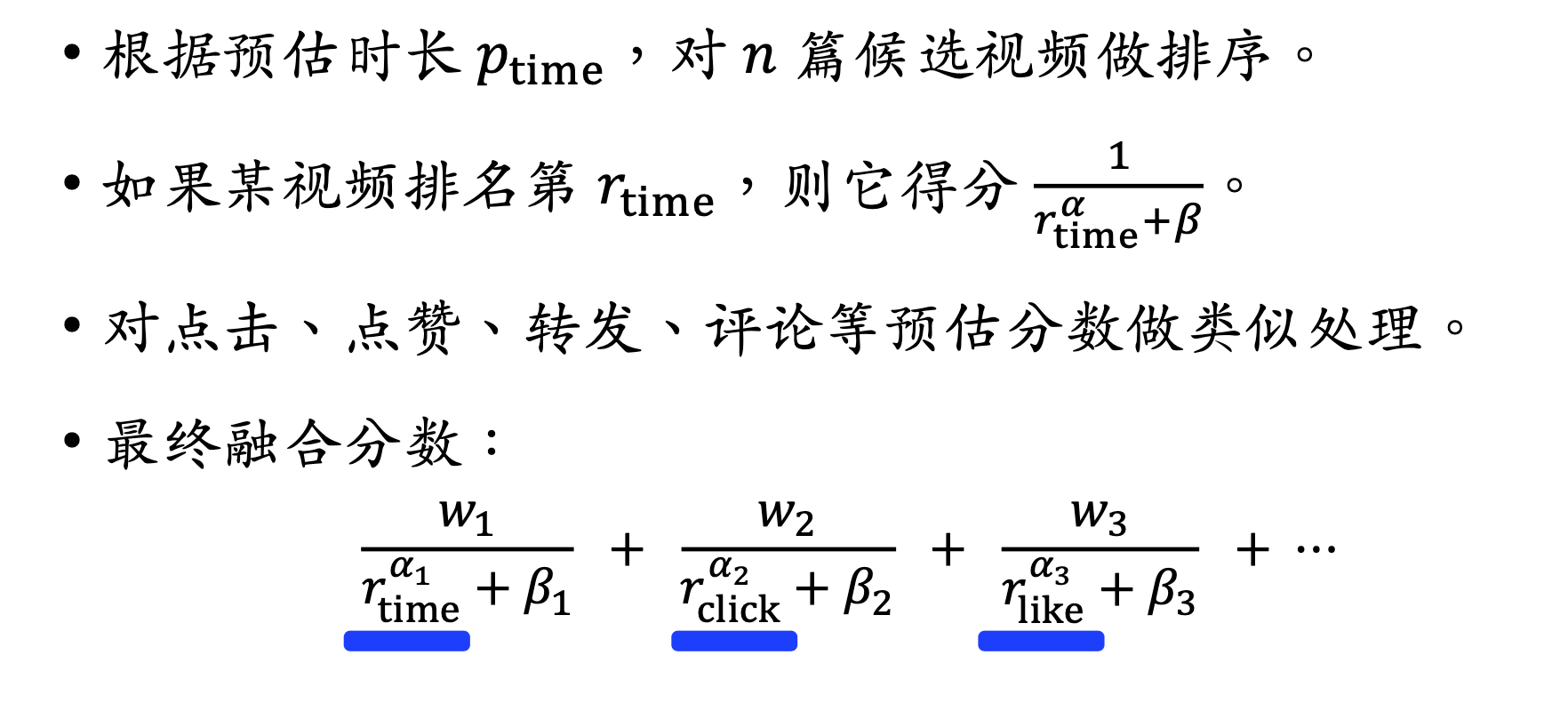
某电商的融分公式

视频播放建模
视频播放时长
- 图文笔记排序的主要依据:
点击、点赞、收藏、转发、评论… - 