






1.求用户连续登录天数、连续下单次数、连续......等次数等。
user_id login_time
1 2022-08-20
1 2022-08-21
2 2022-08-20
2 2022-08-22
2 2022-08-23
3 2022-08-20
3 2022-08-23
3 2022-08-25求用户的最大的连续登录天数:
select
T.user_id,
max(TT.continue_login_cnt) as max_continue_login_cnt
from (
select
T.user_id,
T.login_date,
count(1) as continue_login_cnt
from
(
select
user_id,
login_time,
date_sub(login_time, row_number() over(partition by user_id order by login_time)) login_date
from
tmp_table
) T
group by T.user_id, T.login_date
) TT
group by T.user_id1.2 连续问题的变种
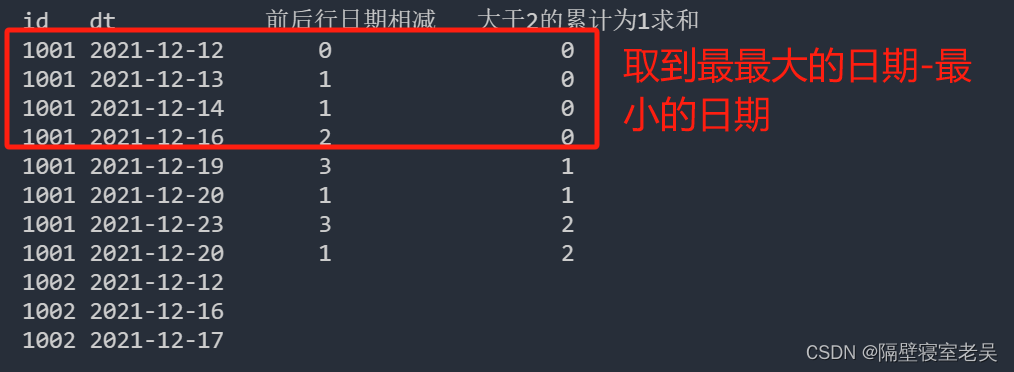
某游戏公司记录的用户每日登录数据:
id dt 前后行日期相减 大于2的累计为1求和
1001 2021-12-12 0 0
1001 2021-12-13 1 0
1001 2021-12-14 1 0
1001 2021-12-16 2 0
1001 2021-12-19 3 1
1001 2021-12-20 1 1
1001 2021-12-23 3 2
1001 2021-12-20 1 2
1002 2021-12-12
1002 2021-12-16
1002 2021-12-17
计算每个用户最大的连续登录天数,可以间隔一天。解释:如果一个用户在 1,3,5,6 登 录游戏,则视为连续 6 天登录。
select
id,
max(days)+1
from
(
select
id,
flag,
datediff(max(dt),min(dt)) days
from
(
select
id,
dt,
sum(if(flag>2,1,0)) over(partition by id order by dt) flag
from
(
select
id,
dt,
datediff(dt,lagdt) flag
from
(
select
id,
dt,
lag(dt,1,'1970-01-01') over(partition by id order by dt) lagdt
from
test3
)t1
)t2
)t3
group by id,flag
)t4
group by id;1.3求最大的连胜的场次数/天数
user_id datetime result
1 2023-01-02 win
1 2023-01-03 win
1 2023-01-05 win
1 2023-01-07 win
1 2023-01-10 Lose
2 2023-01-11 win
2 2023-01-15 win
3 2023-01-19 Lose求连续的胜利场次数/天数如下:
select
TT.user_id,
max(TT.continue_win_cnt) as continue_win_cnt
from (
select
T.user_id,
(T.rank1 - T.rank2) as rank_date,
sum(case when T.result = 'win' then 1 else 0 end) as continue_win_cnt -- 连胜天数
from
(
select
user_id,
datetime,
result,
row_number() over(partition by user_id order by datetime) rank1,
row_number() over(partition by user_id, result order by datetime) rank2
from
tmp_tab
) T
group by T.user_id, (T.rank1 - T.rank2)
) TT 1.4 间断清零,求截至目前的连续签到天数: A 1-4号连续,但是5号没签到,从0开始重新累计,所以是6-8号3天。
WITH data AS (
SELECT 'A' NAME , '2024-04-01' AS DT UNION ALL
SELECT 'A' NAME , '2024-04-02' AS DT UNION ALL
SELECT 'A' NAME , '2024-04-03' AS DT UNION ALL
SELECT 'A' NAME , '2024-04-04' AS DT UNION ALL
SELECT 'A' NAME , '2024-04-06' AS DT UNION ALL
SELECT 'A' NAME , '2024-04-07' AS DT UNION ALL
SELECT 'A' NAME , '2024-04-08' AS DT UNION ALL
SELECT 'B' NAME , '2024-04-01' AS DT UNION ALL
SELECT 'B' NAME , '2024-04-02' AS DT UNION ALL
SELECT 'B' NAME , '2024-04-03' AS DT UNION ALL
