







 本文通过一个实际案例详细介绍了如何使用Power Query进行数据清洗,涵盖删除多余行、提升标题、更改数据类型、数据压缩、表格变换、数据拼接、数据修整和复查等步骤。案例数据包括世界银行的年龄人口占比和人口总数指标,通过Power Query的清洗,为后续建模和数据分析做好准备。
本文通过一个实际案例详细介绍了如何使用Power Query进行数据清洗,涵盖删除多余行、提升标题、更改数据类型、数据压缩、表格变换、数据拼接、数据修整和复查等步骤。案例数据包括世界银行的年龄人口占比和人口总数指标,通过Power Query的清洗,为后续建模和数据分析做好准备。
在本文中,我们将会使用一套简单的案例数据进行一次完整的清洗,尽量覆盖到Power Query中最常用的功能,这些数据也会在接下来建模和DAX语言的讲解中继续用来作为示例数据。
关于案例数据
我们从 世界银行 Indicators | Data 下载了如下四项指标:0-14岁的人口(占总人口的百分比)、15-64岁的人口(占总人口的百分比)、65岁和65岁以上的人口(占总人口的百分比)、人口总数。另外还有一张也是官方提供的维度表,是国家名称、编码、归属区域、收入等级等基础信息。
因为这些数据不涉及更新,为了本地文件管理方便,我将这些数据表合并在了同一个excel中,实际操作中使用独立的文件也完全没有问题、甚至是更加灵活。因为不论是一个excel中的多个工作表、还是独立的多个excel文件,在导入后都是每张工作表形成一个数据源,在数据源数量上没有区别,按照个人使用习惯即可。
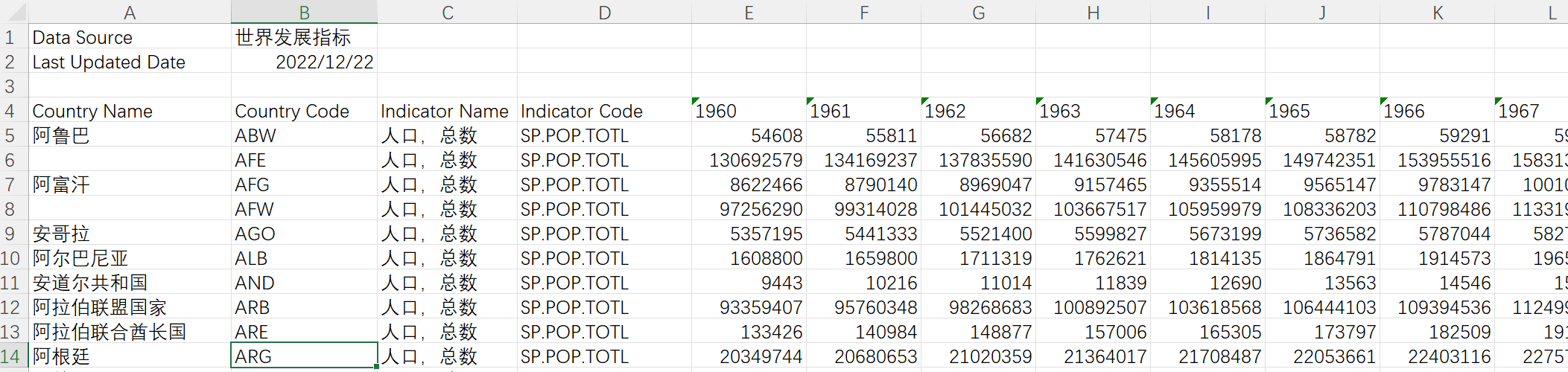
如下图所示,这些指标数据都拥有相同的结构,即数据主体从单元格A4开始,包括Country Name、Country Code、Indicator Name、Indicator Code等四个维度字段,以及1960-2021之间62年的数据,每年单独为一列。
国家维度表的结构如下:

维度表的清洗
如下图所示,国家表在初导入时,表头并未被识别,因为power query是根据第一行数据与后面的数据之间的差异来判断是否是表头的,因为该表是纯文本的,差异不明显,因此会被误判,这时很简单,点击“将第一行用做标题”即可完成标题的提升。

然后观察这张表,通常只要有编码列,我们都推荐使用编码做为各数据表之间关联用的字段,因为它具有非重复性,字段名下方的统计信息中显示没有空值,目测该列信息是完整的。如果对编码的唯一性不放心,也可以在“转换-统计信息”中,对该列进行非重复计数,用于确认。
在该表中我们可以看到,国家名称有空值,经过观察可以发现,该字段为空的记录中,地区以及收入等级列也都是空,可以认为是无效数据,所以也可以对国家名称列进行筛选,过滤掉空值。(这步不做也不要紧,因为影响的数据量很小,而且在报表中过滤也能实现相同的效果)。
数据表的清洗(年龄分组的同构指标)
step1 删除多余行
以0-14岁的数据为例,当数据导入后,power query执行默认的操作步骤,将第一行提升为标题,因此从c列之后因为第一行为空,都被赋了column3……等一系列默认标题,而我们实际要用的标题还处于第3行。

从菜单栏中选择:主页-删除行-删除最前面的几行,输入2行,即可将前面的行删除。
事实上,目前已执行的“提升
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4386
4386

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