视频排序的依据还有播放时长和完播。
- 直接用回归拟合播放时长效果不好。建议用 YouTube 的时长建模 [1]。
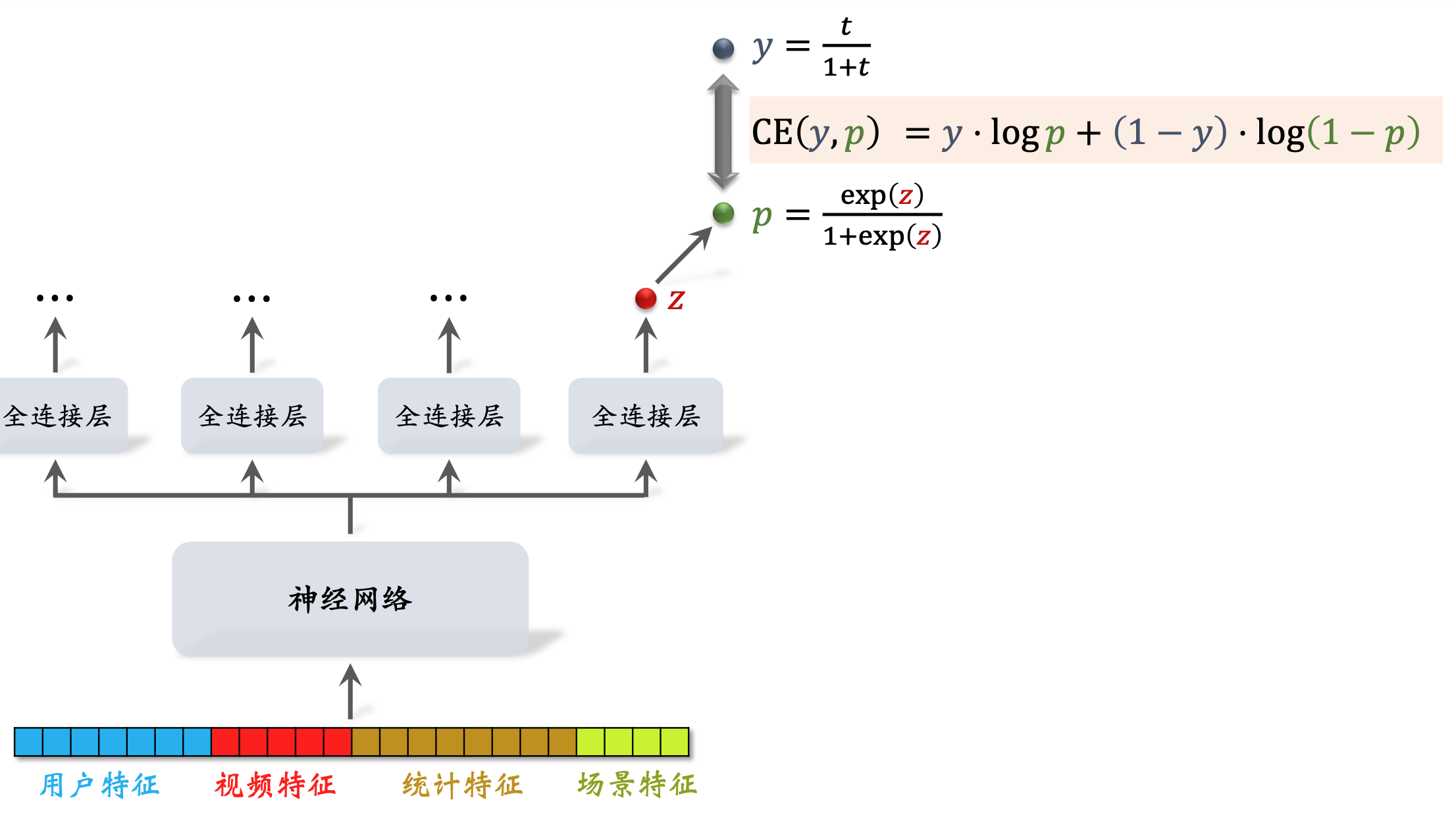