SELECT 'B' NAME , '2024-04-04' AS DT UNION ALL
SELECT 'B' NAME , '2024-04-05' AS DT UNION ALL
SELECT 'B' NAME , '2024-04-06' AS DT UNION ALL
SELECT 'B' NAME , '2024-04-08' AS DT UNION ALL
SELECT 'C' NAME , '2024-04-01' AS DT UNION ALL
SELECT 'C' NAME , '2024-04-02' AS DT UNION ALL
SELECT 'C' NAME , '2024-04-03' AS DT UNION ALL
SELECT 'C' NAME , '2024-04-05' AS DT UNION ALL
SELECT 'C' NAME , '2024-04-06' AS DT UNION ALL
SELECT 'C' NAME , '2024-04-07' AS DT UNION ALL
SELECT 'C' NAME , '2024-04-08' AS DT UNION ALL
SELECT 'D' NAME , '2024-04-01' AS DT UNION ALL
SELECT 'D' NAME , '2024-04-02' AS DT UNION ALL
SELECT 'D' NAME , '2024-04-03' AS DT UNION ALL
SELECT 'D' NAME , '2024-04-04' AS DT UNION ALL
SELECT 'D' NAME , '2024-04-06' AS DT UNION ALL
SELECT 'D' NAME , '2024-04-07' AS DT
)解法如下:
select
NAME,
flag,
min(DT) as st,
max(DT) as et
from
(
select
NAME,
DT,
sum(
case when
datediff(DT, lag(DT, 1, DT) over(partition by NAME order by DT) )
> 1 then 1 else 0 end
) over(partition by NAME order by DT) as flag
from
data
) as T
group by NAME, flag2. 求直播间中并发最高的人数
user_id enter_time out_time
1 2022-08-23 11:00:11 2022-08-23 12:11:00
2 2022-08-23 10:00:12 2022-08-23 11:10:00
1 2022-08-23 09:00:56 2022-08-23 10:10:00
4 2022-08-23 11:20:32 2022-08-23 14:11:00
5 2022-08-23 12:10:00 2022-08-23 15:12:00
6 2022-08-23 13:00:23 2022-08-23 13:13:00
7 2022-08-23 11:30:00 2022-08-23 12:14:00并发指的是:直播过程中直播间某一时刻最大的人数
这种情况,我们需要将直播的进入时间和离开时间分别拆成两条数据,并且为进入事件打上1的标识,离开事件打上-1的标识,然后开窗sum(flag) over(partition by 1 oder by evnet_time),然后对其求最大的那条数据就OK了。此种方法,其实就是模拟直播开始过程中,来一个人就+1,离开一个人就-1的情况,然后求最大就是某一时刻最大的人数。
3.求互为好友的用户有哪些
user_id firend_id
1 2
3 1
2 1
4 3
3 4数据如上,此种有很多种解法,如下:
select
T1.user_id, T1.user_id
from
tmp T1 inner join tmp T2
on T1.user_id = T2.firend_id and T1.firend_id = T2.user_id
where T1.user_id > T2.user_id
和
select
split(T.flag, '#')[0] as user_id,
split(T.flag, '#')[1] as frend_id
from
(
select
concat(if(user_id > firend_id, user_id, firend_id), '#', if(user_id < firend_id, user_id, firend_id)) as flag
from
tmp
group by flag, having count(1) >= 2
) as T4.有msg_time,from,to, msg等字段,计算聊天两轮(用户消息一来一回表示一轮)以上的用户。
time from to
2021-11-24 21:23:00 1 2
2021-11-24 21:23:01 2 1
2021-11-24 21:23:02 1 2
2021-11-24 21:23:03 2 1
2021-11-24 21:23:04 2 1
2021-11-24 21:23:01 3 1
2021-11-24 21:23:02 1 3
2021-11-24 21:23:03 3 1
2021-11-24 21:23:04 1 3这个其实也和上面一样的一样,但是要判断是不是相邻的就比较麻烦点,解法如下:
select
T4.newId,
count(T4.times_flag)/2 as times
from
