







下载安装Hadoop
1、下载地址
- 1
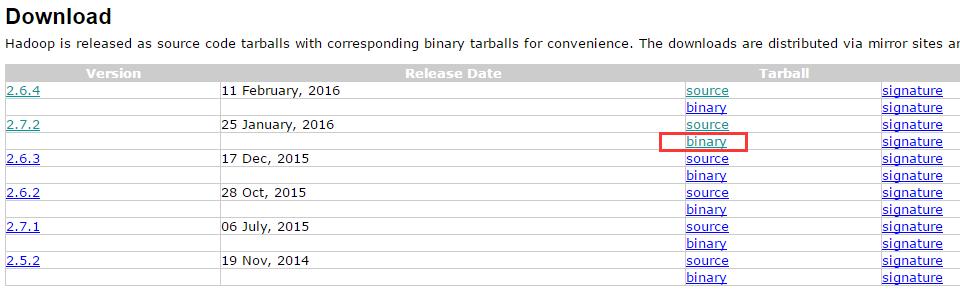
我下载的是2.7.2,官网在2.5之后默认提供的就是64位的,这里直接下载下来用即可
2、安装Hadoop
- 1
3、查看Hadoop是32 or 64 位
参考:http://www.aboutyun.com/thread-12796-1-1.html
- 1
- 2

4、配置/etc/hosts
- 1

配置启动Hadoop
1、修改hadoop2.7.2/etc/hadoop/hadoop-env.sh指定JAVA_HOME
- 1
- 2
2、修改hdfs的配置文件