这里,
t
t
t 为观看时长。
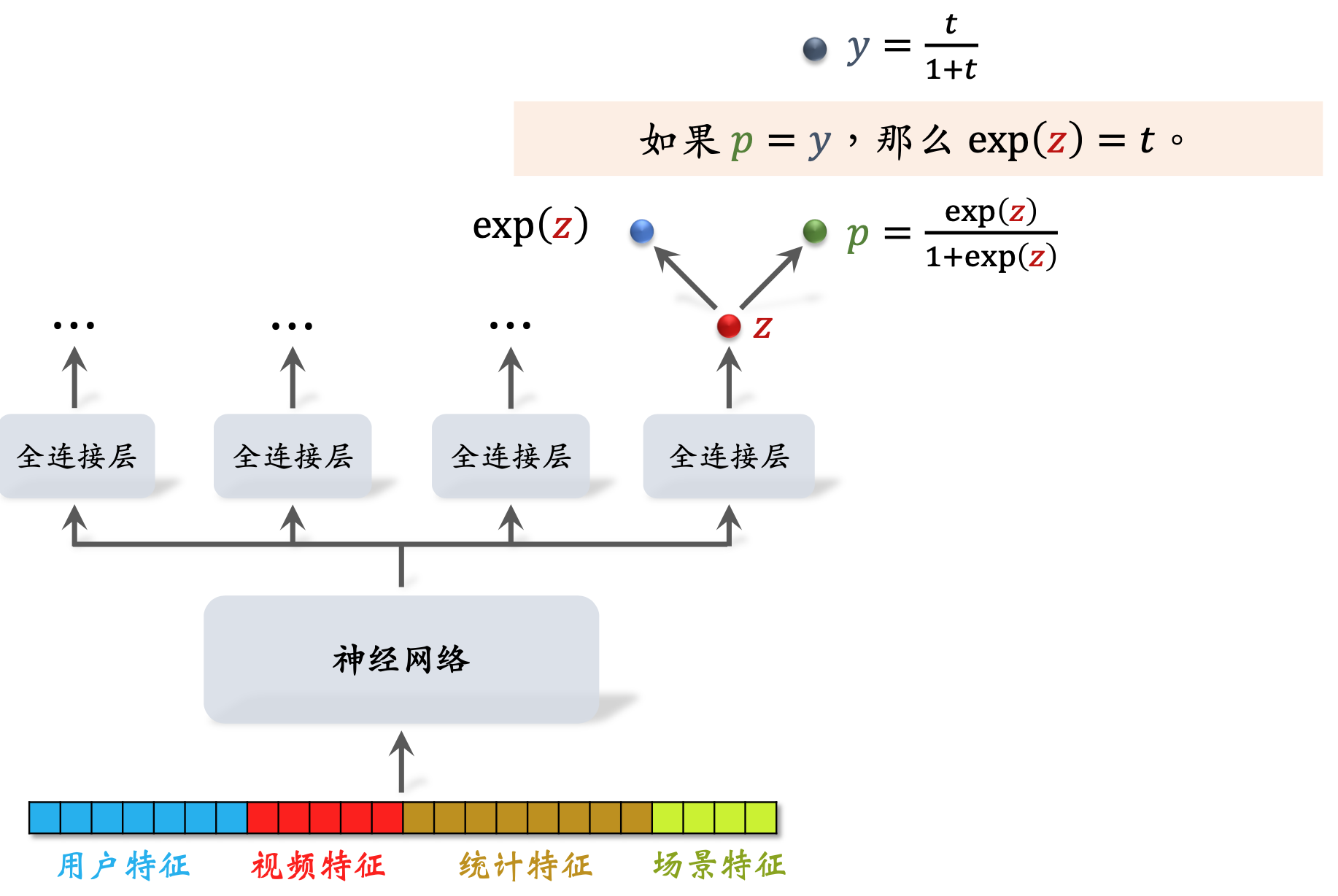
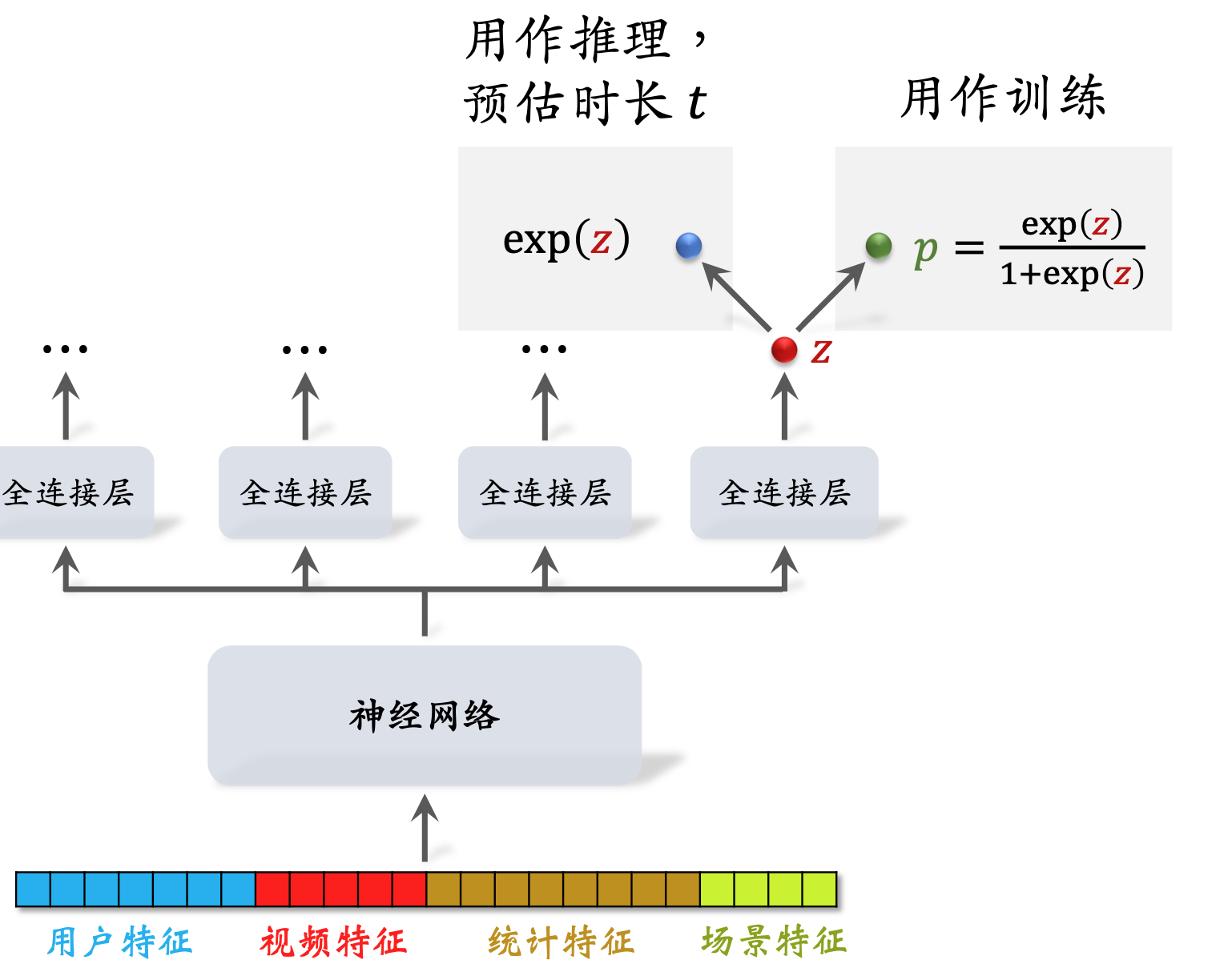