(
select
T3.newId,
case
when T3.from = nvl(lead(T3.to) over(partition by T3.newId order by T3.time), T3.from)
and T3.to = nvl(lead(T3.from) over(partition by T3.newId order by T3.time), T3.to) then 1
else null end as times_flag
from
(
select
T1.time, T1.from, T1.to,
concat(if(T1.from < T1.to, T1.from, T1.to), "#", if(T1.from > T1.to, T1.from, T1.to)) as newId
from
temp as T1
) as T3
) as T4
where T4.times_flag is not null
group by T4.newId having count(T4.times_flag)/2 >= 2;5.微信读书,每次进入书籍后会上报init,点击翻页会上报read事件,求每次init事件之后, read事件出现的次数。
uid event_time event
1 2021-11-24 21:23:10 init
1 2021-11-24 21:23:11 read
1 2021-11-24 21:23:12 read
1 2021-11-24 21:23:13 read
1 2021-11-24 21:23:14 init
1 2021-11-24 21:23:15 read
2 2021-11-24 21:23:11 init
2 2021-11-24 21:23:12 read很简单,解法如下:

select
T2.uid,
T2.event_time,
nvl(lead(T2.rn1, 1) over(partition by T2.uid order by T2.event_time) - 1, T2.cnt) - T2.rn1 as times
from
( select
T1.uid, T1.event_time, T1.rn1, T1.cnt
from
(
select
uid,
event_time,
event,
row_number() over(partition by uid order by event_time) as rn1,
count(1) over(partition by uid) as cnt
from
temp
) as T1
where T1.event = 'init'
) as T26.有一场篮球赛,参赛双方是A队和B队,场边记录员记录下了每次得分的详细信息:
team:队名
number:球衣号,
name:球员姓名,
score_time:得分时间,
score:当次得分1)输出每一次的比分的反超时刻,以及对应的完成反超的球员姓名
2)输出连续三次或以上得分的球员姓名,以及那一拨连续得分的数值
7.打折日期交叉问题
如下为平台商品促销数据:字段为品牌,打折开始日期,打折结束日期
brand stt edt
oppo 2021-06-05 2021-06-09
oppo 2021-06-11 2021-06-21
vivo 2021-06-05 2021-06-15
vivo 2021-06-09 2021-06-21
redmi 2021-06-05 2021-06-21
redmi 2021-06-09 2021-06-15
redmi 2021-06-17 2021-06-26
huawei 2021-06-05 2021-06-26
huawei 2021-06-09 2021-06-15
huawei 2021-06-17 2021-06-21计算每个品牌总的打折销售天数,注意其中的交叉日期,比如 vivo 品牌,第一次活动时 间为 2021-06-05 到 2021-06-15,第二次活动时间为 2021-06-09 到 2021-06-21 其中 9 号到 15 号为重复天数,只统计一次,即 vivo 总打折天数为 2021-06-05 到 2021-06-21 共计 17 天。
select
id,
sum(if(days>=0,days+1,0)) days
from
(select
id,
datediff(edt,stt) days
from
(select
id,
if(maxEdt is null,stt,if(stt>maxEdt,stt,date_add(maxEdt,1))) stt,
edt
from
(select
id,
stt,
edt,
max(edt) over(partition by id order by stt rows between UNBOUNDED PRECEDING and 1 PRECEDING) maxEdt
from test4
)t1
)t2
)t3
group by id;8、数据治理 value值 中间null值用紧邻两行非空的均值填充
with tmp as (
select 'A' as breed, '2023-3-3' as `date`, 4521 as value
union all select 'A' as breed, '2023-3-4' as `date`, null as value
union all select 'A' as breed, '2023-3-5' as `date`, null as value
