







Redis 中的过期策略
What
过期策略种类
1. 定时过期
每个设置过期时间的 key 都需要创建一个定时器,到过期时间就会立即对 key 进行清除。该策略可以立即清除过期的数据,对内存很友好;但 是会占用大量的 CPU 资源去处理过期的数据,从而影响缓存的响应时间和吞吐量
2. 惰性过期
只有当访问一个 key 时,才会判断该 key 是否已过期,过期则清除。该策略可以最大化地节省 CPU 资源,却对内存非常不友好。极端情况可能 出现大量的过期 key 没有再次被访问,从而不会被清除,占用大量内存
3. 定期过期
每隔一定的时间,会扫描一定数量的数据库的 expires 字典中一定数量的 key,并清除其中已过期的 key。该策略是前两者的一个折中方案。通 过调整定时扫描的时间间隔和每次扫描的限定耗时,可以在不同情况下使得 CPU 和内存资源达到最优的平衡效果。
redis使用的过期策略
Redis 中同时使用了惰性过期和定期过期两种过期策略
假设 Redis 当前存放 30 万个 key,并且都设置了过期时间,如果你每隔 100ms 就去检查这全部的 key,CPU 负载会特别高,最后可能会挂掉。
因此,Redis 采取的是定期过期,每隔 100ms 就随机抽取一定数量的 key 来检查和删除的。
但是呢,最后可能会有很多已经过期的 key 没被删除。这时候,Redis 采用惰性删除。在你获取某个 key 的时候,Redis 会检查一下,这个 key 如果设置了过期时间并且已经过期了,此时就会删除。
Redis 内存淘汰策略
LRU
What
RU(Least recently used,最近最少使用)算法根据数据的历史访问记录来进行淘汰数据,其核心思想是“如果数据最近被访问过,那么将来被访问的几率也更高”。
LRU算法需要实现如下特性
- 实现get/put方法(都为O(1)的时间复杂度)
- 每次get时需要将访问的节点提前至队首
- 每次put需要判断队列是否已满,满了则将最后的节点删除,并且将该节点放至队首,不满则直接放队首
基于上述特性需要实现如下数据结构
- 首先需要实现队列,如果使用单向链表,当我们需要使用删除操作时,需要获得前置节点的指针,单向链表则不能做到直接获取。因此使用双向链表。
- 又我们需要get方法达到O(1)的时间复杂度,因此需要一个Hashmap,可以根据key定位到我们双向链表的Node节点。
- 由于我们HashMap中有key,所以我们可不可以Node中只存value,其实是不可以的,后续会提到这个原因。