修改hadoop2.7.2/etc/hadoop/core-site.xml 如下:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
这里fs.defaultFS的value最好是写本机的静态IP当然写本机主机名,再配置hosts是最好的,如果用localhost,然后在windows用java操作hdfs的时候,会连接不上主机。
修改hadoop2.7.2/etc/hadoop/hdfs-site.xml 如下:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
3、配置SSH免密码登录
配置前:
- 1

会出现如上效果,要求我输入本机登录密码
配置方法:
- 1
- 2
- 3
配置后,不用密码可以直接登录了

4、hdfs启动与停止
第一次启动得先格式化(最好不要复制):
- 1
启动hdfs
- 1
看到如下效果表示成功:
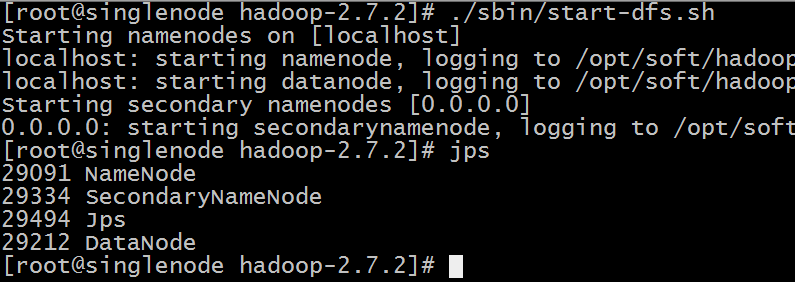
测试用浏览器访问:(如果没响应,则开发50070端口)
- 1
- 2
- 1
效果如下:
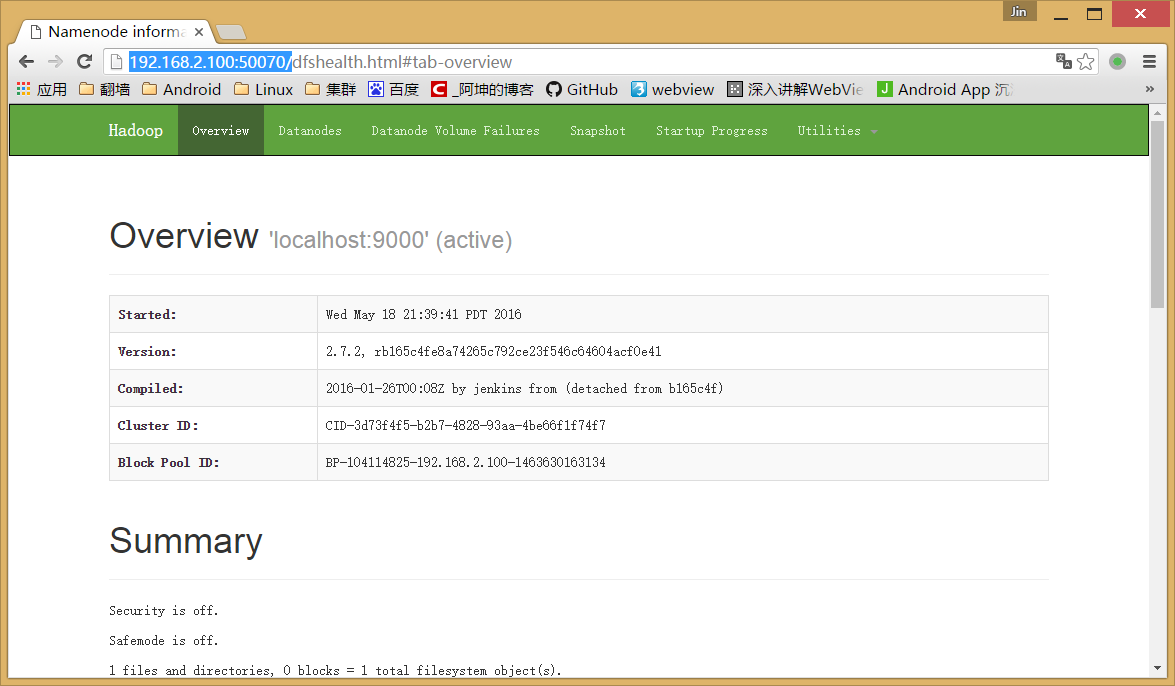
停止hdfs
- 1
5、常用操作:
HDFS shell
查看帮助
- 1
上传
- 1
查看文件内容
- 1
查看文件列表
- 1
下载文件
- 1
上传文件测试
创建一个words.txt 文件并上传