union all select 'A' as breed, '2023-3-6' as `date`, 4430 as value
union all select 'B' as breed, '2023-3-3' as `date`, 4470 as value
union all select 'B' as breed, '2023-3-4' as `date`, null as value
union all select 'B' as breed, '2023-3-5' as `date`, null as value
union all select 'B' as breed, '2023-3-6' as `date`, 4310 as value
union all select 'C' as breed, '2023-3-6' as `date`, 4470 as value
union all select 'C' as breed, '2023-3-7' as `date`, null as value
union all select 'C' as breed, '2023-3-8' as `date`, null as value
union all select 'C' as breed, '2023-3-9' as `date`, null as value
union all select 'C' as breed, '2023-3-10' as `date`, null as value
union all select 'C' as breed, '2023-3-11' as `date`, null as value
union all select 'C' as breed, '2023-3-12' as `date`, null as value
union all select 'C' as breed, '2023-3-13' as `date`, null as value
union all select 'C' as breed, '2023-3-14' as `date`, 4480 as value
)
select * from tmp解法如下:这里要取null行之间紧挨的前后两行的数据,前一行使用last_value(col,true)取从最早到当前行的第一条,这里last_value跳过了为null的行,所以取到了第一行。取最后一行同样的套路。
select
breed,
date,
nvl(value,
(
nvl(last_value(value, true) over(partition by breed order by date rows between unbounded preceding and current row), 0) +
nvl(first_value(value, true) over(partition by breed order by date rows between current row and unbounded following), 0)
) /2
) as value
from
tmp9.对一张超大表进行排序,并生成自增的序列号
核心思想是:将排序的Id值分别按照范围划分到不同的桶中,然后分组排序得到桶中有序的id序列,然后关联当前桶和上一个紧邻的桶的最大值相加既是最大的值
with tmp_tab as (
select 1 as id union all
select 3 as id union all
select 5 as id union all
select 7 as id union all
select 9 as id union all
select 10 as id union all
select 12 as id union all
select 13 as id union all
select 15 as id union all
select 20 as id union all
select 22 as id union all
select 24 as id union all
select 27 as id union all
select 29 as id union all
select 31 as id
)
select
T1.id,
T1.rank + nvl(T2.max_num, 0) as seq
from
(
select
id,
id - id % 10 as part_id,
row_number() over(partition by id - id % 10 order by id) as rank
from
tmp_tab
) as T1 left join
(
select
part_id,
sum(max_num) over(order by part_id) as max_num
from
(
select
id - id % 10 as part_id,
count(1) as max_num
from
tmp_tab
group by id - id % 10
) as T
) as T2
on (T1.part_id - 10) = T2.part_id
order by T1.rank + nvl(T2.max_num, 0)10. 一个表:user_info, 字段,mdn, user_app1, user_app2, user_app3, user_app4
其中:mdn表示手机号,user_app1, user_app2, user_app3, user_app4表示这个手机号经常使用的4个app ,求: app使用率最多的前五名?