#include<iostream>
#include<ctime>
#include<unordered_map>
using namespace std;
struct ListNode {
ListNode* pre;
ListNode* next;
int val;
int key;
ListNode(int _key, int _val):key(_key),val(_val),pre(nullptr),next(nullptr) {};
};
class LRU {
private:
const static int default_capacity = 50;
ListNode* head, * tail;
unordered_map<int, ListNode*>mp;
int size;
int capacity;
public:
LRU():size(0), capacity(default_capacity) {
head = new ListNode(0, 0);
tail = new ListNode(0, 0);
head->next = tail;
tail->pre = head;
}
LRU(int _capacity) :size(0), capacity(_capacity) {
head = new ListNode(0, 0);
tail = new ListNode(0, 0);
head->next = tail;
tail->pre = head;
}
~LRU() {
while (head) {
ListNode* tmp = head;
head = head->next;
delete tmp;
}
}
void put(int key, int value) { // 插入或者更新
if (mp.find(key) != mp.end()) {
ListNode* node = mp[key];
node->val = value;
move_to_head(node);
}
else {
ListNode* newNode = new ListNode(key, value);
mp[key] = newNode;
add_to_head(newNode);
++size; // 记得更新
if (size > capacity) {
ListNode* node = delete_tail();
mp.erase(node->key); // 记得erase
delete node;
--size; // 记得更新
}
}
}
int get(int key) { // 获取数据
if (mp.find(key) != mp.end()) {
ListNode* node = mp[key];
move_to_head(node);
return node->val;
}
return -1;
}
void print() { // 为了测试,打印整个链表(不打印头尾节点)
ListNode* cur = head->next;
while (cur != tail) {
cout << cur->val;
cur = cur->next;
}
cout << endl;
}
private:
void add_to_head(ListNode* node) { // 向链表头部添加node
head->next->pre = node;
node->next = head->next;
node->pre = head;
head->next = node;
}
void move_to_head(ListNode* node) { // 将node移到链表头部
remove(node);
add_to_head(node);
}
void remove(ListNode* node) { // 移除node(注意:是从链表中移除,并没有删除节点)
node->pre->next = node->next;
node->next->pre = node->pre;
}
ListNode* delete_tail() { // 移除尾部节点(最近最少使用节点),并返回该节点便于erase和delete操作
ListNode* tmp = tail->pre;
remove(tmp);
return tmp;
}
};
int main() {
LRU lru(2);
lru.put(1, 1);
lru.print();
lru.put(4, 2);
lru.print();
cout << lru.get(4) << endl;
lru.put(4, 3);
lru.print();
return 0;
}
LFU
what
LFU的全称为Least Frequently Used,意思就是最不频繁使用,所以,LFU算法会淘汰掉使用频率最低的数据。如果存在相同使用频率的数据,则再根据使用时间间隔,将最久未使用的数据淘汰。
我们需要快速找到同一频率的所有节点,然后按照需要淘汰掉最久没被使用过的数据。所以,首先我们要有一个hash表来存储每个频次对应的所有节点信息,同时为了保证操作效率,节点与节点之间同样要组成一个双向链表,得到如下结构:
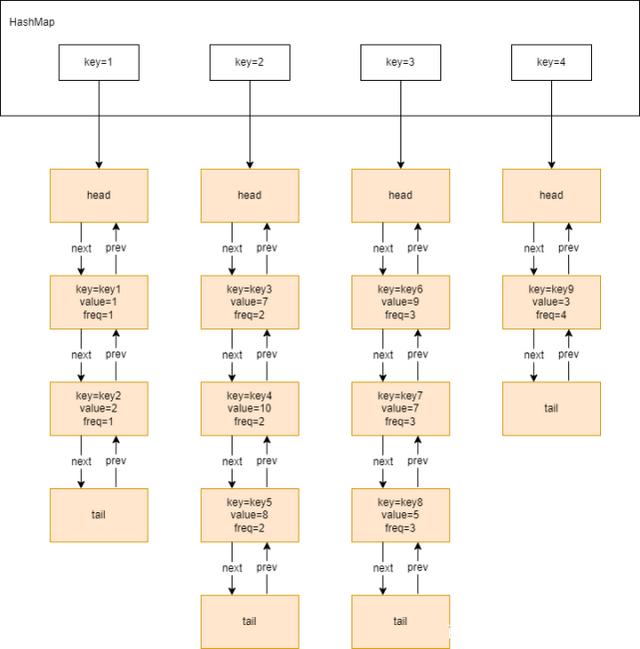
hash表中的key表示访问次数,value就是一个双向链表,链表中所有节点都是被访问过相同次数的数据节点。可以看到,相比较于LRU算法中的节点信息,LFU算法中节点的要素中除了包含具体的key和value之外,还包含了一个freq要素,这个要素就是访问次数,同hash表中的key值一致。这样做的好处是当根据key查找得到一个节点时,我们可以同时得到该节点被访问的次数,从而得到当前访问次数的所有节点。
有了LFU算法的主体结构之后,我们发现还缺少一个重要功能,就是如何根据key值获取value值。所以,参考LRU算法的数据结构,我们还需要有一个hash表来存储key值与节点之间的对应关系。最终,我们就可以得到LFU算法完整的数据结构:
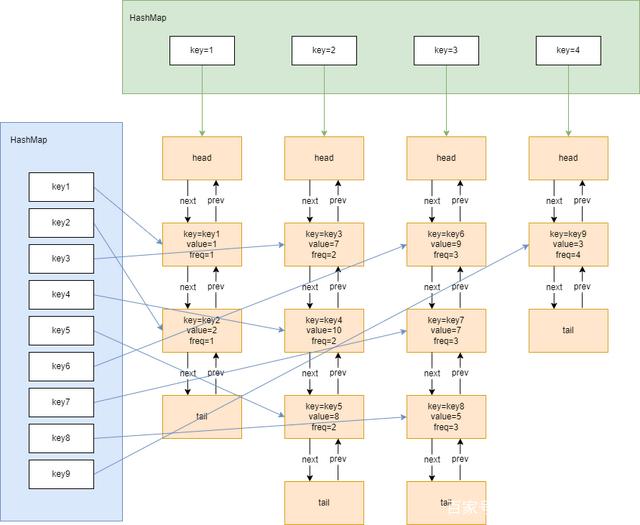
LRU和LFU对比
LRU算法淘汰数据的注重点是时间间隔,只淘汰最久未使用的数据;LFU算法淘汰数据的注重点是使用频率,只淘汰最不经常使用的数据。
LRU算法实现简单,只需要一个hash表+一个双向链表即可实现;LFU算法实现就复杂很多,需要两个hash表+多个双向链表才能实现。
具体使用时,选择哪种算法作为内存淘汰策略要看具体场景,如果对于热点数据的查询要求比较高,则最好采用LFU算法作为内存淘汰策略。如果没有那么高的热点数据要求,则可以选择实现更为简单的LRU算法。
Redis内存淘汰配置
1. volatile-lru
当内存不足以容纳新写入数据时,从设置了过期时间的 key 中使用 LRU(最近最少使用)算法进行淘汰;
2. allkeys-lru:
当内存不足以容纳新写入数据时,从所有 key 中使用 LRU(最近最少使用)算法进行淘汰。
3. volatile-lfu:
4.0 版本新增,当内存不足以容纳新写入数据时,在过期的 key 中,使用 LFU 算法进行删除 key。
4. allkeys-lfu:
4.0 版本新增,当内存不足以容纳新写入数据时,从所有 key 中使用 LFU 算法进行淘汰;
5. volatile-random:
当内存不足以容纳新写入数据时,从设置了过期时间的 key 中,随机淘汰数据;。
6. allkeys-random:
当内存不足以容纳新写入数据时,从所有 key 中随机淘汰数据。
7. volatile-ttl:
当内存不足以容纳新写入数据时,在设置了过期时间的 key 中,根据过期时间进行淘汰,越早过期的优先被淘汰;
8. noeviction:
默认策略,当内存不足以容纳新写入数据时,新写入操作会报错。
















 1155
1155











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