- 1
- 2
- 3
- 4
- 5
- 6
- 7
将words.txt上传到hdfs的根目录
- 1
可以通过浏览器访问:http://192.168.2.100:50070/
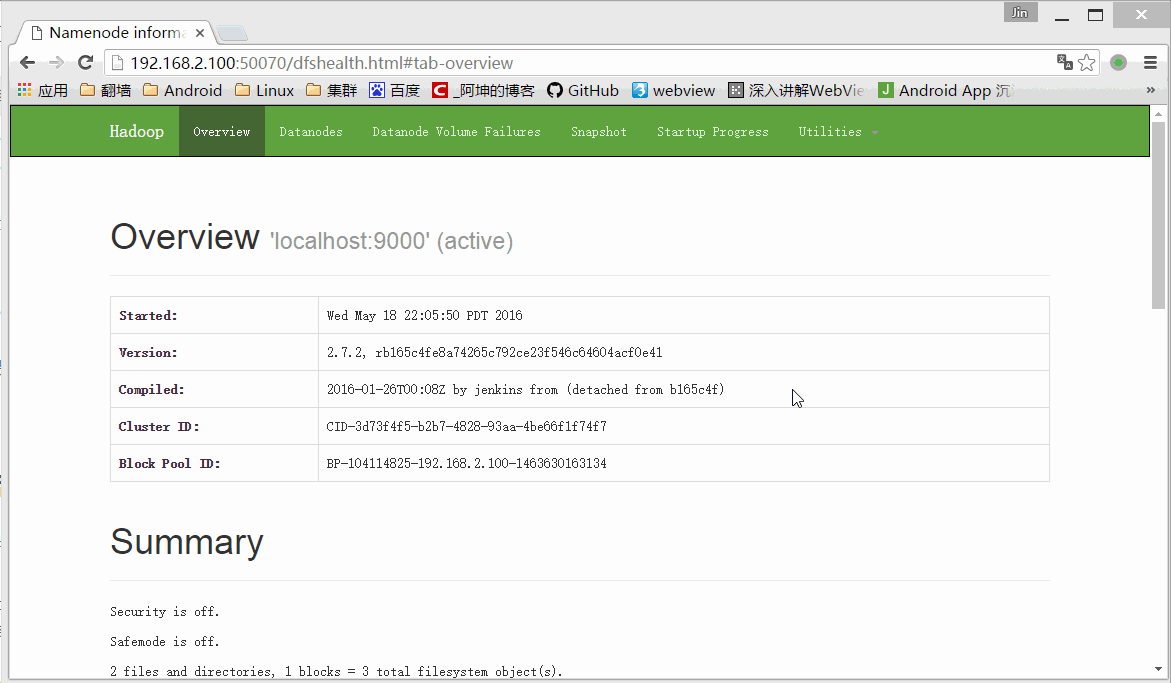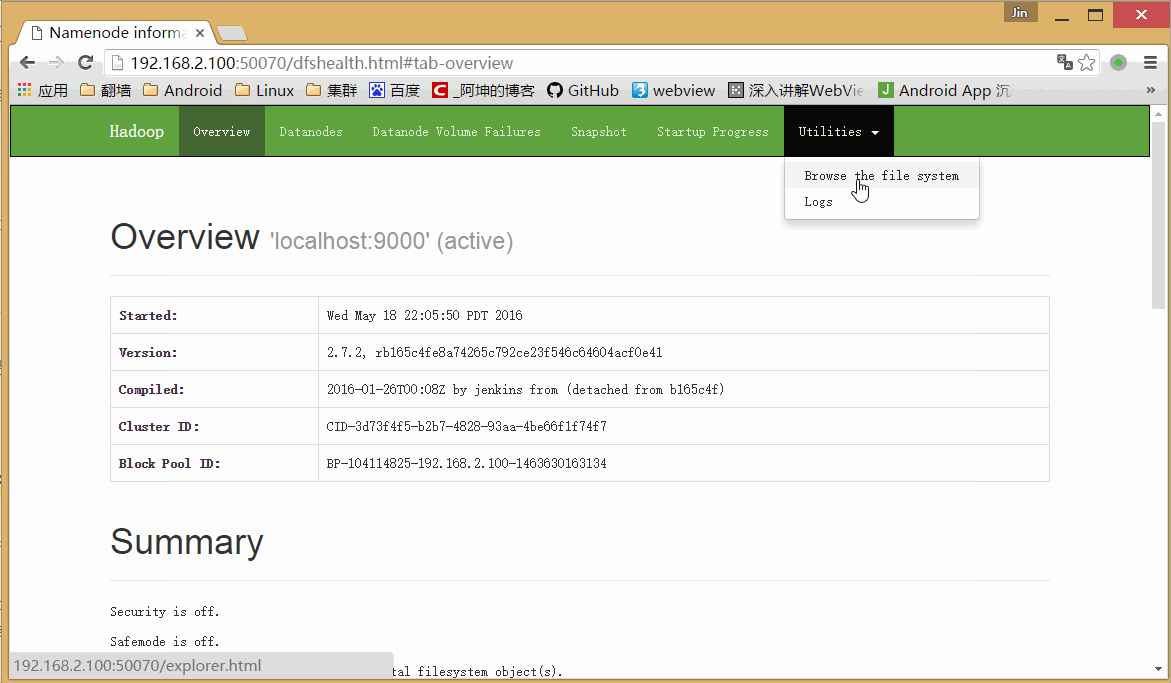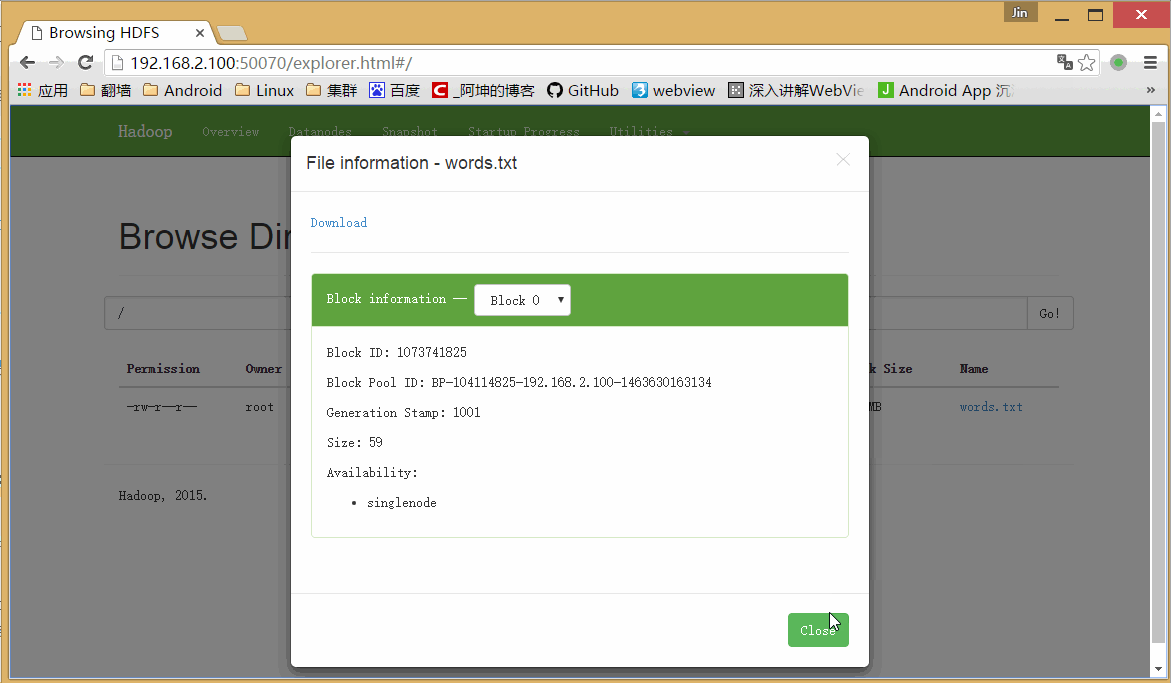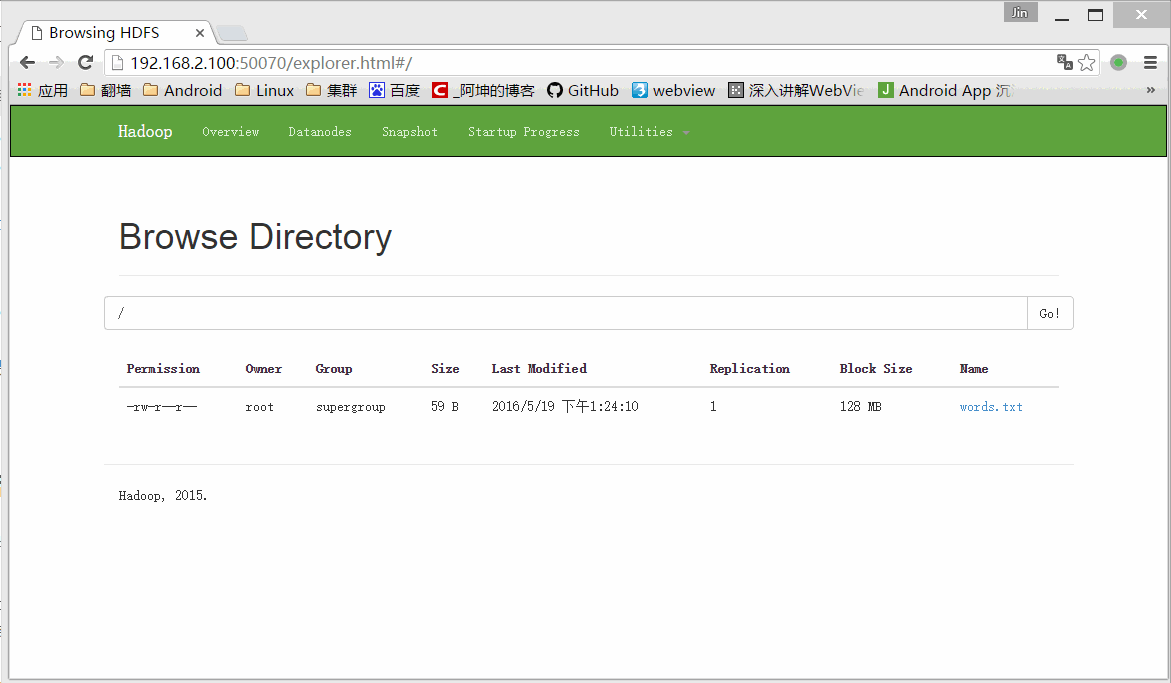
这里的words.txt就是我们上传的words.txt
配置启动YARN
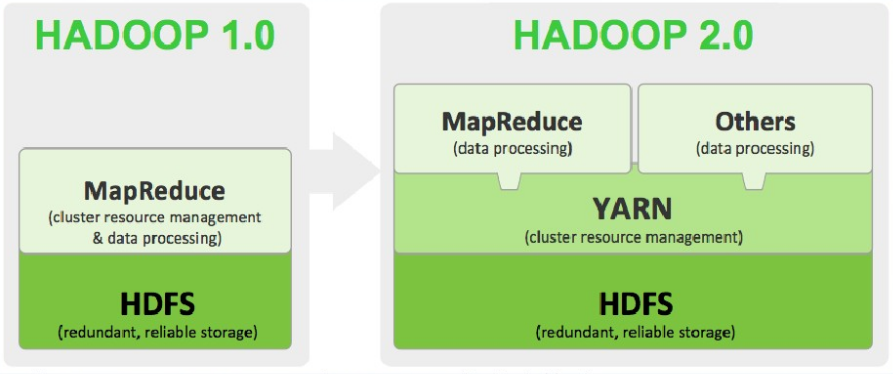