-- 记录下,这里使用lateral view的udtf的方式,来替代union all这种多次读取数据源的操作
select
T.user_app,
count(distinct T.mdn) as cnt
from
(
select
mdn,
user_app
from
tmp_tab
lateral view explode(array(user_app1, user_app2, user_app3, user_app4)) t as user_app
) as T
group by T.user_app
11.已知买家和卖家的交易关系,简要表结构如下。求两个买家之间共同卖家的数量
with data as (
select 1 as buyer_id , array('aa', 'bb','ee') as seller_ids UNION ALL
select 2 as buyer_id , array('aa', 'cc','dd') as seller_ids UNION ALL
select 3 as buyer_id , array('aa', 'bb','dd') as seller_ids UNION ALL
select 4 as buyer_id , array('aa', 'cc') as seller_ids
),
temp1 as (
select
buyer_id,
seller_id
from
data
lateral view explode(seller_ids) t as seller_id
)
select
T1.buyer_id, T2.buyer_id, count(1) as cnt
from
temp1 T1 join temp1 T2
on T1.seller_id = T2.seller_id and T1.buyer_id != T2.buyer_id and T1.buyer_id < T2.buyer_id
group by T1.buyer_id, T2.buyer_id12.计算每年在校生人数
-- year 入学年份
-- stu_len 学制
-- stu_num 入学人数
with tmp_tab as (
select 2 as id, 2000 as year, 1300 as stu_num, 5 as stu_len union all
select 1 as id, 2001 as year, 1200 as stu_num, 3 as stu_len union all
select 4 as id, 2002 as year, 1500 as stu_num, 3 as stu_len union all
select 5 as id, 2002 as year, 1600 as stu_num, 2 as stu_len union all
select 3 as id, 2003 as year, 1400 as stu_num, 4 as stu_len
)
select
distinct
year,
sum(stu_num) over(order by year) as stu_num_now
from
(
select year, stu_num, stu_len from tmp_tab
union all
select year+stu_len as year, stu_num * -1 as stu_num, stu_len from tmp_tab
) T13.实现单列的累乘(运用对数的操作)
with tmp_tab as (
select 1 as val union all
select 2 as val union all
select 3 as val union all
select 4 as val union all
select 5 as val union all
select 6 as val union all
select 7 as val
)
select
round(pow(10, sum(log(10, val)))) as ret -- 这里加round是因为对数过程中会有精度丢失问题
from
tmp_tab1. 行列转换
描述:表中记录了各年份各部门的平均绩效考核成绩。
表名:t1
表结构:
a -- 年份
b -- 部门
c -- 绩效得分
表内容:
a b c
2014 B 9
2015 A 8
2014 A 10
2015 B 7
问题一:多行转多列
问题描述:将上述表内容转为如下输出结果所示:
a col_A col_B
2014 10 9
2015 8 7
参考答案:
select
a,
max(case when b="A" then c end) col_A,
max(case when b="B" then c end) col_B
from t1
group by a;
问题二:如何将结果转成源表?(多列转多行)
问题描述:将问题一的结果转成源表,问题一结果表名为t1_2。
参考答案:
select
a,
b,
c
from (
select a,"A" as b,col_a as c from t1_2
union all
select a,"B" as b,col_b as c from t1_2
)tmp;
问题三:同一部门会有多个绩效,求多行转多列结果
问题描述:2014年公司组织架构调整,导致部门出现多个绩效,业务及人员不同,无法合并算绩效,源表内容如下:
2014 B 9
2015 A 8
2014 A 10
2015 B 7
2014 B 6输出结果如下所示:
a col_A col_B
2014 10 6,9
2015 8 7参考答案:
select
a,