视频完播
回归方法

二分类方法

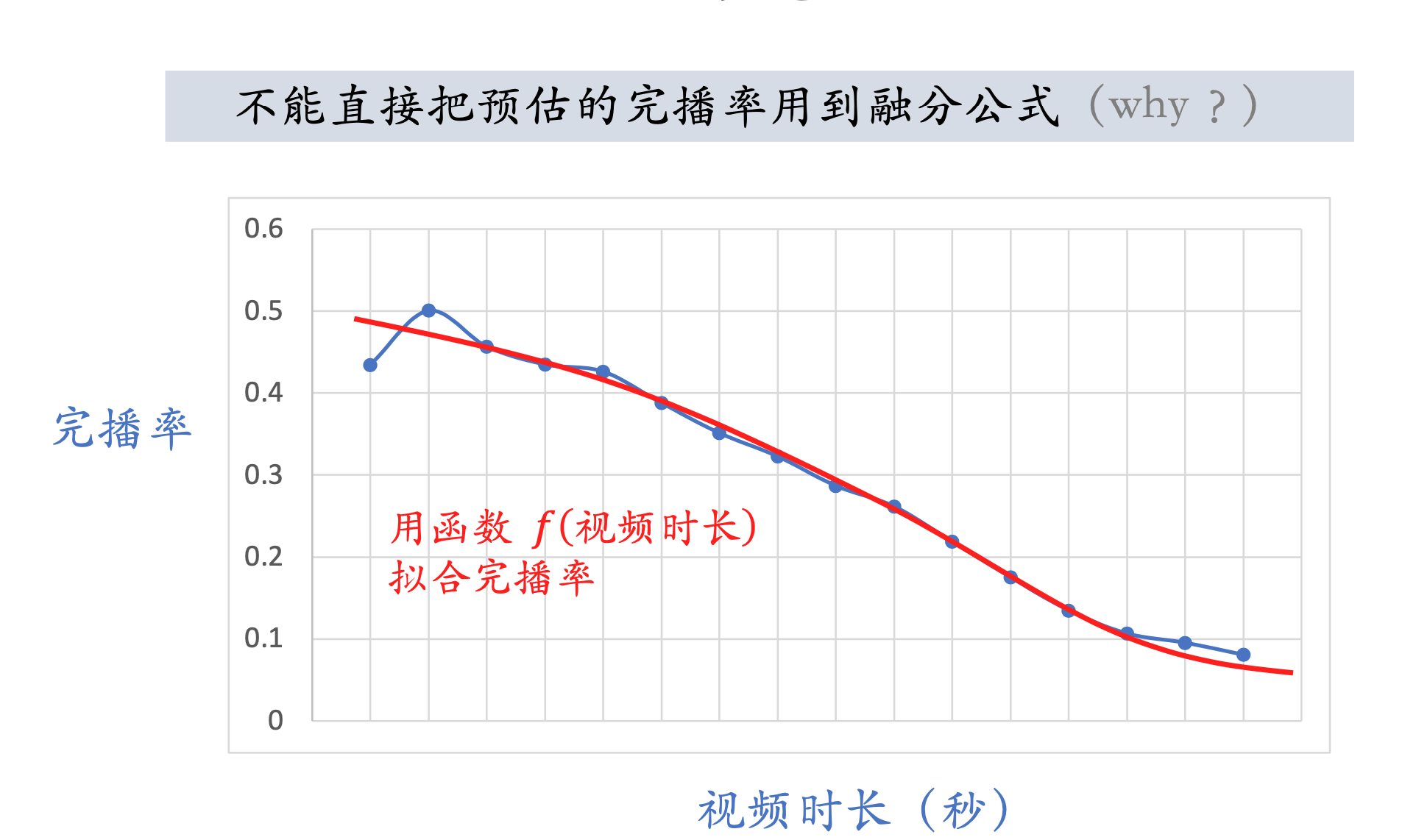
直接把预估的完播率用到融合公式,比较有利于短视频【完播率高】,对长视频不公平【完播率低】,因此,需要对完播率校准





















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