从上图看看出我们的MapReduce是运行在YARN上的,而YARN是运行在HDFS之上的,我们已经安装了HDFS现在来配置启动YARN,然后运行一个WordCount程序。
1、配置etc/hadoop/mapred-site.xml:
mv mapred-site.xml.template mapred-site.xml
- 1
- 2
- 3
- 4
- 5
- 6
- 7
2、配置etc/hadoop/yarn-site.xml:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
3、YARN的启动与停止
启动
- 1
如下:
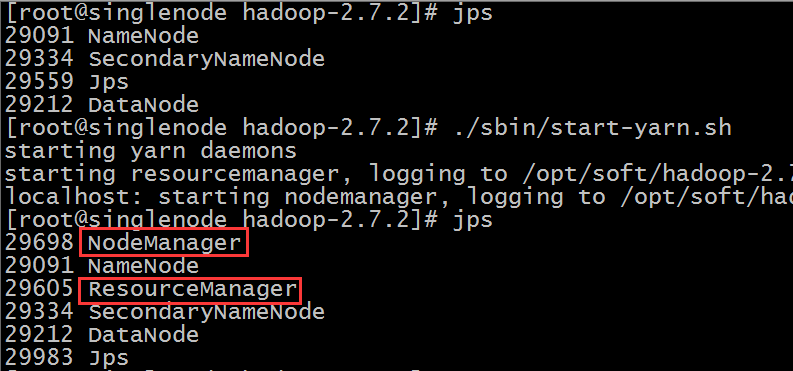
测试用浏览器访问:(如果没响应,则开发8088端口)
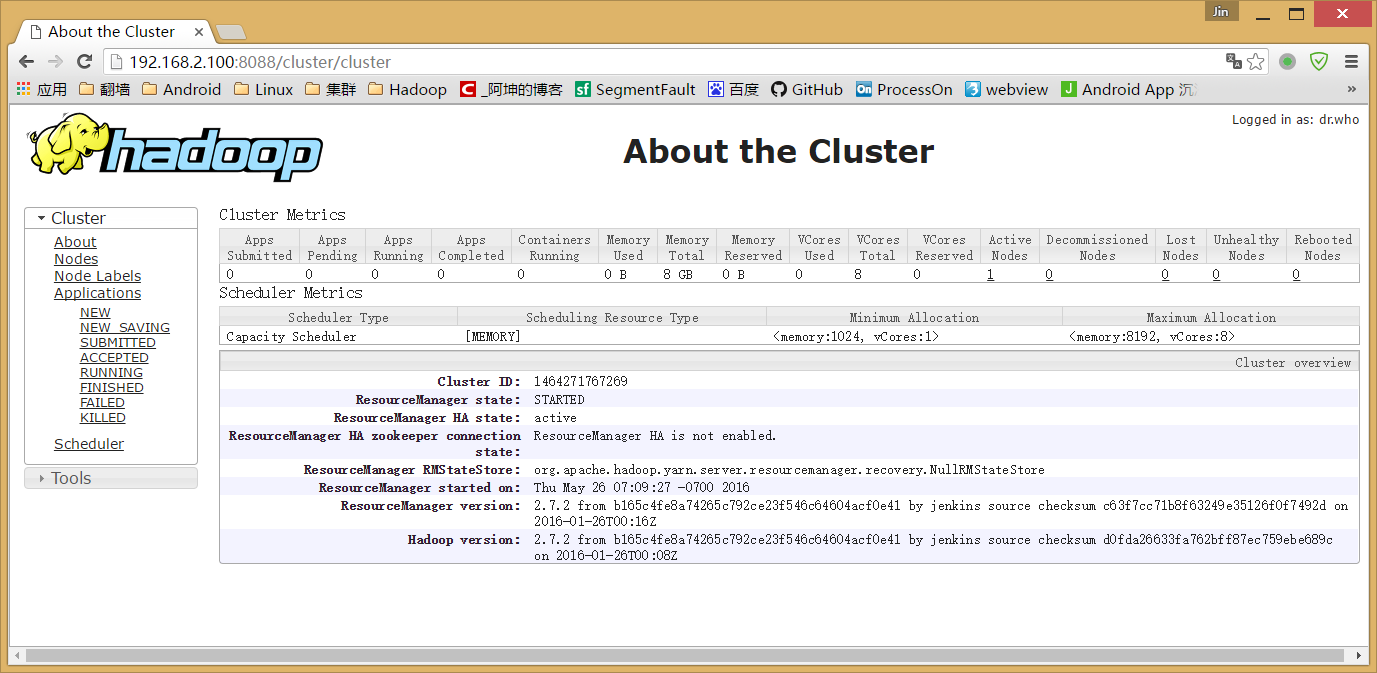
停止
- 1
现在我们的hdfs和yarn都运行成功了,我们开始运行一个WordCount的MP程序来测试我们的单机模式集群是否可以正常工作。
运行一个简单的MP程序
我们的MapperReduce将会跑在YARN上,结果将存在HDFS上:
- 1
用hadoop执行一个叫 hadoop-mapreduce-examples.jar 的 wordcount 方法,其中输入参数为 hdfs上根目录的words.txt 文件,而输出路径为 hdfs跟目录下的out目录,运行过程如下:
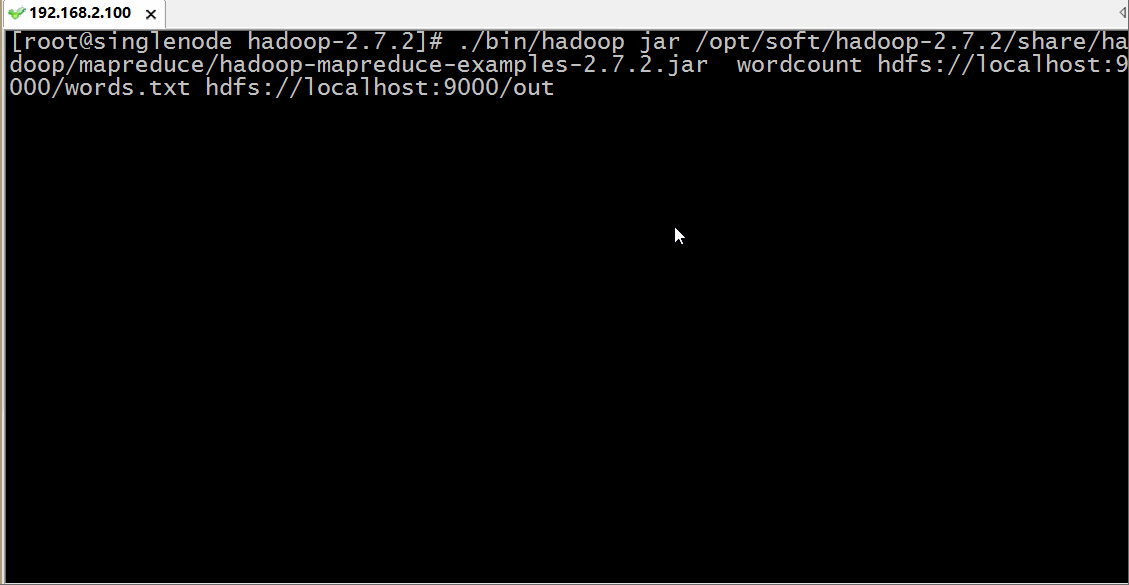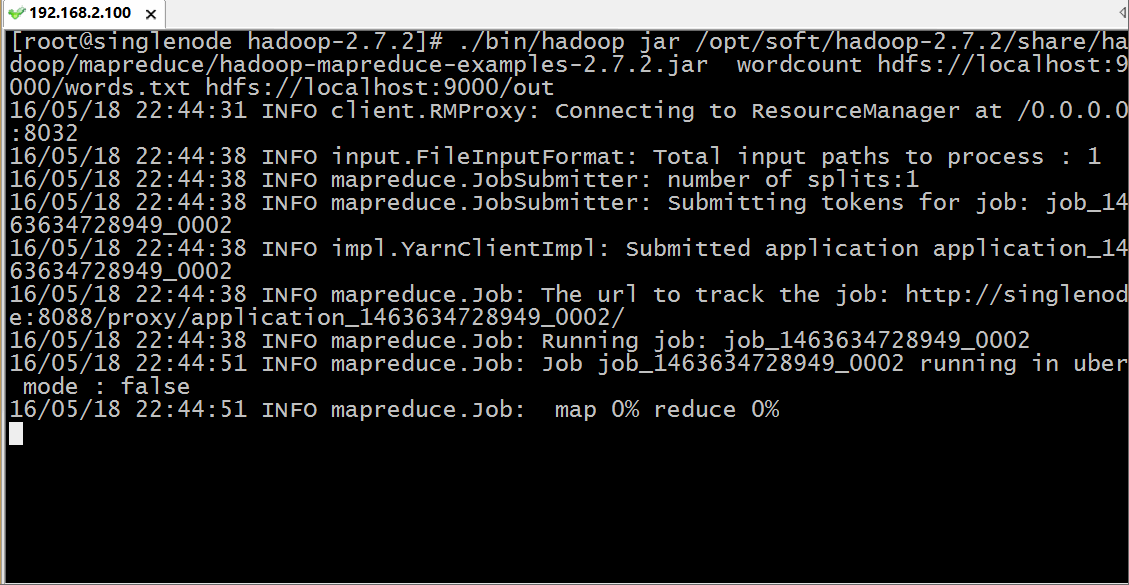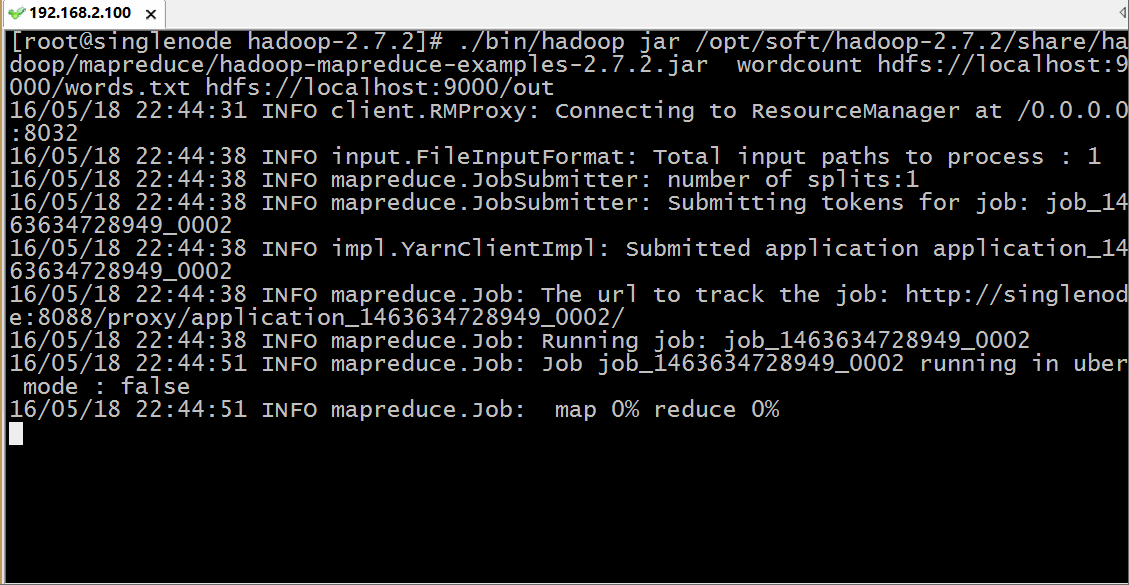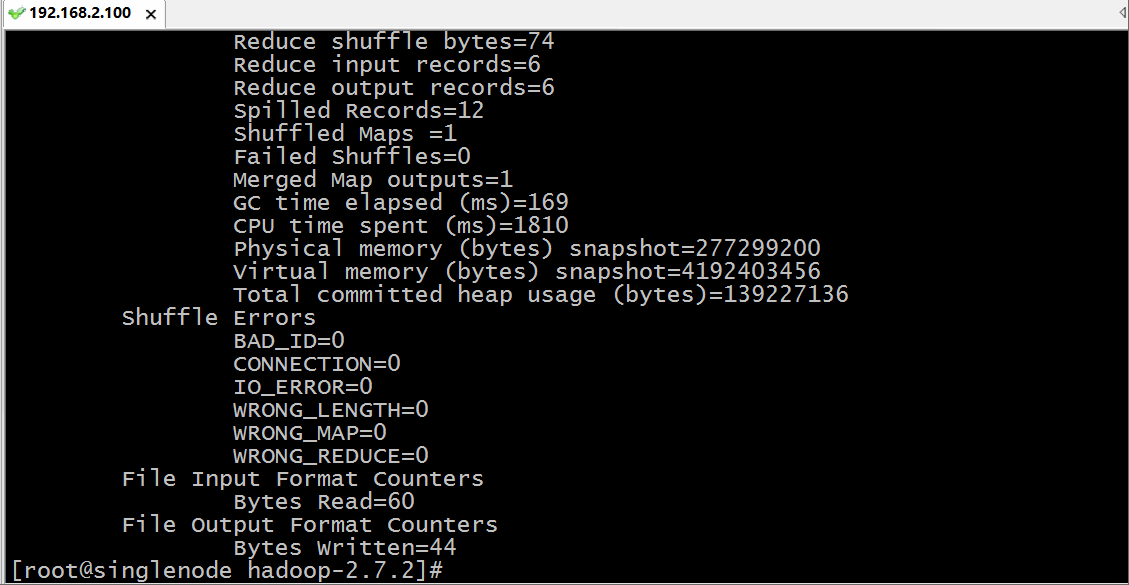
我们通过浏览器访问和下载查看结果:
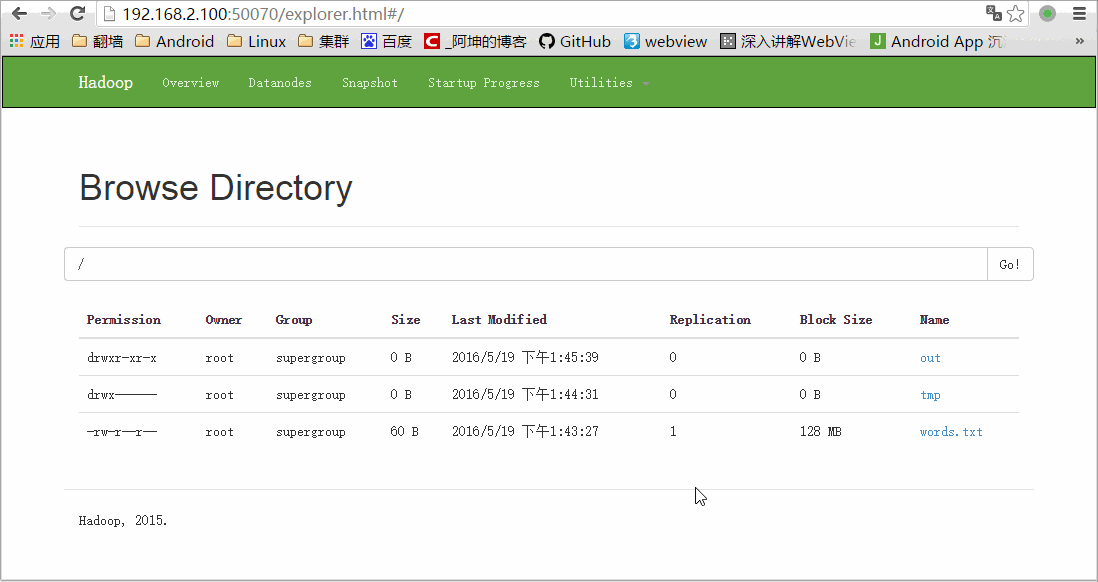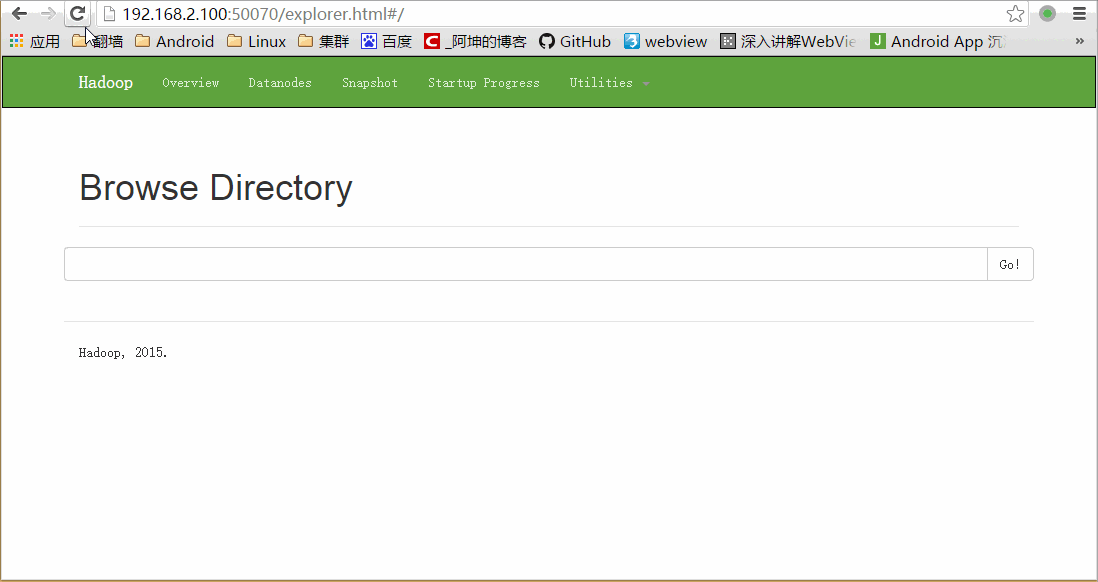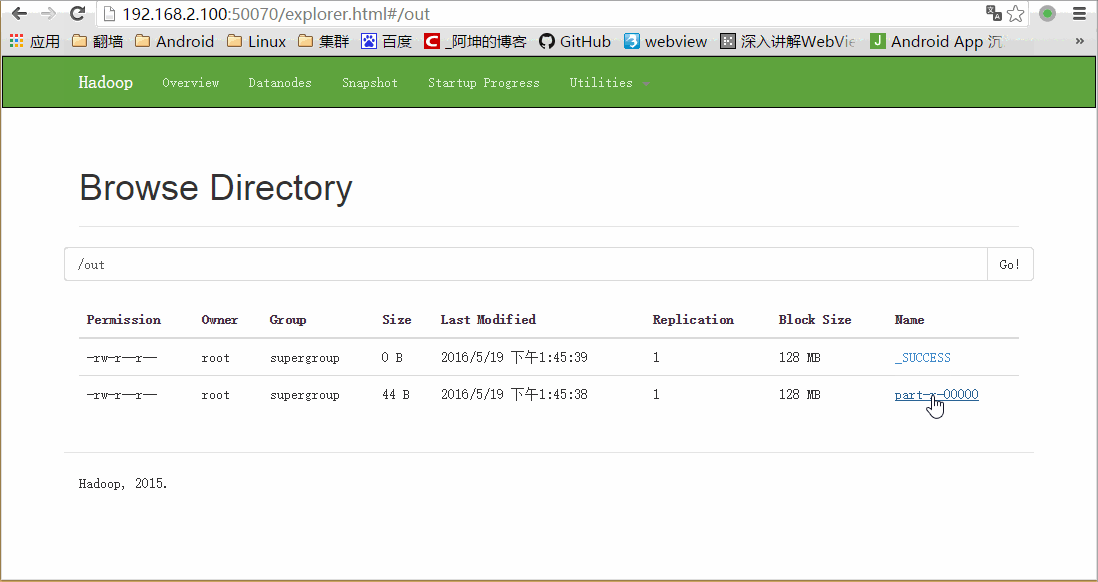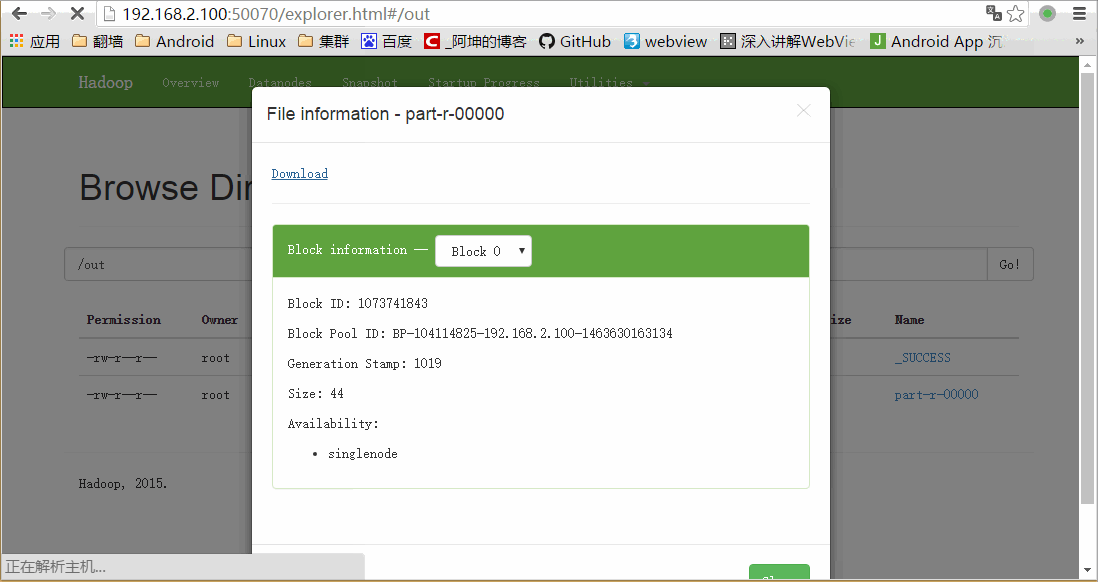
这里下载的时候会跳转到另一个地址如下:
- 1
1、需把singlenode换成192.168.2.100或是在hosts里加入 192.168.2.100 singlenode 隐射关系
2、需开放50075端口。
下载下来结果如下:
- 1
- 2
- 3
- 4
- 5
- 6
说明我们已经计算出了,单词出现的次数。
至此,我们Hadoop的单机模式搭建成功。














 150
150











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