max(case when b="A" then c end) col_A,
max(case when b="B" then c end) col_B
from (
select
a,
b,
concat_ws(",",collect_set(cast(c as string))) as c
from t1
group by a,b
)tmp
group by a;
2. 排名中取他值
表名:t2
表字段及内容:
a b c
2014 A 3
2014 B 1
2014 C 2
2015 A 4
2015 D 3
问题一:按a分组取b字段最小时对应的c字段
问题二:按a分组取b字段排第二时对应的c字段
问题二:按a分组取b字段最小和最大时的c的值
问题四:按a分组取b字段第二小和第二大时对应的c字段
问题五:按a分组取b字段前两小和前两大时对应的c字段
参考答案:
select
tmp1.a as a,
min_c,
max_c
from
(
select
a,
concat_ws(',', collect_list(c)) as min_c
from
(
select
a,
b,
c,
row_number() over(partition by a order by b) as asc_rn
from t2
)a
where asc_rn <= 2
group by a
)tmp1
join
(
select
a,
concat_ws(',', collect_list(c)) as max_c
from
(
select
a,
b,
c,
row_number() over(partition by a order by b desc) as desc_rn
from t2
)a
where desc_rn <= 2
group by a
)tmp2
on tmp1.a = tmp2.a;
3. 累计求值
表名:t3
表字段及内容:
a b c
2014 A 3
2014 B 1
2014 C 2
2015 A 4
2015 D 3
问题一:按a分组按b字段排序,对c累计求和
问题二:按a分组按b字段排序,对c取累计平均值
问题三:按a分组按b字段排序,对b取累计排名比例
问题四:按a分组按b字段排序,对b取累计求和比例
select
a,
b,
c,
round(sum(c) over(partition by a order by b) / (sum(c) over(partition by a)),2) as ratio_c
from t3
order by a,b;
4. 窗口大小控制
表名:t4
表字段及内容:
a b c
2014 A 3
2014 B 1
2014 C 2
2015 A 4
2015 D 3
问题一:按a分组按b字段排序,对c取前后各一行的和
问题二:按a分组按b字段排序,对c取平均值
参考答案:
select
a,
b,
case when lag_c is null then c
else (c+lag_c)/2 end as avg_c
from
(
select
a,
b,
c,
lag(c,1) over(partition by a order by b) as lag_c
from t4
)temp;
5. 产生连续数值
参考答案:
select
id_start+pos as id
from(
select
1 as id_start,
1000000 as id_end
) m lateral view posexplode(split(space(id_end-id_start), '')) t as pos, val
select
row_number() over(order by x) as id
from
(select split(space(999999), '') as x) t
lateral view
explode(x) ex;
6. 数据扩充与收缩
表名:t6
表字段及内容:
a
3
2
4
问题一:数据扩充
输出结果如下所示:
a b
3 3、2、1
2 2、1
4 4、3、2、1
参考答案:
select
t.a,
concat_ws('、',collect_set(cast(t.rn as string))) as b
from
(
select
t6.a,
b.rn
from t6
left join
(
select
row_number() over() as rn
from
(select split(space(5), '') as x) t -- space(5)可根据t6表的最大值灵活调整
lateral view
explode(x) as t1 pe
) b
on 1 = 1
where t6.a >= b.rn
order by t6.a, b.rn desc
) t
group by t.a;
7. 合并与拆分
表名:t7
表字段及内容:
a b
2014 A
2014 B
2015 B
2015 D
问题一:合并
输出结果如下所示:
2014 A、B
2015 B、D
参考答案:
select
a,
concat_ws('、', collect_set(t.b)) b
from t7
group by a;
问题二:拆分
问题描述:将分组合并的结果拆分出来
参考答案:
select
t.a,
d
from
(
select
a,
concat_ws('、', collect_set(t7.b)) b
from t7
group by a
)t
lateral view
explode(split(t.b, '、')) table_tmp as d;
8. 模拟循环操作
表名:t8
表字段及内容:
a
1011
0101
问题一:如何将字符’1’的位置提取出来
select
a,
concat_ws(",",collect_list(cast(index as string))) as res
from (
select
a,
index+1 as index,
chr
from (
select
a,
concat_ws(",",substr(a,1,1),substr(a,2,1),substr(a,3,1),substr(a,-1)) str
from t8
) tmp1
lateral view posexplode(split(str,",")) t as index,chr
where chr = "1"
) tmp2
group by a;
9. 不使用distinct或group by去重
使用row_number()进行去重操作
10. 容器–反转内容
表名:t10
表字段及内容:
a
AB,CA,BAD
BD,EA
问题一:反转逗号分隔的数据:改变顺序,内容不变
select
a,
concat_ws(",",collect_list(reverse(str)))
from
(
select
a,
str
from t10
lateral view explode(split(reverse(a),",")) t as str
) tmp1
group by a;
问题二:反转逗号分隔的数据:改变内容,顺序不变
select
a,
concat_ws(",",collect_list(reverse(str)))
from
(
select
a,
str
from t10
lateral view explode(split(a,",")) t as str
) tmp1
group by a;
11. 多容器–成对提取数据
表名:t11
表字段及内容:
a b
A/B 1/3
B/C/D 4/5/2
问题一:成对提取数据,字段一一对应
输出结果如下所示:
a b
A 1
B 3
B 4
C 5
D 2
select
a_inx,
b_inx
from
(
select
a,
b,
a_id,
a_inx,
b_id,
b_inx
from t11
lateral view posexplode(split(a,'/')) t as a_id,a_inx
lateral view posexplode(split(b,'/')) t as b_id,b_inx
) tmp
where a_id=b_id;
12. 多容器–转多行
表名:t12
表字段及内容:
a b c
001 A/B 1/3/5
002 B/C/D 4/5
问题一:转多行
输出结果如下所示:
a d e
001 type_b A
001 type_b B
001 type_c 1
001 type_c 3
001 type_c 5
002 type_b B
002 type_b C
002 type_b D
002 type_c 4
002 type_c 5
select
a,
d,
e
from
(
select
a,
"type_b" as d,
str as e
from t12
lateral view explode(split(b,"/")) t as str
union all
select
a,
"type_c" as d,
str as e
from t12
lateral view explode(split(c,"/")) t as str
) tmp
order by a,d;
13. 抽象分组–断点排序
表名:t13
表字段及内容:
a b
2014 1
2015 1
2016 1
2017 0
2018 0
2019 -1
2020 -1
2021 -1
2022 1
2023 1
问题一:断点排序
输出结果如下所示:
a b c
2014 1 1
2015 1 2
2016 1 3
2017 0 1
2018 0 2
2019 -1 1
2020 -1 2
2021 -1 3
2022 1 1
2023 1 2
select
a,
b,
row_number() over( partition by b,repair_a order by a asc) as c--按照b列和[b的组首]分组,排序
from
(
select
a,
b,
a-b_rn as repair_a--根据b列值出现的次序,修复a列值为b首次出现的a列值,称为b的[组首]
from
(
select
a,
b,
row_number() over( partition by b order by a asc ) as b_rn--按b列分组,按a列排序,得到b列各值出现的次序
from t13
)tmp1
)tmp2--注意,如果不同的b列值,可能出现同样的组首值,但组首值需要和a列值 一并参与分组,故并不影响排序。
order by a asc;
14. 业务逻辑的分类与抽象–时效
日期表:d_date
表字段及内容:
date_id is_work
2017-04-13 1
2017-04-14 1
2017-04-15 0
2017-04-16 0
2017-04-17 1
工作日:周一至周五09:30-18:30
客户申请表:t14
表字段及内容:
a b c
1 申请 2017-04-14 18:03:00
1 通过 2017-04-17 09:43:00
2 申请 2017-04-13 17:02:00
2 通过 2017-04-15 09:42:00
问题一:计算上表中从申请到通过占用的工作时长
输出结果如下所示:
a d
1 0.67h
2 10.67h















 2508
2508











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









